

Hbase的协处理器

1.起因(Why HBase Coprocessor) HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(0.92)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce Job才能得到。虽
1.起因(Why HBase Coprocessor)
HBase作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执行求和、计数、排序等操作。比如,在旧版本的(
2.灵感来源( Source of Inspration)
HBase协处理器的灵感来自于Jeff Dean 09年的演讲( P66-67)。它根据该演讲实现了类似于bigtable的协处理器,包括以下特性:
- 每个表服务器的任意子表都可以运行代码
- 客户端的高层调用接口(客户端能够直接访问数据表的行地址,多行读写会自动分片成多个并行的RPC调用)
- 提供一个非常灵活的、可用于建立分布式服务的数据模型
- 能够自动化扩展、负载均衡、应用请求路由
3.细节剖析(Implementation)
协处理器分两种类型,系统协处理器可以全局导入region server上的所有数据表,表协处理器即是用户可以指定一张表使用协处理器。协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件。一个是观察者(observer),类似于关系数据库的触发器。另一个是终端(endpoint),动态的终端有点像存储过程。
3.1观察者(Observer)
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法,而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例,它提供了三种观察者接口:
- RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan等。
- WALObserver:提供WAL相关操作钩子。
- MasterObserver:提供DDL-类型的操作钩子。如创建、删除、修改数据表等。
这些接口可以同时使用在同一个地方,按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBase API中。不过这些API可能会由于各种原因有所改动,不同版本的接口改动比较大,具体参考Java Doc。
RegionObserver工作原理,如图1所示。更多关于Observer细节请参见HBaseBook的第9.6.3章节。

图1 RegionObserver工作原理
3.2终端(Endpoint)
终端是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。终端的使用,如下面流程所示:
- 定义一个新的protocol接口,必须继承CoprocessorProtocol.
- 实现终端接口,该实现会被导入region环境执行。
- 继承抽象类BaseEndpointCoprocessor.
- 在客户端,终端可以被两个新的HBase Client API调用 。单个region:HTableInterface.coprocessorProxy(Class
protocol, byte[] row) 。rigons区域:HTableInterface.coprocessorExec(Class protocol, byte[] startKey, byte[] endKey, Batch.Call callable)
整体的终端调用过程范例,如图2所示:
图2 终端调用过程范例
4.编程实践(Code Example)
在该实例中,我们通过计算HBase表中行数的一个实例,来真实感受协处理器 的方便和强大。在旧版的HBase我们需要编写MapReduce代码来汇总数据表中的行数,在0.92以上的版本HBase中,只需要编写客户端的代码即可实现,非常适合用在WebService的封装上。
4.1启用协处理器 Aggregation(Enable Coprocessor Aggregation)
我们有两个方法:1.启动全局aggregation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现,只需要添加如下代码:
<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">property</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">name</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span>hbase.coprocessor.user.region.classes<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">name</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">value</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span>org.apache.hadoop.hbase.coprocessor.AggregateImplementation<span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">value</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span> <span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)"></span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(128,0,0)">property</span><span style="margin:0px; padding:0px; line-height:1.8; color:rgb(0,0,255)">></span></span></span></span>
2.启用表aggregation,只对特定的表生效。通过HBase Shell 来实现。
(1)disable指定表。hbase> disable 'mytable'
