
 Backend Development
Python Tutorial
Python implementation of network paragraph page crawler case
Backend Development
Python Tutorial
Python implementation of network paragraph page crawler case
Python implementation of network paragraph page crawler case

Most of the Python tutorials on the Internet are version 2.X. Compared with python3.X, python2.X has changed a lot. Many libraries are used differently. I installed python3.X. Let’s take a look at the details. Example
0x01
I had nothing to do during the Spring Festival (how free I am), so I wrote a simple program to read some jokes and record the process of writing the program. The first time I came into contact with crawlers was when I saw a post like this. It was a funny post about crawling photos of girls on Omelette. It was not very convenient. So I started to imitate cats and tigers myself and captured some pictures.
Technology is inspiring the future. As a programmer, how can you do such a thing? It is better to make jokes that are better for your physical and mental health.

0x02
Before we roll up our sleeves and get started, let’s popularize some theoretical knowledge.
To put it simply, we need to pull down the content at a specific location on the web page. How to pull it out? We must first analyze the web page to see which piece of content we need. For example, what we crawled this time is jokes from the hilarious website. When we open the jokes page of the hilarious website, we can see a lot of jokes. Our purpose is to obtain this content. Come back and calm down after reading it. If you keep laughing like this, we can't write code. In chrome, we open the Inspect Element and then expand the HTML tags level by level, or click the small mouse to locate the element we need.
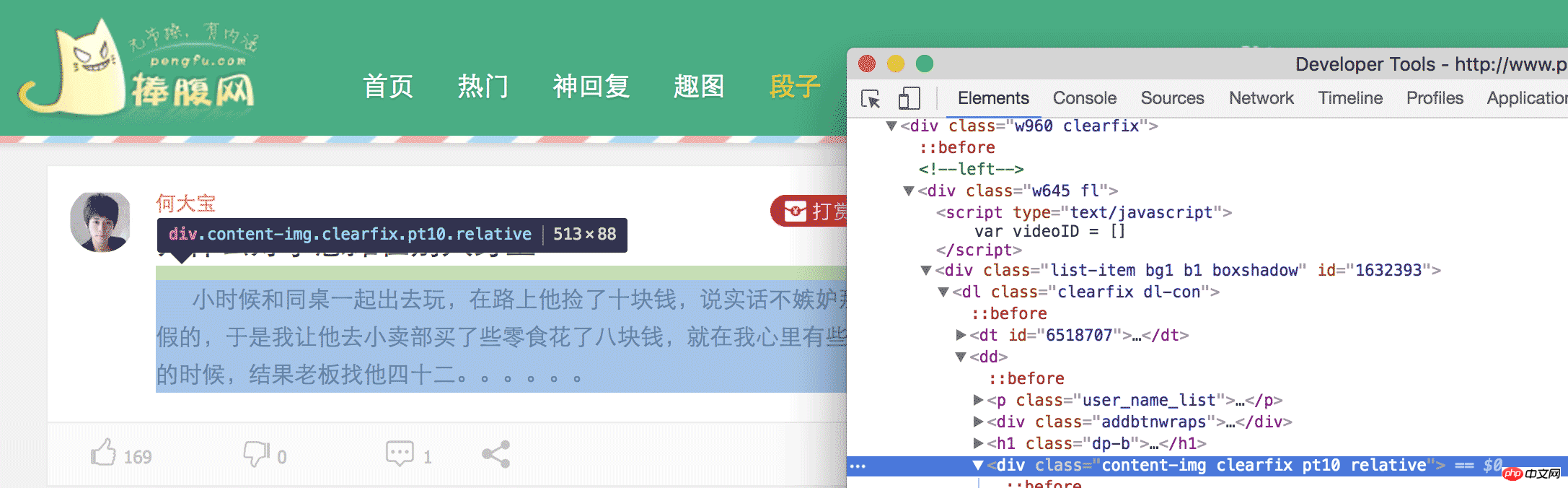
Finally, we can find that the content in
is the joke we need. The same is true when looking at the second joke. So, we can find all the
in this webpage, and then extract the content inside, and we're done.
0x03
Okay, now that we know our purpose, we can roll up our sleeves and get started. I use python3 here. Regarding the choice of python2 and python3, everyone can decide by themselves. The functions can be realized, but there are some differences. But it is still recommended to use python3.
We want to pull down the content we need. First we have to pull down this web page. How to pull it down? Here we need to use a library called urllib. We use the method provided by this library to get the entire web page.
First, we import urllib
The code is as follows:
import urllib.request as request
Then, we can use request to get the web page,
The code is as follows:
return request.urlopen(url).read()
Life is short, I use python, one line of code, download a web page, you said, there is no reason not to use python.
After downloading the web page, we have to parse the web page to get the elements we need. In order to parse elements, we need to use another tool called Beautiful Soup. Using it, we can quickly parse HTML and XML and get the elements we need.
The code is as follows:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))It only takes one sentence to use BeautifulSoup to parse a web page, but when you run the code, such a warning will appear, prompting you to specify a parser. Otherwise, errors may be reported on other platforms or systems.
The code is as follows:
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/init.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))The types of parsers and the differences between different parsers are explained in detail in the official documents. At present, it is more reliable to use lxml parsing.
After modification
The code is as follows:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))In this way, there will be no above warning.
The code is as follows:
p_array = soup.find_all('p', {'class':"content-img clearfix pt10 relative"})Use find_all function to find all p tags of class = content-img clearfix pt10 relative and then traverse this array
The code is as follows:
for x in p_array: content = x.string
In this way, we get the content of destination p. At this point, we have achieved our goal and climbed to our joke.
But when crawling in the same way, such an error will be reported
The code is as follows:
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
代码如下:
def getHTML(url):
head
ers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('p', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('p', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if name == 'main':
get_pengfu_joke()
get_qiubai_joke()【相关推荐】
1. Python免费视频教程
3. Python基础入门手册
The above is the detailed content of Python implementation of network paragraph page crawler case. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1657
1657
 14
1415
52
1309
25
1257
29
1229
24
14
1415
52
1309
25
1257
29
1229
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
