

spring-cloud-sleuth+zipkin tracking service implementation (2)
1. Brief description
In the previous section "spring-cloud-sleuth+zipkin tracking service implementation (1)", we used microservice-zipkin-server, microservice-zipkin-client, microservice- The three zipkin-client-backend programs implement service call link tracking using http for communication and data persistence into memory.
Here we make two changes. First, the data is changed from being stored in memory to being persisted to the database. Second, the http communication is changed to mq asynchronous communication.
We still use the three programs in the previous section to make modifications so that everyone can see the differences. Here, a stream is added to each project name to indicate the difference.
2. microservice-zipkin-stream-server
To change the http method to communication through MQ, we need to replace the original dependent io.zipkin.java:zipkin-server with spring-cloud-sleuth-zipkin-stream and spring-cloud-starter-stream-rabbit
To use mysql persistence at the same time, we need to add mysql related dependencies.
All maven dependencies are as follows:
" <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--zipkin依赖--> <!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> "
After adding the above maven dependencies, we will replace the @EnableZipkinServer annotation in the startup class ZipkinServer with @EnableZipkinStreamServer,
The details are as follows:
package com.yangyang.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* Created by chenshunyang on 2017/5/24.
*/
@EnableZipkinStreamServer// //使用Stream方式启动ZipkinServer
@SpringBootApplication
public class ZipkinStreamServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinStreamServerApplication.class,args);
}
}Click@ From the source code of the EnableZipkinStreamServer annotation, we can see that it also introduces the @EnableZipkinServer annotation and also creates a rabbit-mq message queue listener. 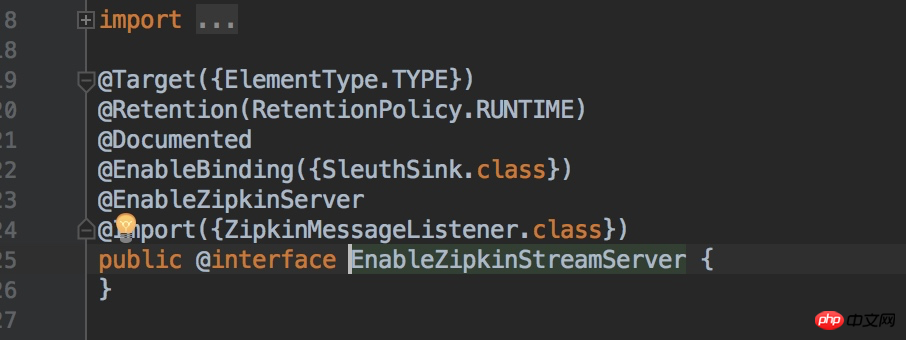
To facilitate receiving mq messages sent from the message client.
Since the message middleware rabbit mq and mysql are used, we also need to add relevant configurations to the configuration file application.properties:
server.port=11020 spring.application.name=microservice-zipkin-stream-server #zipkin数据保存到数据库中需要进行如下配置 #表示当前程序不使用sleuth spring.sleuth.enabled=false #表示zipkin数据存储方式是mysql zipkin.storage.type=mysql #数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素 spring.datasource.schema[0]=classpath:/zipkin.sql #spring boot数据源配置 spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.initialize=true spring.datasource.continue-on-error=true #rabbitmq配置 spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
Among them, zipkin.sql can be copied directly to the official website, or You can copy it from this demo
In order to avoid interference from http communication, we changed the original listening port from 11008 to 11020, started the program, and no error was reported and the rabbit connection log could be seen, indicating that the program started successfully.
3.microservice-zipkin-stream-client, microservice-zipkin-client-stream-backend
The same as the configuration in the previous section, the client configuration is also very simple, and the maven dependency only You need to replace the original spring-cloud-starter-zipkin with the following two dependencies
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
In addition, add the configuration to connect to MQ in the configuration file
server: port: 11021 spring: application: name: microservice-zipkin-stream-client #rabbitmq配置 rabbitmq: host: 127.0.0.1 port : 5672 username: guest password: guest
Of course for the sake of demonstration Difference, the port has also been adjusted accordingly
4. Test
Access according to the previous section: http://localhost:11021/call/1, we can go to the previous section, This shows that the sleuth function of rabbit-mq communication has taken effect.
We have visited the consumer's address many times and can see in the log that the request time will not suddenly take a long time.
In order to experience the feature of no data loss brought to us by MQ communication, we clear the data in the database, and then refresh the zipkin server interface. You can see that there is no more data.
Then we will zipkin -The server program wants to close, and then access the consumer address multiple times. After that, we restart the zipkin server program, and access the UI interface after successful startup
Soon we see that the Span Name option has data to select, and at the same time, the records in the database The number of entries is no longer the previous 0.
This shows that after restarting our zipkin, we successfully obtained the information data generated by the provider and consumer during the shutdown period from MQ. In this way, we can use the rest service call tracking function of spring-cloud-sleuth-stream+zipkin.
The above is the detailed content of spring-cloud-sleuth+zipkin tracking service implementation (2). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1655
1655
 14
1413
52
1306
25
1252
29
1226
24
14
1413
52
1306
25
1252
29
1226
24

 How to implement dual WeChat login on Huawei mobile phones?
