

MySQL paging optimization test case

Recently I accidentally saw a test case for MySQL paging optimization. Without very specific explanation of the test scenario, a classic solution was given,
because in reality there are many The situation is not fixed. To be able to summarize general practices or rules, we need to consider a lot of scenarios.
At the same time, when faced with ways to achieve optimization, we must investigate the reasons. The same approach, If the scene is changed and the optimization effect cannot be achieved, the reasons must be investigated.
I personally expressed doubts about the use of this scenario, and then tested it myself, and found some problems, and also confirmed some expected ideas.
This article will do a simple analysis on MySQL paging optimization, starting from the simplest situation.
Another: The test environment of this article is the cloud server with the lowest configuration. Relatively speaking, the server hardware environment is limited, but different statements (writing methods) should be "equal"
MySQL's classic paging "optimization" practice
In MySQL paging optimization, there is a classic problem. The "back" data in the query is slower (depending on the table) The index type, for the B-tree structure index, the same is true in SQL Server)
select * from t order by id limit m,n.
That is, as M increases, querying the same amount of data will become slower and slower.
Faced with this problem, a classic approach was born, similar to (or a variant of) ) The following way of writing
is to first find out the id in the paging range separately, then associate it with the base table, and finally query the required data
select * from t
inner join ( select id from t order by id limit m,n)t1 on t1.id = t.id
Is this approach always effective, or under what circumstances can the latter be achieved? To achieve the purpose of optimization? Is there any situation where it becomes ineffective or even slows down after rewriting?
At the same time, most queries have filtering conditions.
If there are filtering conditions, the
sql statement becomes It becomes select * from t where *** order by id limit m,n
If you follow the same pattern, rewrite it as something like
select * from t
inner join (select id from t where *** order by id limit m,n )t1 on t1.id = t.id
In this case, can the rewritten SQL statement still achieve the purpose of optimization?
Test environment setup
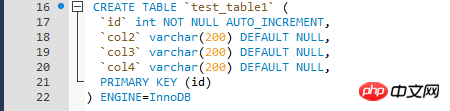
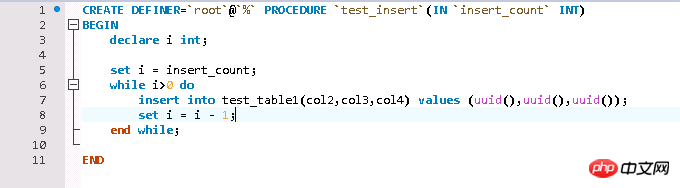
Test data is relatively simple and is written in a loop through a stored procedure Test data, InnoDB engine table of test table.

The reason for paging query optimization
First, let’s take a look at this classic problem. When paging, the "backward" the query is, the slower the response is. Test 1: Query the first 1-20 rows of data, 0.01 seconds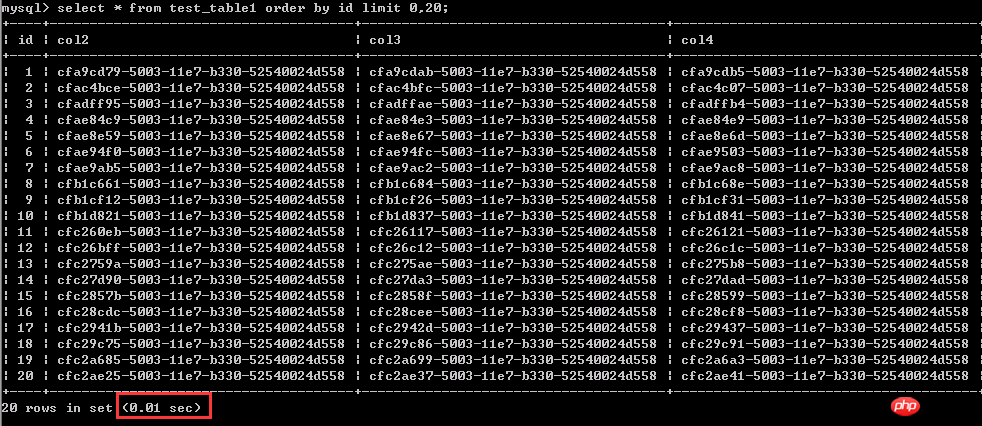

As for why the latter one is less efficient, we will analyze it later.
