
fs.createReadStream('file.json').pipe(request.put('http://mysite.com/obj.json'))request.get('http://google.com/img.png').pipe(request.put('http://mysite.com/img.png'))request.get('http://some.server.com/').auth('username', 'password', false);
Teach you how to parse html under nodejs

Parsing of html in the nodejs environment
In the nodejs environment, obtain/parse/parse the data of the sister picture website and use express to json the client Return of data.
This article mainly solves: 1. The problem of how to parse the requested HTML with jquery; 2. The problem of alternative function libraries for heavy users of jquery in the nodejs environment; 3. The problem of how to send ajax requests under nodejs (ajax request, itself is a request request); 4. This article uses actual cases to introduce how to use cheerio to perform DOM operations.
Users need to install the npm module: cheerio
It is also recommended to use the npm module: nodemon, which can hot deploy nodejs programs
Introduction
WeChat Mini Program Platform The basic requirements are:
1. The data server must be a service interface of https protocol
2. The WeChat applet is not html5 and does not support dom parsing and window operations
3. The test version can use third-party data service interfaces, but the official version does not allow the use of third-party interfaces (of course, here we are talking about multiple third-party data interfaces).
Under the APICLOUD platform, we can use html5 with jquery and other class libraries to realize the parsing of dom data to solve the problem that the data source is not in json format ( Use jquery to load data in html5 under html, and go back and sort out the test app I made when I was learning the apicloud platform API), but under the WeChat mini program platform, there is basically no way to parse the html element . Before writing this article, I saw some answers on the Internet about using underscore instead of jquery for DOM analysis. I worked on it for a long time and found that it was still not that smooth.
Therefore, the solution proposed in this article is to solve two problems:
1. Use your own server to provide your own WeChat applet with HTML data conversion services from third-party websites, and convert the third-party HTML The elements parse out the elements they need. Under the nodejs platform, use the request module to complete the data request, and use the cheerio module to complete the html parsing.
2. Under the nodejs platform, although there is a jquery module, there are still many problems in using it. There is a post on the Internet that was copied by a website, giving a method of using jquery in a nodejs environment. After my actual test, I found that it was not possible to start writing code smoothly.
Therefore, the writing ideas of this article: 1. Analyze the data source; 2. Briefly introduce request; 3. Common methods of cheerio module A brief introduction; 4. Written under nodejs, using the express module to provide json data.
Data source analysis
Data list analysis
According to the routines of most programs, operations on third-party data sources are mostly crawler cases, so the case in this article should be the same It’s a blessing for homeboys. The target address of this article is: http://m.mmjpg.com.
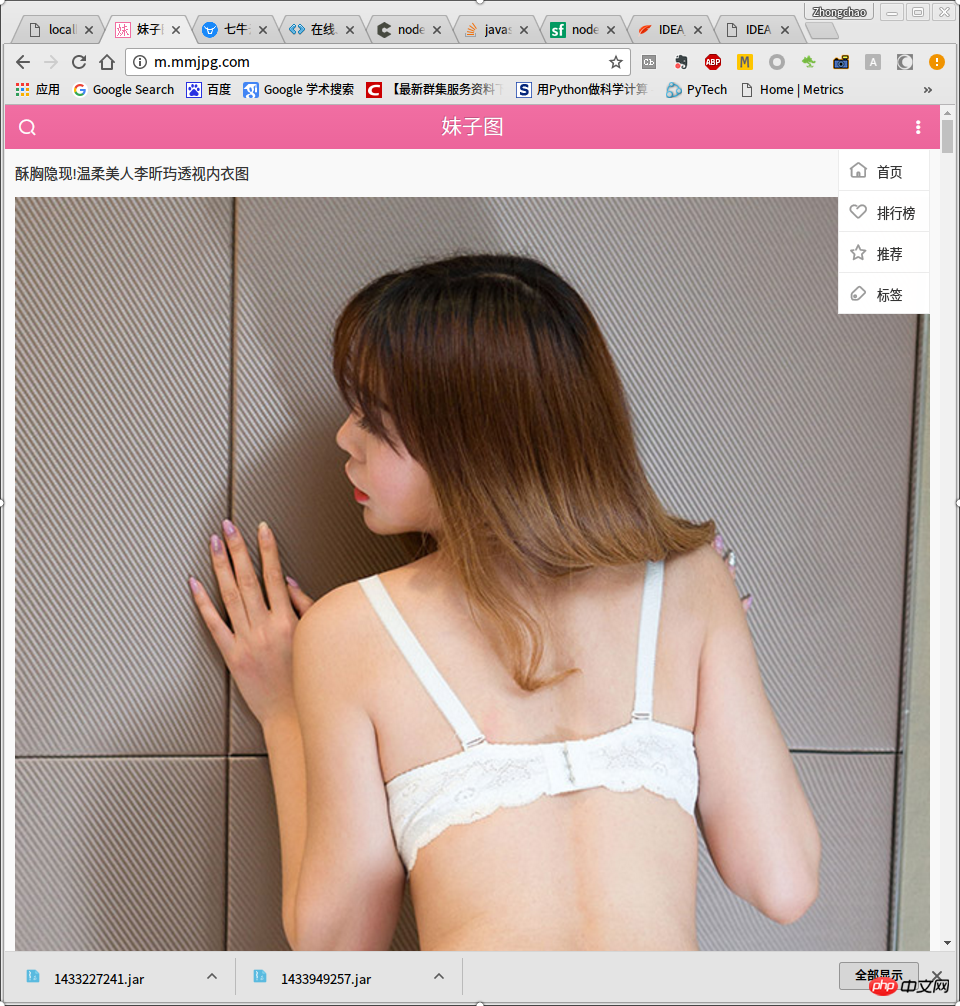
rankingpage. The ranking page looks like this, 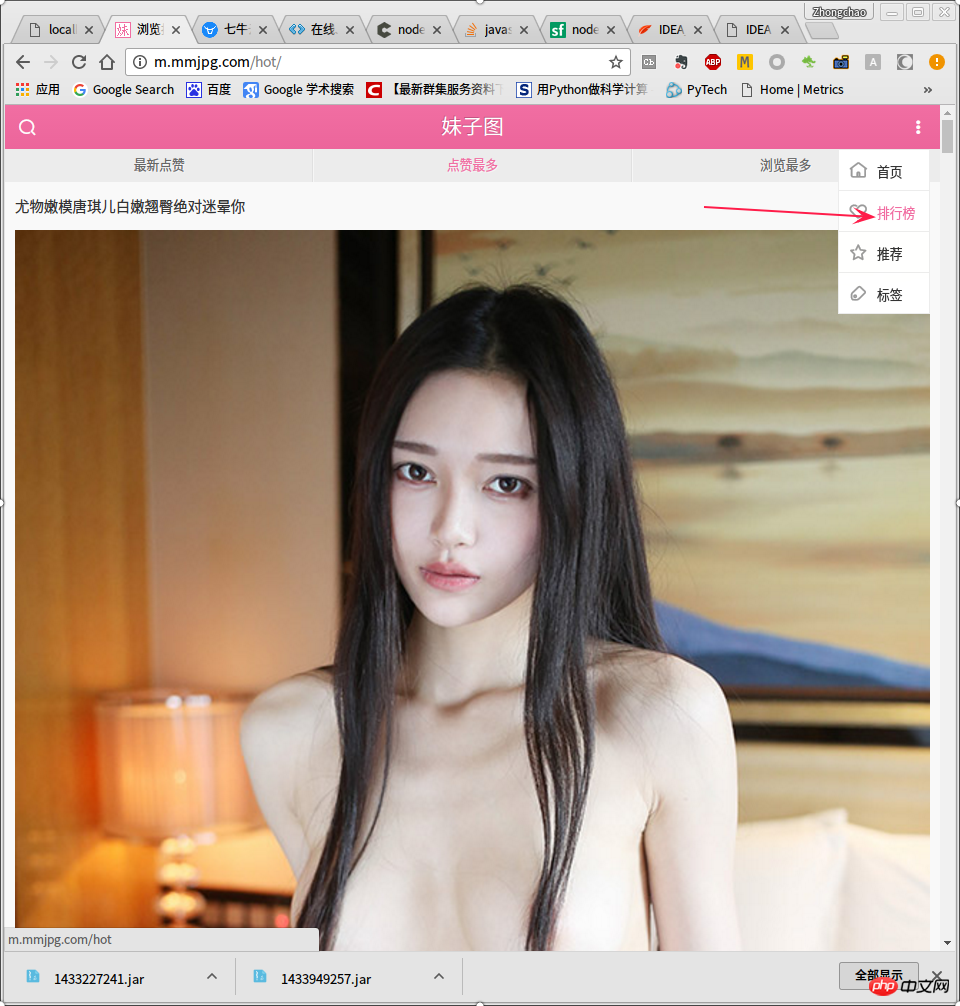
