

Hadoop-Streaming实战经验及问题解决方法总结

目录 1. ? Join操作分清join的类型很重要 2. ?启动程序中key字段和partition字段的设定 3. ?控制hadoop程序内存的方法 4. ? 对于数字key的排序问题 5. ? 在mapper中获取map_input_file环境变量的方法 6. ? 运行过程中记录数据的方法 7. ?多次运行Hadoop之是
目录
1. ? Join操作分清join的类型很重要…
2. ?启动程序中key字段和partition字段的设定…
3. ?控制hadoop程序内存的方法…
4. ? 对于数字key的排序问题…
5. ? 在mapper中获取map_input_file环境变量的方法…
6. ? 运行过程中记录数据的方法…
7. ?多次运行Hadoop之是否成功的判断…
8. ?对stdin读取的 line的预处理…
9. ?Python字符串的连接方法…
10. ?怎样查看mapper程序的输出…
11. ?SHELL脚本中变量名的命名方法…
12. ?提前设计好流程能简化很多重复工作…
13. ?其他一些实用经验…
1. Join操作分清join的类型很重要
Join操作是hadoop计算中非常常见的需求,它要求将两个不同数据源的数据根据一个或多个key字段连接成一个合并数据输出,由于key字段数据的特殊性,导致join分成三种类型,处理方法各有不同,如果一个key在数据中可以重复,则记该数据源为N类型,如果只能出现一次,则记为1类型。
1) ?类型1-1的join
比如(学号,姓名)和(学号,班级)两个数据集根据学号字段进行join,因为同一个学号只能指向单个名字和单个班级,所以为1-1类型,处理方法是map阶段加上标记后,reduce阶段接收到的数据是每两个一个分组,这样的话只需要读取第一行,将非key字段连到第二行后面即可。
每个学号输出数据:1*1=1个
2) ?类型1-N或者N-1的join
比如(学号,姓名)和(学号,选修的课程)两个数据集根据学号字段的join,由于第二个数据源的数据中每个学号会对应很多的课程,所以为1-N类型join,处理方法是map阶段给第一个数据源(类型1)加上标记为1,第二个数据源加上标记为2。这样的话reduce阶段收到的数据以标记为1的行分组,同时每组行数会大于2,join方法是先读取标记1的行,记录其非key字段Field Value 1,然后往下遍历,每次遇到标记2的行都将Field Value 1添加到该行的末尾并输出。
每个学号输出数据:1*N=N*1=N个
3) ?类型M-N的join
比如(学号,选修的课程)和(学号,喜欢的水果)根据学号字段做join,由于每个数据源的单个学号都会对应多个相应数据,所以为M*N类型。处理方法是map阶段给数据源小的加上标记1(目的是reduce阶段的节省内存),给数据源大的加上标记2,reduce阶段每个分组会有M*N行,并且标记1的全部在标记2的前面。Join方法是先初始化一个空数组,遇到标记1的行时,将非key数据都记录在数组中,然后遇到标记2的行时,将数组中的数据添加在该行之后输出。
每个学号输出数据:M*N个
2. 启动程序中key字段和partition字段的设定
在join计算过程中,有两个字段非常的重要并需要对其理解,就是排序字段key和分区字段partition的指定。
| 字段 | 字段说明 |
|
num.key.fields.for.partition |
用于分区,只影响数据被分发到哪个reduce机器,但不影响排序 |
|
stream.num.map.output.key.fields |
Key的意思就是主键,这个主键会影响到数据根据前几列的排序 |
| org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner | 如果需要对字段排序、分区,默认都得加上此设置 |
上面三个配置尤其会影响到join计算时的配置:
1) ?如果是单key的join,因为要加上标记字段排序,所以设定key=2,同时设定partition=1对第一个字段分区来保证同Key的数据都在同一台机器上;
2) ?如果是N个联合key的join,首先需要加上标记字段,所以设定key=N+1,用来对其进行排序,然后需要partition为N来对其按key分区。
3. 控制hadoop程序内存的方法
Hadoop程序是针对海量数据的,因此任何一个保存变量的操作都会在内存中造成N倍的存储,如果尝试用一个数组记录每一行或某些行的单个字段,用不到程序运行结束,hadoop平台就会爆出137内存超出的错误而被kill掉。
控制内存的方法就是少用变量、尤其数组来记录数据,最终实现当前行的处理与数据总规模的无关,汇总、M*N的join等处理不得不记录历史数据,对这种处理要做到用后及时释放,同时尽量记录在单变量而不是数组中,比如汇总计算可以每次记录累加值,而不是先记录所有的元素最后才汇总。
4. 对于数字key的排序问题
如果不加以处理,排序处理过程中数字1会排在10之后,处理方法是需要在数字前面补0,比如如果全部有2位,就将个位数补1个零,让01和10比较,最终reduce输出的时候,再转回来,需要先预测数字的位数。
在mapper.py中:
Print ‘%010d\t%s’%(int(key),value)
