



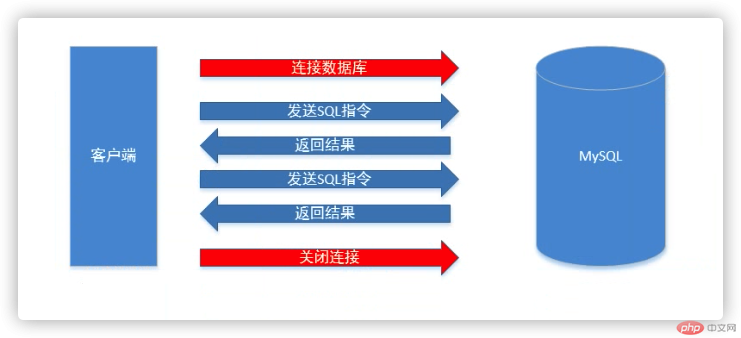
mysql -hlocalhost -P3306 -u'username' -p'password'
| host | -h | 主机 |
|---|---|---|
| port | -P | 端口号 |
| user | -u | 用户名 |
| Password | -p | 密码 |
-h链接本地可以省略,-P默认端口可以省略
退出
数据库:数据库中存放的是表,一个数据库可以存放多个表
表:表是用来存放数据的
关系: 两个表的公共字段
行:也称记录,也称实体
列:也称字段,也称属性
就表结构而言,表分为行和列。就数据而言,表分为记录和字段。面向对象而言,一个记录就是一个实体,一个字段就是一个属性。
冗余只能减少,不能杜绝冗余减少的方法就是分表,同时降低查询速度
正确性+完整性

正确性:数据类型正确准确性:数据范围要准确
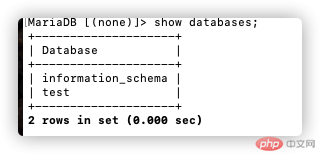
show databases;
create database [if not exists] 数据名 [选项]

#特殊字符创建数据库需要用反引号包括#创建数据库时指定使用的字符编码#如果不指定字符编码,数据库默认使用安装数据库时的指定编码create database `emp` charset=gbk;
语法:
drop database [if exists] `database-name`;
语法:
show create database database-name;
语法:
#修改数据库的字符编码alter database database-name charest=utf8;
语法:
use database-name;
语法:
create table [if not exists] `表名`(`字段名` 数据类型 [null|no null][default][auto_incremment][primary key][comment],`字段名` 数据类型 [null|no null][default][auto_incremment][primary key][comment])[engine=][charset=utf8]null|no null 是否为空default 默认值auto_incremment 自动增长primary key 主键 值不能为空,每个表只有一个主键comment 备注engine 引擎决定了数据的储存和查找 myisam、innodb
#设置客户端和服务器通讯的编码MariaDB [data]> set names gbk;Query OK, 0 rows affected (0.000 sec)#创建简单的表MariaDB [data]> create table stu1(-> id int auto_increment primary key,-> bane varchar(20) not null-> )engine=innodb ;Query OK, 0 rows affected (0.008 sec)#创建复杂的表MariaDB [data]> create table stu2(-> id int auto_increment primary key comment '主键',-> name varchar(20) not null comment '姓名',-> score int default '0' comment '成绩可以为空'-> )engine=innodb;Query OK, 0 rows affected (0.007 sec)
小结:
如果不指定引擎,默认是innodb
如果不指定编码,默认和数据库一样
innodb 一个表对应一个表结构,innodb的所有表的数据都保存在ibdatak文件中,如果数据量很大,会自动创建ibdata2、ibdata3···
| 引擎 | |
| ——— | —————————————————————————————— |
| myisam | 查询速度快、容易产生碎片、不能约束数据 |
| innodb | 以前没有myisam速度快,现在已经提速了、不产生碎片、可以约束数据 |
推荐使用innodb。
语法:
show create table; --结果横着排列show create table stu2\G; --结果竖着排列
语法:
desc[ribe] stu2;
MariaDB [data]> decsribe stu2;ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'decsribe stu2' at line 1MariaDB [data]> describe stu2;+-------+-------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------+-------------+------+-----+---------+----------------+| id | int(11) | NO | PRI | NULL | auto_increment || name | varchar(20) | NO | | NULL | || score | int(11) | YES | | 0 | |+-------+-------------+------+-----+---------+----------------+3 rows in set (0.002 sec)
语法:
drop table [if exists] stu4,stu3,stu2;
#删除一个表MariaDB [data]> drop table if exists sut4;Query OK, 0 rows affected, 1 warning (0.000 sec)#删除多个表MariaDB [data]> drop table if exists sut4,stu3;Query OK, 0 rows affected, 2 warnings (0.000 sec)
语法一:
create table stu3 select id form stu2;
#不能复制主键,只能复制数据
语法二:
create table stu4 like stu2;
#只能复制表结构,不能复制数据
小结:*代表所有数据
语法:
alter table stu2;
添加字段:alter table 表名add [column] 字段名 数据类型 [位置]
``mysql
MariaDB [data]> alter table stu addadd` varchar(20); — 默认添加的字段放在末尾
Query OK, 0 rows affected (0.007 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [data]> alter table stu add sex char(1) after name; — 放在某个之后
Query OK, 0 rows affected (0.006 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [data]> alter table stu add age int first; — 放在最前面
Query OK, 0 rows affected (0.006 sec)
Records: 0 Duplicates: 0 Warnings: 0
2. 删除字段:alter table 表名drop [column]字段名```mysqlMariaDB [data]> desc stu;+-------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-------+-------------+------+-----+---------+-------+| age | int(11) | YES | | NULL | || id | int(11) | YES | | NULL | || name | varchar(20) | YES | | NULL | || sex | char(1) | YES | | NULL | || add | varchar(20) | YES | | NULL | |+-------+-------------+------+-----+---------+-------+5 rows in set (0.001 sec)MariaDB [data]> alter table stu drop age; -- 删除字段Query OK, 0 rows affected (0.010 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [data]> desc stu;+-------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-------+-------------+------+-----+---------+-------+| id | int(11) | YES | | NULL | || name | varchar(20) | YES | | NULL | || sex | char(1) | YES | | NULL | || add | varchar(20) | YES | | NULL | |+-------+-------------+------+-----+---------+-------+4 rows in set (0.001 sec)
修改字段(改名):alter table 表change[column]原字段名 新字段名 数据类型
```mysql
— 将name字段改为stuname
MariaDB [data]> alter table stu change name stuname varchar(20);
Query OK, 0 rows affected (0.007 sec)
Records: 0 Duplicates: 0 Warnings: 0
MariaDB [data]> desc stu
-> ;
+————-+——————-+———+——-+————-+———-+
| Field | Type | Null | Key | Default | Extra |
+————-+——————-+———+——-+————-+———-+
| id | int(11) | YES | | NULL | |
| stuname | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| add | varchar(20) | YES | | NULL | |
+————-+——————-+———+——-+————-+———-+
4 rows in set (0.001 sec)
