
 Backend Development
Python Tutorial
Python implementation of a search engine (Pylucene) example tutorial
Backend Development
Python Tutorial
Python implementation of a search engine (Pylucene) example tutorial
Python implementation of a search engine (Pylucene) example tutorial

Document, document class. The basic unit of indexing in Pylucene is "Document". A Document may be a web page, an article, or an email. Document is the unit used to build the index and is also the result unit when searching. Proper design of it can provide personalized search services.
Filed, domain class. A Document can contain multiple fields (Field). Filed is a component of Document, just like an article may be composed of multiple Files such as article title, article body, author, publication date, etc.
Treat a page as a Document, which contains three fields: the URL address of the page (url), the title of the page (title), and the main text content of the page (content). For the index storage method, choose to use the SimpleFSDirectory class to save the index to a file. The analyzer chooses CJKAnalyzer that comes with Pylucene. This analyzer has good support for Chinese and is suitable for text processing of Chinese content.
What is a search engine?
Search engine is "a system that collects and organizes network information resources and provides information query services, including three parts: information collection, information sorting and user query." Figure 1 is the general structure of a search engine. The information collection module collects information from the Internet into the network information database (generally using crawlers); then the information sorting module performs word segmentation, stop word removal, weighting and other operations on the collected information. Establish an index table (usually an inverted index) to form an index library; finally, the user query module can identify the user's retrieval needs and provide retrieval services.
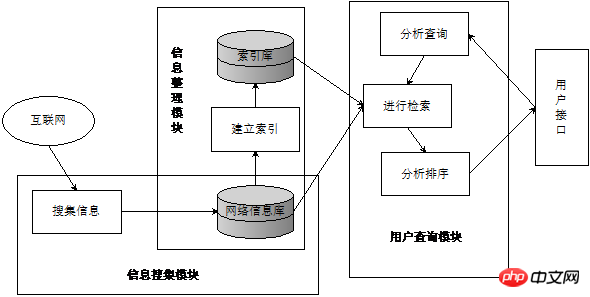
Figure 1 General structure of search engine
2. Use python to implement a simple search engine
2.1 Problem Analysis
From Figure 1, a complete search engine architecture starts from collecting information from the Internet. You can use python to write a crawler, which is the strength of python.
Next, the information processing module. Participle? Stop words? Inverted table? what? What is this mess? Don't worry about it, we have the wheel built by our predecessors---Pylucene (a python package version of lucene. Lucene can help developers add search functions to software and systems. Lucene is a set of open source libraries for full-text retrieval and search) . Using Pylucene can simply help us process the collected information, including index creation and search.
Finally, in order to use our search engine on the web page, we use flask, a lightweight web application framework, to make a small web page to obtain search statements and feedback search results.
2.2 Crawler design
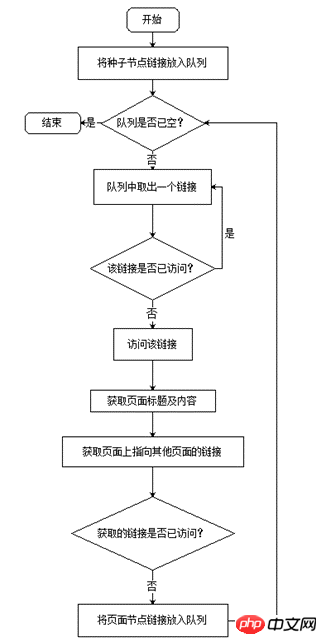
Mainly collects the following content: the title of the target web page, the main text content of the target web page, and the URL addresses of other pages that the target web page points to. The workflow of the web crawler is shown in Figure 2. The main data structure of the crawler is the queue. First, the initial seed node enters the queue, then takes out a node from the queue to access, captures the target information on the node page, then puts the URL link of the node page pointing to other pages into the queue, and then takes out the new node from the queue. nodes are accessed until the queue is empty. Through the "first in, first out" feature of the queue, a breadth-first traversal algorithm is implemented to access each page of the site one by one.
