

Graphical explanation of HTTP Headers knowledge points
Whether you are doing front-end or back-end, you will deal with HTTP Headers from time to time. Understanding it will undoubtedly be of great help to web development. In this article, let me learn all aspects of http headers.
What are HTTP Headers
HTTP is written by the "Hypertext Transfer Protocol". This protocol is used by the entire World Wide Web, and almost most of the content you see in the browser is Transmitted through http protocol, such as this article.
HTTP Headers are the core of HTTP requests and responses. They carry information about the client browser, requested page, server, etc.

Example
When you type a url in the browser address bar, your browser will make an http request similar to the following:
GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1 Host: net.tutsplus.com User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 Keep-Alive: 300 Connection: keep-alive Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120 Pragma: no-cache Cache-Control: no-cache
The first line is called "Request Line" which describes the basic information of the request, and the rest are HTTP headers.
After the request is completed, your browser may receive the following HTTP response:
HTTP/1.x 200 OK Transfer-Encoding: chunked Date: Sat, 28 Nov 2009 04:36:25 GMT Server: LiteSpeed Connection: close X-Powered-By: W3 Total Cache/0.8 Pragma: public Expires: Sat, 28 Nov 2009 05:36:25 GMT Etag: "pub1259380237;gz" Cache-Control: max-age=3600, public Content-Type: text/html; charset=UTF-8 Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT X-Pingback: http://net.tutsplus.com/xmlrpc.php Content-Encoding: gzip Vary: Accept-Encoding, Cookie, User-Agent <!-- ... rest of the html ... -->
The first line is called "Status Line", and after it are the http headers , after the blank line is finished, the content starts to be output (in this case, some html output).
But when you view the page source code, you cannot see the HTTP headers, although they are sent to the browser along with what you can see.
This HTTP request also sends out requests to receive some other resources, such as pictures, css files, js files, etc.
Let’s take a look at the details.
How to see HTTP Headers
The following FireFox extensions can help you analyze HTTP headers:
1. firebug

2.Live HTTP Headers

3. In PHP:
getallheaders() is used to get the request headers. You can also use the $_SERVER array.
headers_list() Used to obtain response headers.
You will see some examples of using PHP demonstration below.
The structure of HTTP Request

The first line called the "first line" contains three parts:
-
"method" indicates what type of request this is. The most common request types are GET, POST and HEAD.
"path" reflects the path after the host. For example, when you request "http://net.tutsplus.com/tutorials/other/top-20-mysql-best-practices/", the path will be "/tutorials/other/top-20-mysql-best" -practices/”.
“protocol” contains “HTTP” and version number, modern browsers will use 1.1.
The rest Each row of the section is a "Name:Value" pair. They contain various information about the request and your browser. For example, "User-Agent" indicates your browser version and the operating system you are using. "Accept-Encoding" tells the server that your browser can accept compressed output like gzip.
Most of these headers are optional. The HTTP request can even be condensed to this:
<span style="font-family:NSimsun">GET /tutorials/other/top-20-mysql-best-practices/ HTTP/1.1<br/>Host: net.tutsplus. com</span>
and you will still receive a valid response from the server.
Request types
The three most common request types are: GET, POST and HEAD. You may be familiar with the first two from the process of writing HTML.
GET: Get a document
Most of the html, images, js, css,... that are transmitted to the browser are requested through the GET method. It is the primary method of obtaining data.