4. 修改字段:alter table 表 modify 字段名 字段属性·```mysql-- 将sex数据类型更改为varchar(20)MariaDB [data]> alter table stu modify sex varchar(20);Query OK, 0 rows affected (0.015 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [data]> desc stu;+---------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+---------+-------------+------+-----+---------+-------+| id | int(11) | YES | | NULL | || stuname | varchar(20) | YES | | NULL | || sex | varchar(20) | YES | | NULL | || add | varchar(20) | YES | | NULL | |+---------+-------------+------+-----+---------+-------+4 rows in set (0.001 sec)-- 将add数据类型更改为varchar(20)默认值‘where?’MariaDB [data]> alter table stu modify `add` varchar(20) default 'where?';Query OK, 0 rows affected (0.006 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [data]> desc stu;+---------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+---------+-------------+------+-----+---------+-------+| id | int(11) | YES | | NULL | || stuname | varchar(20) | YES | | NULL | || sex | varchar(20) | YES | | NULL | || add | varchar(20) | YES | | where? | |+---------+-------------+------+-----+---------+-------+4 rows in set (0.001 sec)
修改引擎:later table 表名engine= 引擎名
-- 修改表的引擎MariaDB [data]> alter table stu engine=myisam;Query OK, 0 rows affected (0.008 sec)Records: 0 Duplicates: 0 Warnings: 0
修改表名 alter table 表名 rename 新表名
-- 将表名改为新表名MariaDB [data]> alter table stu rename stu1;Query OK, 0 rows affected (0.000 sec)MariaDB [data]> show tables;+----------------+| Tables_in_data |+----------------+| stu1 |+----------------+1 row in set (0.000 sec)
将表移动到其他数据库
-- 将当前数据库的表移动到目标数据库MariaDB [data]> alter table stu rename to php.stu;Query OK, 0 rows affected (0.001 sec)
语法:insert into
-- 插入数据,null为yes时可以为空MariaDB [php]> insert into stu (id,stuname,sex,`add`) values (1,'tom','man','beijing');Query OK, 1 row affected (0.004 sec)
-- 插入控值为null-- 插入默认值为defaultMariaDB [php]> insert into stu values(5,'jake',null,default);Query OK, 1 row affected (0.000 sec)MariaDB [php]> select * from stu;+------+---------+-------+-----------+| id | stuname | sex | add |+------+---------+-------+-----------+| 1 | tom | man | beijing || 2 | jerry | woman | beijing || 3 | ros | woman | chongqing || 5 | jake | NULL | where? |+------+---------+-------+-----------+4 rows in set (0.000 sec)
小结:
插入字段名的顺序和表中的顺序可以不一致插入值的个数、顺序必须和插入字段名的个数、顺序要一致
语法:update 表名 set 字段=值[where条件]
-- 将tom的性别给为woman-- 多个链接MariaDB [php]> update stu set sex='woman' where stuname='tom';Query OK, 1 row affected (0.000 sec)Rows matched: 1 Changed: 1 Warnings: 0MariaDB [php]> select * from stu;+------+---------+-------+-----------+| id | stuname | sex | add |+------+---------+-------+-----------+| 1 | tom | woman | beijing || 2 | jerry | woman | beijing || 3 | ros | woman | chongqing || 5 | jake | NULL | where? || 6 | 李白 | man | hunan || 7 | 杜甫 | man | wuhan |+------+---------+-------+-----------+6 rows in set (0.000 sec)
语法:delete from 表名[where条件]
-- 删除stuname为tom的数据MariaDB [php]> delete from stu where stuname='tom';Query OK, 1 row affected (0.000 sec)MariaDB [php]> select * from stu;+------+---------+-------+-----------+| id | stuname | sex | add |+------+---------+-------+-----------+| 2 | jerry | woman | beijing || 3 | ros | woman | chongqing || 5 | jake | NULL | where? || 6 | 李白 | man | hunan || 7 | 杜甫 | man | wuhan |+------+---------+-------+-----------+5 rows in set (0.000 sec)
技巧:
delete from 表 :遍历记录,一条一条删除truncate table 表 :删除表在重新建立表结构(效率更高)
语法:
select 列名 from 表名
-- 从stu查询id数据MariaDB [php]> select id,stuname from stu;Empty set (0.000 sec)
发现:插入数据的时候,如果有中文会报错或者无法插入
可用set names utf8;直接更改client、connection、result
设置什么编码取决于客户端的编码
查看客户端发送的编码
查看服务器接受,返回的编码
MariaDB [(none)]> show variables like 'character_set_%';
-- 更改编码MariaDB [(none)]> set character_set_client=utf8;Query OK, 0 rows affected (0.000 sec)
collate = 校对集 #创建表时可加入
校对集规则
_bin 区分大小写
_ci 不区分大小写
严格模式
sql-mode="...,STRICT_TRANS_TABLES"
插入数据时主键冲突
-- 语法一replace into stu values (id, 'name')# 原理:如果插入的主键不重复就直接插入,如果主键重复就替换(删除原来的记录,插入新记录)-- 语法二on duplicate key update #当插入的值与主键冲突,执行 update操作# 插入的数据和主键或唯一键起冲突,更新字段内容
delimiter // -- 改变定界符
mysql中的数据类型是强类型
| 整型 | 占用字节 | 范围 | 无符号 |
|---|---|---|---|
| tinyint | 1 | -128~127 | 0-256 |
| samllint | 2 | -32768~32767 | |
| mwdiumint | 3 | -8388608~8388607 | |
| int | 4 | -247483648~2147483647 | |
| bigint | 8 | -9223372036854775808~9223372036854775807 |
例题:
-- 数据类型:选择范围尽量的小,占用的资源就小MariaDB [learn]> create table stu;ERROR 1113 (42000): A table must have at least 1 columnMariaDB [learn]> create table stu(-> id tinyint,-> name varchar(20)-> );Query OK, 0 rows affected (0.112 sec)
无符号整型(unsigned) 无符号整型就是没有负数,是整数的两倍
整型支持显示宽度,显示宽度是最小的显示位数,如int(11)表示最小占用11位表示,可用zerofill填充
MariaDB [learn]> create table stu1(-> id tinyint unsigned,-> num int(5) zerofill-> );Query OK, 0 rows affected (0.006 sec)MariaDB [learn]> insert into stu1 values (12,12);Query OK, 1 row affected (0.001 sec)MariaDB [learn]> select * from stu1;+------+-------+| id | num |+------+-------+| 12 | 00012 |+------+-------+1 row in set (0.000 sec)
| 单词 | 意思 |
|---|---|
| nity | 微小的 |
| medium | 中间的 |
| big | 大的 |
| unsigned | 无符号的 |
| 浮点型 | |
|---|---|
| float | 4 |
| double | 8 |
浮点型的声明:float(m,d)、 double(m,d)
m:总位数 d:小数位数