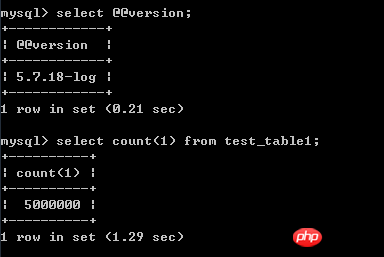
The test environment is centos 7, mysql 5.7, and the data of the test table is 500W
Reproduce the classic paging "optimization". When there are no filter conditions and the sorting column is a clustered index, there will be no improvement.
Here To compare the performance of the following two writing methods when the clustered index column is used as the sorting conditionselect * from t order by id limit m,n.
select * from t
inner join (select id from t order by id limit m,n)t1 on t1.id = t.id
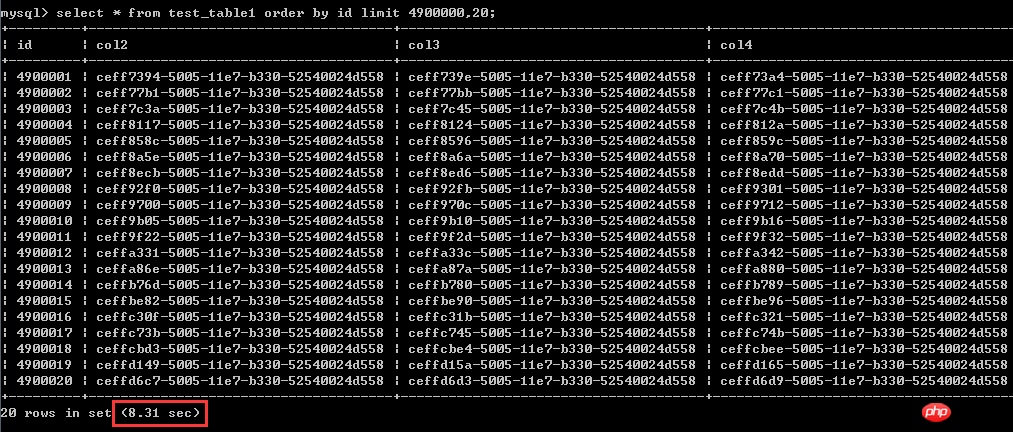
select * from test_table1 order by id asc limit 4900000,20; The test results are shown in the screenshot, The execution time is 8.31 seconds
inner join (select id from test_table1 order by id limit 4900000,20)t2 on t1.id = t2.id;
Execute The time is 8.43 seconds
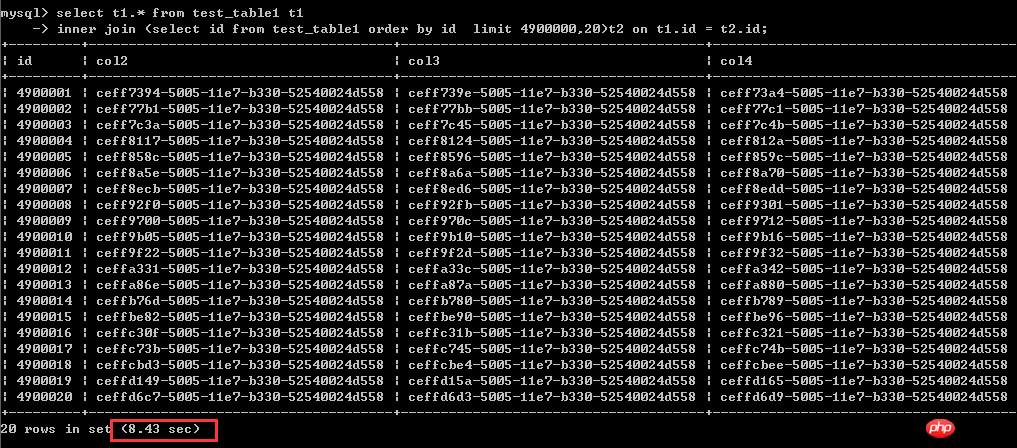
The actual test shows that there is no obvious linear difference in performance between the two. The original poster of the two has done multiple tests.
