
With its excellent performance, low cost, and abundant resources, MySQL has become the preferred relational database for most Internet companies. Although the performance is excellent, the so-called "good horse comes with a good saddle", how to use it better has become a required course for development engineers. We often see things like "Proficient in MySQL" and "SQL statement optimization" from job descriptions , "Understand database principles" and other requirements. We know that in general application systems, the read-write ratio is about 10:1, and insertion operations and general update operations rarely cause performance problems. The most encountered ones, which are also the most likely to cause problems, are some complex query operations, so Optimization of query statements is obviously a top priority.
Since July 2013, I have been working on the optimization of slow queries in the core business system department of Meituan. There are more than ten systems in total, and I have solved and accumulated hundreds of slow query cases. As the complexity of the business increases, the problems encountered are all kinds of strange, varied and unbelievable. This article aims to explain the principles of database indexing and how to optimize slow queries from the perspective of a development engineer.
select count(*) from task where status=2 and operator_id=20839 and operate_time>1371169729 and operate_time<1371174603 and type=2;
System users reported that one function was getting slower and slower, so the engineer found the above SQL.
And found me excitedly, "This SQL needs to be optimized. Add an index to each field for me"
I was surprised and asked, "Why do we need to add an index to each field?"
"It will be faster to add indexes to all query fields." The engineer is full of confidence
"In this case, it is completely possible to build a joint index. Because it is the leftmost prefix match, the operate_time needs to be placed at the end, and other related queries need to be taken in, and a comprehensive evaluation needs to be done."
"Joint index? Leftmost prefix matching? Comprehensive evaluation?" The engineer couldn't help but fell into deep thought.
In most cases, we know that indexes can improve query efficiency, but how should we build indexes? What is the order of the indexes? Many people only know roughly. In fact, it is not difficult to understand these concepts, and the principle of indexing is far less complicated than imagined.
The purpose of the index is to improve query efficiency, which can be compared to a dictionary. If we want to look up the word "mysql", we definitely need to locate the m letter, then find the y letter from bottom to bottom, and then find the remaining sql. If there is no index, then you may need to look through all the words to find what you want. What if I want to find words starting with m? Or what about words starting with ze? Do you feel that without an index, this matter cannot be completed at all?
In addition to dictionaries, examples of indexes can be seen everywhere in life, such as train schedules at train stations, catalogs of books, etc. Their principles are the same. By constantly narrowing the scope of the data you want to obtain, you can filter out the final desired results, and at the same time, turn random events into sequential events, that is, we always use the same search method to lock data.
The same is true for the database, but it is obviously much more complicated, because it not only faces equivalent queries, but also range queries (>, <, between, in), fuzzy queries (like), union queries (or), etc. How should the database choose to deal with all problems? Let’s think back to the dictionary example. Can we divide the data into segments and then query them in segments? The simplest way is if there are 1,000 pieces of data, 1 to 100 are divided into the first section, 101 to 200 are divided into the second section, 201 to 300 are divided into the third section... In this way, to check the 250th piece of data, you only need to find the third section. The sub-removal of 90% of invalid data. But if it is a record of 10 million, how many segments should it be divided into? Students with a little bit of algorithm foundation will think of search trees, whose average complexity is lgN and has good query performance. But here we have overlooked a key issue. The complexity model is based on the same operation cost every time. The database implementation is relatively complex, and the data is saved on the disk. In order to improve performance, part of the data can be read in every time. Calculate using memory, because we know that the cost of accessing disk is about 100,000 times that of accessing memory, so a simple search tree cannot meet complex application scenarios.