For example, to get Nettuts+ articles, the first line of the http request usually looks like this:
<span style="font-family:NSimsun">GET /tutorials/other/top-20-mysql -best-practices/ HTTP/1.1</span>
Once the html is loaded, the browser will send a GET request to get the image, like this:
<span style="font-family:NSimsun">GET /wp-content/themes/tuts_theme/images/header_bg_tall.png HTTP/1.1</span>
<form action="foo.php" method="GET"> First Name: <input name="first_name" type="text" /> Last Name: <input name="last_name" type="text" /> <input name="action" type="submit" value="Submit" /> </form>
GET /foo.php?first_name=John&last_name=Doe&action=Submit HTTP/1.1<span style="font-family:NSimsun">... <br/></span>
你可以将表单输入通过附加进查询字符串的方式发送至服务器。
POST:发送数据至服务器
尽管你可以通过GET方法将数据附加到url中传送给服务器,但在很多情况下使用POST发送数据给服务器更加合适。通过GET发送大量数据是不现实的,它有一定的局限性。
用POST请求来发送表单数据是普遍的做法。我们来吧上面的例子改造成使用POST方式:
<form action="foo.php" method="POST"> First Name: <input name="first_name" type="text" /> Last Name: <input name="last_name" type="text" /> <input name="action" type="submit" value="Submit" /> </form>
提交这个表单会创建一个如下的HTTP 请求:
POST /foo.php HTTP/1.1 Host: localhost User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729) Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: en-us,en;q=0.5 Accept-Encoding: gzip,deflate Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7 Keep-Alive: 300 Connection: keep-alive Referer: http://localhost/test.php Content-Type: application/x-www-form-urlencoded Content-Length: 43 first_name=John&last_name=Doe&action=Submit
这里有三个需要注意的地方:
第一行的路径已经变为简单的 /foo.php , 已经没了查询字符串。
新增了 Content-Type 和 Content-Lenght 头部,它提供了发送信息的相关信息.
所有数据都在headers之后,以查询字符串的形式被发送.
POST方式的请求也可用在AJAX,应用程序,cURL … 之上。并且所有的文件上传表单都被要求使用POST方式。
HEAD:接收头部信息
HEAD和GET很相似,只不过HEAD不接受HTTP响应的内容部分。当你发送了一个HEAD请求,那就意味着你只对HTTP头部感兴趣,而不是文档本身。
这个方法可以让浏览器判断页面是否被修改过,从而控制缓存。也可判断所请求的文档是否存在。
例如,假如你的网站上有很多链接,那么你就可以简单的给他们分别发送HEAD请求来判断是否存在死链,这比使用GET要快很多。
http响应结构
当浏览器发送了HTTP请求之后,服务器就会通过一个HTTP response来响应这个请求。如果不关心内容,那么这个请求看起来会是这样的:

第一个有价值的信息就是协议。目前服务器都会使用 HTTP/1.x 或者 HTTP/1.1。
接下来一个简短的信息代表状态。代码200意味着我们的请求已经发送成功了,服务器将会返回给我们所请求的文档,在头部信息之后。
我们都见过“Graphical explanation of HTTP Headers knowledge points”页面。当我向服务器请求一个不存在的路径时,服务器就用用Graphical explanation of HTTP Headers knowledge points来代替200响应我们。
余下的响应内容和HTTP请求相似。这些内容是关于服务器软件的,页面/文件何时被修改过,mime type 等等…
同样,这些头部信息也是可选的。
HTTP状态码
200 用来表示请求成功.
300 来表示重定向.
400 用来表示请求出现问题.
500 用来表示服务器出现问题.
200 成功 (OK)
前文已经提到,200是用来表示请求成功的。
206 部分内容 (Partial Content)
如果一个应用只请求某范围之内的文件,那么就会返回206.