Load more button , after clicking to load more, in the browser console, you can see that the browser sent a url for http://m.mmjpg.com/getmore.php ?te=1&page=3 request. 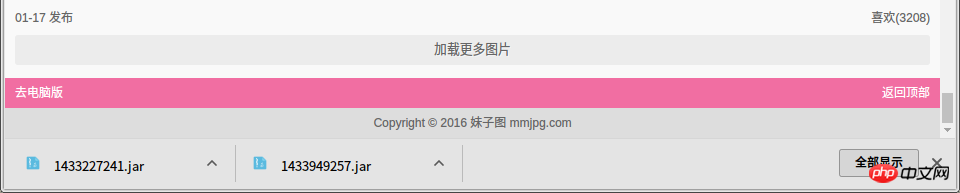
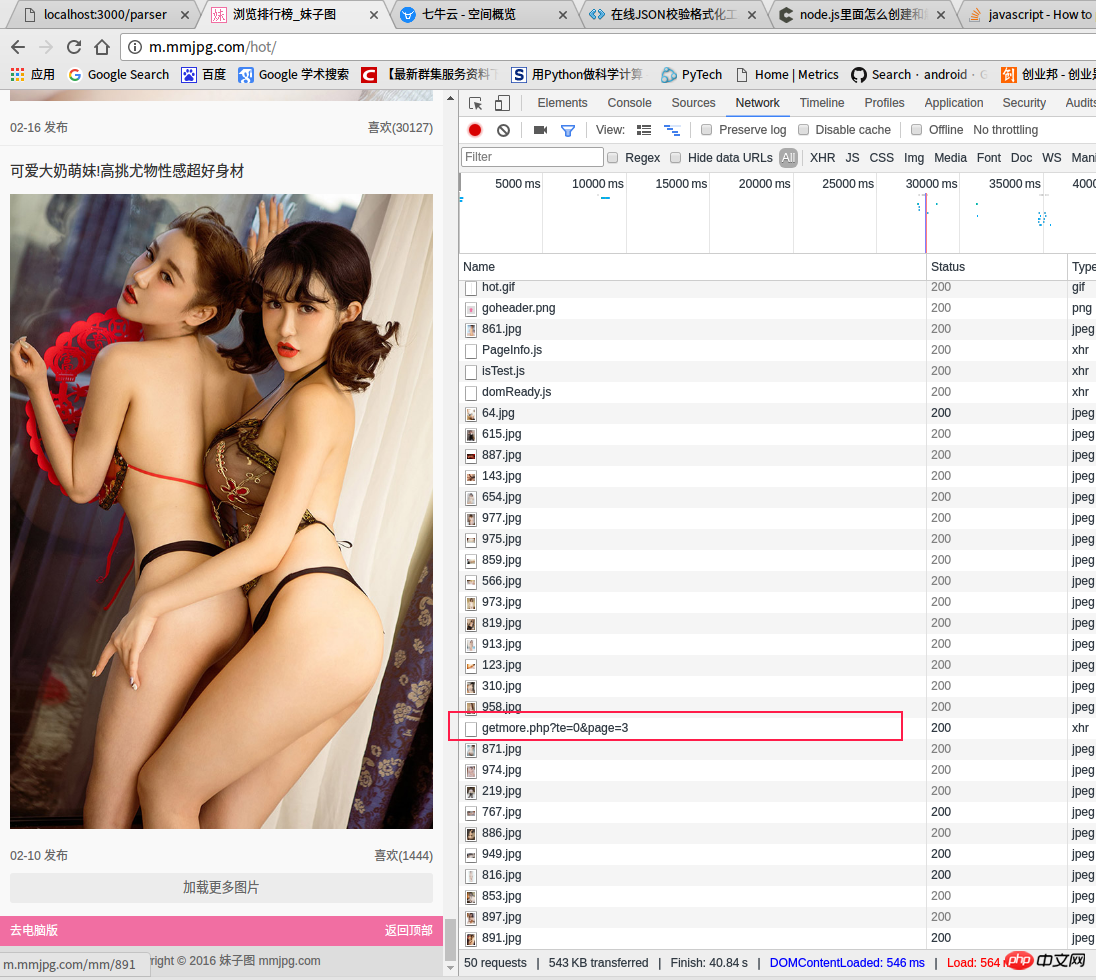 We can Use a browser to open the above link (
We can Use a browser to open the above link (
http://m.mmjpg.com/getmore.php?te=1&page=3). This is what I browsed when I visited this link while writing this article. Real-time data obtained by the browser (readers may get different data from mine when accessing the browser). In the picture below, I have marked the data in the page source code, including the following content: 1. Title; 2. Browsing address of all
pictures; 3. Preview image address; 4. Release time; 5. Number of likes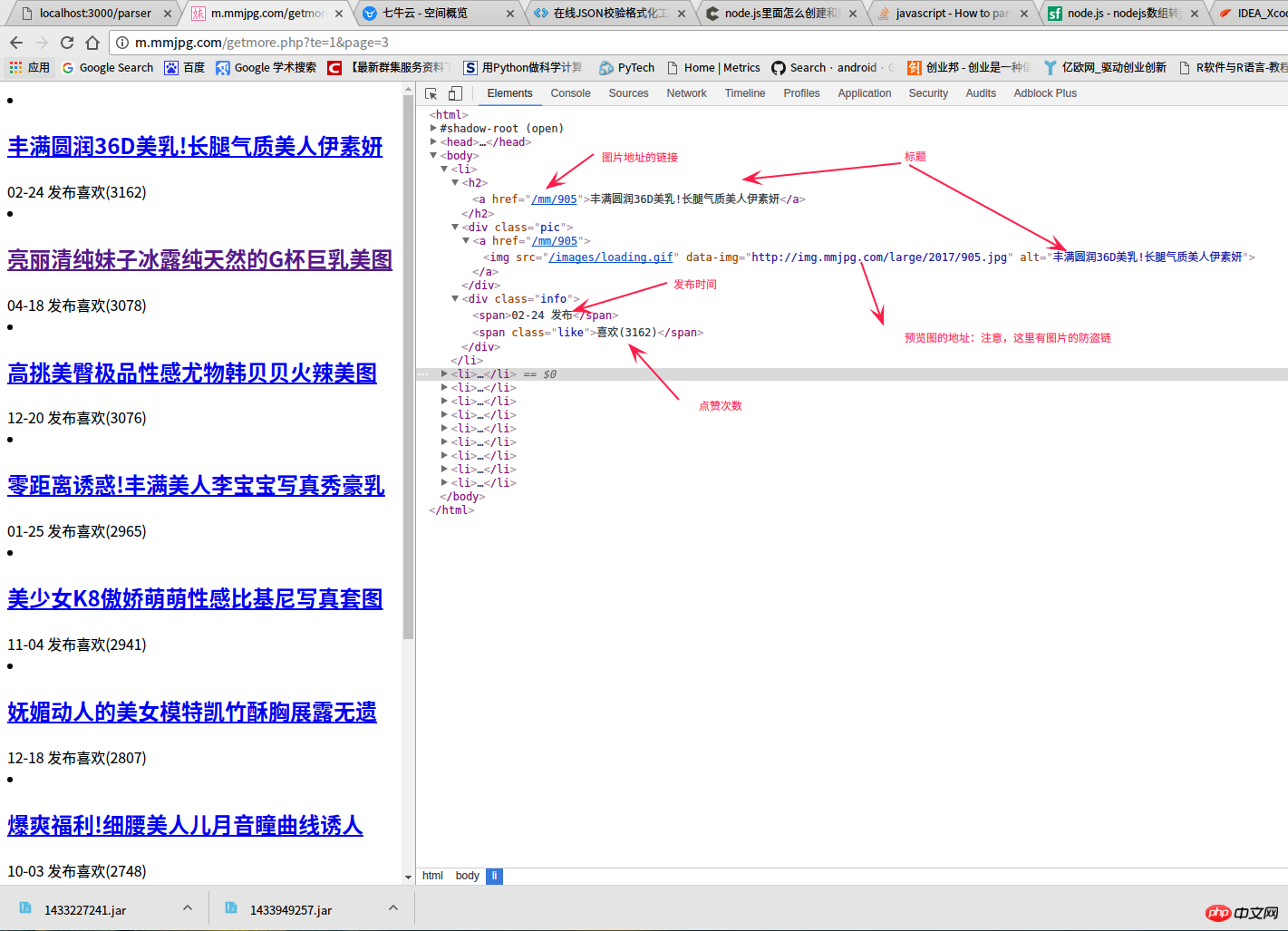
Analysis of data details page
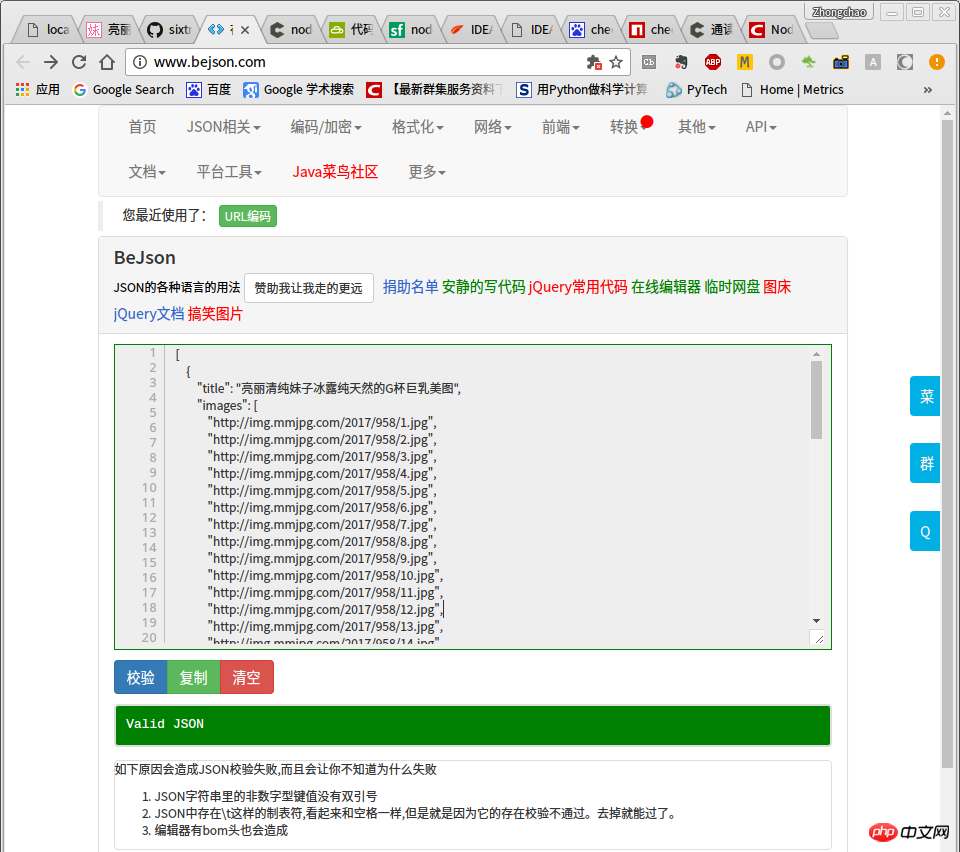
When we accessed to load more pages above, we obtained the page of page=3 list and clicked the following linkhttp://m.mmjpg .com/mm/958, the corresponding title is Beautiful and pure girl’s natural G-cup big breasts pictures.