(2)添加aggregation hbase> alter 'mytable', METHOD => 'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.AggregateImplementation||'
(3)重启指定表 hbase> enable 'mytable'
4.2统计行数代码(Code Snippet)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.coprocessor.AggregationClient;
import org.apache.hadoop.hbase.client.coprocessor.LongColumnInterpreter;
import org.apache.hadoop.hbase.coprocessor.ColumnInterpreter;
import org.apache.hadoop.hbase.util.Bytes;
public class MyAggregationClient {
private static final byte[] TABLE_NAME = Bytes.toBytes("bigtable1w");
private static final byte[] CF = Bytes.toBytes("bd");
public static void main(String[] args) throws Throwable {
Configuration customConf = new Configuration();
customConf.set("hbase.zookeeper.quorum",
"192.168.58.101");
//提高RPC通信时长
customConf.setLong("hbase.rpc.timeout", 600000);
//设置Scan缓存
customConf.setLong("hbase.client.scanner.caching", 1000);
Configuration configuration = HBaseConfiguration.create(customConf);
AggregationClient aggregationClient = new AggregationClient(
configuration);
Scan scan = new Scan();
//指定扫描列族,唯一值
scan.addFamily(CF);
//long rowCount = aggregationClient.rowCount(TABLE_NAME, null, scan);
long rowCount = aggregationClient.rowCount(TableName.valueOf("bigtable1w"), new LongColumnInterpreter(), scan);
System.out.println("row count is " + rowCount);
}
}
4.3 典型例子
协处理器其中的一个作用是使用Observer创建二级索引。先举个实际例子:
我们要查询指定店铺指定客户购买的订单,首先有一张订单详情表,它以被处理后的订单id作为rowkey;其次有一张以客户nick为rowkey的索引表,结构如下:
rowkey family
dp_id+buy_nick1 tid1:null tid2:null ...
dp_id+buy_nick2 tid3:null
...
该表可以通过Coprocessor来构建,实例代码:


- public class TestCoprocessor extends BaseRegionObserver {
- @Override
- public void prePut(final ObserverContextRegionCoprocessorEnvironment> e,
- final Put put, final WALEdit edit, final boolean writeToWAL)
- throws IOException {
- Configuration conf = new Configuration();
- HTable table = new HTable(conf, "index_table");
- ListKeyValue> kv = put.get("data".getBytes(), "name".getBytes());
- IteratorKeyValue> kvItor = kv.iterator();
- while (kvItor.hasNext()) {
- KeyValue tmp = kvItor.next();
- Put indexPut = new Put(tmp.getValue());
- indexPut.add("index".getBytes(), tmp.getRow(), Bytes.toBytes(System.currentTimeMillis()));
- table.put(indexPut);
- }
- table.close();
- }
- }
即继承BaseRegionObserver类,实现prePut方法,在插入订单详情表之前,向索引表插入索引数据。
4.4索引表的使用
先在索引表get索引表,获取tids,然后根据tids查询订单详情表。当有多个查询条件(多张索引表),根据逻辑运算符(and 、or)确定tids。
4.5使用时注意
1.索引表是一张普通的hbase表,为安全考虑需要开启Hlog记录日志。
2.索引表的rowkey最好是不可变量,避免索引表中产生大量的脏数据。
3.如上例子,column是横向扩展的(宽表),rowkey设计除了要考虑region均衡,也要考虑column数量,即表不要太宽。建议不超过3位数。
4.如上代码,一个put操作其实是先后向两张表put数据,为保证一致性,需要考虑异常处理,建议异常时重试。
4.6效率情况
put操作效率不高,如上代码,每插入一条数据需要创建一个新的索引表连接(可以使用htablepool优化),向索引表插入数据。即耗时是双倍的,对hbase的集群的压力也是双倍的。当索引表有多个时,压力会更大。
查询效率比filter高,毫秒级别,因为都是rowkey的查询。
如上是估计的效率情况,需要根据实际业务场景和集群情况而定,最好做预先测试。
4.7Coprocessor二级索引方案优劣
优点:在put压力不大、索引region均衡的情况下,查询很快。
缺点:业务性比较强,若有多个字段的查询,需要建立多张索引表,需要保证多张表的数据一致性,且在hbase的存储和内存上都会有更高的要求

