








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




 PHPz
PHPzCorrection status:qualified
Teacher's comments:



<script>const ul = document.createElement("ul");document.body.append(ul);for (let i = 0; i < 5; i++) {const li = document.createElement("li");li.textContent = "item" + (i + 1);ul.append(li);}console.log(ul);console.log(ul.outerHTML);</script>
关键的操作都在上面的代码中,很直观。最后的两句输出的结果如下所示:
outerHTML是元素的html字符串表示
const three = document.querySelector("ul li:nth-of-type(3)");const li = document.createElement("li");li.textContent = "new item";li.style.color = "red";three.before(li);let cloneli = li.cloneNode(true);three.after(cloneli);

函数名称都说明了函数的功能。注意一点,cloneNode如果没有参数true,就不是深克隆,那么节点的文本内容等属性就不能复制过去。
const h3 = document.createElement("h3");h3.textContent = "商品列表";ul.insertAdjacentElement("beforeBegin", h3);

还有afterBegin,beforeEnd,afterEnd.
const last = document.querySelector("ul li:last-of-type");const a = document.createElement("a");a.href = "https://php.cn";a.textContent = "php.cn";ul.replaceChild(a, last);

ul.lastElementChild.remove();
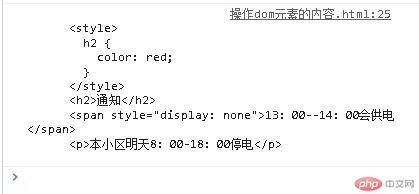
<body><div class="box"><style>h2 {color: red;}</style><h2>通知</h2><span style="display: none">13:00--14:00会供电</span><p>本小区明天8:00-18:00停电</p></div><script>const box = document.querySelector(".box");console.log(box.textContent);</script></body>

拿到的是内部所有标签的文本内容,不显示(display:none)的也能拿到
和它类比,还有一个很很很常用的是innerText.
console.log(box.innerText);

一对比就能看出来,哪些style,display:none等它不拿。
还有一个innerHTML,是最好理解的,内部所有的HTML都取出来。看例子
console.log(box.innerHTML);
innerText在2016年才成为W3C的标准,textContent兼容更好一些。
let p = document.createElement("p");let url = '<a href="https://php.cn"> php.cn </a>';p.innerText = url;box.append(p);

let p = document.createElement("p");let url = '<a href="https://php.cn"> php.cn </a>';p.innerHTML = url;box.append(p);

这个是返回当前自身的HTML字符串
console.log(box.outerHTML);box.outerHTML = null; // 清空,当然也可以替换成其他内容,用null清空。
