
 Database
Mysql Tutorial
Database table design-adjacency list, path enumeration, nested set, closure table
Database
Mysql Tutorial
Database table design-adjacency list, path enumeration, nested set, closure table
Database table design-adjacency list, path enumeration, nested set, closure table
CREATE TABLE Area ([id] [int] NOT NULL,[name] [nvarchar] (50) NULL,[parent_id] [int] NULL,[type] [int] NULL );
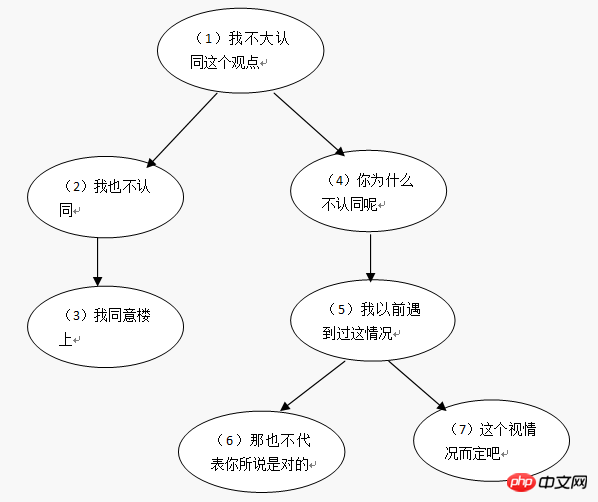
| parent_id | author | comment | |
| 0 | Xiao Ming | I don’t quite agree with this view | |
| 1 | Xiao Zhang | I don’t agree either | |
| 2 | 小红 | I agree with you upstairs | |
| 1 | 小全 | Why do you Don’t agree | |
| ##4 | Xiao Ming | I have encountered this situation before | |
| 5 | Xiao Zhang | That doesn’t mean what you said is right | |
| 5 | 小新 | This depends on the situation |
SELECT c1.*, c2.* FROM comments c1 LEFT OUTER JOIN comments c2 ON c2.parent_id = c1.comment_id;
In the comments table, we use the path field of type varchar to replace the original parent_id field. The content stored in this path field is the sequence from the top-level ancestor of the current node to its own sequence. Just like the UNIX path, you can even use '/' as the path separator.
| author | comment | ##1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 小明 | I don’t quite agree with this view | 2 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Xiao Zhang | I don’t agree either | 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 小红 | I agree with the above | 4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 小全 | Why don’t you agree? | 5 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Xiao Ming | I have encountered this situation before | 6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 小张 | That doesn’t mean what you said is right | 7 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 小新 | This depends on the situation |
你可以通过比较每个节点的路径来查询一个节点祖先。比如:要找到评论#7, 路径是 1/4/5/7一 的祖先,可以这么做:
SELECT * FROM comments AS c WHERE '1/4/5/7' LIKE c.path || '%' ; Copy after login 这句话查询语句会匹配到路径为 1/4/5/%,1/4/% 以及 1/% 的节点,而这些节点就是评论#7的祖先。
同时还可以通过将LIKE 关键字两边的参数互换,来查询一个给定节点的所有后代。比如查询评论#4,路径path为 ‘1/4’ 的所有后代,可以使用如下语句:
SELECT * FROM comemnts AS c WHERE c.path LIKE '1/4' || '%' ; Copy after login 这句查询语句所有能找到的后台路径分别是:1/4/5、1/4/5/6、1/4/5/7。
一旦你可以很简单地获取一棵子树或者从子孙节点到祖先节点的路径,你就可以很简单地实现更多的查询,如查询一颗子树所有节点上值的总和。
插入一个节点也可以像使用邻接表一样地简单。你所需要做的只是复制一份要插入节点的父亲节点路径,并将这个新节点的ID追加到路径末尾即可。
路径枚举也存在一些缺点,比如数据库不能确保路径的格式总是正确或者路径中的节点确实存在。依赖于应用程序的逻辑代码来维护路径的字符串,并且验证字符串的正确性开销很大。无论将varchar 的长度设定为多大,依旧存在长度的限制,因而并不能够支持树结构无限扩展。
二、 嵌套集
嵌套集解决方案是存储子孙节点的相关信息,而不是节点的直接祖先。我们使用两个数字来编码每个节点,从而表示这一信息,可以将这两个数字称为nsleft 和 nsright。
每个节点通过如下的方式确定nsleft 和nsright 的值:nsleft的数值小于该节点所有后代ID,同时nsright 的值大于该节点的所有后代的ID。这些数字和comment_id 的值并没有任何关联。