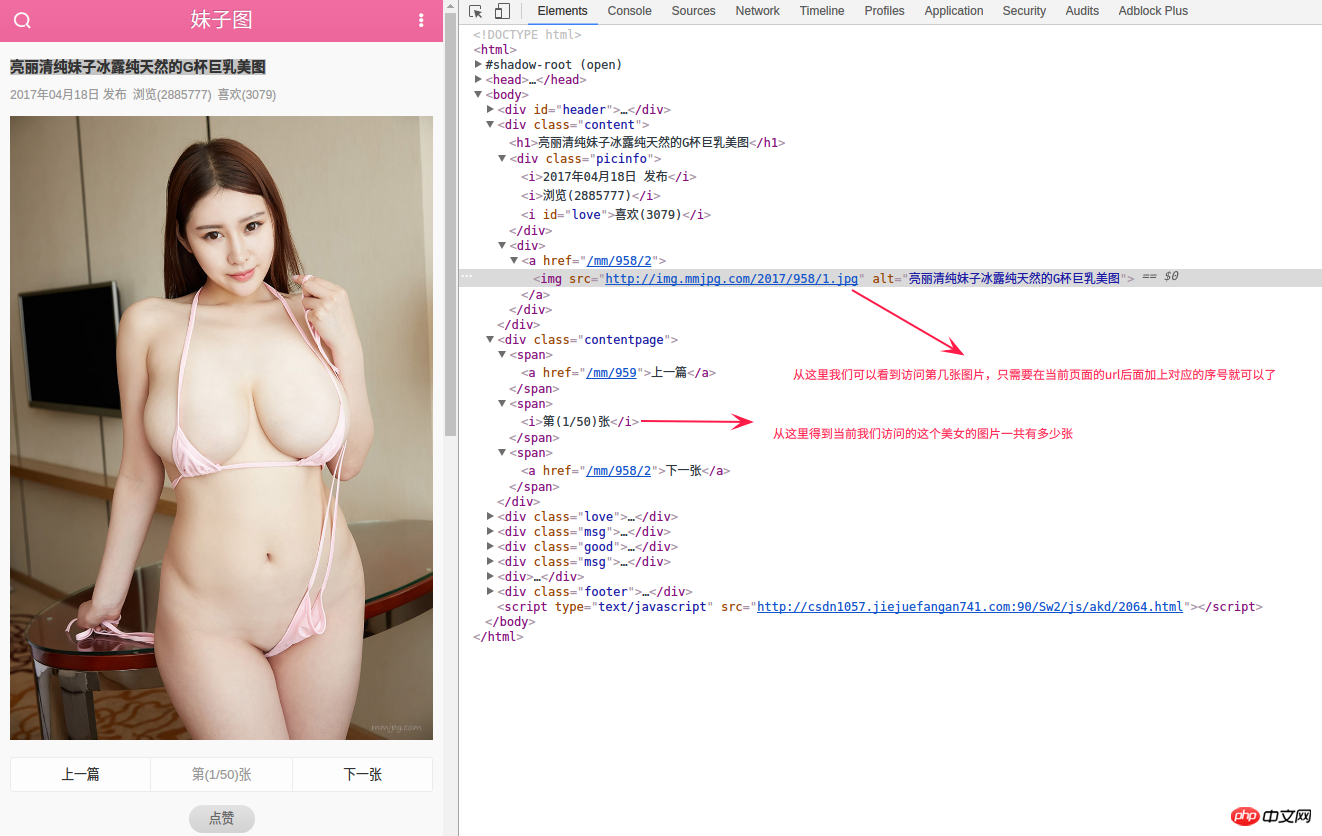
From the above picture, you can see that each http://m.mmjpg.com/mm/958/<a href="http://www.php.cn/wiki/58.html" target="_blank">array</a> There is a picture on the page with serial number , and the address of this picture is also very standardized, which is http://img.mmjpg.com/2017/958/1.jpg. The next thing is very simple. We only need to know how many pictures there are in the current picture collection, and then we can splice the addresses of all pictures according to the rules. Here, to obtain the data of the details page, we only need to obtain the data of the first picture page. The main data obtained is the src of the first img tag under the p of (1/N) and class is content That's it.
request module makes http requests simpler.