其中key既然是数字,就需要用数字的格式化输出%010d表示将输出10位的字符串,如果不够10位,前面补0。
在reducer.py中,最终输出时,使用转int的方法去掉前面的0:
Print ‘%d\t%s’%(int(key),value)
5. 在mapper中获取map_input_file环境变量的方法
在mapper中,有时候为了区分不同的数据文件来源,这时候可以用map_input_file变量来记录当前正在处理的脚本的文件路径。以下是两种判别方法:
a)??????? 用文件名判断
Import os
filepath = os.environ["map_input_file"]
filename = os.path.split(filepath)[-1]
if filename==”filename1”:
#process 1
elif filename==”filename2”:
#process2
b)??????? 用文件路径是否包含确定字符串判断
filepath = os.environ["map_input_file"]
if filepath.find(sys.argv[2])!=-1:
#process
6. 运行过程中记录数据的方法
Hadoop程序不同于本地程序的调试方法,可以使用错误日志来查看错误信息,提交任务前也可以在本地用cat input | mapper.py | sort | reducer.py > output这种方法来先过滤基本的错误,在运行过程中也可以通过以下方法记录信息:
1) ?可以直接将信息输出到std output,程序运行结束后,需要手工筛选记录的数据,或者用awk直接查看,但是会污染结果数据
2) ?大多采用的是用错误输出的方法,这样运行后可以在stderr日志里面查看自己输出的数据:sys.stderr.write(‘filename:%s\t’%(filename))
7. ?多次运行Hadoop之是否成功的判断
如果要运行多次的hadoop计算,并且前一次的计算结果是下一次计算的输入,那么如果上一次计算失败了,下一次很明显不需要启动计算。因此在shell文件中可以通过$?来判断上一次是否运行成功,示例代码:
if [ $? -ne 0 ];then
?? exit 1
fi
8. 对stdin读取的 line的预处理
Mapper和reducer程序都是从标准输入读取数据的,然而如果直接进行split会发现最后一个字段后面跟了个’\n’,解决方法有两种:
1) ?datas = line[:-1].split(‘\t’)
2) ?datas=line.strip().split(‘\t’)
第一种方法直接去除最后一个字符\n,然后split,第二种方法是去除行两边的空格 (包括换行),然后split。个人喜欢用第二种,因为我不确定是否所有行都是\n结尾的,但是有些数据两边会有空格,如果strip掉的话就会伤害数据,所以可以根据情景选用。
9. Python字符串的连接方法
Mapper和reducer的输出或者中间的处理经常需要将不同类型的字符串结合在一起,python中实现字符串连接的方法有格式化输出、字符串连接(加号)和join操作(需要将每个字段转化成字符类型)。
使用格式化输出:’%d\t%s’%(inti,str)
使用字符串的+号进行连接:’%d\t’%i+’\t’.join(list)
写成元祖的\t的Join:’\t’.join((‘%d’%i, ‘\t’.join(list)))
10. 怎样查看mapper程序的输出
一般来说,mapper程序经过处理后,会经过排序然后partition给不同的reducer来做下一步的处理,然而在开发过程中常常需要查看当前的mapper输出是否是预期的结果,对其输出的查看有两种需求。
需求一,查看mapper的直接输出:
在运行脚本中,不设定-reducer参数,也就是没有reducer程序,然后把-D mapred.reduce.tasks=0,即不需要任何reduce的处理,但是同时要设定-output选项,这样的话,在output的目录中会看到每个mapper机器输出的一个文件,就是mapper程序的直接输出。
需求二,查看mapper的输出被partition并排序后的内容,即reducer的输入是什么样子:在运行脚本中,不设定-reducer参数,也就是没有自己的reducer程序,然后把-D mapred.reduce.tasks=1或者更大的值,即有reduce机器,但是没有reducer程序,hadoop会认为有reducer是存在的,因此会继续对mapper的输出调用shuffle打乱和sort操作,这样的话就在output目录下面看到了reducer的输入文件,并且数目等于reducer设定的tasks个数。
11. SHELL脚本中变量名的命名方法
如果遇到很多的输入数据源和很多输出的中间结果,每个hadoop的输出都会用到下一步的输入,并且该人物也用到了其他的输出,这样的话最好在一个统一的shell配置文件中配置所有的文件路径名字,同时一定避免InputDir1、InputDir2这样的命名方法,变量命名是一种功力,一定要多练直观并且显而易见,这样随着程序规模的增加不会变的越来越乱。
12. 提前设计好流程能简化很多重复工作