What causes this current rewrite to not achieve the purpose of improving performance?
What is the principle behind how the latter can improve performance?
Although the latter drives a subquery first, and then uses the results of the subquery to drive the main table,
But the subquery does not change the method of "sequentially scanning the table to query qualified data". Under the current situation, even the rewritten method seems superfluous.


Paging query when there is no filter condition and the sorting column is a clustered index, the so-called Paging query optimization is just superfluous
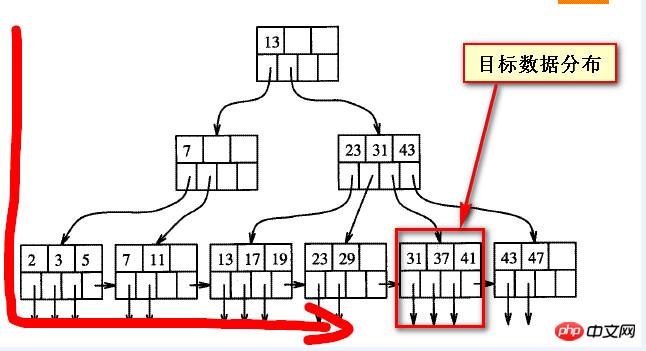
Currently, both methods of querying the above data are very slow. So what should you do if you want to query the above data? We still need to see why it is slow. We must first understand the balanced structure of B numbers. From my own rough understanding, as shown in the figure below,
When the queried data is "behind", it actually deviates from the One direction of the B-tree index, the target data shown in the following two screenshots
In fact, there is no so-called "front" and "back" for the data on the balanced tree, "front" and "back" are both Relative to the other party, or from the direction of scanning
Looking at the "back" data from one direction, it is "forward" from one direction, and the front and back are not absolute.
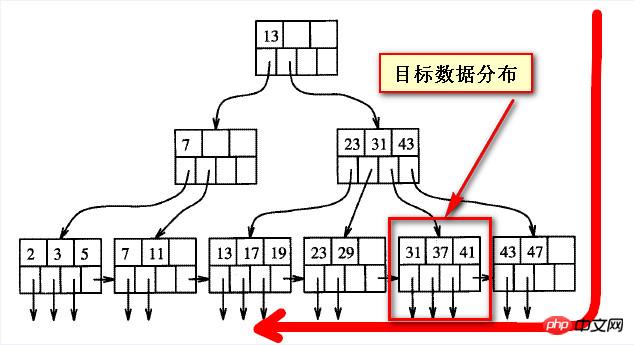
If you use reverse scanning for the later data, you should be able to quickly find this part of the data, and then sort the found data again (asc). The result should be the same,
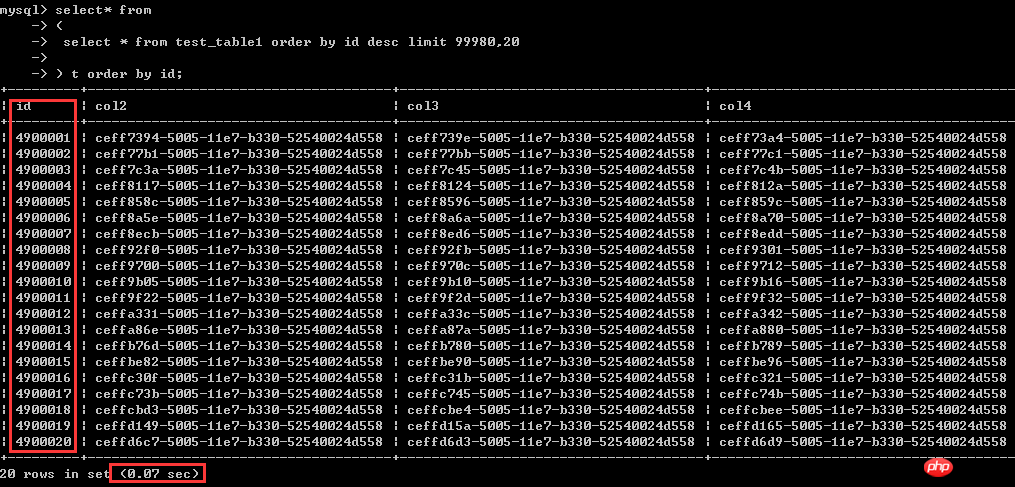
First let’s look at the effect: the result is exactly the same as the above query.