-- mysql支持科学计数法MariaDB [learn]> insert into stu2 values (5E10),(7E-6);Query OK, 2 rows affected (0.001 sec)Records: 2 Duplicates: 0 Warnings: 0MariaDB [learn]> select * from stu2;+-------------+| id |+-------------+| 50000000000 || 0.000007 |+-------------+2 rows in set (0.000 sec)
-- 浮动数精度会丢失MariaDB [learn]> insert into stu2 values (99.9999999999);Query OK, 1 row affected (0.000 sec)MariaDB [learn]> select * from stu2;+------+| id |+------+| 100 |+------+1 row in set (0.000 sec)
原理:将小数部分和整数部分分开存储
语法:
decimal(m,d)
例题:
MariaDB [learn]> alter table stu3 modify num decimal(20,11);Query OK, 0 rows affected (0.013 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [learn]> insert into stu3 values (12.99999999999);Query OK, 1 row affected (0.001 sec)MariaDB [learn]> select * from stu3;+----------------+| num |+----------------+| 12.99999999999 |+----------------+1 row in set (0.000 sec)
deciaml是变长的,m最大为65,d最大时30,默认为(10,2)定点数和浮点数都支持无符号和zerofill
在数据库中没有字符串概念,只有字符
| 数据类型 | 描述 |
|---|---|
| char | 定长字符,最大可到255 |
| varchar | 可变长字符, 最大可到65535 |
| tinytext | 8个字节 |
| text | 16个字节 |
| mediumtext | 24个字节 |
| longtext | 32个字节 |
变长字符的剩余空间会自动回收
一条整个记录的所有字段的总长度不能超过65535
text系列的类型在表中储存的是地址,占用大约10个字节
从集合中选择一个值作为数据(单选)
MariaDB [learn]> create table stu4(-> name varchar(20),-> sex enum('男','女','保密') #枚举-> );Query OK, 0 rows affected (0.006 sec)MariaDB [learn]> insert into stu4 values ('tom', '男');-- 插入值部位每句集合中的数据会报错Query OK, 1 row affected (0.001 sec)MariaDB [learn]> select * from stu4;+------+------+| name | sex |+------+------+| tom | 男 |+------+------+1 row in set (0.000 sec)
枚举值是通过整型数字来管理的
MariaDB [learn]> insert into stu4 values ('berry', 2);Query OK, 1 row affected (0.000 sec)MariaDB [learn]> select * from stu4;+-------+------+| name | sex |+-------+------+| tom | 男 || berry | 女 |+-------+------+2 rows in set (0.000 sec)
限制值节省空间运行速度快
思考:枚举占用两个字节,所以枚举最多有65536,范围是(0-65535),由于枚举从1开始,枚举最多65535个
从集合中选择一个值作为数据(多选)
MariaDB [learn]> alter table stu3 add hobby set ('爬山','游泳','睡觉','吃饭');Query OK, 0 rows affected (0.006 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [learn]> insert into stu3 values (12.00,'admin','游泳,爬山');Query OK, 1 row affected (0.000 sec)MariaDB [learn]> select * from stu3 ;+----------------+-------+---------------+| num | name | hobby |+----------------+-------+---------------+| 12.00000000000 | admin | 爬山,游泳 |+----------------+-------+---------------+1 row in set (0.000 sec)MariaDB [learn]>
集合和枚举一样,为每个集合属性分配一个固定值,分配方式是从前往后按2的0、1、2、、、次方,转换为二进制的只有一位是1,其他都是0。
'爬山','游泳','睡觉','吃饭'MariaDB [learn]> select * from stu3 ;+----------------+-------+---------------+| num | name | hobby |+----------------+-------+---------------+| 12.00000000000 | admin | 爬山,游泳 |+----------------+-------+---------------+1 row in set (0.000 sec)MariaDB [learn]> select hobby+0 from stu3;+---------+| hobby+0 |+---------+| 3 |+---------+1 row in set (0.000 sec)
集合占8个字节,最多可以有64个选项
| 数据类型 | 占用 |
|---|---|
| datetime | 日期时间占用8个字节 |
| date | 日期占用3个字节 |
| time | 时间占用3个字节 |
| year | 年份占用1个字节 |
| timestamp | 时间戳占用4个字节 |
mysql不支持布尔型,存储为1和0boolean型在mysql中对应tinyint型
null表示字段值可以为空not null 表示字段值不能为空
可以用default关键字,替代默认值。
字段值从1开始,每次递增1,自动增长不会有重复,适合用来生成唯一的id。在mysql中只要是自动增长列必须为主键。
唯一标示表中的记录的一个或一组列称为主键特点:不能重复、不能为空一个表只能有一个主键作用:保证数据完整性加快查询速度选择主键的原则最少性:尽量选单个键作为主键稳定性:尽量选择数值更新少的列作为主键
-- 创建主键方法一MariaDB [learn]> create table stu3(-> id int auto_increment primary key,-> name varchar(20)-> );Query OK, 0 rows affected (0.006 sec)-- 创建主键的方法二MariaDB [learn]> create table stue(-> id int ,-> name varchar(20),-> primary key(id)-> );Query OK, 0 rows affected (0.006 sec)-- 组合键创建主键方法MariaDB [learn]> create table stu3(-> classname char,-> name varchar(20),-> primary key(classname,name)-> );Query OK, 0 rows affected (0.006 sec)MariaDB [learn]> desc stu3;+-----------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-----------+-------------+------+-----+---------+-------+| classname | char(1) | NO | PRI | NULL | || name | varchar(20) | NO | PRI | NULL | |+-----------+-------------+------+-----+---------+-------+2 rows in set (0.002 sec)
#添加主键MariaDB [learn]> alter table sut3 add primary key (id);Query OK, 0 rows affected (0.008 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [learn]> desc sut3;+-------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-------+-------------+------+-----+---------+-------+| id | int(11) | NO | PRI | NULL | || name | varchar(20) | NO | | NULL | |+-------+-------------+------+-----+---------+-------+2 rows in set (0.001 sec)#删除主键MariaDB [learn]> alter table sut3 drop primary key ;Query OK, 0 rows affected (0.021 sec)Records: 0 Duplicates: 0 Warnings: 0MariaDB [learn]> desc sut3;+-------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-------+-------------+------+-----+---------+-------+| id | int(11) | NO | | NULL | || name | varchar(20) | NO | | NULL | |+-------+-------------+------+-----+---------+-------+2 rows in set (0.001 sec)
小结:1. 只要是auto_increment必须是主键,但是主键不一定auto_increment2. 主键的特点是不能重复不能为空3. 一个表只能有一个主键,但是一个主键可以有多个字段组成4. 自动增长列通过插入null值让其递增5. 自动增长列的数据被删除,默认不再重复使用。truncate table 删除数据就会从1开始。