这通常被用来进行下载管理,断点续传或者文件分块下载。
Graphical explanation of HTTP Headers knowledge points 没有找到 (Not Found)
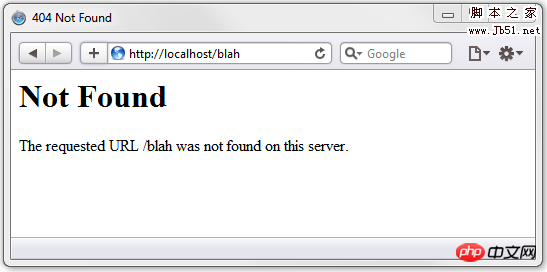
很容易理解
Graphical explanation of HTTP Headers knowledge points 未经授权 (Unauthorized)
受密码保护的页面会返回这个状态。如果你没有输入正确的密码,那么你就会在浏览器中看到如下的信息:
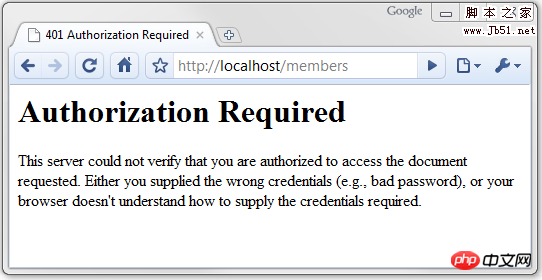
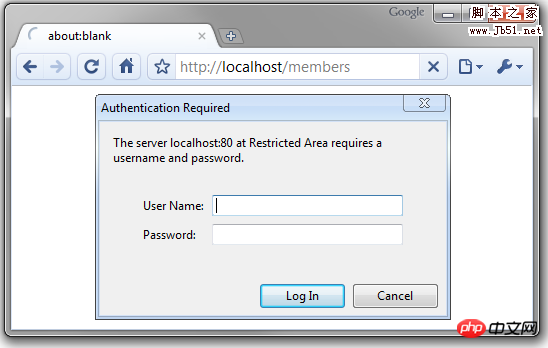
注意这只是受密码保护页面,请求输入密码的弹出框是下面这个样子的:
403 被禁止(Forbidden)
如果你没有权限访问某个页面,那么就会返回403状态。这种情况通常会发生在你试图打开一个没有index页面的文件夹。如果服务器设置不允许查看目录内容,那么你就会看到403错误。
其它一些一些方式也会发送权限限制,例如你可以通过IP地址进行阻止,这需要一些htaccess的协助。
<span style="font-family:NSimsun">order allow,deny<br/>deny from 192.168.44.201<br/>deny from 224.39.163.12<br/>deny from 172.16.7.92<br/>allow from all</span>
302(或307)临时移动(Moved Temporarily) 和 301 永久移动(Moved Permanently)
这两个状态会出现在浏览器重定向时。例如,你使用了类似 bit.ly 的网址缩短服务。这也是它们如何获知谁点击了他们链接的方法。
302和301对于浏览器来说是非常相似的,但对于搜索引擎爬虫就有一些差别。打个比方,如果你的网站正在维护,那么你就会将客户端浏览器用302 重定向到另外一个地址。搜索引擎爬虫就会在将来重新索引你的页面。但是如果你使用了301重定向,这就等于你告诉了搜索引擎爬虫:你的网站已经永久的移动 到了新的地址。
500 服务器错误(Internal Server Error)
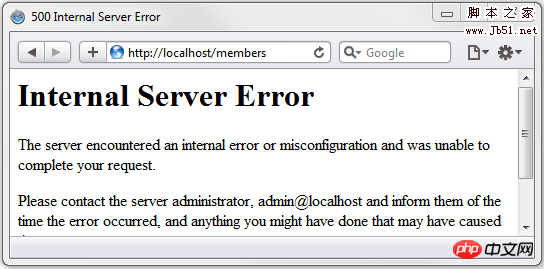
这个代码通常会在页面脚本崩溃时出现。大部分CGI脚本都不会像PHP那样输出错误信息给浏览器。如果出现了致命的错误,它们只会发送一个500的状态码。这时需要查看服务器错误日志来排错。
完整的列表
你可以在这里找到完整的HTTP 状态码说明。
HTTP Headers 中的 HTTP请求
现在我们来看一些在HTTP headers中常见的HTTP请求信息。
所有这些头部信息都可以在PHP的$_SERVER数组中找到。你也可以用getallheaders() 函数一次性获取所有的头部信息。
Host
一个HTTP请求会发送至一个特定的IP地址,但是大部分服务器都有在同一IP地址下托管多个网站的能力,那么服务器必须知道浏览器请求的是哪个域名下的资源。
<span style="font-family:NSimsun">Host: rlog.cn</span>
这只是基本的主机名,包含域名和子级域名。
在PHP中,可以通过$_SERVER['HTTP_HOST'] 或 $_SERVER['SERVER_NAME']来查看。
User-Agent
<span style="font-family:NSimsun">User-Agent: Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.5) Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)</span>
这个头部可以携带如下几条信息:
浏览器名和版本号.
