


我们在做爬虫的时候,经常会遇到这种情况,爬虫最初运行的时候,数据是可以正常获取的,一切看起来都那么的美好,然而,不一会儿,就可能会出现
403 Forbidden, 然后你会打开网站看一眼,可能会看到”您的IP访问频率过高,请稍后重试“。 出现这种情况的时候,通常这种情况,我们会使用代理IP来隐藏自身IP,来实现大量抓取。国内的代理常用的产品多达几十种,而当我们需要爬取海外网站的时候,这些个代理是都不能用的,所以我们今天使用的是一款Ipidea的全球代理。
使用起来和国内的相差不大,可以根据需求,选在指定国家,或者全球混播,通过api接口调用,指定提取数量,也可以指定接口返回数据格式,有txt,json,html等,这里就以全球混播、json格式为例,获取代理,单次获取1个,python代码如下:
import requestsurl = "http://tiqu.linksocket.com:81/abroad?num=1&type=2&pro=0&city=0&yys=0&port=1&flow=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=0®ions=www&n=0&f=1"resp = requests.get(url)# 成功获取到的数据为:{'code': 0, 'data': [{'ip': '47.74.232.57', 'port': 21861}], 'msg': '0', 'success': True}data = resp.json().get('data')[0]proxy = {"http": "http://%s:%d" % (data.get("ip"), data.get("port")),"https": "https://%s:%d" % (data.get("ip"), data.get("port"))}
在获取ip之前,我们要通过个人中心设置IP白名单,否则是无法获取到数据的。
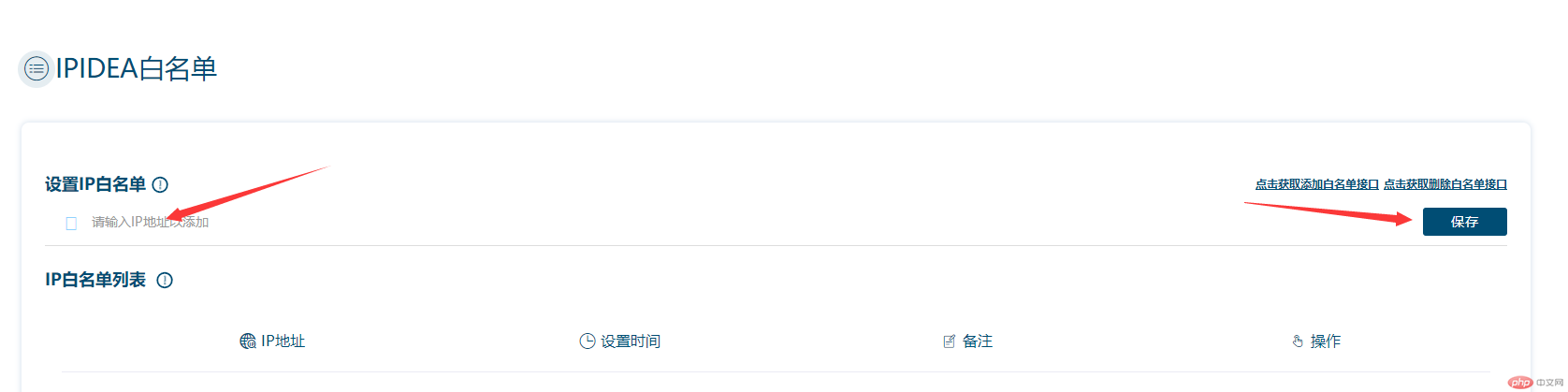
把你本机公网填入保存即可(官方也提供了接口添加或删除白名单),若不知道公网IP为多少,可以通过百度搜索IP即可。
爬虫demo如下,这里以六度新闻为例:
import requestsurl = "http://tiqu.linksocket.com:81/abroad?num=1&type=2&pro=0&city=0&yys=0&port=1&flow=1&ts=0&ys=0&cs=0&lb=1&sb=0&pb=4&mr=0®ions=www&n=0&f=1"def get_proxy():"""获取代理"""resp = requests.get(url)data = resp.json().get('data')[0]proxy = {"http": "http://%s:%d" % (data.get("ip"), data.get("port")),"https": "https://%s:%d" % (data.get("ip"), data.get("port"))}return proxydef download_html(url):"""获取url接口数据"""resp = requests.get(url,proxies=get_proxy())return resp.json()def run():"""主程序:return:"""url = "https://6do.news/api/tag/114?page=1"content = download_html(url)# 数据处理略if __name__ == '__main__':run()
数据如图:
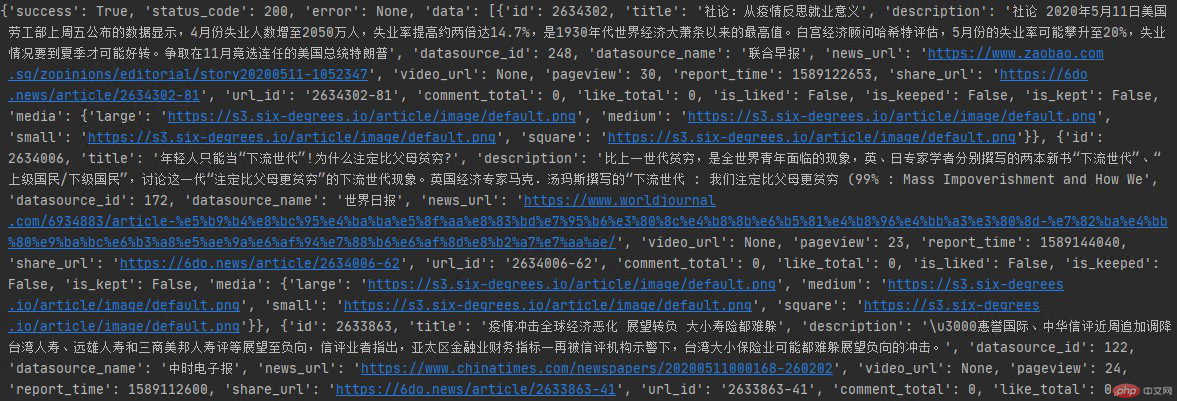
前后端分离的接口,对于爬虫来说还是比较友好的,数据提取起来比较方便,这里就不做过多处理,根据需求提取数据即可。
如果在爬虫中挂不上代理,请检查是否添加白名单。
本次海外网站的采集教程到这里就结束了,详细交流欢迎与我联系。
本文章旨在用于交流分享,【未经允许,谢绝转载】









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