| 键 | 区别 |
|---|---|
| 主键 | 不能重复,不能为空<br />一个表只能有一个主键 |
| 唯一键 | 不能重复,可以为空<br />一个表可以有多个唯一键 |
-- 创建唯一键MariaDB [learn]> create table stu3(-> id int auto_increment primary key,-> name varchar(20) unique -- 唯一键-> );Query OK, 0 rows affected (0.006 sec)-- 方法二MariaDB [learn]> create table stu3(-> id int ,-> name varchar(20)-> ,unique (name)-> );Query OK, 0 rows affected (0.007 sec)-- 修改表添加唯一键-- 添加多个用,分开MariaDB [learn]> alter table stu3 add unique (id);Query OK, 0 rows affected (0.007 sec)Records: 0 Duplicates: 0 Warnings: 0-- 查看唯一键的名字MariaDB [learn]> show create table stu3\G;*************************** 1. row ***************************Table: stu3Create Table: CREATE TABLE `stu3` (`id` int(11) DEFAULT NULL,`name` varchar(20) DEFAULT NULL,UNIQUE KEY `id` (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb41 row in set (0.000 sec)-- 通过唯一键的名字删除唯一键MariaDB [learn]> alter table stu3 drop index name;Query OK, 0 rows affected (0.007 sec)Records: 0 Duplicates: 0 Warnings: 0
说明性文本属于SQL代码的一部分
MariaDB [learn]> create table stu4(-> id int primary key, -- 主键-> name varchar(20) not null, #姓名-> sex tinyint-> )-> /*/*> 这是一个学生表/*> */
主键约束唯一约束标识符
数据类型约束非空约束默认值约束
主外键约束
储存过程触发器
主表中没有的记录,从表不允许插入从表中有的记录,主表不允许删除
从表中的公共字段。alter table 从表 foreign 从表公共字段 references 主表公共字段alter table 从表 drop foreign key 外键的名字小结:只有innodb才能支持外键公共字段的名字可以不一样,但数据类型要一样。
严格限制
置空操作(set null )
foreign 从表公共字段 references 主表公共字段 on delete set null
级联操作(cascade)
foreign 从表公共字段 references 主表公共字段 on update cascade
小结:置空、级联操作中外键不能是从表的主键
主表中的一条记录对应从表中的多条记录实现一对多的关系:主键和非主键建立关系例子:班主任表--学生表品牌表--商品表

主表中的一条记录对应从表中的一条记录实现一对一的关系:主键和主键键了关系一个表为什么分成两个表:

非主键和非主键之间的关系实现:引入第三方关系表



实体对应表属性对应字段如果没有合适的主键,可以添加一个自增长键。
确保每列的原子性,一个字段表示一个信息
非主键要依赖于主键
非主键之间不能有效应关系
性能比规范化更重要
语法:select [选项] 列名 [from表名][where条件][group by 分组][order by 排序][having 条件][limit限制]
-- 可以直接输出内容MariaDB [book]> select 10*10;+-------+| 10*10 |+-------+| 100 |+-------+1 row in set (0.000 sec)-- 可以输出表达式MariaDB [book]> select ch,math,ch+math from stu;+------+------+---------+| ch | math | ch+math |+------+------+---------+| 80 | NULL | NULL || 77 | 76 | 153 || 55 | 82 | 137 || NULL | 74 | NULL || 72 | 56 | 128 || 86 | 92 | 178 || 74 | 67 | 141 || 65 | 67 | 132 || 88 | 77 | 165 |+------+------+---------+9 rows in set (0.000 sec)-- 表达式部分可以用函数MariaDB [book]> select rand();+--------------------+| rand() |+--------------------+| 0.3300995624904517 |+--------------------+1 row in set (0.000 sec)
MariaDB [book]> select ch,math,ch+math as '总分' from stu;+------+------+--------+| ch | math | 总分 |+------+------+--------+| 80 | NULL | NULL || 77 | 76 | 153 || 55 | 82 | 137 || NULL | 74 | NULL || 72 | 56 | 128 || 86 | 92 | 178 || 74 | 67 | 141 || 65 | 67 | 132 || 88 | 77 | 165 |+------+------+--------+9 rows in set (0.000 sec)-- as可以省略的MariaDB [book]> select ch,math,ch+math '总分' from stu;+------+------+--------+| ch | math | 总分 |+------+------+--------+| 80 | NULL | NULL || 77 | 76 | 153 || 55 | 82 | 137 || NULL | 74 | NULL || 72 | 56 | 128 || 86 | 92 | 178 || 74 | 67 | 141 || 65 | 67 | 132 || 88 | 77 | 165 |+------+------+--------+9 rows in set (0.000 sec)
from:来自,from后面跟的原可以有多个源,返回笛卡尔积。
dual伪表是为乐保持语句完整性
跟条件,在数据源中进行筛选
-- 查询大于等于MariaDB [book]> select * from stu where ch >= 60;+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL || s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 || s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 |+--------+--------------+--------+--------+---------+------------+------+------+7 rows in set (0.001 sec)-- 查询大于等于MariaDB [book]> select * from stu where ch >= 60 and math >=60;+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 || s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 |+--------+--------------+--------+--------+---------+------------+------+------+5 rows in set (0.000 sec)-- 查询需要或语句MariaDB [book]> select * from stu where ch < 60 or math <60;+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 |+--------+--------------+--------+--------+---------+------------+------+------+2 rows in set (0.000 sec)
将查询的结果分组,分组查询目的在于统计数据
MariaDB [book]> select stusex,avg(ch) '平均分' from stu group by stusex;+--------+-----------+| stusex | 平均分 |+--------+-----------+| 女 | 72.2500 || 男 | 77.0000 |+--------+-----------+2 rows in set (0.001 sec)-- --------MariaDB [book]> select stuaddress,count(*) from stu group by stuaddress;+------------+----------+| stuaddress | count(*) |+------------+----------+| 上海 | 1 || 北京 | 3 || 天津 | 2 || 河北 | 2 || 河南 | 1 |+------------+----------+5 rows in set (0.000 sec)
通过group_concat()函数将同一组的值连接起来
MariaDB [book]> select group_concat(stuname),stusex,avg(math) from stu group by stusex;+---------------------------------------------------+--------+-----------+| group_concat(stuname) | stusex | avg(math) |+---------------------------------------------------+--------+-----------+| 李斯文,诸葛丽丽,梅超风,Tabm | 女 | 70.5000 || 张秋丽,李文才,欧阳俊雄,争青小子,Tom | 男 | 77.2500 |+---------------------------------------------------+--------+-----------+2 rows in set (0.000 sec)
如果是分组字段,查询字段必须是分组字段和聚合函数查询字段是普通字段,只取第一个值