Accessing the disk was mentioned earlier, so here is a brief introduction to disk IO and pre-reading. Reading data from the disk relies on mechanical movement. The time spent each time reading data can be divided into three categories: seek time, rotation delay, and transmission time. In part, the seek time refers to the time it takes for the magnetic arm to move to the specified track. Mainstream disks are generally below 5ms; the rotation delay is the disk speed we often hear. For example, a disk with 7200 rpm means it can rotate 7200 times per minute. , that is to say, it can rotate 120 times in 1 second, and the rotation delay is 1/120/2 = 4.17ms; the transmission time refers to the time to read from the disk or write data to the disk, which is generally a few tenths of a millisecond, relative to The first two times can be ignored. Then the time for accessing a disk, that is, the time for a disk IO is approximately equal to 5+4.17 = 9ms, which sounds pretty good, but you must know that a 500-MIPS machine can execute 500 million instructions per second, because the instructions It relies on the nature of electricity. In other words, 400,000 instructions can be executed in the time it takes to execute one IO. The database often contains hundreds of thousands, millions or even tens of millions of data. Each time it takes 9 milliseconds, it is obviously a disaster. The following picture is a comparison chart of computer hardware latency for your reference:

Considering that disk IO is a very expensive operation, the computer operating system has made some optimizations. When performing an IO, not only the data at the current disk address, but also adjacent data are read into the memory buffer, because local The principle of read-ahead tells us that when the computer accesses data at an address, the adjacent data will also be accessed quickly. The data read each time by IO is called a page. The specific size of data on a page depends on the operating system, usually 4k or 8k. That is, when we read the data in a page, only one IO actually occurs. This theory is very helpful for the data structure design of the index.
I have talked about examples of indexes in life, the basic principles of indexes, the complexity of databases, and related knowledge about operating systems. The purpose is to let everyone understand that no data structure is created out of thin air, and there must be it. Background and usage scenarios, let us now summarize what we need this data structure to be able to do. It is actually very simple, that is: control the number of disk IOs to a very small order of magnitude every time we look for data, preferably a constant order of magnitude. . Then we think about whether a highly controllable multi-path search tree can meet the needs? In this way, the b+ tree came into being.
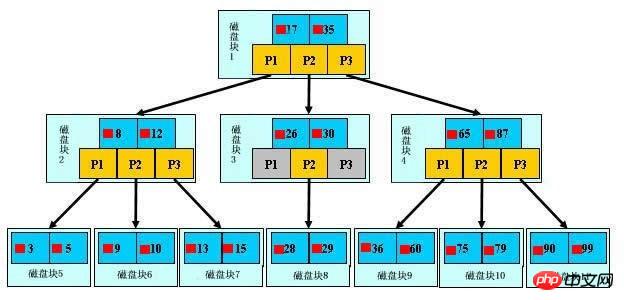
As shown above, it is a b+ tree. For the definition of b+ tree, please refer to B+ tree. Here are just some key points. We call the light blue block a disk block. You can see that each disk block contains several data items. (shown in dark blue) and pointers (shown in yellow), for example, disk block 1 contains data items 17 and 35, and contains pointers P1, P2, and P3. P1 represents disk blocks less than 17, and P2 represents between 17 and 35. Disk blocks, P3 represents disk blocks greater than 35. The real data exists in leaf nodes, namely 3, 5, 9, 10, 13, 15, 28, 29, 36, 60, 75, 79, 90, 99. Non-leaf nodes do not store real data, but only data items that guide the search direction. For example, 17 and 35 do not actually exist in the data table.
As shown in the figure, if you want to find data item 29, you will first load disk block 1 from the disk to the memory. At this time, an IO occurs. Use a binary search in the memory to determine that 29 is between 17 and 35, and lock disk block 1. The P2 pointer, the memory time is negligible because it is very short (compared to disk IO), disk block 3 is loaded from the disk to the memory through the disk address of the P2 pointer of disk block 1, the second IO occurs, 29 at 26 and 30, the P2 pointer of disk block 3 is locked, and disk block 8 is loaded into the memory through the pointer. The third IO occurs. At the same time, a binary search is performed in the memory to find 29, and the query is ended. A total of three IOs. The real situation is that a 3-layer b+ tree can represent millions of data. If millions of data searches only require three IOs, the performance improvement will be huge. If there is no index, one IO will occur for each data item. , then a total of millions of IOs are required, which is obviously very, very expensive.