Filed.
Directory is a class for file operations in Pylucene. It has 11 subclasses such as SimpleFSDirectory, RAMDirectory, CompoundFileDirectory, and FileSwitchDirectory. The four listed are subclasses related to saving the index directory. SimpleFSDirectory saves the built index to the file system; RAMDirectory saves the index to RAM memory. Among them; CompoundFileDirectory is a compound index saving method; and FileSwitchDirectory allows temporary switching of the index saving method to take advantage of various index saving methods.
Analyzer, analyzer. It is a class that processes the text obtained by the crawler to be indexed. Including operations such as word segmentation of text, removal of stop words, and case conversion. Pylucene comes with several analyzers, and you can also use third-party analyzers or self-written analyzers when building indexes. The quality of the analyzer is related to the quality of index construction and the accuracy and speed that the search service can provide.
IndexWriter, index writing class. In the storage space opened by Directory, IndexWriter can perform operations such as writing, modifying, adding, and deleting indexes, but it cannot read or search the index.
Document, document class. The basic unit of indexing in Pylucene is "Document". A Document may be a web page, an article, or an email. Document is the unit used to build the index and is also the result unit when searching. Proper design of it can provide personalized search services.
Filed, domain class. A Document can contain multiple fields (Field). Filed is a component of Document, just like an article may be composed of multiple Files such as article title, article body, author, publication date, etc.
Treat a page as a Document, which contains three fields: the URL address of the page (url), the title of the page (title), and the main text content of the page (content). For the index storage method, choose to use the SimpleFSDirectory class to save the index to a file. The analyzer chooses CJKAnalyzer that comes with Pylucene. This analyzer has good support for Chinese and is suitable for text processing of Chinese content.
The specific steps for using Pylucene to build an index are as follows:
lucene.initVM()
INDEXIDR = self.__index_dir
indexdir = SimpleFSDirectory(File(INDEXIDR))①
analyzer = CJKAnalyzer(Version.LUCENE_30)②
index_writer = IndexWriter(indexdir, analyzer, True, IndexWriter.MaxFieldLength(512))③
document = Document()④
document.add(Field("content", str(page_info["content"]), Field.Store.NOT, Field.Index.ANALYZED))⑤
document.add(Field("url", visiting, Field.Store.YES, Field.Index.NOT_ANALYZED))⑥
document.add(Field("title", str(page_info["title"]), Field.Store.YES, Field.Index.ANALYZED))⑦
index_writer.addDocument(document)⑧
index_writer.optimize()⑨
index_writer.close()⑩
There are 10 main steps to build an index:
① Instantiate a SimpleFSDirectory object and save the index to a local file. The saved path is the customized path "INDEXIDR".
② Instantiate a CJKAnalyzer analyzer. The parameter Version.LUCENE_30 during instantiation is the version number of Pylucene.
③ Instantiate an IndexWriter object. The four parameters carried are the previously instantiated SimpleFSDirectory object and the CJKAnalyzer analyzer. The Boolean variable true indicates the creation of a new index. IndexWriter.MaxFieldLength specifies The maximum number of fields (Filed) in an index.
④ Instantiate a Document object and name it document.
⑤Add a domain named "content" to the document. The content of this field is the main text content of a web page obtained by the crawler. The parameter of this operation is the Field object that is instantiated and used immediately; the four parameters of the Field object are:
(1) "content", the name of the domain.
(2) page_info["content"], the main text content of the web page collected by the crawler.
(3) Field.Store is a variable used to indicate whether the value of this field can be restored to the original characters. Field.Store.YES indicates that the content stored in this field can be restored to the original text content. Field. Store.NOT means it is not recoverable.
(4) Field.Index variable indicates whether the content of the field should be processed by the analyzer. Field. Index.ANALYZED indicates that the analyzer is used for character processing in the field. Field. Index. NOT_ANALYZED indicates that the analyzer is not used for the field. The parser processes characters.