多列分组
MariaDB [book]> select stuaddress,stusex,avg(math) from stu group by stusex,stuaddress;+------------+--------+-----------+| stuaddress | stusex | avg(math) |+------------+--------+-----------+| 北京 | 女 | 82.0000 || 河北 | 女 | 72.0000 || 河南 | 女 | 56.0000 || 上海 | 男 | 76.0000 || 北京 | 男 | 67.0000 || 天津 | 男 | 83.0000 |+------------+--------+-----------+6 rows in set (0.000 sec)
asc:升序
desc:降序
默认为升序
-- 拿年龄的升序排序MariaDB [book]> select * from stu order by stuage asc;+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL || s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 || s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | NULL | 74 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 |+--------+--------------+--------+--------+---------+------------+------+------+9 rows in set (0.000 sec)-- 按总分排序MariaDB [book]> select *,ch+math '总分' from stu order by ch+math desc;+--------+--------------+--------+--------+---------+------------+------+------+--------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math | 总分 |+--------+--------------+--------+--------+---------+------------+------+------+--------+| s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 | 178 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 | 165 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 | 153 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 | 141 || s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 | 137 || s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 | 132 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 | 128 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL | NULL || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | NULL | 74 | NULL |+--------+--------------+--------+--------+---------+------------+------+------+--------+9 rows in set (0.000 sec)
-- 多列MariaDB [book]> select * from stu order by stuage asc,ch desc;+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL || s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 || s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | 86 | 92 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | NULL | 74 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 |+--------+--------------+--------+--------+---------+------------+------+------+
结果集中进行条件筛选
MariaDB [book]> select * from stu where stusex='女';+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 |+--------+--------------+--------+--------+---------+------------+------+------+4 rows in set (0.001 sec)-- ------MariaDB [book]> select * from stu having stusex='女';+--------+--------------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+--------------+--------+--------+---------+------------+------+------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | 72 | 56 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | 74 | 67 || s25321 | Tabm | 女 | 23 | 9 | 河北 | 88 | 77 |+--------+--------------+--------+--------+---------+------------+------+------+4 rows in set (0.000 sec)
语法:limit起始位置,显示长度
MariaDB [book]> select * from stu limit 0,3;+--------+-----------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+-----------+--------+--------+---------+------------+------+------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL || s25302 | 李文才 | 男 | 31 | 3 | 上海 | 77 | 76 || s25303 | 李斯文 | 女 | 22 | 2 | 北京 | 55 | 82 |+--------+-----------+--------+--------+---------+------------+------+------+3 rows in set (0.001 sec)
limit 在update和delete语句中使用。
MariaDB [book]> update stu set ch=ch+1 order by ch+math desc limit 3;Query OK, 3 rows affected (0.000 sec)Rows matched: 3 Changed: 3 Warnings: 0
all: 显示所有数据distinct:去除重复数据
sum() 求和avg() 求平均值max() 求最大值min() 求最小值count() 求记录数
_代表任意一个字符%代表任意字符
MariaDB [book]> select * from stu where stuname like 'T_m';+--------+---------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+---------+--------+--------+---------+------------+------+------+| s25320 | Tom | 男 | 24 | 8 | 北京 | 65 | 67 |+--------+---------+--------+--------+---------+------------+------+------+1 row in set (0.000 sec)MariaDB [book]> select * from stu where stuname like '张%';+--------+-----------+--------+--------+---------+------------+------+------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | ch | math |+--------+-----------+--------+--------+---------+------------+------+------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | 80 | NULL |+--------+-----------+--------+--------+---------+------------+------+------+1 row in set (0.000 sec)
语法:select 语句 union [选项] select 语句 union [选项] select 语句将多个select的语句的结果集纵向连接起来all:显示所有数据discinct:去除重复的数据(默认)结果默认去除重复
union 两边的select 语句的字段个数必须一致union 两边的select 语句的字段名可以不一样,按第一个select 语句的字段名union 两边的select 语句中的数据类型可以不一致
规则:返回两个表的公共记录
-- 语法一select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段-- 语法二select * from 表1,表2 where 表1.公共字段=表2.公共字段