操作系统名和版本号.
默认语言.
这就是某些网站用来收集访客信息的一般手段。例如,你可以判断访客是否在使用手机访问你的网站,然后决定是否将他们引导至一个在低分辨率下表现良好的移动网站。
在PHP中,可以通过 $_SERVER['HTTP_USER_AGENT'] 来获取User-Agent
if ( strstr($_SERVER['HTTP_USER_AGENT'],'MSIE 6') ) {
echo "Please stop using IE6!";
}Accept-Language
<span style="font-family:NSimsun">Accept-Language: en-us,en;q=0.5</span>
这个信息可以说明用户的默认语言设置。如果网站有不同的语言版本,那么就可以通过这个信息来重定向用户的浏览器。
它可以通过逗号分割来携带多国语言。第一个会是首选的语言,其它语言会携带一个“q”值,来表示用户对该语言的喜好程度(0~1)。
在PHP中用 $_SERVER["HTTP_ACCEPT_LANGUAGE"] 来获取这一信息。
if (substr($_SERVER['HTTP_ACCEPT_LANGUAGE'], 0, 2) == 'fr') {
header('Location: http://french.mydomain.com');
}Accept-Encoding
<span style="font-family:NSimsun">Accept-Encoding: gzip,deflate</span>
大部分的现代浏览器都支持gzip压缩,并会把这一信息报告给服务器。这时服务器就会压缩过的HTML发送给浏览器。这可以减少近80%的文件大小,以节省下载时间和带宽。
在PHP中可以使用 $_SERVER["HTTP_ACCEPT_ENCODING"] 获取该信息。 然后调用ob_gzhandler()方法时会自动检测该值,所以你无需手动检测。
<span style="font-family:NSimsun">// enables output buffering<br/>// and all output is compressed if the browser supports it<br/>ob_start('ob_gzhandler');</span>
If-Modified-Since
如果一个页面已经在你的浏览器中被缓存,那么你下次浏览时浏览器将会检测文档是否被修改过,那么它就会发送这样的头部:
<span style="font-family:NSimsun">If-Modified-Since: Sat, 28 Nov 2009 06:38:19 GMT</span>
如果自从这个时间以来未被修改过,那么服务器将会返回“304 Not Modified”,而且不会再返回内容。浏览器将自动去缓存中读取内容
在PHP中,可以用$_SERVER['HTTP_IF_MODIFIED_SINCE'] 来检测。
// assume $last_modify_time was the last the output was updated
// did the browser send If-Modified-Since header?
if(isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])) {
// if the browser cache matches the modify time
if ($last_modify_time == strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE'])) {
// send a 304 header, and no content
header("HTTP/1.1 304 Not Modified");
exit;
}
}还有一个叫Etag的HTTP头信息,它被用来确定缓存的信息是否正确,稍后我们将会解释它。
Cookie
顾名思义,他会发送你浏览器中存储的Cookie信息给服务器。
<span style="font-family:NSimsun">Cookie: PHPSESSID=r2t5uvjq435r4q7ib3vtdjq120; foo=bar</span>
它是用分号分割的一组名值对。Cookie也可以包含session id。
在PHP中,单一的Cookie可以访问$_COOKIE数组获得。你可以直接用$_SESSION array获取session变量。如果你需要session id,那么你可以使用session_id()函数代替cookie。
echo $_COOKIE['foo']; // output: bar echo $_COOKIE['PHPSESSID']; // output: r2t5uvjq435r4q7ib3vtdjq120 session_start(); echo session_id(); // output: r2t5uvjq435r4q7ib3vtdjq120
Referer
顾名思义, 头部将会包含referring url信息。
例如,我访问Nettuts+的主页并点击了一个链接,这个头部信息将会发送到浏览器:<span style="font-family:NSimsun">Referer: http://net.tutsplus.com/ </span>
在PHP中,可以通过 $_SERVER['HTTP_REFERER'] 获取该值。
if (isset($_SERVER['HTTP_REFERER'])) {
$url_info = parse_url($_SERVER['HTTP_REFERER']);
// is the surfer coming from Google?
if ($url_info['host'] == 'www.google.com') {
parse_str($url_info['query'], $vars);
echo "You searched on Google for this keyword: ". $vars['q'];
}
}
// if the referring url was:
// http://www.google.com/search?source=ig&hl=en&rlz=&=&q=http+headers&aq=f&oq=&aqi=g-p1g9
// the output will be:
// You searched on Google for this keyword: http headersYou may have noticed the word “referrer” is misspelled as “referer”. Unfortunately it made into the official HTTP specifications like that and got stuck.
