

Implement a thread pool

1. The three most important synchronization mechanisms of threads
1. Semaphores
2. Mutex locks
3. Condition variables
2. Implement a wrapper class for each of the three synchronization mechanisms
#ifdef LOCKER_H
#define LOCKER_H
#include <pthread.h>
#include <semaphore.h>
/*信号量的封装*/
class sem
{
public:
sem()
{
if( sem_init( &sem_like, 0, 0))
{
throw std::exception();
}
}
~sem()
{
sem_destroy( &sem_like);
}
bool wait()
{
return sem_wait( &sem_like)== 0;
}
bool post()
{
return sem_post( &sem_like)== 0;
}
private:
sem_t sem_like;
}
/*互斥锁的封装*/
class locker
{
public:
locker()
{
if( pthread_mutex_init( &mutex_like,NULL) !=0)
{
throw std::exception();
}
}
~locker()
{
pthread_mutex_destroy( &mutex_like);
}
bool lock()
{
return pthread_mutex_lock( &mutex_like)== 0;
}
bool unlock()
{
return pthread_mutex_unlock( &mutex_like);
}
private:
pthread_mutex_t mutex_like;
}
/*条件变量的封装*/
class cond
{
public:
cond()
{
if( pthread_mutex_init( &mutex_like,NULL)!= 0)
{
throw std::exception;
}
if( pthread_cond_init( &cond_like, NULL)!= 0)
{
//释放对应的互斥锁
pthread_mutex_destroy( &mutex_like);
throw std::exception;
}
}
~cond()
{
pthread_mutex_destroy( &mutex_like);
pthread_cond_destroy( &cond_like);
}
bool wait()
{
int flag= 0;
pthread_mutex_lock( &mutex_like);
flag= pthread_cond_wait( &cond_like, &mutex_like);
pthread_mutex_unlock( &mutex_like);
return flag== 0;
}
bool signal()
{
return pthread_cond_signal( &cond_like)== 0;
}
private:
pthread_mutex_t mutex_like;
pthread_cond_t cond_like;
}
#endif3. Implementation Thread Pool 十 The dynamic creation of threads is very time -consuming. If there is a thread pool, when the user request comes, take a free thread from the thread pool to handle the user's request. After the request is processed, the thread becomes idle and wait for the next time .
here Use a list container to store all requests, and request processing is in the order of fifo
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <list>
#include <cstdio>
#include <exception>
#include <pthread.h>
#include "locker.h"
template< typename T >
class threadpool
{
public:
threadpool( int thread_number = 8, int max_requests = 10000 );
~threadpool();
bool append( T* request );
private:
static void* worker( void* arg );
void run();
private:
int thread_number_like;//当前线程池中的线程个数
int max_requests_like;//最大请求数
//pthread_t* threads_like;
vector< pthread> threads_like;//线程容器
std::list< T* > workqueue_like;//请求队列
locker queuelocker_like;//请求队列的访问互斥锁
sem queuestat_like;//用于请求队列与空闲线程同步的信号量
bool stop_like;//结束所有线程,线程池此时没有线程
};
template< typename T >
threadpool< T >::threadpool( int thread_number, int max_requests ) :
m_thread_number( thread_number ), m_max_requests( max_requests ), m_stop( false ), m_threads( NULL )
{
if( ( thread_number <= 0 ) || ( max_requests <= 0 ) )
{
throw std::exception();
}
threads_like.resize( thread_number_like);
if( thread_number_like!= threads_like.size() )
{
throw std::exception();
}
for ( int i = 0; i < thread_number_like; ++i )
{
printf( "create the %dth thread\n", i );
if( pthread_create( &threads_like [i], NULL, worker, this ) != 0 )//创建线程
{
threads_like.resize(0);
throw std::exception();
}
if( pthread_detach( m_threads[i] ) )//设置为脱离线程
{
threads_like.resize(0);
throw std::exception();
}
}
}
template< typename T >
threadpool< T >::~threadpool()
{
stop_like = true;
}
template< typename T >
bool threadpool< T >::append( T* request )
{
queuelocker_like.lock();
if ( workqueue_like.size() > max_requests_like )
{
queuelocker_like.unlock();
return false;
}
workqueue_like.push_back( request );
queuelocker_like.unlock();
queuestat_like.post();
return true;
}
template< typename T >
void* threadpool< T >::worker( void* arg )
{
threadpool* pool = ( threadpool* )arg;//静态函数要调用动态成员run,必须通过参数arg得到
pool->run();//线程的执行体
return pool;
}
template< typename T >
void threadpool< T >::run()
{
while ( ! m_stop )
{
queuestat_like.wait();
queuelocker_like.lock();
if ( workqueue_like.empty() )
{
queuelocker_like.unlock();
continue;
}
T* request = workqueue_like.front();
workqueue_like.pop_front();
queuelocker_like.unlock();
if ( ! request )
{
continue;
}
request->process();//执行当前请求所对应的处理函数
}
}
#endif
Note: 1. In the thread pool model here, each thread corresponds to a request
2. This method ensures the timeliness of user requests processing, the performance requirements for the request processing function are smaller, because this model does not require the request processing process to be non-blocking, because the processing delay of one request will not affect the system's processing of other requests (of course the number of threads must be dynamic Increase).
3. This method is not optimal for high-concurrency servers. A method similar to nginx in which one process responds to multiple user requests is more advantageous. The nginx model has two main advantages: 1. The number of processes is fixed and does not It will take up too much memory because there are many threads or processes at the same time. 2: The number of nginx working processes is generally consistent with the number of CPU cores, and a process can be bound to a core, thus saving the system overhead caused by process switching or thread switching