-- inner joinMariaDB [book]> select * from stuinfo inner join stumarks on stuinfo.stuno=stumarks.stuno;+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam |+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 |+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+5 rows in set (0.002 sec)-- where 联合查询MariaDB [book]> select * from stuinfo,stumarks where stuinfo.stuno=stumarks.stuno;+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam |+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 |+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+5 rows in set (0.000 sec)-- 取消重复显示方法MariaDB [book]> select stuinfo.stuno,stuname,stusex,stuage, stuseat,writtenexam,labexam from stuinfo,stumarks where stuinfo.stuno=stumarks.stuno;+--------+--------------+--------+--------+---------+-------------+---------+| stuno | stuname | stusex | stuage | stuseat | writtenexam | labexam |+--------+--------------+--------+--------+---------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 56 | 48 |+--------+--------------+--------+--------+---------+-------------+---------+5 rows in set (0.001 sec)
内联之中inner可以省略select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段MariaDB [book]> select * from stuinfo join stumarks on stuinfo.stuno=stumarks.stuno;+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam |+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 |+--------+--------------+--------+--------+---------+------------+---------+--------+-------------+---------+5 rows in set (0.000 sec)-- 表连接越多,效率越低-- 如何实现三表查询select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段 inner join 表3 on 表2.公共字段=表3.公共字段
规则:以左边的表为准,右边如果没有对应的记录用null显示
语法:select * from 表1 left join 表2 on 表1.公共字段=表2.公共字段
MariaDB [book]> select stuname,writtenexam,labexam from stuinfo left join stumarks on stuinfo.stuno=stumarks.stuno;+--------------+-------------+---------+| stuname | writtenexam | labexam |+--------------+-------------+---------+| 李斯文 | 80 | 58 || 李文才 | 50 | 90 || 欧阳俊雄 | 65 | 50 || 张秋丽 | 77 | 82 || 争青小子 | 56 | 48 || 诸葛丽丽 | NULL | NULL || 梅超风 | NULL | NULL |+--------------+-------------+---------+7 rows in set (0.005 sec)
select * from 表1 left join 表2 on 表1.公共字段=表2.公共字段和select * from 表2 left join 表1 on 表1.公共字段=表2.公共字段 一样吗?答:不一样,第一个SQL以表1为准,第二个SQL以表2为准。
规则:以右边的表为准,左边如果没有对应的记录用null显示
语法:select * from 表1 right join 表2 on 表1.公共字段=表2.公共字段
MariaDB [book]> select stuinfo.stuname,writtenexam,labexam from stuinfo right join stumarks on stuinfo.stuno=stumarks.stuno;+--------------+-------------+---------+| stuname | writtenexam | labexam |+--------------+-------------+---------+| 李斯文 | 80 | 58 || 李文才 | 50 | 90 || 欧阳俊雄 | 65 | 50 || 张秋丽 | 77 | 82 || 争青小子 | 56 | 48 || NULL | 66 | 77 |+--------------+-------------+---------+6 rows in set (0.000 sec)
语法,返回笛卡尔积
语法:select * from 表1 cross join 表2
-- 交叉连接mysql> select * from stuinfo cross join stumarks;-- 交叉连接有连接表达式与内连接是一样的mysql> select * from stuinfo cross join stumarks on stuinfo.stuno=stumarks.stuno;+--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | stuNo | writtenExam | labExam |+--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | s25303 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | s25302 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | s25304 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | s25301 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | s25318 | 56 | 48 |+--------+----------+--------+--------+---------+------------+---------+--------+-------------+---------+5 rows in set (0.00 sec)
小结1、交叉连接如果没有连接条件返回笛卡尔积2、如果有连接条件和内连接是一样的。
自动判断条件连接,判断的条件是依据同名字段如果没同名字段返回笛卡尔积同名字段只显示一个,并自动放在最前面
natural join
MariaDB [book]> select * from stuinfo natural join stumarks;+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | writtenExam | labExam |+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | 56 | 48 |+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+5 rows in set (0.000 sec)
natural left join
MariaDB [book]> select * from stuinfo natural left join stumarks;+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | writtenExam | labExam |+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | 56 | 48 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 | NULL | NULL | NULL || s25319 | 梅超风 | 女 | 23 | 5 | 河北 | NULL | NULL | NULL |+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+7 rows in set (0.000 sec)
natural right join
MariaDB [book]> select * from stuinfo natural right join stumarks ;+--------+---------+-------------+---------+--------------+--------+--------+---------+------------+| stuNo | examNo | writtenExam | labExam | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+---------+-------------+---------+--------------+--------+--------+---------+------------+| s25303 | s271811 | 80 | 58 | 李斯文 | 女 | 22 | 2 | 北京 || s25302 | s271813 | 50 | 90 | 李文才 | 男 | 31 | 3 | 上海 || s25304 | s271815 | 65 | 50 | 欧阳俊雄 | 男 | 28 | 4 | 天津 || s25301 | s271816 | 77 | 82 | 张秋丽 | 男 | 18 | 1 | 北京 || s25318 | s271819 | 56 | 48 | 争青小子 | 男 | 26 | 6 | 天津 || s25320 | s271820 | 66 | 77 | NULL | NULL | NULL | NULL | NULL |+--------+---------+-------------+---------+--------------+--------+--------+---------+------------+6 rows in set (0.000 sec)
用来指定连接字段
