

The http protocol is one of the most important and basic protocols in the Internet. Our crawlers need to often deal with the http protocol. The following article mainly introduces to you the relevant information about pythonGetting started with crawlers and quickly understanding the HTTP protocol. The introduction in the article is very detailed. Friends who need it can refer to it. Let’s come together. Let's see.
Preface
The basic principle of the crawler is to simulate the browser to make HTTP requests. Understanding the HTTP protocol is the necessary foundation for writing a crawler , the crawler position on the recruitment website also clearly states that you are proficient in the HTTP protocol specifications. When writing a crawler, you have to start with the HTTP protocol.
What is the HTTP protocol?
Every web page you browse is presented based on the HTTP protocol. The HTTP protocol is a protocol for data communication between the client (browser) and the server in Internet applications. . The protocol stipulates the format in which the client should send requests to the server, and also stipulates the format of the response returned by the server.
As long as everyone initiates requests and returns response results in accordance with the protocol, anyone can implement their own Web client (browser, crawler) and Web server (Nginx, Apache, etc.) based on the HTTP protocol.
The HTTP protocol itself is very simple. It stipulates that the client can only actively initiate a request, and the server returns the response result after receiving the request and processing it. At the same time, HTTP is a status protocol, and the protocol itself does not record the client's historical request records.

#How does the HTTP protocol specify the request format and response format? In other words, in what format can the client correctly initiate an HTTP request? In what format does the server return the response result so that the client can parse it correctly?
HTTP request
HTTP request is grouped into three parts, namely request line, request header, and request body , the header and request body are optional and not required for every request.

Request line
The request line is an essential part of every request, it consists of 3 It consists of parts, namely Request method (method), request URL (URI), and HTTP protocol version, separated by spaces.
The most commonly used request methods in HTTP protocol are: GET, POST, PUT, DELETE. The GET method is used to obtain resources from the server, and 90% of crawlers crawl data based on GET requests.
The request URL refers to the path address of the server where the resource is located. For example, the example above indicates that the client wants to obtain the resource index.html, and its path is under the root directory (/) of the server foofish.net.
Request header
Because the amount of information carried by the request line is very limited, the client still has a lot to say to the server Things have to be placed in the request header (Header). The request header is used to provide some additional information to the server. For example, User-Agent is used to indicate the identity of the client and let the server know whether the request comes from a browser or a crawler, or from Chrome. The browser is still FireFox. HTTP/1.1 specifies 47 header field types. The format of the HTTP header field is very similar to the dictionary type in Python, consisting of key-value pairs separated by colons. For example:
User-Agent: Mozilla/5.0
Because when the client sends a request, the data (message) sent is composed of a string. In order to distinguish the end of the request header and the beginning of the request body, a blank line is used to represent it. When a blank line is reached, it means that this is the end of the header and the beginning of the request body.
Request body
The request body is the real content submitted by the client to the server, such as the username and password required when the user logs in. For example, file upload data, such as form information submitted when registering user information.
Now we use the original API socket module provided by Python to simulate an HTTP request to the server
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
# 1. 与服务器建立连接
s.connect(("www.seriot.ch", 80))
# 2. 构建请求行,请求资源是 index.php
request_line = b"GET /index.php HTTP/1.1"
# 3. 构建请求首部,指定主机名
headers = b"Host: seriot.ch"
# 4. 用空行标记请求首部的结束位置
blank_line = b"\r\n"
# 请求行、首部、空行这3部分内容用换行符分隔,组成一个请求报文字符串
# 发送给服务器
message = b"\r\n".join([request_line, headers, blank_line])
s.send(message)
# 服务器返回的响应内容稍后进行分析
response = s.recv(1024)
print(response)HTTP response
After the server receives the request and processes it, it returns the response content to the client. Similarly, the response content must follow a fixed format in order for the browser to parse it correctly. The HTTP response also consists of three parts: response line, response header, and response body, which correspond to the HTTP request format.
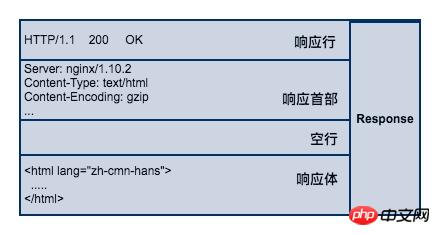
响应行
响应行同样也是3部分组成,由服务端支持的 HTTP 协议版本号、状态码、以及对状态码的简短原因描述组成。
状态码是响应行中很重要的一个字段。通过状态码,客户端可以知道服务器是否正常处理的请求。如果状态码是200,说明客户端的请求处理成功,如果是500,说明服务器处理请求的时候出现了异常。404 表示请求的资源在服务器找不到。除此之外,HTTP 协议还很定义了很多其他的状态码,不过它不是本文的讨论范围。
响应首部
响应首部和请求首部类似,用于对响应内容的补充,在首部里面可以告知客户端响应体的数据类型是什么?响应内容返回的时间是什么时候,响应体是否压缩了,响应体最后一次修改的时间。
响应体
响应体(body)是服务器返回的真正内容,它可以是一个HTML页面,或者是一张图片、一段视频等等。
我们继续沿用前面那个例子来看看服务器返回的响应结果是什么?因为我只接收了前1024个字节,所以有一部分响应内容是看不到的。
b'HTTP/1.1 200 OK\r\n Date: Tue, 04 Apr 2017 16:22:35 GMT\r\n Server: Apache\r\n Expires: Thu, 19 Nov 1981 08:52:00 GMT\r\n Set-Cookie: PHPSESSID=66bea0a1f7cb572584745f9ce6984b7e; path=/\r\n Transfer-Encoding: chunked\r\n Content-Type: text/html; charset=UTF-8\r\n\r\n118d\r\n <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">\n\n <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">\n <head>\n\t <meta http-equiv="Content-Type" content="text/html;charset=iso-8859-1" /> \n\t <meta http-equiv="content-language" content="en" />\n\t ... </html>
从结果来看,它与协议中规范的格式是一样的,第一行是响应行,状态码是200,表明请求成功。第二部分是响应首部信息,由多个首部组成,有服务器返回响应的时间,Cookie信息等等。第三部分就是真正的响应体 HTML 文本。
至此,你应该对 HTTP 协议有一个总体的认识了,爬虫的行为本质上就是模拟浏览器发送HTTP请求,所以要想在爬虫领域深耕细作,理解 HTTP 协议是必须的。
【相关推荐】
1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup
2. python爬虫入门(3)--利用requests构建知乎API
3. python爬虫入门(2)--HTTP库requests
The above is the detailed content of Getting started with python crawlers (1)--Quickly understand the HTTP protocol. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