It only takes 0.07 seconds. The previous two writing methods both took more than 8 seconds, and the efficiency is hundreds of times different.
As for why this is, I think based on the above explanation, I should be able to understand it. Here is the sql.
If you often query the so-called later data, such as data with larger IDs, or newer data in the time dimension, you can use flashback scanning index to achieve efficient paging query
(Please calculate the page where the data is located here. For the same data, the starting "page number" is different in forward and reverse order)
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
When there are no filter conditions and the sorting column is a non-clustered index, there will be an improvement
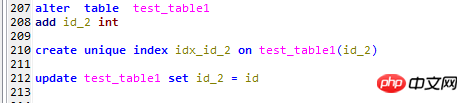
Here are the following changes to the test table test_table1
1. Add an id_2 Column,
2. Create a unique index on this field,
3. Fill this field with the corresponding primary key Id
Above The test is sorted according to the primary key index (clustered index). Now let's sort according to the non-clustered index, that is, the newly added column id_2, and test the two paging methods mentioned at the beginning.
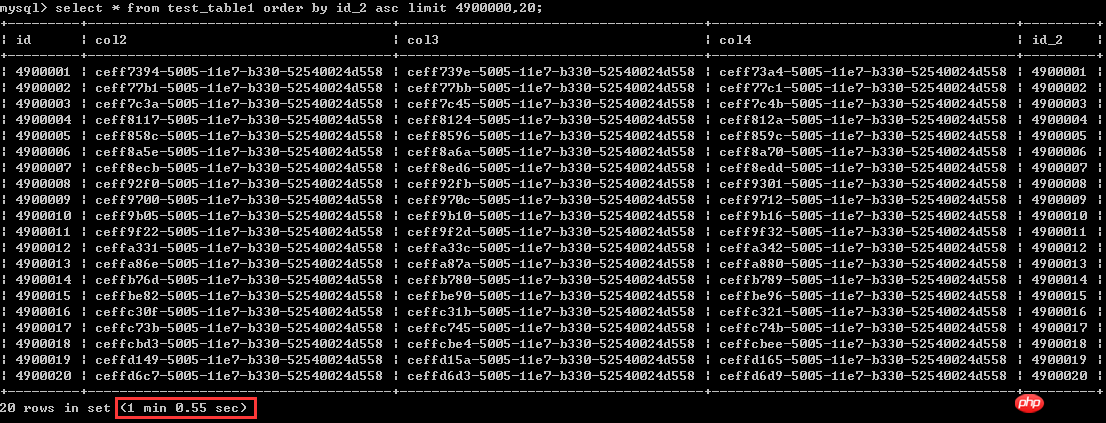
First let’s look at the first way of writing
select * from test_table1 order by id_2 asc limit 4900000,20; the execution time is a little more than 1 minute, let’s consider it as 60 seconds
The second way of writing
select t1.* from test_table1 t1
inner join (select id from test_table1 order by id_2 limit 4900000, 20)t2 on t1.id = t2.id;Execution time 1.67 seconds
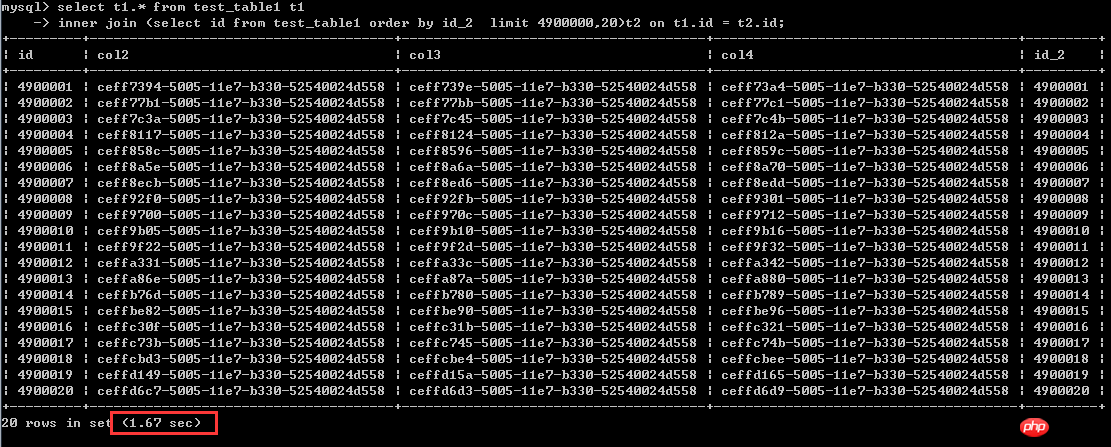
From this situation, that is to say, the sorting column is When using non-clustered index columns, the latter writing method can indeed greatly improve efficiency. That's almost a 40-fold improvement.