1.通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
2.当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
关于MySQL索引原理是比较枯燥的东西,大家只需要有一个感性的认识,并不需要理解得非常透彻和深入。我们回头来看看一开始我们说的慢查询,了解完索引原理之后,大家是不是有什么想法呢?先总结一下索引的几大基本原则
1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
3.尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
4.索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
5.尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
根据最左匹配原则,最开始的sql语句的索引应该是status、operator_id、type、operate_time的联合索引;其中status、operator_id、type的顺序可以颠倒,所以我才会说,把这个表的所有相关查询都找到,会综合分析;
比如还有如下查询
select * from task where status = 0 and type = 12 limit 10; select count(*) from task where status = 0 ;
那么索引建立成(status,type,operator_id,operate_time)就是非常正确的,因为可以覆盖到所有情况。这个就是利用了索引的最左匹配的原则
关于explain命令相信大家并不陌生,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外,下面会讲到)。所以优化语句基本上都是在优化rows。
0.先运行看看是否真的很慢,注意设置SQL_NO_CACHE
1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
2.explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
3.order by limit 形式的sql语句让排序的表优先查
4.了解业务方使用场景
5.加索引时参照建索引的几大原则
6.观察结果,不符合预期继续从0分析
下面几个例子详细解释了如何分析和优化慢查询
很多情况下,我们写SQL只是为了实现功能,这只是第一步,不同的语句书写方式对于效率往往有本质的差别,这要求我们对mysql的执行计划和索引原则有非常清楚的认识,请看下面的语句
select
distinct cert.emp_id
from
cm_log cl
inner join
(
select
emp.id as emp_id,
emp_cert.id as cert_id
from
employee emp
left join
emp_certificate emp_cert
on emp.id = emp_cert.emp_id
where
emp.is_deleted=0
) cert
on (
cl.ref_table='Employee'
and cl.ref_oid= cert.emp_id
)
or (
cl.ref_table='EmpCertificate'
and cl.ref_oid= cert.cert_id
)
where
cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00';0.先运行一下,53条记录 1.87秒,又没有用聚合语句,比较慢
53 rows in set (1.87 sec)
1.explain
+----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+ | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where; Using temporary | | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 63727 | Using where; Using join buffer | | 2 | DERIVED | emp | ALL | NULL | NULL | NULL | NULL | 13317 | Using where | | 2 | DERIVED | emp_cert | ref | emp_certificate_empid | emp_certificate_empid | 4 | meituanorg.emp.id | 1 | Using index | +----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+
简述一下执行计划,首先mysql根据idx_last_upd_date索引扫描cm_log表获得379条记录;然后查表扫描了63727条记录,分为两部分,derived表示构造表,也就是不存在的表,可以简单理解成是一个语句形成的结果集,后面的数字表示语句的ID。derived2表示的是ID = 2的查询构造了虚拟表,并且返回了63727条记录。我们再来看看ID = 2的语句究竟做了写什么返回了这么大量的数据,首先全表扫描employee表13317条记录,然后根据索引emp_certificate_empid关联emp_certificate表,rows = 1表示,每个关联都只锁定了一条记录,效率比较高。获得后,再和cm_log的379条记录根据规则关联。从执行过程上可以看出返回了太多的数据,返回的数据绝大部分cm_log都用不到,因为cm_log只锁定了379条记录。
如何优化呢?可以看到我们在运行完后还是要和cm_log做join,那么我们能不能之前和cm_log做join呢?仔细分析语句不难发现,其基本思想是如果cm_log的ref_table是EmpCertificate就关联emp_certificate表,如果ref_table是Employee就关联employee表,我们完全可以拆成两部分,并用union连接起来,注意这里用union,而不用union all是因为原语句有“distinct”来得到唯一的记录,而union恰好具备了这种功能。如果原语句中没有distinct不需要去重,我们就可以直接使用union all了,因为使用union需要去重的动作,会影响SQL性能。
优化过的语句如下
select
emp.id
from
cm_log cl
inner join
employee emp
on cl.ref_table = 'Employee'
and cl.ref_oid = emp.id
where
cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00'
and emp.is_deleted = 0
union
select
emp.id
from
cm_log cl
inner join
emp_certificate ec
on cl.ref_table = 'EmpCertificate'
and cl.ref_oid = ec.id
inner join
employee emp
on emp.id = ec.emp_id
where
cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00'
and emp.is_deleted = 04.不需要了解业务场景,只需要改造的语句和改造之前的语句保持结果一致
5.现有索引可以满足,不需要建索引
6.用改造后的语句实验一下,只需要10ms 降低了近200倍!