确定这三个值(nsleft,comment_id,nsright)的简单方法是对树进行一次深度优先遍历,在逐层深入的过程中依次递增地分配nsleft的值,并在返回时依次递增地分配nsright的值。得到数据如下:

一旦你为每个节点分配了这些数字,就可以使用它们来找到指定节点的祖先和后代。比如搜索评论#4及其所有后代,可以通过搜索哪些节点的ID在评论 #4 的nsleft 和 nsright 范围之间,例:
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c2.nsleft BETWEEN c1.nsleftAND c1.nsright WHERE c1.comment_id = 4; Copy after login 比如搜索评论#6及其所有祖先,可以通过搜索#6的ID在哪些节点的nsleft 和 nsright 范围之间,例:
SELECT c2.* FROM comments AS c1 JOIN comments AS c2 ON c1.nsleft BETWEEN c2.nsleftAND c2.nsright WHERE c1.comment_id = 6; Copy after login 使用嵌套集设计的主要优势是,当你想要删除一个非叶子节点时,它的后代会自动替代被删除的节点,成为其直接祖先节点的直接后代。就是说已经自动减少了一层。
然而,某些在邻接表的设计中表现得很简单的查询,比如获取一个节点的直接父亲或者直接后代,在嵌套集设计中会变得比较复杂。在嵌套集中,如果需要查询一个节点的直接父亲,我们会这么做,比如要找到评论#6 的直接父亲:
SELECT parent.* FROM comments AS c JOIN comments AS parent ON c.nsleft BETWEEN parent.nsleft AND parent.nsrightLEFT OUTER JOIN comments AS in_between ON c.nsleft BETWEEN in_between.nsleft AND in_between.nsrightAND in_between.nsleft BETWEEN parent.nsleft AND parent.nsright WHERE c.comment_id = 6AND in_between.comment_id IS NULL; Copy after login 总之有些复杂。
对树进行操作,比如插入和移动节点,使用嵌套集会比其它设计复杂很多。当插入一个新节点时,你需要重新计算新插入节点的相邻兄弟节点、祖先节点和它祖先节点的兄弟,来确保他们的左右值都比这个新节点的左值大。同时,如果这个新节点时一个非叶子节点,你还要检查它的子孙节点。
如果简单快速查询是整个程序中最重要的部分,嵌套集是最好的选择,比操作单独的节点要方便快捷很多。然而,嵌套集的插入和移动节点是比较复杂的,因为需要重新分配左右值,如果你的应用程序需要频繁的插入、删除节点,那么嵌套集可能并不合适。
三、闭包表
闭包表是解决分级存储的一个简单而优雅的解决方案,它记录了树中所有节点间的关系,而不仅仅只有那些直接的父子节点。
在设计评论系统时,我们额外创建了一个叫 tree_paths 表,它包含两列,每一列都指向 comments 中的外键。
我们不再使用comments 表存储树的结构,而是将树中任何具有(祖先 一 后代)关系的节点对都存储在treepaths 表里,即使这两个节点之间不是直接的父子关系;同时,我们还增加一行指向节点自己。
通过treepaths 表来获取祖先和后代比使用嵌套集更加的直接。例如要获取评论#4的后代,只需要在 treepaths 表中搜索祖先是评论 #4的行就行了。同样获取后代也是如此。
要插入一个新的叶子节点,比如评论#6的一个子节点,应首先插入一条自己到自己的关系,然后搜索 treepaths 表中后代是评论#6 的节点,增加该节点和新插入节点的“祖先一后代”关系(新节点ID 应该为8):
INSERT INTO treepaths (ancestor, descendant)SELECT t.ancestor, 8FROM treepaths AS tWHERE t.descendant = 6UNION ALL SELECT 8, 8; Copy after login 要删除一个叶子节点,比如评论#7, 应删除所有treepaths 表中后代为评论 #7 的行:
DELETE FROM treepaths WHERE descendant = 7; Copy after login
要删除一颗完整的子树,比如评论#4 和它所有的后代,可删除所有在 treepaths 表中后代为 #4的行,以及那些以评论#4后代为后代的行。
闭包表的设计比嵌套集更加的直接,两者都能快捷地查询给定节点的祖先和后代,但是闭包表能更加简单地维护分层信息。这两个设计都比使用邻接表或者路径枚举更方便地查询给定节点的直接后代和祖先。
然而你可以优化闭包表来使它更方便地查询直接父亲节点或者子节点: 在 treepaths 表中添加一个 path_length 字段。一个节点的自我引用的path_length 为0,到它直接子节点的path_length 为1,再下一层为2,以此类推。这样查询起来就方便多了。
总结:你该使用哪种设计:
种设计都各有优劣,如何选择设计,依赖于应用程序的哪种操作是你最需要性能上的优化。
层级数据设计比较
1、邻接表是最方便的设计,并且很多程序员都了解它
2、如果你使用的数据库支持WITH 或者 CONNECT BY PRIOR 的递归查询,那能使得邻接表的查询更高效。
3、枚举路径能够很直观地展示出祖先到后代之间的路径,但同时由于它不能确保引用完整性,使得这个设计非常脆弱。枚举路径也使得数据的存储变得比较冗余。
4、嵌套集是一个聪明的解决方案,但可能过于聪明,它不能确保引用完整性。最好在一个查询性能要求很高而对其他要求一般的场合来使用它。
5、闭包表是最通用的设计,并且以上的方案也只有它能允许一个节点属于多棵树。它要求一张额外的表来存储关系,使用空间换时间的方案减少操作过程中由冗余的计算所造成的消耗。
这几种设计方案只是我们日常设计中的一部分,开发中肯定会遇到更多的选择方案。选择哪一种方案,是需要切合实际,根据自己项目的需求,结合方案的优劣,选择最适合的一种。