Authorization
当一个页面需要授权,浏览器就会弹出一个登陆窗口,输入正确的帐号后,浏览器会发送一个HTTP请求,但此时会包含这样一个头部:
<span style="font-family:NSimsun">Authorization: Basic bXl1c2VyOm15cGFzcw==</span>
包含在头部的这部分信息是base64 encoded。例如,base64_decode(‘bXl1c2VyOm15cGFzcw==’) 会被转化为 ‘myuser:mypass’ 。
在PHP中,这个值可以用$_SERVER['PHP_AUTH_USER'] 和 $_SERVER['PHP_AUTH_PW'] 获得。
更多细节我们会在WWW-Authenticate部分讲解。
HTTP Headers 中的 HTTP响应
现在让我了解一些常见的HTTP Headers中的HTTP响应信息。
在PHP中,你可以通过 header() 来设置头部响应信息。PHP已经自动发送了一些必要的头部信息,如 载入的内容,设置 cookies 等等… 你可以通过 headers_list() 函数看到已发送和将要发送的头部信息。你也可以使用headers_sent()函数来检查头部信息是否已经被发送。
Cache-Control
w3.org 的定义是:“The Cache-Control general-header field is used to specify directives which MUST be obeyed by all caching mechanisms along the request/response chain.” 其中“caching mechanisms” 包含一些你ISP可能会用到的 网关和代理信息。
例如:
<span style="font-family:NSimsun">Cache-Control: max-age=3600, public</span>
“public”意味着这个响应可以被任何人缓存,“max-age” 则表明了该缓存有效的秒数。允许你的网站被缓存降大大减少下载时间和带宽,同时也提高的浏览器的载入速度。
也可以通过设置 “no-cache” 指令来禁止缓存:
<span style="font-family:NSimsun">Cache-Control: no-cache </span>
更多详情请参见w3.org。
Content-Type
这个头部包含了文档的”mime-type”。浏览器将会依据该参数决定如何对文档进行解析。例如,一个html页面(或者有html输出的php页面)将会返回这样的东西:
<span style="font-family:NSimsun">Content-Type: text/html; charset=UTF-8</span>
‘text’ 是文档类型,‘html’则是文档子类型。 这个头部还包括了更多信息,例如 charset。
如果是一个图片,将会发送这样的响应:
<span style="font-family:NSimsun">Content-Type: image/gif</span>
浏览器可以通过mime-type来决定使用外部程序还是自身扩展来打开该文档。如下的例子降调用Adobe Reader:
<span style="font-family:NSimsun">Content-Type: application/pdf</span>
直接载入,Apache通常会自动判断文档的mime-type并且添加合适的信息到头部去。并且大部分浏览器都有一定程度的容错,在头部未提供或者错误提供该信息的情况下它会去自动检测mime-type。
你可以在这里找到一个常用mime-type列表。
在PHP中你可以通过 finfo_file() 来检测文件的ime-type。
Content-Disposition
这个头部信息将告诉浏览器打开一个文件下载窗口,而不是试图解析该响应的内容。例如:
<span style="font-family:NSimsun">Content-Disposition: attachment; filename="download.zip"</span>
他会导致浏览器出现这样的对话框:
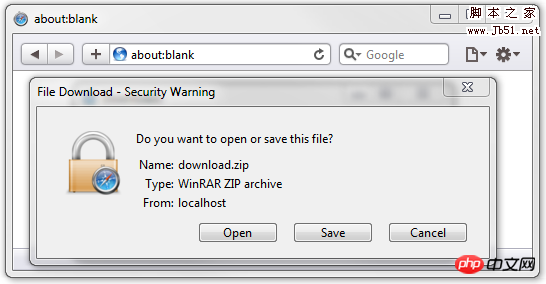
注意,适合它的Content-Type头信息同时也会被发送
<span style="max-width:90%">Content-Type: application/zip<br/>Content-Disposition: attachment; filename="download.zip"</span>
Content-Length
当内容将要被传输到浏览器时,服务器可以通过该头部告知浏览器将要传送文件的大小(bytes)。
<span style="font-family:NSimsun">Content-Length: 89123</span>
对于文件下载来说这个信息相当的有用。这就是为什么浏览器知道下载进度的原因。
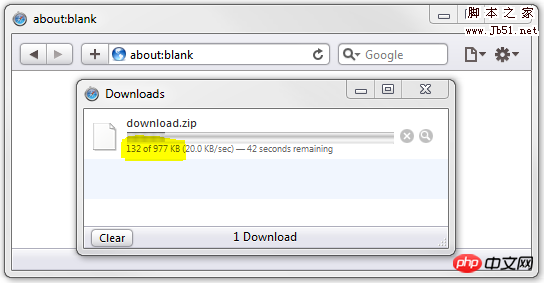
例如,这里我写了一段虚拟脚本,来模拟一个慢速下载。
// it's a zip file
header('Content-Type: application/zip');