⑥Add a domain named "url" to save the page address.
⑦Add a field named "title" to save the title of the page.
⑧Instantiate the IndexWriter object to write the document document to the index file.
⑨Optimize the index library files and merge small files in the index library into large files.
⑩Close the IndexWriter object after the index building operation is completed in a single cycle.
Pylucene’s main classes for index search include IndexSearcher, Query, and QueryParser[16].
IndexSearcher, index search class. Used to perform search operations in the index library built by IndexWriter.
Query, the class that describes the query request. It submits the query request to IndexSearcher to complete the search operation. Query has many subclasses to complete different query requests. For example, TermQuery searches by term, which is the most basic and simple query type, and is used to match documents with specific items in a specified domain; RangeQuery, searches within a specified range, is used to match documents within a specific range in a specified domain; FuzzyQuery, a fuzzy query, can simply identify synonym matches that are semantically similar to the query keyword.
QueryParser, Query parser. When you need to implement different query requirements, you must use different subclasses provided by Query, which makes it easy to cause confusion when using Query. Therefore, Pylucene also provides Query parser QueryParser. QueryParser can parse the submitted Query statement and select the appropriate Query subclass according to the Query syntax to complete the corresponding query. Developers do not need to care about what Query implementation class is used at the bottom. For example, the Query statement "keyword 1 and keyword 2" QueryParser parses to query documents that match both keyword 1 and keyword 2; the Query statement "id[123 to 456]" QueryParser parses to query the domain whose name is "id" Documents whose value is in the specified range "123" to "456"; Query statement "keyword site:www.web.com" QueryParser parses into a query that also satisfies the value of "www.web" in the domain named "site" .com" and documents matching the two query conditions of "keyword".
Index search is one of the areas that Pylucene focuses on. A class named query is written to implement index search. Query implements index search and has the following main steps:
lucene.initVM()
if query_str.find(":") ==-1 and query_str.find(":") ==-1:
query_str="title:"+query_str+" OR content:"+query_str①
indir= SimpleFSDirectory(File(self.__indexDir))②
lucene_analyzer= CJKAnalyzer(Version.LUCENE_CURRENT)③
lucene_searcher= IndexSearcher(indir)④
my_query = QueryParser(Version.LUCENE_CURRENT,"title",lucene_analyzer).parse(query_str)⑤
total_hits = lucene_searcher.search(my_query, MAX)⑥
for hit in total_hits.scoreDocs:⑦
print"Hit Score: ", hit.score
doc = lucene_searcher.doc(hit.doc)
result_urls.append(doc.get("url").encode("utf-8"))
result_titles.append(doc.get("title").encode("utf-8"))
print doc.get("title").encode("utf-8")
result = {"Hits": total_hits.totalHits, "url":tuple(result_urls), "title":tuple(result_titles)}
return result
Index search has 7 main steps:
① First, judge the search statement. If the statement is not a single domain query for the title or article content, that is, it does not contain the keyword "title" :" or "content:", the title and content fields are searched by default.
②Instantiate a SimpleFSDirectory object and specify its working path as the path where the index was previously created.