近期自己接到一个较为复杂的hadoop数据处理流程,大大小小的处理估算的话得十几个hadoop任务才能完成,不过幸好没有直接开始写代码,而是把这些任务统一整理了一下,最后竟然发现很多个问题可以直接合并成一类代码处理,过程中同时将整个任务拆分成了很多小任务并列了个顺序,然后挨个解决小任务非常的快。Hadoop处理流程中如果任务之间错综复杂并相互依赖对方的处理结果,都需要事先设计好处理流程再开始事先。
13. 其他一些实用经验
1) ?Mapper和reducer脚本写在同一个Python程序,便于对比和查看;
2) ?独立编写数据源的字段信息和位置映射字典,不容易混淆;
3) ?抽取常用的如输出数据、读入数据模块为独立函数;
4) ?测试脚本及数据、run脚本、map-reduce程序分目录放置;
原文地址:Hadoop-Streaming实战经验及问题解决方法总结, 感谢原作者分享。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 Solution to the problem that Win11 system cannot install Chinese language pack
Mar 09, 2024 am 09:48 AM
Solution to the problem that Win11 system cannot install Chinese language pack
Mar 09, 2024 am 09:48 AM
Solution to the problem that Win11 system cannot install Chinese language pack With the launch of Windows 11 system, many users began to upgrade their operating system to experience new functions and interfaces. However, some users found that they were unable to install the Chinese language pack after upgrading, which troubled their experience. In this article, we will discuss the reasons why Win11 system cannot install the Chinese language pack and provide some solutions to help users solve this problem. Cause Analysis First, let us analyze the inability of Win11 system to
 Five tips to teach you how to solve the problem of Black Shark phone not turning on!
Mar 24, 2024 pm 12:27 PM
Five tips to teach you how to solve the problem of Black Shark phone not turning on!
Mar 24, 2024 pm 12:27 PM
As smartphone technology continues to develop, mobile phones play an increasingly important role in our daily lives. As a flagship phone focusing on gaming performance, the Black Shark phone is highly favored by players. However, sometimes we also face the situation that the Black Shark phone cannot be turned on. At this time, we need to take some measures to solve this problem. Next, let us share five tips to teach you how to solve the problem of Black Shark phone not turning on: Step 1: Check the battery power. First, make sure your Black Shark phone has enough power. It may be because the phone battery is exhausted
 How to solve the problem of automatically saving pictures when publishing on Xiaohongshu? Where is the automatically saved image when posting?
Mar 22, 2024 am 08:06 AM
How to solve the problem of automatically saving pictures when publishing on Xiaohongshu? Where is the automatically saved image when posting?