// 1 million bytes (about 1megabyte)
header('Content-Length: 1000000');
// load a download dialogue, and save it as download.zip
header('Content-Disposition: attachment; filename="download.zip"');
// 1000 times 1000 bytes of data
for ($i = 0; $i < 1000; $i++) {
echo str_repeat(".",1000);
// sleep to slow down the download
usleep(50000);
}结果将会是这样的:
现在,我将Content-Length头部注释掉:
// it's a zip file
header('Content-Type: application/zip');
// the browser won't know the size
// header('Content-Length: 1000000');
// load a download dialogue, and save it as download.zip
header('Content-Disposition: attachment; filename="download.zip"');
// 1000 times 1000 bytes of data
for ($i = 0; $i < 1000; $i++) {
echo str_repeat(".",1000);
// sleep to slow down the download
usleep(50000);
}结果就变成了这样:
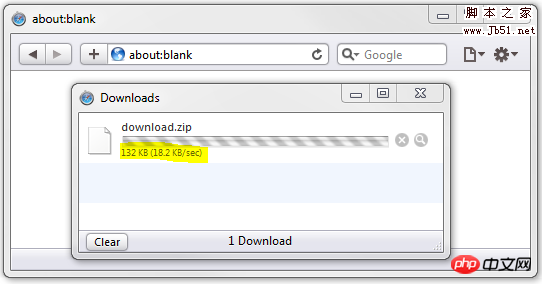
这个浏览器只会告诉你已下载了多少,但不会告诉你总共需要下载多少。而且进度条也不会显示进度。
Etag
这是另一个为缓存而产生的头部信息。它看起来会是这样:
<span style="max-width:90%">Etag: "pub1259380237;gz"</span>
服务器可能会将该信息和每个被发送文件一起响应给浏览器。该值可以包含文档的最后修改日期,文件大小或者文件校验和。浏览会把它和所接收到的文档一起缓存。下一次当浏览器再次请求同一文件时将会发送如下的HTTP请求:
<span style="font-family:NSimsun">If-None-Match: "pub1259380237;gz"</span>
如果所请求的文档Etag值和它一致,服务器将会发送304状态码,而不是2oo。并且不返回内容。浏览器此时就会从缓存加载该文件。
Last-Modified
顾名思义,这个头部信息用GMT格式表明了文档的最后修改时间:
<span style="font-family:NSimsun">Last-Modified: Sat, 28 Nov 2009 03:50:37 GMT</span>
<span style="font-family:NSimsun">$modify_time = filemtime($file);<br/>header("Last-Modified: " . gmdate("D, d M Y H:i:s", $modify_time) . " GMT");</span>
它提供了另一种缓存机制。浏览器可能会发送这样的请求:
<span style="font-family:NSimsun">If-Modified-Since: Sat, 28 Nov 2009 06:38:19 GMT</span>
在If-Modified-Since一节我们已经讨论过了。
Location
这个头部是用来重定向的。如果响应代码为 301 或者 302 ,服务器就必须发送该头部。例如,当你访问 www.nettuts.com 时浏览器就会收到如下的响应:
<span style="font-family:NSimsun">HTTP/1.x 301 Moved Permanently<br/>...<br/>Location: http://net.tutsplus.com/<br/>...</span>
在PHP中你可以通过这种方式对访客重定向:<span style="font-family:NSimsun">header('Location: http://net.tutsplus.com/');</span>
默认会发送302状态码,如果你想发送301,就这样写:
<span style="font-family:NSimsun">header('Location: http://net.tutsplus.com/', true, 301);</span>
Set-Cookie
当一个网站需要设置或者更新你浏览的cookie信息时,它就会使用这样的头部:
<span style="font-family:NSimsun">Set-Cookie: skin=noskin; path=/; domain=.amazon.com; expires=Sun, 29-Nov-2009 21:42:28 GMT<br/>Set-Cookie: session-id=120-7333518-8165026; path=/; domain=.amazon.com; expires=Sat Feb 27 08:00:00 2010 GMT</span>
