

If you have read the previous information about HashSet and HashMap, as well as TreeSet and TreeMap For the explanation, you must be able to think that LinkedHashSet and LinkedHashMap that will be explained in this article are actually the same thing. LinkedHashSet and LinkedHashMap also have the same implementation in Java. The former just wraps the latter, that is to say, inside LinkedHashSet There is a LinkedHashMap (Adapter Pattern). Therefore, this article will focus on analyzing LinkedHashMap.
LinkedHashMap implements the Map interface, which allows elements with key to be null and also allows insertion of value is an element of null. It can be seen from the name that the container is a mixture of linked list and HashMap, which means that it satisfies both HashMap and # Some features of ##linked list. Think of LinkedHashMap as HashMap enhanced with linked list.
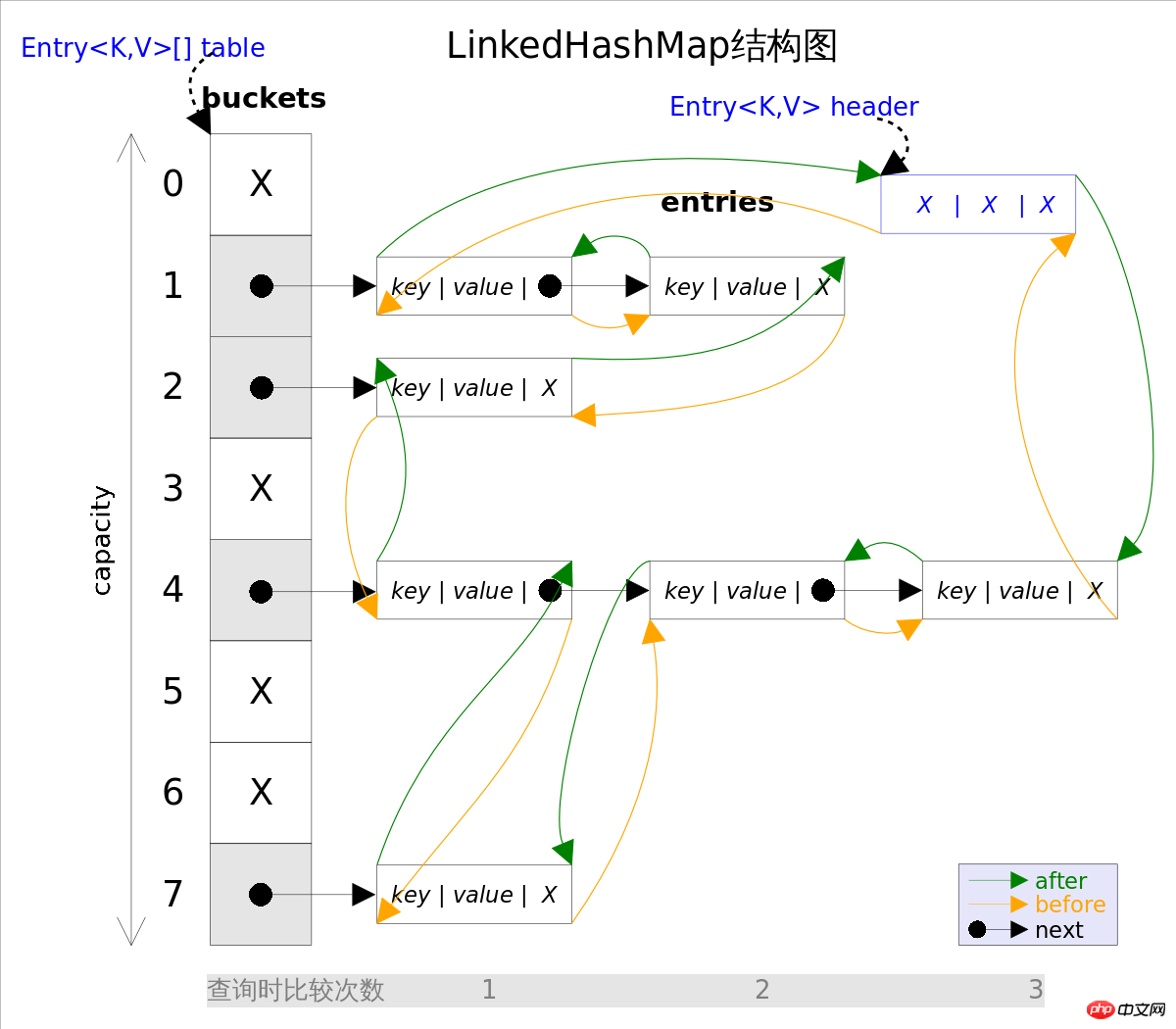
LinkedHashMap is a direct subclass of HashMap, The only difference between the two isLinkedHashMap Based on HashMap, all entry are connected in the form of a doubly-linked list. This is to ensure that the iteration sequence of the elements follows The insertion order is the same . The above figure shows the structure diagram of LinkedHashMap. The main part is exactly the same as HashMap, with the addition of header pointing to the head of the doubly linked list (which is a dummy element) , The iteration order of the doubly linked list is the insertion order of entry.
When iterating LinkedHashMap, there is no need to traverse the entire table like HashMap , and you only need to directly traverse the doubly linked list pointed to by header, that is to say, the iteration time of LinkedHashMap is only the same as that of entry It is related to the number and has nothing to do with the size of table.
