
 Database
Mysql Tutorial
How to optimize performance? Detailed explanation of examples of MySQL implementing batch insertion to optimize performance
Database
Mysql Tutorial
How to optimize performance? Detailed explanation of examples of MySQL implementing batch insertion to optimize performance
How to optimize performance? Detailed explanation of examples of MySQL implementing batch insertion to optimize performance

This article mainly introduces the tutorial of MySQL to implement batch insertion to optimize performance. The running time is given in the article to indicate the comparison after performance optimization. Friends in need can refer to it
For some data with large amounts of data, In large systems, the database faces not only low query efficiency but also long data storage time. Especially for reporting systems, the time spent on data import may last for several hours or more than ten hours every day. Therefore, it makes sense to optimize database insertion performance.
After some performance tests on MySQL innodb, we found some methods that can improve insert efficiency for your reference.
1. One SQL statement inserts multiple pieces of data.
Commonly used insert statements such as
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
are modified to:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
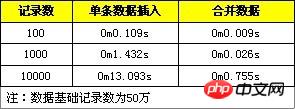
The modified insert operation can improve the insertion efficiency of the program. The main reason why the second SQL execution efficiency is high here is that the amount of logs after merging (MySQL's binlog and innodb's transaction logs) are reduced, which reduces the amount and frequency of log flushing, thereby improving efficiency. By merging SQL statements, it can also reduce the number of SQL statement parsing and reduce network transmission IO.
Here are some test comparison data, which are to import a single piece of data and convert it into a SQL statement for import, and to test 100, 1,000, and 10,000 data records respectively.
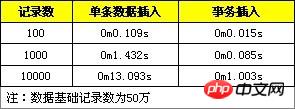
#2. Perform insertion processing in the transaction.
Change the insertion to:
START TRANSACTION; INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1); ... COMMIT;
3. Insert data in order.
Orderly insertion of data means that the inserted records are arranged in order on the primary key. For example, datetime is the primary key of the record:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('2', 'userid_2', 'content_2',2);
is modified to:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);Since the database needs to maintain index data when inserting, disordered records will increase the cost of maintaining the index. We can refer to the B+tree index used by innodb. If each inserted record is at the end of the index, the index positioning efficiency is very high, and the index adjustment is small; if the inserted record is in the middle of the index, B+tree is required. Processes such as splitting and merging will consume more computing resources, and the index positioning efficiency of inserted records will decrease. When the amount of data is large, there will be frequent disk operations.
The following provides a performance comparison of random data and sequential data, which are recorded as 100, 1000, 10000, 100000 and 1 million respectively.
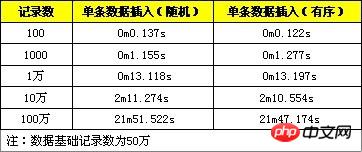
#From the test results, the performance of this optimization method has improved, but the improvement is not very obvious.
Comprehensive performance test:
Here is a test that uses the above three methods to optimize INSERT efficiency.
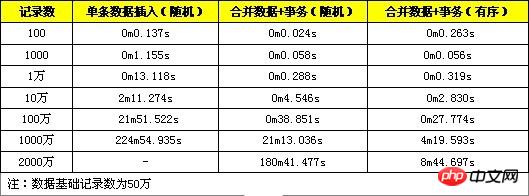
It can be seen from the test results that the performance improvement of the method of merging data + transactions is obvious when the amount of data is small. When the amount of data is large, the performance improvement is obvious. (more than 10 million), the performance will drop sharply. This is because the amount of data exceeds the capacity of innodb_buffer at this time. Each index positioning involves more disk read and write operations, and the performance drops quickly. The method of using merged data + transactions + ordered data still performs well when the data volume reaches tens of millions. When the data volume is large, the ordered data index positioning is more convenient and does not require frequent read and write operations on the disk. Therefore, high performance can be maintained.
Notes:
1. SQL statements have a length limit. When merging data in the same SQL, the SQL length limit must not be exceeded. It can be modified through the max_allowed_packet configuration. The default is 1M, modified to 8M during testing.
2. Transactions need to be controlled in size. If a transaction is too large, it may affect execution efficiency. MySQL has the innodb_log_buffer_size configuration item. If this value is exceeded, the innodb data will be flushed to the disk. At this time, the efficiency will decrease. So a better approach is to commit the transaction before the data reaches this value.
The above is the detailed content of How to optimize performance? Detailed explanation of examples of MySQL implementing batch insertion to optimize performance. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1657
1657
 14
1415
52
1309
25
1257
29
1229
24
14
1415
52
1309
25
1257
29
1229
24

 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
The process of starting MySQL in Docker consists of the following steps: Pull the MySQL image to create and start the container, set the root user password, and map the port verification connection Create the database and the user grants all permissions to the database
 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
 Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Article summary: This article provides detailed step-by-step instructions to guide readers on how to easily install the Laravel framework. Laravel is a powerful PHP framework that speeds up the development process of web applications. This tutorial covers the installation process from system requirements to configuring databases and setting up routing. By following these steps, readers can quickly and efficiently lay a solid foundation for their Laravel project.
 MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin are powerful database management tools. 1) MySQL is used to create databases and tables, and to execute DML and SQL queries. 2) phpMyAdmin provides an intuitive interface for database management, table structure management, data operations and user permission management.
 MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
Compared with other programming languages, MySQL is mainly used to store and manage data, while other languages such as Python, Java, and C are used for logical processing and application development. MySQL is known for its high performance, scalability and cross-platform support, suitable for data management needs, while other languages have advantages in their respective fields such as data analytics, enterprise applications, and system programming.
 MySQL vs. Other Databases: Comparing the Options
Apr 15, 2025 am 12:08 AM
MySQL vs. Other Databases: Comparing the Options
Apr 15, 2025 am 12:08 AM
MySQL is suitable for web applications and content management systems and is popular for its open source, high performance and ease of use. 1) Compared with PostgreSQL, MySQL performs better in simple queries and high concurrent read operations. 2) Compared with Oracle, MySQL is more popular among small and medium-sized enterprises because of its open source and low cost. 3) Compared with Microsoft SQL Server, MySQL is more suitable for cross-platform applications. 4) Unlike MongoDB, MySQL is more suitable for structured data and transaction processing.