每个cookie会作为单独的一条头部信息。注意,通过js设置cookie将不会体现在HTTP头中。
在PHP中,你可以通过setcookie()函数来设置cookie,PHP会发送合适的HTTP 头。
<span style="font-family:NSimsun">setcookie("TestCookie", "foobar");</span>
它会发送这样的头信息:
<span style="font-family:NSimsun">Set-Cookie: TestCookie=foobar</span>
如果未指定到期时间,cookie就会在浏览器关闭后被删除。
WWW-Authenticate
一个网站可能会通过HTTP发送这个头部信息来验证用户。当浏览器看到头部有这个响应时就会打开一个弹出窗。
<span style="font-family:NSimsun">WWW-Authenticate: Basic realm="Restricted Area"</span>
它会看起来像这样:
在PHP手册的一章中就有一段简单的代码演示了如果用PHP做这样的事情:
if (!isset($_SERVER['PHP_AUTH_USER'])) {
header('WWW-Authenticate: Basic realm="My Realm"');
header('HTTP/1.0 Graphical explanation of HTTP Headers knowledge points Unauthorized');
echo 'Text to send if user hits Cancel button';
exit;
} else {
echo "<p>Hello {$_SERVER['PHP_AUTH_USER']}.</p>";
echo "<p>You entered {$_SERVER['PHP_AUTH_PW']} as your password.</p>";
}Content-Encoding
这个头部通常会在返回内容被压缩时设置。
<span style="font-family:NSimsun">Content-Encoding: gzip</span>
在PHP中,如果你调用了ob_gzhandler()函数,这个头部将会自动被设置。
【相关推荐】
1. HTML免费视频教程
2. Tutorial on using hyperlink tags in XHTML
3. Tutorial on using hyperlink tags in XHTML
4. Introduction to how to display JSON data in html
5. htmlDetailed example of implementing the quantity subscript on the message button
The above is the detailed content of Graphical explanation of HTTP Headers knowledge points. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1266
29
1239
24
14
1422
52
1316
25
1266
29
1239
24

 What does http status code 520 mean?
Oct 13, 2023 pm 03:11 PM
What does http status code 520 mean?
Oct 13, 2023 pm 03:11 PM
HTTP status code 520 means that the server encountered an unknown error while processing the request and cannot provide more specific information. Used to indicate that an unknown error occurred when the server was processing the request, which may be caused by server configuration problems, network problems, or other unknown reasons. This is usually caused by server configuration issues, network issues, server overload, or coding errors. If you encounter a status code 520 error, it is best to contact the website administrator or technical support team for more information and assistance.
 What is http status code 403?
Oct 07, 2023 pm 02:04 PM
What is http status code 403?