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1667
1667
 14
1426
52
1328
25
1273
29
1255
24
14
1426
52
1328
25
1273
29
1255
24

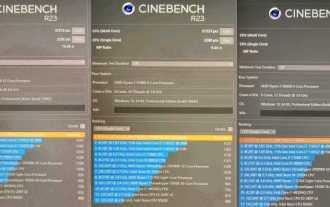 AMD Ryzen 9900X, 9700X, 9600X Prozessor Cinebench R23-Laufergebnisse veröffentlicht, mit einer durchschnittlichen Steigerung von 10–15 %
Jul 29, 2024 am 11:38 AM
AMD Ryzen 9900X, 9700X, 9600X Prozessor Cinebench R23-Laufergebnisse veröffentlicht, mit einer durchschnittlichen Steigerung von 10–15 %
Jul 29, 2024 am 11:38 AM
Laut Nachrichten dieser Website vom 29. Juli sind Prozessoren der AMD Ryzen 9000-Serie jetzt auf JD.com buchbar. Die erste Charge von vier Modellen wird am 15. August auf den Markt kommen. Die Evaluierungsdaten dieser Prozessoren werden am 14. August, einen Tag vor ihrem Verkaufsstart, veröffentlicht. Einige Medien oder Institutionen haben jedoch vorab Muster erhalten und mit dem Testen begonnen, so auch die laufenden Bewertungsdaten der Prozessoren R99900X, R79700X und R59600X durchgesickert. ▲Bildquelle: @9550pro Insgesamt wird erwartet, dass der Wechsel von Zen4 zu Zen5 eine Verbesserung der Single-Core-Leistung um 10 % bis 15 % und eine Verbesserung der Multi-Core-Leistung um 10 % bis 13 % mit sich bringt, die TDP ist jedoch etwas geringer niedriger als die der Ryzen 7000-Serie, was auch mit den offiziellen IPC-Verbesserungsdaten von AMD übereinstimmt. Ryzen
 144-Kerne, 3D-gestapelter SRAM: Fujitsu stellt den Rechenzentrumsprozessor MONAKA der nächsten Generation vor
Jul 29, 2024 am 11:40 AM
144-Kerne, 3D-gestapelter SRAM: Fujitsu stellt den Rechenzentrumsprozessor MONAKA der nächsten Generation vor
Jul 29, 2024 am 11:40 AM
Laut Nachrichten dieser Website vom 28. Juli berichteten die ausländischen Medien TechRader, dass Fujitsu den FUJITSU-MONAKA-Prozessor (im Folgenden als MONAKA bezeichnet) detailliert vorgestellt habe, dessen Auslieferung im Jahr 2027 geplant sei. MONAKACPU basiert auf der „Cloud Native 3D Many-Core“-Architektur und übernimmt den Arm-Befehlssatz. Es ist auf die Bereiche Rechenzentrum, Edge und Telekommunikation ausgerichtet. Es ist für KI-Computing geeignet und kann RAS1 auf Mainframe-Ebene realisieren. Fujitsu sagte, dass MONAKA einen Sprung in puncto Energieeffizienz und Leistung machen wird: Dank Technologien wie der Ultra-Low-Voltage-Technologie (ULV) kann die CPU im Jahr 2027 die doppelte Energieeffizienz von Konkurrenzprodukten erreichen, und für die Kühlung ist keine Wasserkühlung erforderlich Darüber hinaus kann die Anwendungsleistung des Prozessors doppelt so hoch sein wie die Ihres Konkurrenten. In puncto Anleitung ist MONAKA mit Vector ausgestattet
 AMD Ryzen 9 9950X übertaktet auf 6,6 GHz, CineBench R23 erreichte eine maximale Punktzahl von 55296 Punkten
Jul 17, 2024 pm 09:49 PM
AMD Ryzen 9 9950X übertaktet auf 6,6 GHz, CineBench R23 erreichte eine maximale Punktzahl von 55296 Punkten