LinkedHashMap: initial capacity (initial capacity) and load factor (load factor). The initial capacity specifies the size of the initial table, and the load factor is used to specify the critical value for automatic expansion. When the number of entry exceeds capacity*load_factor, the container will automatically expand and rehash. For scenarios where a large number of elements are inserted, setting a larger initial capacity can reduce the number of rehashes.
object into LinkedHashMap or LinkedHashSet, there are two methods that require special attention: hashCode() and equals(). hashCode()The method determines which bucket the object will be placed in. When the hash values of multiple objects conflict, equals() Method determines whether these objects are "the same object". Therefore, if you want to put a custom object into LinkedHashMap or LinkedHashSet, you need *@Override*hashCode() and equals() method.
LinkedHashMap that is the same as the source Mapiteration order in the following way:
void foo(Map m) {
Map copy = new LinkedHashMap(m);
}LinkedHashMap is asynchronous (not synchronized). If it needs to be used in a multi-threaded environment, programmer needs to be synchronized manually; or LinkedHashMap is packaged in the following way. (wrapped) Synchronized:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
get(Object<a href="http://www.php.cn/wiki/60.html" target="_blank"> key)</a> method returns the corresponding value based on the specified key value. The process of this method is almost exactly the same as the HashMap.get() method. Readers can refer to the previous article and will not go into details here.
put(K key, V value)The method is to add the specified key, value pair to the map inside. This method will first search map to see if it contains the tuple. If it is included, it will return directly. The search process is similar to the get() method; if it is not found, then A new entry will be inserted through the addEntry(int hash, K key, V value, int bucketIndex) method.
insertion here has two meanings:
- From the perspective of
table
, new Theentryneeds to be inserted into the correspondingbucket. When there is a hash conflict, the head insertion method is used to insert the newentryinto the head of the conflict linked list. .从
header的角度看,新的entry需要插入到双向链表的尾部。
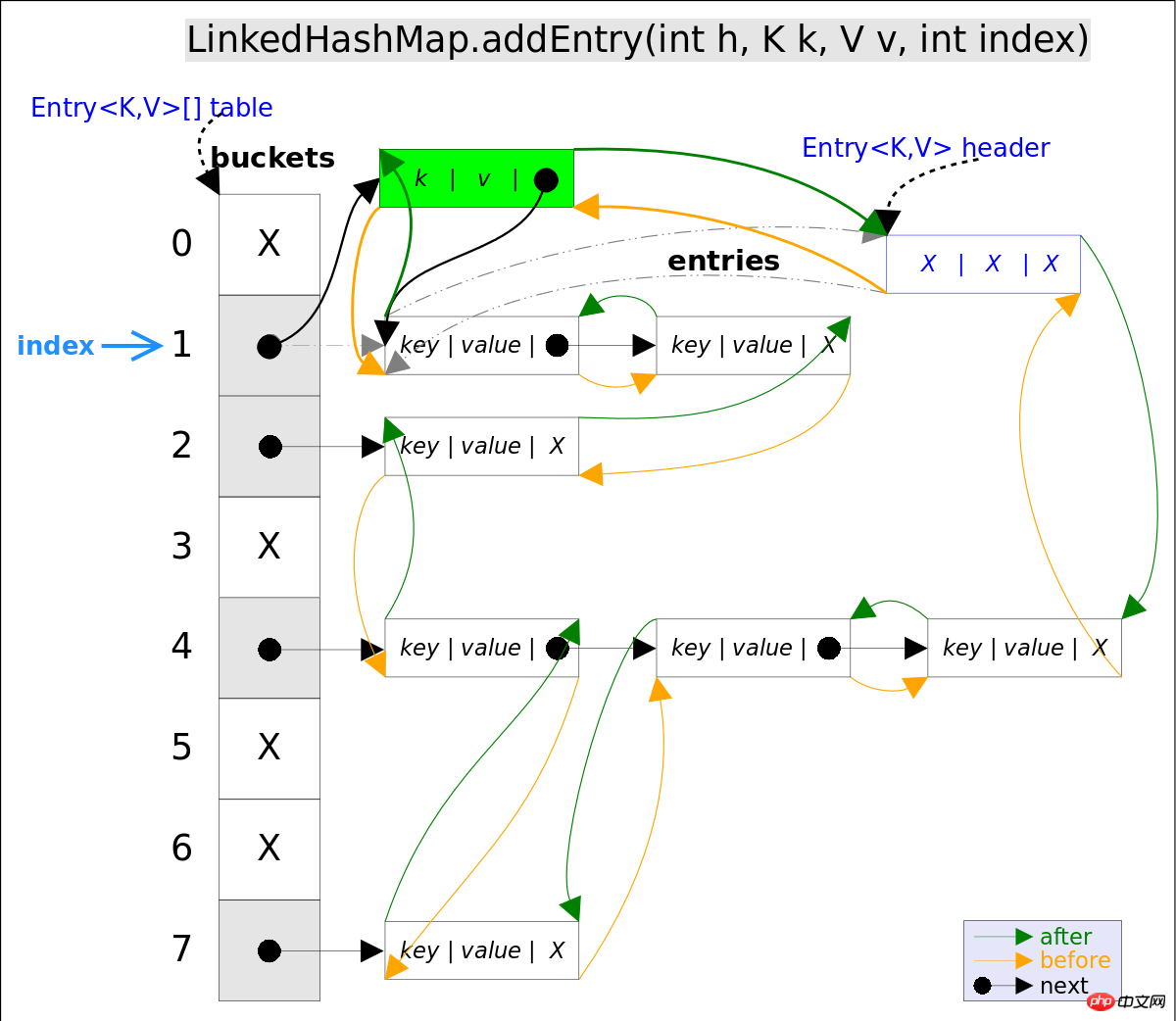
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从
table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。从
header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。

removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
}The above is the detailed content of Detailed explanation of Java collection framework LinkedHashSet and LinkedHashMap source code analysis (picture). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