Oct 07, 2023 pm 02:04 PM
HTTP status code 403 means that the server rejected the client's request. The solution to http status code 403 is: 1. Check the authentication credentials. If the server requires authentication, ensure that the correct credentials are provided; 2. Check the IP address restrictions. If the server has restricted the IP address, ensure that the client's IP address is restricted. Whitelisted or not blacklisted; 3. Check the file permission settings. If the 403 status code is related to the permission settings of the file or directory, ensure that the client has sufficient permissions to access these files or directories, etc.
 Understand common application scenarios of web page redirection and understand the HTTP 301 status code
Feb 18, 2024 pm 08:41 PM
Understand common application scenarios of web page redirection and understand the HTTP 301 status code
Feb 18, 2024 pm 08:41 PM
Understand the meaning of HTTP 301 status code: common application scenarios of web page redirection. With the rapid development of the Internet, people's requirements for web page interaction are becoming higher and higher. In the field of web design, web page redirection is a common and important technology, implemented through the HTTP 301 status code. This article will explore the meaning of HTTP 301 status code and common application scenarios in web page redirection. HTTP301 status code refers to permanent redirect (PermanentRedirect). When the server receives the client's
 HTTP 200 OK: Understand the meaning and purpose of a successful response
Dec 26, 2023 am 10:25 AM
HTTP 200 OK: Understand the meaning and purpose of a successful response
Dec 26, 2023 am 10:25 AM
HTTP Status Code 200: Explore the Meaning and Purpose of Successful Responses HTTP status codes are numeric codes used to indicate the status of a server's response. Among them, status code 200 indicates that the request has been successfully processed by the server. This article will explore the specific meaning and use of HTTP status code 200. First, let us understand the classification of HTTP status codes. Status codes are divided into five categories, namely 1xx, 2xx, 3xx, 4xx and 5xx. Among them, 2xx indicates a successful response. And 200 is the most common status code in 2xx
 How to use Nginx Proxy Manager to implement automatic jump from HTTP to HTTPS
Sep 26, 2023 am 11:19 AM
How to use Nginx Proxy Manager to implement automatic jump from HTTP to HTTPS
Sep 26, 2023 am 11:19 AM
How to use NginxProxyManager to implement automatic jump from HTTP to HTTPS. With the development of the Internet, more and more websites are beginning to use the HTTPS protocol to encrypt data transmission to improve data security and user privacy protection. Since the HTTPS protocol requires the support of an SSL certificate, certain technical support is required when deploying the HTTPS protocol. Nginx is a powerful and commonly used HTTP server and reverse proxy server, and NginxProxy
 Send POST request with form data using http.PostForm function
Jul 25, 2023 pm 10:51 PM
Send POST request with form data using http.PostForm function
Jul 25, 2023 pm 10:51 PM
Use the http.PostForm function to send a POST request with form data. In the http package of the Go language, you can use the http.PostForm function to send a POST request with form data. The prototype of the http.PostForm function is as follows: funcPostForm(urlstring,dataurl.Values)(resp*http.Response,errerror)where, u
 Quick Application: Practical Development Case Analysis of PHP Asynchronous HTTP Download of Multiple Files
Sep 12, 2023 pm 01:15 PM
Quick Application: Practical Development Case Analysis of PHP Asynchronous HTTP Download of Multiple Files
Sep 12, 2023 pm 01:15 PM
Quick Application: Practical Development Case Analysis of PHP Asynchronous HTTP Download of Multiple Files With the development of the Internet, the file download function has become one of the basic needs of many websites and applications. For scenarios where multiple files need to be downloaded at the same time, the traditional synchronous download method is often inefficient and time-consuming. For this reason, using PHP to download multiple files asynchronously over HTTP has become an increasingly common solution. This article will analyze in detail how to use PHP asynchronous HTTP through an actual development case.
 http request 415 error solution
Nov 14, 2023 am 10:49 AM
http request 415 error solution
Nov 14, 2023 am 10:49 AM
Solution: 1. Check the Content-Type in the request header; 2. Check the data format in the request body; 3. Use the appropriate encoding format; 4. Use the appropriate request method; 5. Check the server-side support.