Mar 24, 2024 am 11:27 AM
How to implement dual WeChat login on Huawei mobile phones?
Mar 24, 2024 am 11:27 AM
How to implement dual WeChat login on Huawei mobile phones? With the rise of social media, WeChat has become one of the indispensable communication tools in people's daily lives. However, many people may encounter a problem: logging into multiple WeChat accounts at the same time on the same mobile phone. For Huawei mobile phone users, it is not difficult to achieve dual WeChat login. This article will introduce how to achieve dual WeChat login on Huawei mobile phones. First of all, the EMUI system that comes with Huawei mobile phones provides a very convenient function - dual application opening. Through the application dual opening function, users can simultaneously
 PHP Programming Guide: Methods to Implement Fibonacci Sequence
Mar 20, 2024 pm 04:54 PM
PHP Programming Guide: Methods to Implement Fibonacci Sequence
Mar 20, 2024 pm 04:54 PM
The programming language PHP is a powerful tool for web development, capable of supporting a variety of different programming logics and algorithms. Among them, implementing the Fibonacci sequence is a common and classic programming problem. In this article, we will introduce how to use the PHP programming language to implement the Fibonacci sequence, and attach specific code examples. The Fibonacci sequence is a mathematical sequence defined as follows: the first and second elements of the sequence are 1, and starting from the third element, the value of each element is equal to the sum of the previous two elements. The first few elements of the sequence
 What is the correct way to restart a service in Linux?
Mar 15, 2024 am 09:09 AM
What is the correct way to restart a service in Linux?
Mar 15, 2024 am 09:09 AM
What is the correct way to restart a service in Linux? When using a Linux system, we often encounter situations where we need to restart a certain service, but sometimes we may encounter some problems when restarting the service, such as the service not actually stopping or starting. Therefore, it is very important to master the correct way to restart services. In Linux, you can usually use the systemctl command to manage system services. The systemctl command is part of the systemd system manager
 How to implement the WeChat clone function on Huawei mobile phones
Mar 24, 2024 pm 06:03 PM
How to implement the WeChat clone function on Huawei mobile phones
Mar 24, 2024 pm 06:03 PM
How to implement the WeChat clone function on Huawei mobile phones With the popularity of social software and people's increasing emphasis on privacy and security, the WeChat clone function has gradually become the focus of people's attention. The WeChat clone function can help users log in to multiple WeChat accounts on the same mobile phone at the same time, making it easier to manage and use. It is not difficult to implement the WeChat clone function on Huawei mobile phones. You only need to follow the following steps. Step 1: Make sure that the mobile phone system version and WeChat version meet the requirements. First, make sure that your Huawei mobile phone system version has been updated to the latest version, as well as the WeChat App.
 Master how Golang enables game development possibilities
Mar 16, 2024 pm 12:57 PM
Master how Golang enables game development possibilities
Mar 16, 2024 pm 12:57 PM
In today's software development field, Golang (Go language), as an efficient, concise and highly concurrency programming language, is increasingly favored by developers. Its rich standard library and efficient concurrency features make it a high-profile choice in the field of game development. This article will explore how to use Golang for game development and demonstrate its powerful possibilities through specific code examples. 1. Golang’s advantages in game development. As a statically typed language, Golang is used in building large-scale game systems.
 How to track the precise location of your Apple phone if it is lost and turned off?
Mar 08, 2024 pm 02:30 PM
How to track the precise location of your Apple phone if it is lost and turned off?
Mar 08, 2024 pm 02:30 PM
It is possible to recover an Apple phone if it is lost and turned off. The method is also very simple. Users can choose to log in to the official iCloud website to search, or a friend who also uses an Apple phone can use his phone to search for your iPhone. How to track the precise location of an Apple phone if it is lost and turned off? Answer: Search on the official iCloud website or borrow someone else's iPhone device to find it. 1. Users find that their Apple phone is lost or missing, and it can be found even if it is turned off. 2. Users directly log in to the iCloud official website, click Find My iPhone, and be sure to enter the correct account number. 3. Make sure your account is consistent with the account of the lost phone so that you have a chance to recover the phone. 4. If the phone is turned on and connected
 PHP Game Requirements Implementation Guide
Mar 11, 2024 am 08:45 AM
PHP Game Requirements Implementation Guide
Mar 11, 2024 am 08:45 AM
PHP Game Requirements Implementation Guide With the popularity and development of the Internet, the web game market is becoming more and more popular. Many developers hope to use the PHP language to develop their own web games, and implementing game requirements is a key step. This article will introduce how to use PHP language to implement common game requirements and provide specific code examples. 1. Create game characters In web games, game characters are a very important element. We need to define the attributes of the game character, such as name, level, experience value, etc., and provide methods to operate these
 How to implement exact division operation in Golang
Feb 20, 2024 pm 10:51 PM
How to implement exact division operation in Golang
Feb 20, 2024 pm 10:51 PM
Implementing exact division operations in Golang is a common need, especially in scenarios involving financial calculations or other scenarios that require high-precision calculations. Golang's built-in division operator "/" is calculated for floating point numbers, and sometimes there is a problem of precision loss. In order to solve this problem, we can use third-party libraries or custom functions to implement exact division operations. A common approach is to use the Rat type from the math/big package, which provides a representation of fractions and can be used to implement exact division operations.