③实例化一个CJKAnalyzer分析器,搜索时使用的分析器应与索引构建时使用的分析器在类型版本上均一致。
④实例化一个IndexSearcher对象lucene_searcher,它的参数为第○2步的SimpleFSDirectory对象。
⑤实例化一个QueryParser对象my_query,它描述查询请求,解析Query查询语句。参数Version.LUCENE_CURRENT为pylucene的版本号,“title”指默认的搜索域,lucene_analyzer指定了使用的分析器,query_str是Query查询语句。在实例化QueryParser前会对用户搜索请求作简单处理,若用户指定了搜索某个域就搜索该域,若用户未指定则同时搜索“title”和“content”两个域。
⑥lucene_searcher进行搜索操作,返回结果集total_hits。total_hits中包含结果总数totalHits,搜索结果的文档集scoreDocs,scoreDocs中包括搜索出的文档以及每篇文档与搜索语句相关度的得分。
⑦lucene_searcher搜索出的结果集不能直接被Python处理,因而在搜索操作返回结果之前应将结果由Pylucene转为普通的Python数据结构。使用For循环依次处理每个结果,将结果文档按相关度得分高低依次将它们的地址域“url”的值放入Python列表result_urls,将标题域“title”的值放入列表result_titles。最后将包含地址、标题的列表和结果总数组合成一个Python“字典”,将最后处理的结果作为整个搜索操作的返回值。
用户在浏览器搜索框输入搜索词并点击搜索,浏览器发起一个GET请求,Flask的路由route设置了由result函数响应该请求。result函数先实例化一个搜索类query的对象infoso,将搜索词传递给该对象,infoso完成搜索将结果返回给函数result。函数result将搜索出来的页面和结果总数等传递给模板result.html,模板result.html用于呈现结果
如下是Python使用flask模块处理搜索请求的代码:
app = Flask(__name__)#创建Flask实例
@app.route('/')#设置搜索默认主页
def index():
html="<h1>title这是标题</h1>"
return render_template('index.html')
@app.route("/result",methods=['GET', 'POST'])#注册路由,并指定HTTP方法为GET、POST
def result(): #resul函数
if request.method=="GET":#响应GET请求
key_word=request.args.get('word')#获取搜索语句
if len(key_word)!=0:
infoso = query("./glxy") #创建查询类query的实例
re = infoso.search(key_word)#进行搜索,返回结果集
so_result=[]
n=0
for item in re["url"]:
temp_result={"url":item,"title":re["title"][n]}#将结果集传递给模板
so_result.append(temp_result)
n=n+1
return render_template('result.html', key_word=key_word, result_sum=re["Hits"],result=so_result)
else:
key_word=""
return render_template('result.html')
if __name__ == '__main__':
app.debug = True
app.run()#运行web服务The above is the detailed content of Python implementation of a search engine (Pylucene) example tutorial. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1655
1655
 14
1413
52
1306
25
1252
29
1226
24
14
1413
52
1306
25
1252
29
1226
24

 PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP and Python: Different Paradigms Explained
Apr 18, 2025 am 12:26 AM
PHP is mainly procedural programming, but also supports object-oriented programming (OOP); Python supports a variety of paradigms, including OOP, functional and procedural programming. PHP is suitable for web development, and Python is suitable for a variety of applications such as data analysis and machine learning.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP and Python: A Deep Dive into Their History
Apr 18, 2025 am 12:25 AM
PHP originated in 1994 and was developed by RasmusLerdorf. It was originally used to track website visitors and gradually evolved into a server-side scripting language and was widely used in web development. Python was developed by Guidovan Rossum in the late 1980s and was first released in 1991. It emphasizes code readability and simplicity, and is suitable for scientific computing, data analysis and other fields.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 How to run sublime code python
Apr 16, 2025 am 08:48 AM
How to run sublime code python
Apr 16, 2025 am 08:48 AM
To run Python code in Sublime Text, you need to install the Python plug-in first, then create a .py file and write the code, and finally press Ctrl B to run the code, and the output will be displayed in the console.
 Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Where to write code in vscode
Apr 15, 2025 pm 09:54 PM
Writing code in Visual Studio Code (VSCode) is simple and easy to use. Just install VSCode, create a project, select a language, create a file, write code, save and run it. The advantages of VSCode include cross-platform, free and open source, powerful features, rich extensions, and lightweight and fast.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 How to run python with notepad
Apr 16, 2025 pm 07:33 PM
How to run python with notepad
Apr 16, 2025 pm 07:33 PM
Running Python code in Notepad requires the Python executable and NppExec plug-in to be installed. After installing Python and adding PATH to it, configure the command "python" and the parameter "{CURRENT_DIRECTORY}{FILE_NAME}" in the NppExec plug-in to run Python code in Notepad through the shortcut key "F6".