var request = require('request');
request('http://www.google.com', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body);
}
})Copy after login
Catch images from the Internet and save them locally var request = require('request');
request('http://www.google.com', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body);
}
})var fs=require('fs');var request=require('request');
request('http://n.sinaimg.cn/news/transform/20170211/F57R-fyamvns4810245.jpg').pipe(fs.createWriteStream('doodle.png'));
Copy after login
Upload the local file.json file to mysite.com/obj. jsonvar fs=require('fs');var request=require('request'); request('http://n.sinaimg.cn/news/transform/20170211/F57R-fyamvns4810245.jpg').pipe(fs.createWriteStream('doodle.png'));
fs.createReadStream('file.json').pipe(request.put('http://mysite.com/obj.json'))
Copy after login
Upload google.com/img.png to mysite.com/img.pngfs.createReadStream('file.json').pipe(request.put('http://mysite.com/obj.json'))
request.get('http://google.com/img.png').pipe(request.put('http://mysite.com/img.png'))
Copy after login
Submit the form to service.com/uploadrequest.get('http://google.com/img.png').pipe(request.put('http://mysite.com/img.png'))
var r = request.post('http://service.com/upload')var form = r.form()
form.append('my_field', 'my_value')
form.append('my_buffer', new Buffer([1, 2, 3]))
form.append('my_file', fs.createReadStream(path.join(dirname, 'doodle.png'))
form.append('remote_file', request('http://google.com/doodle.png'))
Copy after login
HTTP authenticationvar r = request.post('http://service.com/upload')var form = r.form() form.append('my_field', 'my_value') form.append('my_buffer', new Buffer([1, 2, 3])) form.append('my_file', fs.createReadStream(path.join(dirname, 'doodle.png')) form.append('remote_file', request('http://google.com/doodle.png'))
request.get('http://some.server.com/').auth('username', 'password', false);
Copy after login
Customized HTTP headerrequest.get('http://some.server.com/').auth('username', 'password', false);
//User-Agent之类可以在options对象中设置。var options = {
url: 'https://api.github.com/repos/mikeal/request',
headers: { 'User-Agent': 'request'
}
};function callback(error, response, body) {
if (!error && response.statusCode == 200) { var info = JSON.parse(body);
console.log(info.stargazers_count +"Stars");
console.log(info.forks_count +"Forks");
}
}
request(options, callback);Copy after login
Cheerio module introductioncheerio is a fast, flexible and implemented jQuery core implementation specially customized for the server.//User-Agent之类可以在options对象中设置。var options = {
url: 'https://api.github.com/repos/mikeal/request',
headers: { 'User-Agent': 'request'
}
};function callback(error, response, body) {
if (!error && response.statusCode == 200) { var info = JSON.parse(body);
console.log(info.stargazers_count +"Stars");
console.log(info.forks_count +"Forks");
}
}
request(options, callback);Cheerio is supported under the npm official website Introduction to the module:www.npmjs.com/package/cheerio
cnodejs.org/topic/5203a71844e76d216a727d2e
const cheerio = require('cheerio');To load the cheerio module in this way, use our html source string as a parameter and use the load function of cheerio If loaded, we can completely follow the programming ideas in the jquery environment to realize the parsing of the dom.
cheerio module implements most of the jquery functions, this article will not introduce too much here.
json, but html, For jquery, html should set dataType to text when sending an ajax request.
1. Use ajax request, pass in url and set dataType
2. Use
$(data) to ajaxThe obtained data is converted into a jquery object. 3. Use the
find and get methods of jquery to find the element you need to obtain. 4. Use the
attr and html methods of jquery to obtain the required information. 5. Integrate the above information into a json string or perform
dom operations on your html before to complete the data loading.
1. Use requets to request, pass in the url and set the dataType
2. Use
cheerio.load(body) to request The obtained data is converted into a cheerio object. 3. Use the
find and get methods of cheerio to find the element you need to obtain. 4. Use the
