

Suppose we have just watched Nolan's blockbuster "Interstellar", how can we let the machine automatically analyze whether the audience's evaluation of the movie is "positive" or "negative"? This type of problem is a sentiment analysis problem. The first step in dealing with this type of problem is to convert text into features. This article mainly introduces the Python text feature extraction and vectorization algorithm in detail. It has certain reference value. Interested friends can refer to it. I hope it can help everyone.
Therefore, in this chapter we only learn the first step, how to extract features from text and vectorize them.
Since the processing of Chinese involves word segmentation, this article uses a simple example to illustrate how to use Python's machine learning library to extract features from English.
1. Data preparation
Python's sklearn.datasets supports reading all classified texts from the directory. However, the directories must be placed according to the rules of one folder and one label name. For example, the data set used in this article has a total of 2 labels, one is "net" and the other is "pos", and there are 6 text files under each directory. The directory is as follows:
neg
1.txt
2.txt
......
pos
1.txt
2 .txt
....
The contents of the 12 files are summarized as follows:
##
neg: shit. waste my money. waste of money. sb movie. waste of time. a shit movie. pos: nb! nb movie! nb! worth my money. I love this movie! a nb movie. worth it!
2. Text features
How to extract emotional attitudes from these English words and classify them?We also noticed that some words are meaningless for sentiment classification. For example, words such as "of" and "I" in the above data. This type of word has a name, called "
Stop_Word" (stop word). Such words can be completely ignored and not counted. Obviously by ignoring these words, the storage space of word frequency records can be optimized and the construction speed is faster. There is also a problem in using the word frequency of each word as an important feature. For example, "movie" in the above data appears 5 times in 12 samples, but the number of positive and negative occurrences is almost the same, and there is no distinction. And "worth" appears twice, but only in the pos category. It obviously has a strong strong color, that is, the distinction is very high.
TF-IDF (Term Frequency-Inverse Document Frequency, Term frequency and reverse document frequency) to further consider each word .
TF (Word Frequency) is calculated very simply, that is, for a document t, the frequency of a certain word Nt appearing in the document. For example, in the document "I love this movie", the TF of the word "love" is 1/4. If you remove the stop words "I" and "it", it is 1/2.
IDF (Inverse Document Frequency) means that for a certain word t, the number of documents Dt in which the word appears accounts for the proportion of all test documents D. Then find the natural logarithm. For example, the word "movie" appears 5 times in total, and the total number of documents is 12, so the IDF is ln(5/12).
Obviously, IDF is to highlight the words that appear rarely but have strong emotional color. For example, the IDF of a word like "movie" is ln(12/5)=0.88, which is much smaller than the IDF of "love"=ln(12/1)=2.48.
TF-IDF is simply multiplying the two together. In this way, finding the TF-IDF of each word in each document is the text feature value we extracted.
3. Vectorization
With the above foundation, the document can be vectorized. Let’s look at the code first, and then analyze the meaning of vectorization:# -*- coding: utf-8 -*-
import scipy as sp
import numpy as np
from sklearn.datasets import load_files
from sklearn.cross_validation import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
'''''加载数据集,切分数据集80%训练,20%测试'''
movie_reviews = load_files('endata')
doc_terms_train, doc_terms_test, y_train, y_test\
= train_test_split(movie_reviews.data, movie_reviews.target, test_size = 0.3)
'''''BOOL型特征下的向量空间模型,注意,测试样本调用的是transform接口'''
count_vec = TfidfVectorizer(binary = False, decode_error = 'ignore',\
stop_words = 'english')
x_train = count_vec.fit_transform(doc_terms_train)
x_test = count_vec.transform(doc_terms_test)
x = count_vec.transform(movie_reviews.data)
y = movie_reviews.target
print(doc_terms_train)
print(count_vec.get_feature_names())
print(x_train.toarray())
print(movie_reviews.target)运行结果如下:
[b'waste of time.', b'a shit movie.', b'a nb movie.', b'I love this movie!', b'shit.', b'worth my money.', b'sb movie.', b'worth it!']
['love', 'money', 'movie', 'nb', 'sb', 'shit', 'time', 'waste', 'worth']
[[ 0. 0. 0. 0. 0. 0. 0.70710678 0.70710678 0. ]
[ 0. 0. 0.60335753 0. 0. 0.79747081 0. 0. 0. ]
[ 0. 0. 0.53550237 0.84453372 0. 0. 0. 0. 0. ]
[ 0.84453372 0. 0.53550237 0. 0. 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 1. 0. 0. 0. ]
[ 0. 0.76642984 0. 0. 0. 0. 0. 0. 0.64232803]
[ 0. 0. 0.53550237 0. 0.84453372 0. 0. 0. 0. ]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. ]]
[1 1 0 1 0 1 0 1 1 0 0 0]
python输出的比较混乱。我这里做了一个表格如下:
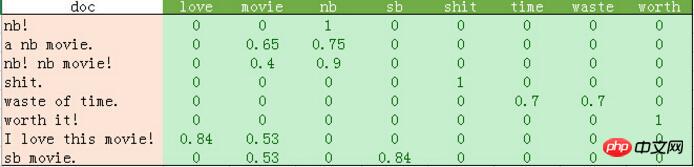
从上表可以发现如下几点:
1、停用词的过滤。
初始化count_vec的时候,我们在count_vec构造时传递了stop_words = 'english',表示使用默认的英文停用词。可以使用count_vec.get_stop_words()查看TfidfVectorizer内置的所有停用词。当然,在这里可以传递你自己的停用词list(比如这里的“movie”)
2、TF-IDF的计算。
这里词频的计算使用的是sklearn的TfidfVectorizer。这个类继承于CountVectorizer,在后者基本的词频统计基础上增加了如TF-IDF之类的功能。
我们会发现这里计算的结果跟我们之前计算不太一样。因为这里count_vec构造时默认传递了max_df=1,因此TF-IDF都做了规格化处理,以便将所有值约束在[0,1]之间。
3. The result of count_vec.fit_transform is a huge matrix. We can see that there are a lot of 0's in the above table, so sklearn uses a sparse matrix for its internal implementation. The data in this example is small. If readers are interested, you can try real data used by machine learning researchers, from Cornell University: http://www.cs.cornell.edu/people/pabo/movie-review-data/. This website provides many data sets, including several databases of about 2M, with about 700 positive and negative examples. The scale of this kind of data is not large and can still be completed within 1 minute. I suggest you give it a try. However, be aware that these data sets may have illegal character issues. So when constructing count_vec, decode_error = 'ignore' is passed in to ignore these illegal characters.
The results in the above table are the results of training 8 features of 8 samples. This result can be classified using various classification algorithms.
Related recommendations:
Share Python text generation QR code example
Detailed explanation of edit distance for Python text similarity calculation
Example detailed explanation of Python implementation of simple web page image grabbing
The above is the detailed content of Detailed explanation of Python text feature extraction and vectorization algorithm learning examples. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