MariaDB [book]> select * from stuinfo inner join stumarks using(stuno);+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress | examNo | writtenExam | labExam |+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 | s271811 | 80 | 58 || s25302 | 李文才 | 男 | 31 | 3 | 上海 | s271813 | 50 | 90 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 | s271815 | 65 | 50 || s25301 | 张秋丽 | 男 | 18 | 1 | 北京 | s271816 | 77 | 82 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 | s271819 | 56 | 48 |+--------+--------------+--------+--------+---------+------------+---------+-------------+---------+5 rows in set (0.000 sec)
using的结果也会对公共字段进行优化,优化的规则和自然连接一样
语法:select * from 表1 where (子查询)外面的查询称为父查询子查询为父查询提供查询条件
MariaDB [book]> select * from stuinfo where stuno=(select stuno from stumarks where writtenexam=80);+--------+-----------+--------+--------+---------+------------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+-----------+--------+--------+---------+------------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 |+--------+-----------+--------+--------+---------+------------+1 row in set (0.002 sec)
MariaDB [book]> select * from stuinfo where stuno=(select stuno from stumarks where writtenexam=(select max(writtenexam) from stumarks));+--------+-----------+--------+--------+---------+------------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+-----------+--------+--------+---------+------------+| s25303 | 李斯文 | 女 | 22 | 2 | 北京 |+--------+-----------+--------+--------+---------+------------+1 row in set (0.001 sec)
特点:返回值的是一列如果子查询的结果为多条记录,用in或not in
特点:返回值为一行
特点:将子查询作为表名如果将子查询当成一个表来看,必须给结果集取别名
作用:提高查询效率
视图是一张虚拟表,它表示一张表的部分数据或多张表的综合数据,其结构和数据是建立在对表的查询基础上视图中并不存放数据,而是存放在视图所引用的原始表(基表)中同一张原始表,根据不同用户的不同需求,可以创建不同的视图
筛选表中的行防止未经许可的用户访问敏感数据隐藏数据表的结构降低数据表的复杂程度
语法:-- 创建create view 试图名asselect 语句;-- 查询视图select 列名 from 视图
-- 语法alter view 视图名asselect 语句;
语法drop view [if exists] 视图1,视图2
-- 查看所有的表和视图show tables;-- 查看视图select table_name from information_schema.views #查看表和视图的详细状态信息show table status where comment='view'\G; #只查看视图信息-- 查看视图的结构信息desc view1;-- 查看视图的创建语句show create view view1;
视图的算法和表的算法不一样merge:合并算法temptable:临时表算法undefined:未定义算法(用哪种算法由mysql决定,这是默认算法,视图一般会选merge算法)重新通过视图create or replace algorithm=tmptable view view3asselect * from stu order by stusex;
事务(TRANSACTION)是一个整体,要么一起执行,要么一起不执行
原子性:事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行,要么都不执行一致性:当事务完成时,数据必须处于一致状态隔离性:对数据进行修改的所有并发事务是彼此隔离的。永久性:事务完成后,它对数据库的修改被永久保持。
-- 开启事务start transaction 或begin [work]-- 回滚事务rollback-- 提交事务commit-- 设置事务的回滚点savepoint-- 自动提交事务
事务是事务开始的时候开始提交事务、回滚事务后事务结束只有innodb支持事务每个SQL语句都是一个事务
优点:加快查询速度缺点:带索引的表在数据库中需要更多的存储空间增、删、改命令需要更长的处理时间,因为他们需要对索引进行更新
适合创建索引的列:该列用于频繁搜索该列用于对数据进行排序在where\join出现的列不适合创建索引的列:列中仅包含几个值表中仅包含几行,数据量很少
创建了主键就会自动的创建主键索引
唯一索引
创建唯一键就创建了唯一索引create unique index ix_name on t5(name)
-- 创建表的时候添加普通索引
删除索引
drop index 索引名 on 表名
数字类
-- rand()获取随机数MariaDB [book]> select * from stuinfo order by rand() limit 1;+--------+-----------+--------+--------+---------+------------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+-----------+--------+--------+---------+------------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 |+--------+-----------+--------+--------+---------+------------+1 row in set (0.000 sec)-- round() 四舍五入MariaDB [book]> select round(3.1415926,3);+--------------------+| round(3.1415926,3) |+--------------------+| 3.142 |+--------------------+1 row in set (0.000 sec)-- truncate()截取数据MariaDB [book]> select truncate(3.1415926,3)-> ;+-----------------------+| truncate(3.1415926,3) |+-----------------------+| 3.141 |+-----------------------+1 row in set (0.000 sec)-- ceil() 向上取整MariaDB [book]> select ceil(3.1415926)-> ;+-----------------+| ceil(3.1415926) |+-----------------+| 4 |+-----------------+1 row in set (0.000 sec)-- floor 向下取整MariaDB [book]> select floor(3.9)-> ;+------------+| floor(3.9) |+------------+| 3 |+------------+1 row in set (0.000 sec)
-- 大小写转换mysql> select ucase('i name is tom') '转成大写',lcase('My Name IS TOM') '转成小写';+---------------+----------------+| 转成大写 | 转成小写 |+---------------+----------------+| I NAME IS TOM | my name is tom |+---------------+----------------+1 row in set (0.00 sec)-- 截取字符串mysql> select left('abcdef',3) '从左边截取',right('abcdef',3) '从右边截取',substring('abcdef',2,3) '字符串';+------------+------------+--------+| 从左边截取 | 从右边截取 | 字符串 |+------------+------------+--------+| abc | def | bcd |+------------+------------+--------+1 row in set (0.00 sec)-- 字符串相连mysql> select concat('中国','北京','顺义') '地址';+--------------+| 地址 |+--------------+| 中国北京顺义 |+--------------+1 row in set (0.00 sec)mysql> select concat(stuname,'-',stusex) 信息 from stuinfo;+-------------+| 信息 |+-------------+| 张秋丽-男 || 李文才-男 || 李斯文-女 || 欧阳俊雄-男 || 诸葛丽丽-女 || 争青小子-男 || 梅超风-女 |+-------------+7 rows in set (0.00 sec)-- coalesce(str1,str2) :str1有值显示str1,如果str1为空就显示str2-- 将成绩为空的显示为缺考mysql> select stuname,coalesce(writtenexam,'缺考'),coalesce(labexam,'缺考') from stuinfo natural left join stumarks;+----------+------------------------------+--------------------------+| stuname | coalesce(writtenexam,'缺考') | coalesce(labexam,'缺考') |+----------+------------------------------+--------------------------+| 张秋丽 | 77 | 82 || 李文才 | 50 | 90 || 李斯文 | 80 | 58 || 欧阳俊雄 | 65 | 50 || 诸葛丽丽 | 缺考 | 缺考 || 争青小子 | 56 | 48 || 梅超风 | 缺考 | 缺考 |+----------+------------------------------+--------------------------+7 rows in set (0.02 sec)-- length():字节长度,char_length():字符长度mysql> select length('锄禾日当午') 字节,char_length('锄禾日当午') 字符;+------+------+| 字节 | 字符 |+------+------+| 10 | 5 |+------+------+1 row in set (0.00 sec)