我遇到一些开发人员,为了敷衍了事,在设计数据库表时,只考虑能否完成眼下的任务,不太注重以后拓展的问题,不考虑查询起来是否耗性能。可能前期数据量不多的时候,看不出什么影响,但数据量稍微多一点的话,就已经显而易见了(例如:可以使用外联接查询的,偏偏要使用子查询)。
我觉得设计数据库是一个很有趣且充满挑战的工作,它有时能体现你的视野有多宽广,有时它能让你睡不着觉,总之痛并快乐着。
|
The above is the detailed content of Database table design-adjacency list, path enumeration, nested set, closure table. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1657
1657
 14
1415
52
1309
25
1257
29
1229
24
14
1415
52
1309
25
1257
29
1229
24

 Honor Magic V3 debuts AI defocus eye protection technology: effectively alleviates the development of myopia
Jul 18, 2024 am 09:27 AM
Honor Magic V3 debuts AI defocus eye protection technology: effectively alleviates the development of myopia
Jul 18, 2024 am 09:27 AM
According to news on July 12, the Honor Magic V3 series was officially released today, equipped with the new Honor Vision Soothing Oasis eye protection screen. While the screen itself has high specifications and high quality, it also pioneered the introduction of AI active eye protection technology. It is reported that the traditional way to alleviate myopia is "myopia glasses". The power of myopia glasses is evenly distributed to ensure that the central area of sight is imaged on the retina, but the peripheral area is imaged behind the retina. The retina senses that the image is behind, promoting the eye axis direction. grow later, thereby deepening the degree. At present, one of the main ways to alleviate the development of myopia is the "defocus lens". The central area has a normal power, and the peripheral area is adjusted through optical design partitions, so that the image in the peripheral area falls in front of the retina.
 Vivo's phone with the strongest signal! vivo X100s is equipped with a universal signal amplification system: 21 antennas, 360° surround design
Jun 03, 2024 pm 08:41 PM
Vivo's phone with the strongest signal! vivo X100s is equipped with a universal signal amplification system: 21 antennas, 360° surround design
Jun 03, 2024 pm 08:41 PM
According to news on May 13, vivoX100s was officially released tonight. In addition to excellent images, the new phone also performs very well in terms of signal. According to vivo’s official introduction, vivoX100s uses an innovative universal signal amplification system, which is equipped with up to 21 antennas. This design has been re-optimized based on the direct screen to balance many signal requirements such as 5G, 4G, Wi-Fi, GPS, and NFC. This makes vivoX100s the mobile phone with the strongest signal reception capability in vivo’s history. The new phone also uses a unique 360° surround design, with antennas distributed around the body. This design not only enhances the signal strength, but also optimizes various daily holding postures to avoid problems caused by improper holding methods.