+----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+ | 1 | PRIMARY | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 1 | PRIMARY | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | Using where | | 2 | UNION | cl | range | cm_log_cls_id,idx_last_upd_date | idx_last_upd_date | 8 | NULL | 379 | Using where | | 2 | UNION | ec | eq_ref | PRIMARY,emp_certificate_empid | PRIMARY | 4 | meituanorg.cl.ref_oid | 1 | | | 2 | UNION | emp | eq_ref | PRIMARY | PRIMARY | 4 | meituanorg.ec.emp_id | 1 | Using where | | NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | | +----+--------------+------------+--------+---------------------------------+-------------------+---------+-----------------------+------+-------------+
举这个例子的目的在于颠覆我们对列的区分度的认知,一般上我们认为区分度越高的列,越容易锁定更少的记录,但在一些特殊的情况下,这种理论是有局限性的
select
*
from
stage_poi sp
where
sp.accurate_result=1
and (
sp.sync_status=0
or sp.sync_status=2
or sp.sync_status=4
);0.先看看运行多长时间,951条数据6.22秒,真的很慢
951 rows in set (6.22 sec)
1.先explain,rows达到了361万,type = ALL表明是全表扫描
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+ | 1 | SIMPLE | sp | ALL | NULL | NULL | NULL | NULL | 3613155 | Using where | +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
2.所有字段都应用查询返回记录数,因为是单表查询 0已经做过了951条
3.让explain的rows 尽量逼近951
看一下accurate_result = 1的记录数
select count(*),accurate_result from stage_poi group by accurate_result; +----------+-----------------+ | count(*) | accurate_result | +----------+-----------------+ | 1023 | -1 | | 2114655 | 0 | | 972815 | 1 | +----------+-----------------+
我们看到accurate_result这个字段的区分度非常低,整个表只有-1,0,1三个值,加上索引也无法锁定特别少量的数据
再看一下sync_status字段的情况
select count(*),sync_status from stage_poi group by sync_status; +----------+-------------+ | count(*) | sync_status | +----------+-------------+ | 3080 | 0 | | 3085413 | 3 | +----------+-------------+
同样的区分度也很低,根据理论,也不适合建立索引
问题分析到这,好像得出了这个表无法优化的结论,两个列的区分度都很低,即便加上索引也只能适应这种情况,很难做普遍性的优化,比如当sync_status 0、3分布的很平均,那么锁定记录也是百万级别的
4.找业务方去沟通,看看使用场景。业务方是这么来使用这个SQL语句的,每隔五分钟会扫描符合条件的数据,处理完成后把sync_status这个字段变成1,五分钟符合条件的记录数并不会太多,1000个左右。了解了业务方的使用场景后,优化这个SQL就变得简单了,因为业务方保证了数据的不平衡,如果加上索引可以过滤掉绝大部分不需要的数据
5.根据建立索引规则,使用如下语句建立索引
alter table stage_poi add index idx_acc_status(accurate_result,sync_status);
6.观察预期结果,发现只需要200ms,快了30多倍。
952 rows in set (0.20 sec)
我们再来回顾一下分析问题的过程,单表查询相对来说比较好优化,大部分时候只需要把where条件里面的字段依照规则加上索引就好,如果只是这种“无脑”优化的话,显然一些区分度非常低的列,不应该加索引的列也会被加上索引,这样会对插入、更新性能造成严重的影响,同时也有可能影响其它的查询语句。所以我们第4步调差SQL的使用场景非常关键,我们只有知道这个业务场景,才能更好地辅助我们更好的分析和优化查询语句。
select
c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
c.last_modified_user_id
from
contact c
inner join
contact_branch cb
on c.id = cb.contact_id
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 10802
and oei.org_category = - 1
order by
c.created_time desc limit 0 ,
10;还是几个步骤
0.先看语句运行多长时间,10条记录用了13秒,已经不可忍受
10 rows in set (13.06 sec)
1.explain
+----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+ | 1 | SIMPLE | oei | ref | idx_category_left_right,idx_data_id | idx_category_left_right | 5 | const | 8849 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | bu | ref | PRIMARY,idx_userid_status | idx_userid_status | 4 | meituancrm.oei.data_id | 76 | Using where; Using index | | 1 | SIMPLE | cb | ref | idx_branch_id,idx_contact_branch_id | idx_branch_id | 4 | meituancrm.bu.branch_id | 1 | | | 1 | SIMPLE | c | eq_ref | PRIMARY | PRIMARY | 108 | meituancrm.cb.contact_id | 1 | | +----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+
从执行计划上看,mysql先查org_emp_info表扫描8849记录,再用索引idx_userid_status关联branch_user表,再用索引idx_branch_id关联contact_branch表,最后主键关联contact表。
rows返回的都非常少,看不到有什么异常情况。我们在看一下语句,发现后面有order by + limit组合,会不会是排序量太大搞的?于是我们简化SQL,去掉后面的order by 和 limit,看看到底用了多少记录来排序
select
count(*)
from
contact c
inner join
contact_branch cb
on c.id = cb.contact_id
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 10802
and oei.org_category = - 1
+----------+
| count(*) |
+----------+
| 778878 |
+----------+
1 row in set (5.19 sec)发现排序之前居然锁定了778878条记录,如果针对70万的结果集排序,将是灾难性的,怪不得这么慢,那我们能不能换个思路,先根据contact的created_time排序,再来join会不会比较快呢?