Mar 22, 2024 am 08:06 AM
With the continuous development of social media, Xiaohongshu has become a platform for more and more young people to share their lives and discover beautiful things. Many users are troubled by auto-save issues when posting images. So, how to solve this problem? 1. How to solve the problem of automatically saving pictures when publishing on Xiaohongshu? 1. Clear the cache First, we can try to clear the cache data of Xiaohongshu. The steps are as follows: (1) Open Xiaohongshu and click the "My" button in the lower right corner; (2) On the personal center page, find "Settings" and click it; (3) Scroll down and find the "Clear Cache" option. Click OK. After clearing the cache, re-enter Xiaohongshu and try to post pictures to see if the automatic saving problem is solved. 2. Update the Xiaohongshu version to ensure that your Xiaohongshu
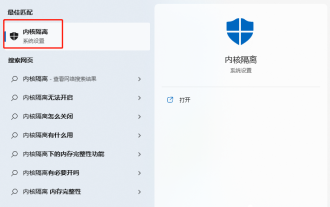 The driver cannot be loaded on this device. How to solve it? (Personally tested and valid)
Mar 14, 2024 pm 09:00 PM
The driver cannot be loaded on this device. How to solve it? (Personally tested and valid)
Mar 14, 2024 pm 09:00 PM
Everyone knows that if the computer cannot load the driver, the device may not work properly or interact with the computer correctly. So how do we solve the problem when a prompt box pops up on the computer that the driver cannot be loaded on this device? The editor below will teach you two ways to easily solve the problem. Unable to load the driver on this device Solution 1. Search for "Kernel Isolation" in the Start menu. 2. Turn off Memory Integrity, and it will prompt "Memory Integrity has been turned off. Your device may be vulnerable." Click behind to ignore it, and it will not affect the use. 3. The problem can be solved after restarting the machine.
 Interpreting Oracle error 3114: causes and solutions
Mar 08, 2024 pm 03:42 PM
Interpreting Oracle error 3114: causes and solutions
Mar 08, 2024 pm 03:42 PM
Title: Analysis of Oracle Error 3114: Causes and Solutions When using Oracle database, you often encounter various error codes, among which error 3114 is a relatively common one. This error generally involves database link problems, which may cause exceptions when accessing the database. This article will interpret Oracle error 3114, discuss its causes, and give specific methods to solve the error and related code examples. 1. Definition of error 3114 Oracle error 3114 pass
 Are you worried about WordPress backend garbled code? Try these solutions
Mar 05, 2024 pm 09:27 PM
Are you worried about WordPress backend garbled code? Try these solutions
Mar 05, 2024 pm 09:27 PM
Are you worried about WordPress backend garbled code? Try these solutions, specific code examples are required. With the widespread application of WordPress in website construction, many users may encounter the problem of garbled code in the WordPress backend. This kind of problem will cause the background management interface to display garbled characters, causing great trouble to users. This article will introduce some common solutions to help users solve the trouble of garbled characters in the WordPress backend. Modify the wp-config.php file and open wp-config.
 Guide to solving WordPress installation problems in one article
Feb 29, 2024 am 11:06 AM
Guide to solving WordPress installation problems in one article
Feb 29, 2024 am 11:06 AM
WordPress is a very popular open source content management system. Many individual users and businesses choose to use WordPress to build and manage their own websites. However, during the installation of WordPress, you sometimes encounter some problems, such as database connection errors, file permission issues, etc. This article will provide a guide to solving common WordPress installation problems and help users solve problems quickly through specific code examples. Problem 1: Database connection error when installing WordPress
 How to solve the problem of garbled characters when importing Chinese data into Oracle?
Mar 10, 2024 am 09:54 AM
How to solve the problem of garbled characters when importing Chinese data into Oracle?
Mar 10, 2024 am 09:54 AM
Title: Methods and code examples to solve the problem of garbled characters when importing Chinese data into Oracle. When importing Chinese data into Oracle database, garbled characters often appear. This may be due to incorrect database character set settings or encoding conversion problems during the import process. . In order to solve this problem, we can take some methods to ensure that the imported Chinese data can be displayed correctly. The following are some solutions and specific code examples: 1. Check the database character set settings In the Oracle database, the character set settings are