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
Solution: Your organization requires you to change your PIN
Oct 04, 2023 pm 05:45 PM
The message "Your organization has asked you to change your PIN" will appear on the login screen. This happens when the PIN expiration limit is reached on a computer using organization-based account settings, where they have control over personal devices. However, if you set up Windows using a personal account, the error message should ideally not appear. Although this is not always the case. Most users who encounter errors report using their personal accounts. Why does my organization ask me to change my PIN on Windows 11? It's possible that your account is associated with an organization, and your primary approach should be to verify this. Contacting your domain administrator can help! Additionally, misconfigured local policy settings or incorrect registry keys can cause errors. Right now
 How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
How to adjust window border settings on Windows 11: Change color and size
Sep 22, 2023 am 11:37 AM
Windows 11 brings fresh and elegant design to the forefront; the modern interface allows you to personalize and change the finest details, such as window borders. In this guide, we'll discuss step-by-step instructions to help you create an environment that reflects your style in the Windows operating system. How to change window border settings? Press + to open the Settings app. WindowsI go to Personalization and click Color Settings. Color Change Window Borders Settings Window 11" Width="643" Height="500" > Find the Show accent color on title bar and window borders option, and toggle the switch next to it. To display accent colors on the Start menu and taskbar To display the theme color on the Start menu and taskbar, turn on Show theme on the Start menu and taskbar
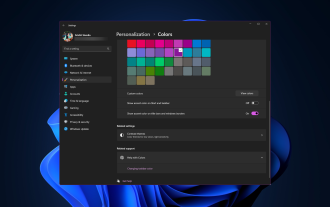 How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
How to change title bar color on Windows 11?
Sep 14, 2023 pm 03:33 PM
By default, the title bar color on Windows 11 depends on the dark/light theme you choose. However, you can change it to any color you want. In this guide, we'll discuss step-by-step instructions for three ways to change it and personalize your desktop experience to make it visually appealing. Is it possible to change the title bar color of active and inactive windows? Yes, you can change the title bar color of active windows using the Settings app, or you can change the title bar color of inactive windows using Registry Editor. To learn these steps, go to the next section. How to change title bar color in Windows 11? 1. Using the Settings app press + to open the settings window. WindowsI go to "Personalization" and then
 How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
How to enable or disable taskbar thumbnail previews on Windows 11
Sep 15, 2023 pm 03:57 PM
Taskbar thumbnails can be fun, but they can also be distracting or annoying. Considering how often you hover over this area, you may have inadvertently closed important windows a few times. Another disadvantage is that it uses more system resources, so if you've been looking for a way to be more resource efficient, we'll show you how to disable it. However, if your hardware specs can handle it and you like the preview, you can enable it. How to enable taskbar thumbnail preview in Windows 11? 1. Using the Settings app tap the key and click Settings. Windows click System and select About. Click Advanced system settings. Navigate to the Advanced tab and select Settings under Performance. Select "Visual Effects"
 OOBELANGUAGE Error Problems in Windows 11/10 Repair
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE Error Problems in Windows 11/10 Repair
Jul 16, 2023 pm 03:29 PM
Do you see "A problem occurred" along with the "OOBELANGUAGE" statement on the Windows Installer page? The installation of Windows sometimes stops due to such errors. OOBE means out-of-the-box experience. As the error message indicates, this is an issue related to OOBE language selection. There is nothing to worry about, you can solve this problem with nifty registry editing from the OOBE screen itself. Quick Fix – 1. Click the “Retry” button at the bottom of the OOBE app. This will continue the process without further hiccups. 2. Use the power button to force shut down the system. After the system restarts, OOBE should continue. 3. Disconnect the system from the Internet. Complete all aspects of OOBE in offline mode
 Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
Display scaling guide on Windows 11
Sep 19, 2023 pm 06:45 PM
We all have different preferences when it comes to display scaling on Windows 11. Some people like big icons, some like small icons. However, we all agree that having the right scaling is important. Poor font scaling or over-scaling of images can be a real productivity killer when working, so you need to know how to customize it to get the most out of your system's capabilities. Advantages of Custom Zoom: This is a useful feature for people who have difficulty reading text on the screen. It helps you see more on the screen at one time. You can create custom extension profiles that apply only to certain monitors and applications. Can help improve the performance of low-end hardware. It gives you more control over what's on your screen. How to use Windows 11
 10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
10 Ways to Adjust Brightness on Windows 11
Dec 18, 2023 pm 02:21 PM
Screen brightness is an integral part of using modern computing devices, especially when you look at the screen for long periods of time. It helps you reduce eye strain, improve legibility, and view content easily and efficiently. However, depending on your settings, it can sometimes be difficult to manage brightness, especially on Windows 11 with the new UI changes. If you're having trouble adjusting brightness, here are all the ways to manage brightness on Windows 11. How to Change Brightness on Windows 11 [10 Ways Explained] Single monitor users can use the following methods to adjust brightness on Windows 11. This includes desktop systems using a single monitor as well as laptops. let's start. Method 1: Use the Action Center The Action Center is accessible
 How to Fix Activation Error Code 0xc004f069 in Windows Server
Jul 22, 2023 am 09:49 AM
How to Fix Activation Error Code 0xc004f069 in Windows Server
Jul 22, 2023 am 09:49 AM
The activation process on Windows sometimes takes a sudden turn to display an error message containing this error code 0xc004f069. Although the activation process is online, some older systems running Windows Server may experience this issue. Go through these initial checks, and if they don't help you activate your system, jump to the main solution to resolve the issue. Workaround – close the error message and activation window. Then restart the computer. Retry the Windows activation process from scratch again. Fix 1 – Activate from Terminal Activate Windows Server Edition system from cmd terminal. Stage – 1 Check Windows Server Version You have to check which type of W you are using