So what’s the reason?
First let’s look at the execution plan of the first way of writing. It can be simply understood that the entire table is scanned during the execution of this sql, and then sorted according to id_2, and finally the top 20 pieces of data are taken.
First of all, full table scanning is a very time-consuming process, and sorting is also a very high cost, so the performance is very low.

Let’s look at the execution plan of the latter. It first scans the sub-query in the order of the index on id_2, and then uses the qualified primary key Id to query the table. Data
In this case, it is avoided to query a large amount of data and then reorder it (Using filesort)
If you understand the sqlserver execution plan, compared with the former, the latter should avoid frequent table returns ( The process called key lookup or bookmark lookup in sqlserver can be considered as a batch and one-time process of querying the 20 qualifying data in the outer table driven by a subquery.
 Actually, only under the current circumstances, that is, when the sorting column is a non-clustered index column, can the rewritten sql improve the efficiency of paging queries.
Actually, only under the current circumstances, that is, when the sorting column is a non-clustered index column, can the rewritten sql improve the efficiency of paging queries.
As you can see above, the same data is returned. The following query takes 0.07 seconds, which is still 2 orders of magnitude higher than the 1.67 seconds here
select* from(select * from test_table1 order by id desc limit 99980,20) t order by id;
Another question I want to mention is that if paging queries are frequent and in a certain order, then why not create a clustered index on this column.
For example, if the statement automatically increments the ID, or if the time + other fields ensure uniqueness, mysql will automatically create a clustered index on the primary key.
Then with the clustered index, "front" and "back" are just relative logical concepts. If you want to get "back" or newer data most of the time, you can use the above writing method,
Optimization of paging queries when there are filter conditions
After thinking about this part, the situation is too complicated and it is difficult to summarize A very representative case came out, so I won’t do too many tests.
select * from t where *** order by id limit m,n
1. For example, the brush selection condition itself is very efficient. Once it is filtered out, only a small part of the data is left, so it does not matter whether the sql is changed or not. Not big, because the filtering conditions themselves can achieve very efficient filtering
2. For example, the brush selection conditions themselves have little effect (the amount of data is still huge after filtering). This situation actually returns to the situation where there are no filtering conditions. , and it also depends on how to sort, forward or reverse order, etc.
3. For example, the filtering conditions themselves have little effect (the amount of data is still huge after filtering). A very practical issue to consider is data distribution,
The distribution of data will also affect the execution efficiency of sql (experience in sqlserver, mysql should not be much different)
4. When the query itself is relatively complex, it is difficult to say that efficient use can be achieved in a certain way
The more complex the situation, the more difficult it is to summarize a general rule or method. Everything must be viewed based on the specific situation, and it is difficult to draw a conclusion.
Here we will not analyze the situation of adding filtering conditions to the query one by one, but what is certain is that without the actual scenario, there is definitely no solid solution.
In addition, when querying the data of the current page, using the maximum value of the query on the previous page as the filter condition can also quickly find the data of the current page. This is of course no problem, but This is another approach and is not discussed in this article.