于是改造成下面的语句,也可以用straight_join来优化
select c.id, c.name, c.position, c.sex, c.phone, c.office_phone, c.feature_info, c.birthday, c.creator_id, c.is_keyperson, c.giveup_reason, c.status, c.data_source, from_unixtime(c.created_time) as created_time, from_unixtime(c.last_modified) as last_modified, c.last_modified_user_id from contact c where exists ( select 1 from contact_branch cb inner join branch_user bu on cb.branch_id = bu.branch_id and bu.status in ( 1, 2) inner join org_emp_info oei on oei.data_id = bu.user_id and oei.node_left >= 2875 and oei.node_right <= 10802 and oei.org_category = - 1 where c.id = cb.contact_id ) order by c.created_time desc limit 0 , 10;
验证一下效果 预计在1ms内,提升了13000多倍!
10 rows in set (0.00 sec)
本以为至此大工告成,但我们在前面的分析中漏了一个细节,先排序再join和先join再排序理论上开销是一样的,为何提升这么多是因为有一个limit!大致执行过程是:mysql先按索引排序得到前10条记录,然后再去join过滤,当发现不够10条的时候,再次去10条,再次join,这显然在内层join过滤的数据非常多的时候,将是灾难的,极端情况,内层一条数据都找不到,mysql还傻乎乎的每次取10条,几乎遍历了这个数据表!
用不同参数的SQL试验下
select
sql_no_cache c.id,
c.name,
c.position,
c.sex,
c.phone,
c.office_phone,
c.feature_info,
c.birthday,
c.creator_id,
c.is_keyperson,
c.giveup_reason,
c.status,
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
c.last_modified_user_id
from
contact c
where
exists (
select
1
from
contact_branch cb
inner join
branch_user bu
on cb.branch_id = bu.branch_id
and bu.status in (
1,
2)
inner join
org_emp_info oei
on oei.data_id = bu.user_id
and oei.node_left >= 2875
and oei.node_right <= 2875
and oei.org_category = - 1
where
c.id = cb.contact_id
)
order by
c.created_time desc limit 0 ,
10;
Empty set (2 min 18.99 sec)2 min 18.99 sec!比之前的情况还糟糕很多。由于mysql的nested loop机制,遇到这种情况,基本是无法优化的。这条语句最终也只能交给应用系统去优化自己的逻辑了。
通过这个例子我们可以看到,并不是所有语句都能优化,而往往我们优化时,由于SQL用例回归时落掉一些极端情况,会造成比原来还严重的后果。所以,第一:不要指望所有语句都能通过SQL优化,第二:不要过于自信,只针对具体case来优化,而忽略了更复杂的情况。
慢查询的案例就分析到这儿,以上只是一些比较典型的案例。我们在优化过程中遇到过超过1000行,涉及到16个表join的“垃圾SQL”,也遇到过线上线下数据库差异导致应用直接被慢查询拖死,也遇到过varchar等值比较没有写单引号,还遇到过笛卡尔积查询直接把从库搞死。再多的案例其实也只是一些经验的积累,如果我们熟悉查询优化器、索引的内部原理,那么分析这些案例就变得特别简单了。
本文以一个慢查询案例引入了MySQL索引原理、优化慢查询的一些方法论;并针对遇到的典型案例做了详细的分析。其实做了这么长时间的语句优化后才发现,任何数据库层面的优化都抵不上应用系统的优化,同样是MySQL,可以用来支撑Google/FaceBook/Taobao应用,但可能连你的个人网站都撑不住。套用最近比较流行的话:“查询容易,优化不易,且写且珍惜!”
参考文献如下:
1.《高性能MySQL》
2.《数据结构与算法分析》
The above is the detailed content of MySQL index principles and slow query optimization. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



