

MSSQL表分区的创建详细讲解过程

现在基本所有数据库都存在表分区的概念,但MSSQL表分区一些细节又不一样,我现在也是有一定的了解,因此本篇文章不做很细的原理性质的讲解,主要讲一下MSSQL表分区的创建过程。
首先创建新的文件,分别放到我本机的D:SPPartition文件夹下的FirstPart,SecondPart,ThirdPart文件夹,新建3个文件文件分别对应3个文件组,以我本机中存在的数据库CenterMy为例子,它现在有个表TestSP,这是一个用户表,现在测试数据只有1000多条数据,创建代码如下:
| 代码如下 | 复制代码 |
|
ALTER DATABASE CenterMy ADD FILEGROUP FGSP1 GO ALTER DATABASE CenterMy ADD FILE ( NAME = 'SPTestLevel1', FILENAME = 'D:SPPartitionFirstPartSPTestLevel1.ndf', SIZE = 5120 KB, MAXSIZE = UNLIMITED, FILEGROWTH = 5120 KB ) TO FILEGROUP FGSP1 GO |
|
| 代码如下 | 复制代码 |
|
ALTER DATABASE CenterMy ADD FILEGROUP FGSP2 GO ALTER DATABASE CenterMy ADD FILE ( NAME = 'SPTestLevel2', FILENAME = 'D:SPPartitionSecondPartSPTestLevel2.ndf', SIZE = 5120 KB, MAXSIZE = UNLIMITED, FILEGROWTH = 5120 KB ) TO FILEGROUP FGSP2 GO |
|
| 代码如下 | 复制代码 |
|
ALTER DATABASE CenterMy ADD FILEGROUP FGSP3 GO ALTER DATABASE CenterMy ADD FILE ( NAME = 'SPTestLevel3', FILENAME = 'D:SPPartitionThirdPartSPTestLevel3.ndf', SIZE = 5120 KB, MAXSIZE = UNLIMITED, FILEGROWTH = 5120 KB ) TO FILEGROUP FGSP3 GO |
|
查询当前数据库CenterMy的分组:
| 代码如下 | 复制代码 |
|
SELECT * FROM sys.filegrou |
|
查看当前数据文件:
| 代码如下 | 复制代码 |
|
SELECT * FROM sys.database_files |
|
下面创建分区函数,它将为分区中数据分布制定标准。
| 代码如下 | 复制代码 |
|
CREATE PARTITION FUNCTION TestSPFunction (INT) AS RANGE RIGHT FOR VALUES ( 500, 1000,1300) GO |
|
然后创建分区方案,它将创建的分区函数映射到文件组,文件组对应磁盘上的物理数据库文件。
| 代码如下 | 复制代码 |
|
CREATE PARTITION SCHEME TestSPScheme AS PARTITION TestSPFunction TO ([PRIMARY], FGSP1, FGSP2,FGSP3 ) GO |
|
然后把表链接到分区方案,这里使用SPNO主键作为分区列。
ALTER TABLE TestSP add CONSTRAINT [PK_SPNO] PRIMARY KEY CLUSTERED (SPNo)
ON TestSPScheme(SPNo)
通过上面的操作,表分区就创建好了,并且数据自动放到相应的分区中了,下面我们查询下各个分区对应的数据量。
*
FROM sys.partitions
WHERE OBJECT_NAME(OBJECT_ID)='TestSP'
可以看到主分区有467条记录,partion_number的1,2,3,4分别对应不同文件组对应的row数据条数。

最后查询表的时候,可以在完全不知道表分区的情况下查询,我们查看下数据对应的所在分区:
SELECT *, $PARTITION.TestSPFunction(SPNo)
FROM TestSP

发现SPNO为500的正好在第二个分区了,证明我们创建表分区成功了!
上面只是简单描述了下表分区的过程,MSSQL2008还新增了可视化界面来添加表分区,如图:

本文主要是展现了分区的过程,对于实际项目中,是否需要分区,怎么分区,分区部署到什么磁盘上,分区后索引创建以及是否能达到优化的效果,还需要再根据实际情况更多的考虑,

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1657
1657
 14
1415
52
1309
25
1257
29
1230
24
14
1415
52
1309
25
1257
29
1230
24

 Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
The message "Your organization has asked you to change your PIN" will appear on the login screen. This happens when the PIN expiration limit is reached on a computer using organization-based account settings, where they have control over personal devices. However, if you set up Windows using a personal account, the error message should ideally not appear. Although this is not always the case. Most users who encounter errors report using their personal accounts. Why does my organization ask me to change my PIN on Windows 11? It's possible that your account is associated with an organization, and your primary approach should be to verify this. Contacting your domain administrator can help! Additionally, misconfigured local policy settings or incorrect registry keys can cause errors. Right now
 How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
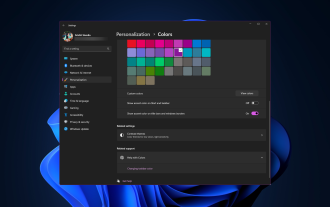
Windows 11 brings fresh and elegant design to the forefront; the modern interface allows you to personalize and change the finest details, such as window borders. In this guide, we'll discuss step-by-step instructions to help you create an environment that reflects your style in the Windows operating system. How to change window border settings? Press + to open the Settings app. WindowsI go to Personalization and click Color Settings. Color Change Window Borders Settings Window 11" Width="643" Height="500" > Find the Show accent color on title bar and window borders option, and toggle the switch next to it. To display accent colors on the Start menu and taskbar To display the theme color on the Start menu and taskbar, turn on Show theme on the Start menu and taskbar
 How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
By default, the title bar color on Windows 11 depends on the dark/light theme you choose. However, you can change it to any color you want. In this guide, we'll discuss step-by-step instructions for three ways to change it and personalize your desktop experience to make it visually appealing. Is it possible to change the title bar color of active and inactive windows? Yes, you can change the title bar color of active windows using the Settings app, or you can change the title bar color of inactive windows using Registry Editor. To learn these steps, go to the next section. How to change title bar color in Windows 11? 1. Using the Settings app press + to open the settings window. WindowsI go to "Personalization" and then
 How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
Taskbar thumbnails can be fun, but they can also be distracting or annoying. Considering how often you hover over this area, you may have inadvertently closed important windows a few times. Another disadvantage is that it uses more system resources, so if you've been looking for a way to be more resource efficient, we'll show you how to disable it. However, if your hardware specs can handle it and you like the preview, you can enable it. How to enable taskbar thumbnail preview in Windows 11? 1. Using the Settings app tap the key and click Settings. Windows click System and select About. Click Advanced system settings. Navigate to the Advanced tab and select Settings under Performance. Select "Visual Effects"
 OOBELANGUAGE Error Problems in Windows 11/10 Repair
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE Error Problems in Windows 11/10 Repair
Jul 16, 2023 pm 03:29 PM
Do you see "A problem occurred" along with the "OOBELANGUAGE" statement on the Windows Installer page? The installation of Windows sometimes stops due to such errors. OOBE means out-of-the-box experience. As the error message indicates, this is an issue related to OOBE language selection. There is nothing to worry about, you can solve this problem with nifty registry editing from the OOBE screen itself. Quick Fix – 1. Click the “Retry” button at the bottom of the OOBE app. This will continue the process without further hiccups. 2. Use the power button to force shut down the system. After the system restarts, OOBE should continue. 3. Disconnect the system from the Internet. Complete all aspects of OOBE in offline mode
 Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
We all have different preferences when it comes to display scaling on Windows 11. Some people like big icons, some like small icons. However, we all agree that having the right scaling is important. Poor font scaling or over-scaling of images can be a real productivity killer when working, so you need to know how to customize it to get the most out of your system's capabilities. Advantages of Custom Zoom: This is a useful feature for people who have difficulty reading text on the screen. It helps you see more on the screen at one time. You can create custom extension profiles that apply only to certain monitors and applications. Can help improve the performance of low-end hardware. It gives you more control over what's on your screen. How to use Windows 11
 10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
Screen brightness is an integral part of using modern computing devices, especially when you look at the screen for long periods of time. It helps you reduce eye strain, improve legibility, and view content easily and efficiently. However, depending on your settings, it can sometimes be difficult to manage brightness, especially on Windows 11 with the new UI changes. If you're having trouble adjusting brightness, here are all the ways to manage brightness on Windows 11. How to Change Brightness on Windows 11 [10 Ways Explained] Single monitor users can use the following methods to adjust brightness on Windows 11. This includes desktop systems using a single monitor as well as laptops. let's start. Method 1: Use the Action Center The Action Center is accessible
 How to solve discuz database error
Nov 20, 2023 am 10:10 AM
How to solve discuz database error
Nov 20, 2023 am 10:10 AM
The solutions to discuz database error are: 1. Check the database configuration; 2. Make sure the database server is running; 3. Check the database table status; 4. Back up the data; 5. Clear the cache; 6. Reinstall Discuz; 7. Check the server resources ; 8. Contact Discuz official support. Solving Discuz database errors requires starting from multiple aspects, gradually identifying the cause of the problem, and taking corresponding measures to repair it.