attr and text methods of cheerio to obtain the required information. 5. Integrate the above information into a json string, and use
express's res.json to respond json to the client (mini program or other APP).
var express = require('express');var router = express.Router();var bodyParser = require("body-parser");var http = require('http');const cheerio = require('cheerio');/* GET home page. */router.get('/', function (req, res, next) {
res.render('index', {title: 'Express'});
});/* GET 妹子图列表 page. */router.get('/parser', function (req, res, next) {
var json =new Array(); var url = `http://m.mmjpg.com/getmore.php?te=0&page=3`;
var request = require('request');
request(url, function (error, response, body) { if (!error && response.statusCode == 200) { var $ = cheerio.load( body );//将响应的html转换成cheerio对象
var $lis = $('li');//便利列表页的所有的li标签,每个li标签对应的是一条信息
var json = new Array();//需要返回的json数组
var index = 0;
$lis.each(function () {
var h2 = $(this).find("h2");//获取h2标签,方便获取h2标签里的a标签
var a = $(h2).find("a");//获取a标签,是为了得到href和标题
var img = $(this).find("img");//获取预览图
var info =$($($(this).find(".info")).find("span")).get(0);//获取发布时间
var like = $(this).find(".like");//获取点赞次数
//生成json数组
json[index] = new Array({"title":$(a).text(),"href":$(a).attr("href"),"image":$(img).attr("data-img"),"timer":$(info).text(),"like":$(like).text()});
index++;
}) //设置响应头
res.header("contentType", "application/json"); //返回json数据
res.json(json);
}
});
})
;/**
* 从第(1/50)张这样的字符串中提取50出来
* @param $str
* @returns {string}
*/function getNumberFromString($str) {
var start = $str.indexOf("/"); var end = $str.indexOf(")"); return $str.substring(start+1,end);
}/* GET 妹子图所有图片 page. */router.get('/details', function (req, res, next) {
var json; var url = `http://m.mmjpg.com/mm/958`;
var request = require('request');
request(url, function (error, response, body) {
if (!error && response.statusCode == 200) { var $ = cheerio.load( body );//将响应的html转换成cheerio对象
var json = new Array();//需要返回的json数组
var index = 0; var img = $($(".content").find("a")).find("img");//每一次操作之后得到的对象都用转换成cheerio对象的
var imgSrc = $(img).attr("src");//获取第一张图片的地址
var title = $(img).attr("alt");//获取图片集的标题
var total =$($(".contentpage").find("span").get(1)).text();//获取‘第(1/50)张’
total = getNumberFromString(total);//从例如`第(1/50)张`提取出50来
var imgPre = imgSrc.substring(0,imgSrc.lastIndexOf("/")+1);//获取图片的地址的前缀
var imgFix = imgSrc.substring(imgSrc.lastIndexOf("."));//获取图片的格式后缀名
console.log(imgPre + "\t" + imgFix); //生成json数组
var images= new Array(); for(var i=1;i<=total;i++) {
images[i-1] =imgPre+i+imgFix;
}
json = new Array({"title":title,"images":images}); //设置响应头
res.header("contentType", "application/json"); //返回json数据
res.json(json);
}
});
})
;
module.exports = router;Copy after login
While browsing, get the json of the list page, the screenshot is as follows: var express = require('express');var router = express.Router();var bodyParser = require("body-parser");var http = require('http');const cheerio = require('cheerio');/* GET home page. */router.get('/', function (req, res, next) {
res.render('index', {title: 'Express'});
});/* GET 妹子图列表 page. */router.get('/parser', function (req, res, next) {
var json =new Array(); var url = `http://m.mmjpg.com/getmore.php?te=0&page=3`;
var request = require('request');
request(url, function (error, response, body) { if (!error && response.statusCode == 200) { var $ = cheerio.load( body );//将响应的html转换成cheerio对象
var $lis = $('li');//便利列表页的所有的li标签,每个li标签对应的是一条信息
var json = new Array();//需要返回的json数组
var index = 0;
$lis.each(function () {
var h2 = $(this).find("h2");//获取h2标签,方便获取h2标签里的a标签
var a = $(h2).find("a");//获取a标签,是为了得到href和标题
var img = $(this).find("img");//获取预览图
var info =$($($(this).find(".info")).find("span")).get(0);//获取发布时间
var like = $(this).find(".like");//获取点赞次数
//生成json数组
json[index] = new Array({"title":$(a).text(),"href":$(a).attr("href"),"image":$(img).attr("data-img"),"timer":$(info).text(),"like":$(like).text()});
index++;
}) //设置响应头
res.header("contentType", "application/json"); //返回json数据
res.json(json);
}
});
})
;/**
* 从第(1/50)张这样的字符串中提取50出来
* @param $str
* @returns {string}
*/function getNumberFromString($str) {
var start = $str.indexOf("/"); var end = $str.indexOf(")"); return $str.substring(start+1,end);