Jul 17, 2024 pm 09:49 PM
Laut Nachrichten dieser Website demonstrierte das AMDXOC-Team am 16. Juli den geladenen Medien und Gästen den übertakteten Ryzen 99950X-Prozessor. Der Prozessor wurde mit flüssigem Stickstoff (LN2) übertaktet und erzielte im CineBench eine Bewertung von mehr als 23 Millionen , und der Stromverbrauch beträgt bis zu 552 W. Die vom XOC-Team verwendete Übertaktungsplattform ist das ASUS X670EROG CorsshairGene-Motherboard, ein Motherboard, das speziell für Übertaktungsspieler entwickelt wurde und mit 2 DDR5DIMMs ausgestattet ist. Nach der Verwendung von flüssigem Stickstoff sank die Betriebstemperatur des Ryzen 99950X-Prozessors auf minus 90 Grad Celsius, der Stromverbrauch betrug 552 W, die CPU wurde mit 6,4 GHz übertaktet und erreichte im CineBenchR23 mehr als 55296
 Multi-Core übersteigt 100.000, AMD EPYC 9755-Prozessor CPU-Z-Laufpunktzahl ermittelt: 14 % schneller als EPYC 9654
Jul 25, 2024 am 10:46 AM
Multi-Core übersteigt 100.000, AMD EPYC 9755-Prozessor CPU-Z-Laufpunktzahl ermittelt: 14 % schneller als EPYC 9654
Jul 25, 2024 am 10:46 AM
Laut Nachrichten dieser Website vom 25. Juli hat die Quelle HXL (@9550pro) gestern (24. Juli) getwittert und Informationen über die Zen5-basierte AMDEPYC9755 „Turin“-CPU geteilt, die im CPU-Z-Benchmark-Test hervorragende Ergebnisse erzielte . AMDEPYC9755 „Turin“ CPU-Informationen EPYC9755 ist AMDs Produkt der EPYC-Familie der fünften Generation, ausgestattet mit 128 Kernen und 256 Threads auf der Zen5-Architektur. Die Basistaktfrequenz des EPYC9755-Prozessors beträgt 2,70 GHz und die Beschleunigungstaktfrequenz kann 4,10 GHz erreichen. Im Vergleich zur vorherigen Generation ist die Anzahl der Kerne/Threads um 33 % und die Taktfrequenz um 11 % gestiegen. EPYC9755
 AMD gibt die hochschwere Sicherheitslücke „Sinkclose' bekannt, die Millionen von Ryzen- und EPYC-Prozessoren betrifft
Aug 10, 2024 pm 10:31 PM
AMD gibt die hochschwere Sicherheitslücke „Sinkclose' bekannt, die Millionen von Ryzen- und EPYC-Prozessoren betrifft
Aug 10, 2024 pm 10:31 PM
Laut Nachrichten dieser Website vom 10. August hat AMD offiziell bestätigt, dass einige EPYC- und Ryzen-Prozessoren eine neue Schwachstelle namens „Sinkclose“ mit dem Code „CVE-2023-31315“ aufweisen, die möglicherweise Millionen von AMD-Benutzern auf der ganzen Welt betrifft. Was ist Sinkclose? Laut einem Bericht von WIRED ermöglicht die Schwachstelle Eindringlingen die Ausführung von Schadcode im „System Management Mode (SMM)“. Angeblich können Eindringlinge eine Art Malware namens Bootkit verwenden, um die Kontrolle über das System der anderen Partei zu übernehmen, und diese Malware kann von Antivirensoftware nicht erkannt werden. Hinweis von dieser Website: Der System Management Mode (SMM) ist ein spezieller CPU-Arbeitsmodus, der für erweiterte Energieverwaltung und betriebssystemunabhängige Funktionen entwickelt wurde.