 iOS 18 adds a new 'Recovered' album function to retrieve lost or damaged photos
Jul 18, 2024 am 05:48 AM
iOS 18 adds a new 'Recovered' album function to retrieve lost or damaged photos
Jul 18, 2024 am 05:48 AM
Apple's latest releases of iOS18, iPadOS18 and macOS Sequoia systems have added an important feature to the Photos application, designed to help users easily recover photos and videos lost or damaged due to various reasons. The new feature introduces an album called "Recovered" in the Tools section of the Photos app that will automatically appear when a user has pictures or videos on their device that are not part of their photo library. The emergence of the "Recovered" album provides a solution for photos and videos lost due to database corruption, the camera application not saving to the photo library correctly, or a third-party application managing the photo library. Users only need a few simple steps
 Honor X60i mobile phone is on sale starting from 1,399 yuan: visual quadrilateral OLED direct screen
Jul 29, 2024 pm 08:25 PM
Honor X60i mobile phone is on sale starting from 1,399 yuan: visual quadrilateral OLED direct screen
Jul 29, 2024 pm 08:25 PM
According to news on July 29, the Honor X60i mobile phone is officially on sale today, starting at 1,399 yuan. In terms of design, the Honor X60i mobile phone adopts a straight screen design with a hole in the center and almost unbounded ultra-narrow borders on all four sides, which greatly broadens the field of view. Honor X60i parameters Display: 6.7-inch high-definition display Battery: 5000mAh large-capacity battery Processor: Dimensity 6080 processor (TSMC 6nm, 2x2.4G A76+6×2G A55) System: MagicOS8.0 system Other features: 5G signal enhancement, smart capsule, under-screen fingerprint, dual MIC, noise reduction, knowledge Q&A, photography capabilities: rear dual camera system: 50 million pixels main camera, 2 million pixels auxiliary lens, front selfie lens: 8 million pixels, price: 8GB
 Detailed tutorial on establishing a database connection using MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
Detailed tutorial on establishing a database connection using MySQLi in PHP
Jun 04, 2024 pm 01:42 PM
How to use MySQLi to establish a database connection in PHP: Include MySQLi extension (require_once) Create connection function (functionconnect_to_db) Call connection function ($conn=connect_to_db()) Execute query ($result=$conn->query()) Close connection ( $conn->close())
 New stacking process! Xiaomi MIX Fold 4 is equipped with Jinshajiang 'three-dimensional special-shaped' battery for the first time
Jul 20, 2024 am 03:20 AM
New stacking process! Xiaomi MIX Fold 4 is equipped with Jinshajiang 'three-dimensional special-shaped' battery for the first time
Jul 20, 2024 am 03:20 AM
According to news on July 19, Xiaomi MIX Fold 4, the first flagship folding new phone, was officially released tonight and is equipped with a "three-dimensional special-shaped battery" for the first time. According to reports, Xiaomi MIX Fold4 has achieved a major breakthrough in battery technology and designed an innovative "three-dimensional special-shaped battery" specifically for folding screens. Traditional folding screen devices mostly use conventional square batteries, which have low space utilization efficiency. In order to solve this problem, Xiaomi did not use the common winding battery cells, but developed a new lamination process to create a new form of battery, which greatly improved the space utilization. Battery Technology Innovation In order to accurately alternately stack positive and negative electrode sheets and ensure the safe embedding of lithium ions, Xiaomi has developed a new ultrasonic welding machine and lamination machine to improve welding and cutting accuracy.
 Xiaomi's 100-yuan phone Redmi 14C design specifications revealed, will be released on August 31
Aug 23, 2024 pm 09:31 PM
Xiaomi's 100-yuan phone Redmi 14C design specifications revealed, will be released on August 31
Aug 23, 2024 pm 09:31 PM
Xiaomi's Redmi brand is gearing up to add another budget phone to its portfolio - the Redmi 14C. The device is confirmed to be released in Vietnam on August 31st. However, ahead of the launch, the phone's specifications have been revealed via a Vietnamese retailer. Redmi14CR Redmi often brings new designs in new series, and Redmi14C is no exception. The phone has a large circular camera module on the back, which is completely different from the design of its predecessor. The blue color version even uses a gradient design to make it look more high-end. However, Redmi14C is actually an economical mobile phone. The camera module consists of four rings; one houses the main 50-megapixel sensor, and another may house the camera for depth information.
 How to handle database connection errors in PHP
Jun 05, 2024 pm 02:16 PM
How to handle database connection errors in PHP
Jun 05, 2024 pm 02:16 PM
To handle database connection errors in PHP, you can use the following steps: Use mysqli_connect_errno() to obtain the error code. Use mysqli_connect_error() to get the error message. By capturing and logging these error messages, database connection issues can be easily identified and resolved, ensuring the smooth running of your application.
