

This article mainly introduces the basics of pandas data processing and related information about filtering data in specified rows or specified columns. Friends in need can refer to it
The two main data structures of pandas are: series (equivalent to data structure in one row or column) and DataFrame (equivalent to a tabular data structure with multiple rows and columns).
For the convenience of understanding, this article will make an analogy with excel or sql operations on rows or columns
1. Reindex: reindex and ix
As introduced in the previous article, the default row index after data reading is 0,1,2,3...such sequence numbers. The column index is equivalent to the field name (i.e. the first row of data). Re-indexing here means that you can re-modify the default index to what you want.
1.1 Series
For example: data=Series([4,5,6],index=['a','b','c']), the row index is a ,b,c.
After we use data.reindex(['a','c','d','e']) to modify the index, the output will be:
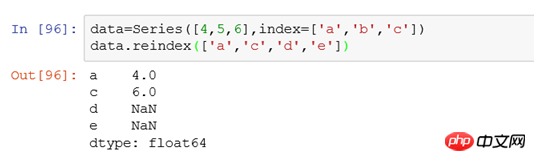
It can be understood that after we use reindex to set the index, we match the corresponding value in the original data according to the index, and the unmatched value is NaN.
1.2 DataFrame
(1) Row index modification: DataFrame row index is the same as Series
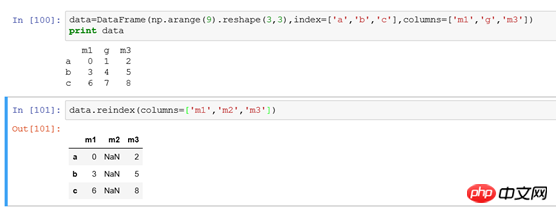
(2) Column index modification: column index uses reindex(columns=['m1' ,'m2','m3']), use the parameter columns to specify the modification of the column index. Modifying the logic is similar to the row index, which is equivalent to using the new column index to match the original data. If there is no match, set it to NaN
. Example:
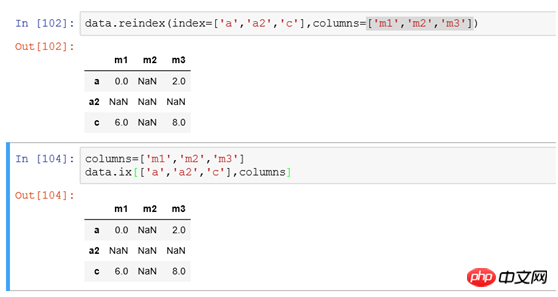
(3 ) To modify the row and column indexes at the same time, you can use
2. Discard the columns on the specified axis (in layman’s terms, delete rows or columns) :drop
Select which row or column to delete by index
data.drop(['a','c']) is equivalent to delete table a where xid='a' or xid='c'
data.drop('m1',axis=1) is equivalent to delete table a where yid='m1'
3. Selection and filtering (in layman’s terms, it means filtering queries according to conditions in SQL)
Because there is a row and column index in python, It will be more convenient to filter data
3.1 Series
(1) Select according to the row index, such as
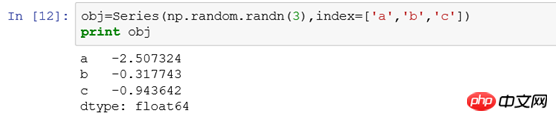
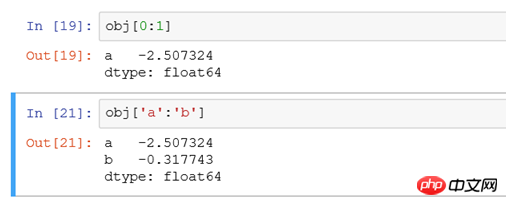
obj['b '] Equivalent to select * from tb where xid='b'obj['b','a','c'] Equivalent to select * from tb where xid in ('a' ,'b','c'), and the results are displayed in the order of b,a,c. This is the difference with sql obj[0:1] and obj['a':'b' ] The difference is as follows:
#The former does not include the end, and the latter does include the end
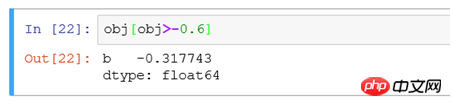
(2) Filter obj[ according to the size of the value obj>-0.6] is equivalent to finding records with values larger than -0.6 in the obj data for display
3.2 DataFrame
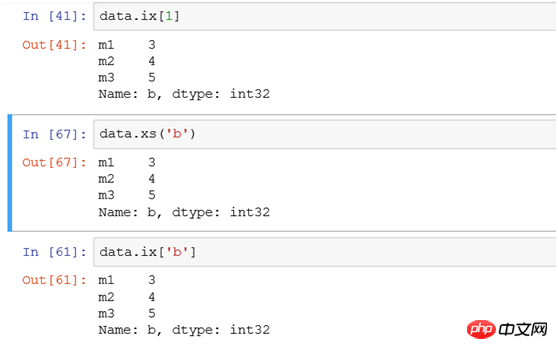
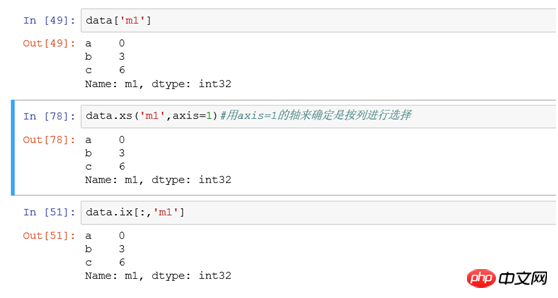
(1) Select a single row Use ix or xs:
If you filter the row record with index b, use the following three methods
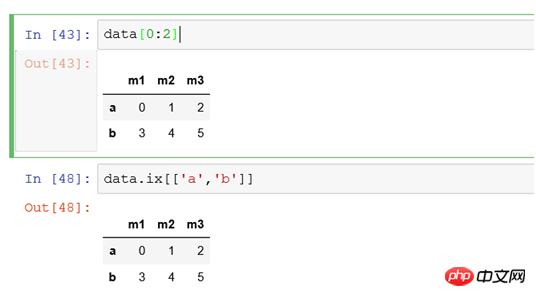

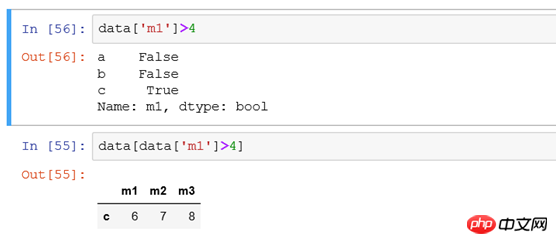
(6) If you filter all records with a column value greater than 4 and only need to display some columns
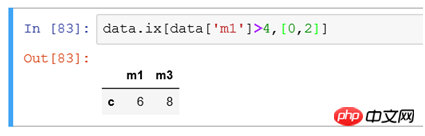
Rows are filtered using conditions, and columns are filtered using [0,2] to filter data in the first and third columns
Related recommendations:
Select rows and columns based on pandas data samples Methods
python3 pandas to read MySQL data and insert
##
The above is the detailed content of Pandas data processing basics: filter data in specified rows or specified columns. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