-- 时间戳MariaDB [book]> select unix_timestamp();+------------------+| unix_timestamp() |+------------------+| 1591236240 |+------------------+1 row in set (0.000 sec)-- 格式化时间戳MariaDB [book]> select from_unixtime(unix_timestamp());+---------------------------------+| from_unixtime(unix_timestamp()) |+---------------------------------+| 2020-06-04 10:05:22 |+---------------------------------+1 row in set (0.000 sec)-- 获取当前格式化时间MariaDB [book]> select now();+---------------------+| now() |+---------------------+| 2020-06-04 10:05:47 |+---------------------+1 row in set (0.000 sec)-- 获取年,月,日,小时,分钟,秒mysql> select year(now()) 年,month(now()) 月,day(now()) 日,hour(now()) 小时,minute(now()) 分钟,second(now())秒;+------+------+------+------+------+------+| 年 | 月 | 日 | 小时 | 分钟 | 秒 |+------+------+------+------+------+------+| 2019 | 6 | 12 | 17 | 10 | 48 |+------+------+------+------+------+------+1 row in set (0.00 sec)-- 星期,本年第几天;mysql> select dayname(now()) 星期,dayofyear(now()) 本年第几天;+-----------+------------+| 星期 | 本年第几天 |+-----------+------------+| Wednesday | 163 |+-----------+------------+1 row in set (0.00 sec)MariaDB [book]> select monthname(now())-> ;+------------------+| monthname(now()) |+------------------+| June |+------------------+1 row in set (0.000 sec)-- 日期相减mysql> select datediff(now(),'2010-08-08') 相距天数;+----------+| 相距天数 |+----------+| 3230 |+----------+1 row in set (0.00 sec)
-- md5加密mysql> select md5('aa');+----------------------------------+| md5('aa') |+----------------------------------+| 4124bc0a9335c27f086f24ba207a4912 |+----------------------------------+1 row in set (0.00 sec)-- sha加密mysql> select sha('aa');+------------------------------------------+| sha('aa') |+------------------------------------------+| e0c9035898dd52fc65c41454cec9c4d2611bfb37 |+------------------------------------------+1 row in set (0.00 sec)
每个代码的段的执行都要经历:词法分析——语法分析——编译——执行
预编译一次,可以多次执行。用来解决一条SQL语句频繁执行的问题。
预处理语句:prepare 预处理名字 from ‘sql语句’执行预处理:execute 预处理名字 [using 变量]
-- 创建预处理mysql> prepare stmt from 'select * from stuinfo';Query OK, 0 rows affected (0.06 sec)Statement prepared-- 执行预处理mysql> execute stmt;+--------+----------+--------+--------+---------+------------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+----------+--------+--------+---------+------------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 || s25302 | 李文才 | 男 | 31 | 3 | 上海 || s25303 | 李斯文 | 女 | 22 | 2 | 北京 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 || s25305 | 诸葛丽丽 | 女 | 23 | 7 | 河南 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 || s25319 | 梅超风 | 女 | 23 | 5 | 河北 |+--------+----------+--------+--------+---------+------------+7 rows in set (0.00 sec)
-- 创建带有位置占位符的预处理语句mysql> prepare stmt from 'select * from stuinfo where stuno=?' ;Query OK, 0 rows affected (0.00 sec)Statement prepared-- 调用预处理,并传参数mysql> delimiter //mysql> set @id='s25301';-> execute stmt using @id //Query OK, 0 rows affected (0.00 sec)+--------+---------+--------+--------+---------+------------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+---------+--------+--------+---------+------------+| s25301 | 张秋丽 | 男 | 18 | 1 | 北京 |+--------+---------+--------+--------+---------+------------+1 row in set (0.00 sec)
mysql> prepare stmt from 'select * from stuinfo where stuage>? and stusex=?' //Query OK, 0 rows affected (0.00 sec)Statement preparedmysql> set @age=20;-> set @sex='男';-> execute stmt using @age,@sex //Query OK, 0 rows affected (0.00 sec)Query OK, 0 rows affected (0.00 sec)+--------+----------+--------+--------+---------+------------+| stuNo | stuName | stuSex | stuAge | stuSeat | stuAddress |+--------+----------+--------+--------+---------+------------+| s25302 | 李文才 | 男 | 31 | 3 | 上海 || s25304 | 欧阳俊雄 | 男 | 28 | 4 | 天津 || s25318 | 争青小子 | 男 | 26 | 6 | 天津 |+--------+----------+--------+--------+---------+------------+3 rows in set (0.00 sec)
小结:1、MySQL中变量以@开头2、通过set给变量赋值3、?是位置占位符
数据库中的数据需要定期备份
mysqldump 数据库连接 数据库 > SQL文件备份地址
-- 将data数据库中所有的表导出到data.sql中F:\wamp\PHPTutorial\MySQL\bin>mysqldump -uroot -proot data>c:\data.sql-- 将data数据库中的stuinfo、stumarks表F:\wamp\PHPTutorial\MySQL\bin>mysqldump -uroot -proot data stuinfo stumarks>c:\data.sql-- 导出data数据库,导出的语句中带有创建数据库的语法F:\wamp\PHPTutorial\MySQL\bin>mysqldump -uroot -proot -B data>c:\data1.sql
mysql> source c:/data.sql;注意:地址分隔符用斜线,不能用反斜线mysql 连接数据库 导入的数据库名 < 导入的SQL文件mysql -uroot -proot data1 < c:\data.sql









![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