}/* GET 妹子图所有图片 page. */router.get('/details', function (req, res, next) {
var json; var url = `http://m.mmjpg.com/mm/958`;
var request = require('request');
request(url, function (error, response, body) {
if (!error && response.statusCode == 200) { var $ = cheerio.load( body );//将响应的html转换成cheerio对象
var json = new Array();//需要返回的json数组
var index = 0; var img = $($(".content").find("a")).find("img");//每一次操作之后得到的对象都用转换成cheerio对象的
var imgSrc = $(img).attr("src");//获取第一张图片的地址
var title = $(img).attr("alt");//获取图片集的标题
var total =$($(".contentpage").find("span").get(1)).text();//获取‘第(1/50)张’
total = getNumberFromString(total);//从例如`第(1/50)张`提取出50来
var imgPre = imgSrc.substring(0,imgSrc.lastIndexOf("/")+1);//获取图片的地址的前缀
var imgFix = imgSrc.substring(imgSrc.lastIndexOf("."));//获取图片的格式后缀名
console.log(imgPre + "\t" + imgFix); //生成json数组
var images= new Array(); for(var i=1;i<=total;i++) {
images[i-1] =imgPre+i+imgFix;
}
json = new Array({"title":title,"images":images}); //设置响应头
res.header("contentType", "application/json"); //返回json数据
res.json(json);
}
});
})
;
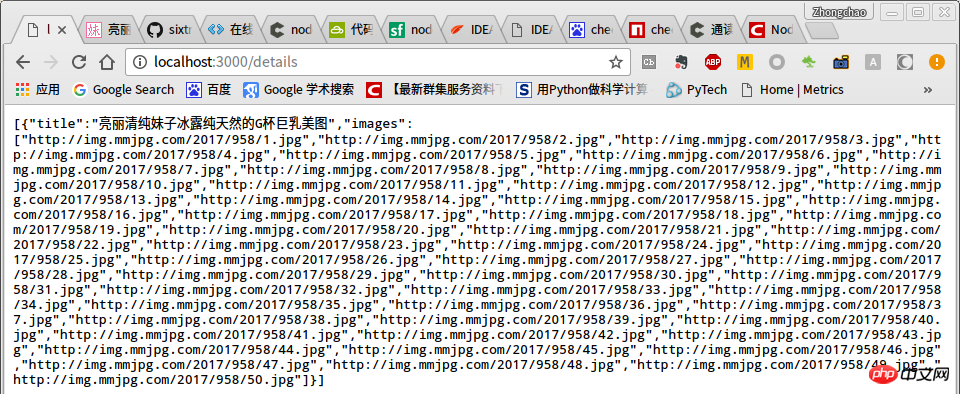
module.exports = router;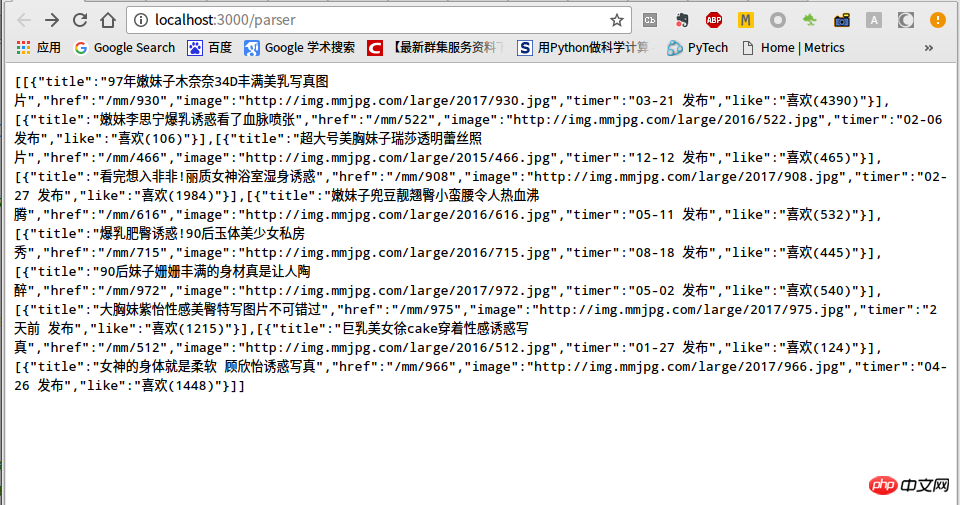
apicloud平台下利用jquery实现的代码
//获取妹子图的列表function loadData() {
url = 'http://m.mmjpg.com/getmore.php';
$.ajax({
url: tmpurl,
method: 'get',
dataType: "application/text",
data:{
te:0,
page:3
},
success: function (data) {
if (data) {
ret = "<ul>" + ret + "</ul>"; var lis = $(ret).find("li"); var one = '';
$(lis).each(function () {
var a = $(this).find("h2 a"); var ahtml = $(a).html();//标题
var ahref = $(a).attr('href');//链接
var info = $(this).find(".info"); var date = $($(info).find("span").get(0)).html(); var like = $($(info).find(".like")).html(); var img = $(this).find("img").get(0); var imgsrc = $(img).attr('data-img'); //接下来,决定如何对数据进行显示咯。如dom操作,直接显示。
});
} else {
alert("数据加载失败,请重试");
}
}
});
};//end of loadData//图片详情页的获取,就不再提供jquery版本的代码了总结
本文主要解决了:1.jquery解析请求过来的html如何实现的问题;2.nodejs环境下jquery重度使用者的替代函数库的问题;3.nodejs下,如何发送ajax请求的问题(ajax请求,本身就是一个request请求);4. 本文用实际的案例来介绍了如何使用cheerio进行dom操作。
【相关推荐】
1. HTML免费视频教程
The above is the detailed content of Teach you how to parse html under nodejs. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1657
1657
 14
1415
52
1309
25
1257
29
1230
24
14
1415
52
1309
25
1257
29
1230
24

 Table Border in HTML
Sep 04, 2024 pm 04:49 PM
Table Border in HTML
Sep 04, 2024 pm 04:49 PM
Guide to Table Border in HTML. Here we discuss multiple ways for defining table-border with examples of the Table Border in HTML.
 HTML margin-left
Sep 04, 2024 pm 04:48 PM
HTML margin-left
Sep 04, 2024 pm 04:48 PM
Guide to HTML margin-left. Here we discuss a brief overview on HTML margin-left and its Examples along with its Code Implementation.
 Nested Table in HTML
Sep 04, 2024 pm 04:49 PM
Nested Table in HTML
Sep 04, 2024 pm 04:49 PM
This is a guide to Nested Table in HTML. Here we discuss how to create a table within the table along with the respective examples.
 HTML Table Layout
Sep 04, 2024 pm 04:54 PM
HTML Table Layout
Sep 04, 2024 pm 04:54 PM
Guide to HTML Table Layout. Here we discuss the Values of HTML Table Layout along with the examples and outputs n detail.
 HTML Input Placeholder
Sep 04, 2024 pm 04:54 PM
HTML Input Placeholder
Sep 04, 2024 pm 04:54 PM
Guide to HTML Input Placeholder. Here we discuss the Examples of HTML Input Placeholder along with the codes and outputs.
 HTML Ordered List
Sep 04, 2024 pm 04:43 PM
HTML Ordered List
Sep 04, 2024 pm 04:43 PM
Guide to the HTML Ordered List. Here we also discuss introduction of HTML Ordered list and types along with their example respectively
 How do you parse and process HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
How do you parse and process HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
This tutorial demonstrates how to efficiently process XML documents using PHP. XML (eXtensible Markup Language) is a versatile text-based markup language designed for both human readability and machine parsing. It's commonly used for data storage an
 HTML onclick Button
Sep 04, 2024 pm 04:49 PM
HTML onclick Button
Sep 04, 2024 pm 04:49 PM
Guide to HTML onclick Button. Here we discuss their introduction, working, examples and onclick Event in various events respectively.