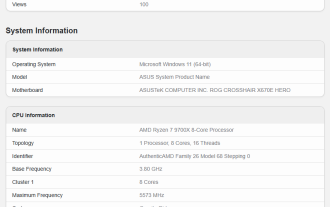 AMD Ryzen 7 9700X-Prozessor erscheint auf Geekbench: Single-Core-Laufpunktzahl ist 14 % höher als R7 7700X
Jul 12, 2024 pm 01:59 PM
AMD Ryzen 7 9700X-Prozessor erscheint auf Geekbench: Single-Core-Laufpunktzahl ist 14 % höher als R7 7700X
Jul 12, 2024 pm 01:59 PM
Laut Nachrichten dieser Website vom 9. Juli erschien in der Geekbench-Datenbank ein ASUS-Testgerät mit AMD Ryzen 79700X-Prozessor, ausgestattet mit einem ROG CROSSHAIRX670EHERO-Motherboard und 32 GBDDR56000-Speicher. AMD Ryzen 79700X verfügt über 8 Kerne und 16 Threads, 3,8 GHz Basisfrequenz, 5,5 GHz Beschleunigungsfrequenz, 40 MB Cache (Hinweis auf dieser Seite: 32MBL3+8MBL2) und 65 W TDP-Design, aber es gibt auch Neuigkeiten, dass AMD seine TDP auf 120 W erhöht hat . Wie in der Abbildung gezeigt, erzielte die Testplattform Single- und Multi-Core-Werte von 3312 Punkten und 16431 Punkten auf Geekbench6.3.0, was besser ist als der R77700
 2*A78+6*A55, MediaTek veröffentlicht den Mid- bis High-End-Chromebook-Prozessor Kompanio 838
Jun 04, 2024 pm 03:34 PM
2*A78+6*A55, MediaTek veröffentlicht den Mid- bis High-End-Chromebook-Prozessor Kompanio 838
Jun 04, 2024 pm 03:34 PM
Laut Nachrichten dieser Website vom 31. Mai hat MediaTek heute den Kompanio 838-Prozessor auf den Markt gebracht. MediaTek sagte, dass dieser 6-nm-Prozess-SoC auf den mittleren bis oberen Chromebook-Markt ausgerichtet ist. Im Vergleich zu den Produkten der Kompanio500-Serie ist die Grafikleistung um bis zu 76 % verbessert, der CPU-Benchmark-Test ist um bis zu 66 % verbessert. , und der Web-Benchmark-Test wird um bis zu 60 % verbessert. Diese Seite organisiert die Parameter des Kompanio838-Prozessors wie folgt: CPU: 8-Kern-Design, 2*ArmCortex-A78@2,6GHz+6*ArmCortex-A55@2,0GHz; GPU: ArmMali-G57MC3; AI-Prozessor: NPU650, Rechenleistung 4TOPS
 Intel Core Ultra 9 285K-Prozessor enthüllt: Single-Core-Laufleistung ist 4 % schneller als Ryzen 9 9950X und Multi-Core ist 14 % schneller
Aug 21, 2024 pm 04:46 PM
Intel Core Ultra 9 285K-Prozessor enthüllt: Single-Core-Laufleistung ist 4 % schneller als Ryzen 9 9950X und Multi-Core ist 14 % schneller
Aug 21, 2024 pm 04:46 PM
Nachrichten von dieser Website vom 21. August, das Technologiemedium WccFtech berichtete heute, dass der Intel Core Ultra9285K „ArrowLake“-Prozessor in der GeekBench6-Benchmark-Bibliothek aufgetaucht ist und die Prozessoren Core i9-14900KS und Ryzen99950X übertrifft. Testplattform Die diesmal vorgestellte Testplattform ist das ASUS ROGSTRIXZ890-AGamingWIFI-Motherboard und 64 GBDDR5-6400-Speicher. Einführung in den Intel Core Ultra9285K „ArrowLake-S“ Desktop-Prozessor. Der PL1-Stromverbrauch des Intel Core Ultra9285K-Prozessors beträgt 125 W und verwendet einen 7-nm-Prozess (CPU-Z-Informationen, sollte es eigentlich sein).