Summary
Paging query, the farther back, the slower. In fact, for B-tree index, the front and back are A logically relative concept, the difference in performance is based on the B-tree index structure and scanning method.
If filtering conditions are added, the situation will become more complicated. The principle of this problem is the same in SQL Server. Yes, it was originally tested in SQL Server, so I won’t repeat it here.
In the current situation, the sorting column, query conditions, and data distribution are not necessarily certain, so it is difficult to use a specific method to achieve "optimization". If not, it will have superfluous side effects.
Therefore, when doing paging optimization, you must do analysis based on specific scenarios. There is not necessarily only one method. Any conclusion that is divorced from the actual scenario is nonsense.
Only by understanding the ins and outs of this problem can we be able to deal with it with ease.
Therefore, my personal conclusion on data "optimization" must be based on specific analysis of specific problems. It is very taboo to summarize a set of rules (Rules 1, 2, 3, 4, 5) for others to "apply". Since I am also very Food, let alone sum up some dogma.
The above is the detailed content of MySQL paging optimization test case. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
MySQL's Role: Databases in Web Applications
Apr 17, 2025 am 12:23 AM
The main role of MySQL in web applications is to store and manage data. 1.MySQL efficiently processes user information, product catalogs, transaction records and other data. 2. Through SQL query, developers can extract information from the database to generate dynamic content. 3.MySQL works based on the client-server model to ensure acceptable query speed.
 Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel Introduction Example
Apr 18, 2025 pm 12:45 PM
Laravel is a PHP framework for easy building of web applications. It provides a range of powerful features including: Installation: Install the Laravel CLI globally with Composer and create applications in the project directory. Routing: Define the relationship between the URL and the handler in routes/web.php. View: Create a view in resources/views to render the application's interface. Database Integration: Provides out-of-the-box integration with databases such as MySQL and uses migration to create and modify tables. Model and Controller: The model represents the database entity and the controller processes HTTP requests.
 MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin: Core Features and Functions
Apr 22, 2025 am 12:12 AM
MySQL and phpMyAdmin are powerful database management tools. 1) MySQL is used to create databases and tables, and to execute DML and SQL queries. 2) phpMyAdmin provides an intuitive interface for database management, table structure management, data operations and user permission management.
 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
 MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
MySQL vs. Other Programming Languages: A Comparison
Apr 19, 2025 am 12:22 AM
Compared with other programming languages, MySQL is mainly used to store and manage data, while other languages such as Python, Java, and C are used for logical processing and application development. MySQL is known for its high performance, scalability and cross-platform support, suitable for data management needs, while other languages have advantages in their respective fields such as data analytics, enterprise applications, and system programming.
 Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Laravel framework installation method
Apr 18, 2025 pm 12:54 PM
Article summary: This article provides detailed step-by-step instructions to guide readers on how to easily install the Laravel framework. Laravel is a powerful PHP framework that speeds up the development process of web applications. This tutorial covers the installation process from system requirements to configuring databases and setting up routing. By following these steps, readers can quickly and efficiently lay a solid foundation for their Laravel project.
 MySQL for Beginners: Getting Started with Database Management
Apr 18, 2025 am 12:10 AM
MySQL for Beginners: Getting Started with Database Management
Apr 18, 2025 am 12:10 AM
The basic operations of MySQL include creating databases, tables, and using SQL to perform CRUD operations on data. 1. Create a database: CREATEDATABASEmy_first_db; 2. Create a table: CREATETABLEbooks(idINTAUTO_INCREMENTPRIMARYKEY, titleVARCHAR(100)NOTNULL, authorVARCHAR(100)NOTNULL, published_yearINT); 3. Insert data: INSERTINTObooks(title, author, published_year)VA
 Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
Solve MySQL mode problem: The experience of using the TheliaMySQLModesChecker module
Apr 18, 2025 am 08:42 AM
When developing an e-commerce website using Thelia, I encountered a tricky problem: MySQL mode is not set properly, causing some features to not function properly. After some exploration, I found a module called TheliaMySQLModesChecker, which is able to automatically fix the MySQL pattern required by Thelia, completely solving my troubles.
