

Crawler parsing method four: PyQuery

Many languages can crawl, but crawlers based on python are more concise and convenient. Crawlers have also become an essential part of the python language. There are also many ways to parse crawlers. The previous article told you about the third method of crawler analysis: regular expression. Today I bring you another method, PyQuery.

PyQuery
The PyQuery library is also a very powerful and flexible web page parsing library. If you have front-end development experience, you can use it. If you have been exposed to jQuery, then PyQuery is a very good choice for you. PyQuery is a strict implementation of Python modeled after jQuery. The syntax is almost identical to jQuery, so no more trying to remember weird methods.
There are generally three ways to pass in during initialization: pass in string, pass in url, pass in file.
String initialization
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
The results are as follows:
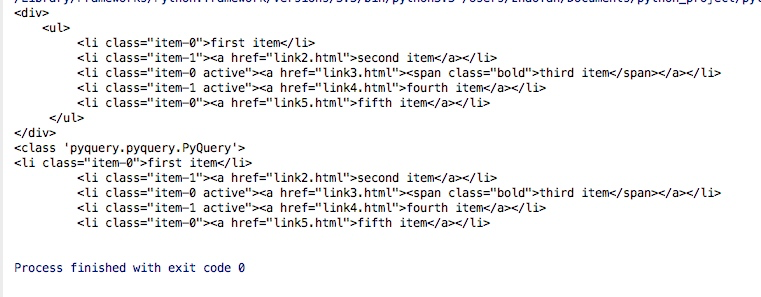
Since PyQuery is more troublesome to write, we import it Alias will be added when:
1 |
|
Here we can know that the doc in the above code is actually a pyquery object. We can select elements through doc. In fact, this is a css selector, so All CSS selector rules can be used. You can directly doc (tag name) to get all the content of the tag. If you want to get the class, then doc('.class_name'), if it is the id, then doc('#id_name') ....
URL initialization
1 2 |
|
File initialization
We can pass in url parameters or file parameters here in pq() , of course the file here is usually an html file, for example: pq(filename='index.html')
Basic CSS selector
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
One thing we need to pay attention to here is the doc ('#container .list li'), the three here do not have to be next to each other, as long as there is a hierarchical relationship, the following is the commonly used CSS selector method:
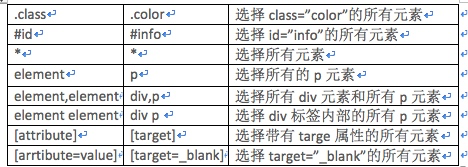
Find elements
Child elements
children,find
Code example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
The running results are as follows
We can also see from the results that the result found through pyquery is actually a pyquery object, and you can continue to search. items.find('li') in the above code means to find all li in ul. Tag
Of course, the same effect can be achieved through children, and the result obtained through the .children method is also a pyquery object
1 2 3 |
|
At the same time, the CSS selector can also be used in children
1 2 |
|
Parent element
parent,parents method
You can find the content of the parent element through .parent. The example is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
You can find the ancestor node through .parents The content, examples are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
The results are as follows: From the results we can see that two parts of content are returned, one is the information of the parent node, and the other is the information of the parent node of the parent node, that is, the information of the ancestor node
Similarly when we search through .parents, we can also add css selectors to filter the content
Sibling elements
siblings
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
In the code, .tem-0 and .active in doc('.list .item-0.active') are next to each other, so they are in a merged relationship, so there is only one left that meets the conditions: the third item That tag
In this way, you can get all the sibling tags through .siblings, of course, your own is not included here
Similarly, in .siblings(), you can also filter through the CSS selector
Traversal
Single element
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
The running results are as follows: From the results, we can see that a generator can be obtained through items(), And each element we get through the for loop is still a pyquery object.
Get information
Get attributes
pyquery object.attr(attribute name)
pyquery object.attr.attribute name
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
So here we can also know that when getting the attribute value, we can directly a.attr (attribute name) or a.attr.attribute name
Get the text
In many cases, we need to obtain the text information contained in the html tag. We can obtain the text information through .text()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
The result is as follows:

Get html
We can get the html information contained in the current tag through .html(). The example is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
The results are as follows:

DOM operation
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
1 2 3 4 5 6 7 8 9 |
|
结果如下:

The above is the detailed content of Crawler parsing method four: PyQuery. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download DeepSeek Xiaomi? Search for "DeepSeek" in the Xiaomi App Store. If it is not found, continue to step 2. Identify your needs (search files, data analysis), and find the corresponding tools (such as file managers, data analysis software) that include DeepSeek functions.
 How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
The key to using DeepSeek effectively is to ask questions clearly: express the questions directly and specifically. Provide specific details and background information. For complex inquiries, multiple angles and refute opinions are included. Focus on specific aspects, such as performance bottlenecks in code. Keep a critical thinking about the answers you get and make judgments based on your expertise.
 How to search deepseek
Feb 19, 2025 pm 05:18 PM
How to search deepseek
Feb 19, 2025 pm 05:18 PM
Just use the search function that comes with DeepSeek. Its powerful semantic analysis algorithm can accurately understand the search intention and provide relevant information. However, for searches that are unpopular, latest information or problems that need to be considered, it is necessary to adjust keywords or use more specific descriptions, combine them with other real-time information sources, and understand that DeepSeek is just a tool that requires active, clear and refined search strategies.
 How to program deepseek
Feb 19, 2025 pm 05:36 PM
How to program deepseek
Feb 19, 2025 pm 05:36 PM
DeepSeek is not a programming language, but a deep search concept. Implementing DeepSeek requires selection based on existing languages. For different application scenarios, it is necessary to choose the appropriate language and algorithms, and combine machine learning technology. Code quality, maintainability, and testing are crucial. Only by choosing the right programming language, algorithms and tools according to your needs and writing high-quality code can DeepSeek be successfully implemented.
 How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
Question: Is DeepSeek available for accounting? Answer: No, it is a data mining and analysis tool that can be used to analyze financial data, but it does not have the accounting record and report generation functions of accounting software. Using DeepSeek to analyze financial data requires writing code to process data with knowledge of data structures, algorithms, and DeepSeek APIs to consider potential problems (e.g. programming knowledge, learning curves, data quality)
 How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
Detailed explanation of DeepSeekAPI access and call: Quick Start Guide This article will guide you in detail how to access and call DeepSeekAPI, helping you easily use powerful AI models. Step 1: Get the API key to access the DeepSeek official website and click on the "Open Platform" in the upper right corner. You will get a certain number of free tokens (used to measure API usage). In the menu on the left, click "APIKeys" and then click "Create APIkey". Name your APIkey (for example, "test") and copy the generated key right away. Be sure to save this key properly, as it will only be displayed once
 Major update of Pi Coin: Pi Bank is coming!
Mar 03, 2025 pm 06:18 PM
Major update of Pi Coin: Pi Bank is coming!
Mar 03, 2025 pm 06:18 PM
PiNetwork is about to launch PiBank, a revolutionary mobile banking platform! PiNetwork today released a major update on Elmahrosa (Face) PIMISRBank, referred to as PiBank, which perfectly integrates traditional banking services with PiNetwork cryptocurrency functions to realize the atomic exchange of fiat currencies and cryptocurrencies (supports the swap between fiat currencies such as the US dollar, euro, and Indonesian rupiah with cryptocurrencies such as PiCoin, USDT, and USDC). What is the charm of PiBank? Let's find out! PiBank's main functions: One-stop management of bank accounts and cryptocurrency assets. Support real-time transactions and adopt biospecies
 What are the current AI slicing tools?
Nov 29, 2024 am 10:40 AM
What are the current AI slicing tools?
Nov 29, 2024 am 10:40 AM
Here are some popular AI slicing tools: TensorFlow DataSetPyTorch DataLoaderDaskCuPyscikit-imageOpenCVKeras ImageDataGenerator
