

TI TPA2016D2 D类音频放大方案

欢迎进入IT技术社区论坛,与200万技术人员互动交流 >>进入 TI 公司的TPA2016D2 是立体声无滤波器的D类音频功率放大器,带有音量控制,动态范围压缩(DRC)和自动增益控制(AGC),5V工作时每路能向8欧姆负载1.7W的功率.器件具有独立的软件关断特性,并提供热保护和短
欢迎进入IT技术社区论坛,与200万技术人员互动交流 >>进入
TI 公司的TPA2016D2 是立体声无滤波器的D类音频功率放大器,带有音量控制,动态范围压缩(DRC)和自动增益控制(AGC),5V工作时每路能向8欧姆负载1.7W的功率.器件具有独立的软件关断特性,并提供热保护和短路保护,广泛应用在无线手机和PDA,手提导航设备,手提DVD播放器,笔记本电脑,收音机,游戏机以及智力玩具等.本文介绍了TPA2016D2的主要特性,功能方框图和应用电路以及TPA2016D2EVM评估板电路图和所用元件列表.The TPA2016D2 is a stereo, filter-free Class-D audio power amplifier with volume control, dynamic range compression (DRC) and automatic gain control (AGC). It is available in a 2.2 mm x 2.2 mm WCSP package.
The DRC/AGC function in the TPA2016D2 is programmable via a digital I2C interface. The DRC/AGC function can be configured to automatically prevent distortion of the audio signal and enhance quiet passages that are normally not heard. The DRC/AGC can also be configured to protect the speaker from damage at high power levels and compress the dynamic range of music to fit within the dynamic range of the speaker. The gain can be selected from -28 dB to +30 dB in 1-dB steps. The TPA2016D2 is capable of driving 1.7 W/Ch at 5 V or 750 mW/Ch at 3.6 V into 8 Ω load. The device features independent software shutdown controls for each channel and also provides thermal and short circuit protection.

图1. TPA2016D2外形图
TPA2016D2 主要特性:
Filter-Free Class-D Architecture
1.7 W/Ch Into 8 Ω at 5 V (10% THD+N)
750 mW/Ch Into 8 Ω at 3.6 V (10% THD+N)
Power Supply Range: 2.5 V to 5.5 V
Flexible Operation With/Without I2C
Programmable DRC/AGC Parameters
Digital I2C Volume Control
Selectable Gain from -28 dB to 30 dB in 1-dB Steps (when compression is used)
Selectable Attack, Release and Hold Times
4 Selectable Compression Ratios
Low Supply Current: 3.5 mA
Low Shutdown Current: 0.2 µA
High PSRR: 80 dB
Fast Start-up Time: 5 ms
AGC Enable/Disable Function
Limiter Enable/Disable Function
Short-Circuit and Thermal Protection
Space-Saving Package 2,2 mm × 2,2 mm Nano-Free WCSP (YZH)
应用范围:
Wireless or Cellular Handsets and PDAs
Portable Navigation Devices
Portable DVD Player
Notebook PCs
Portable Radio
Portable Games
Educational Toys
USB Speakers

图2. TPA2016D2功能方框图
图3. TPA2016D2简化应用电路
The TPA2016D2 evaluation module (EVM) is a complete, stand-alone audio board. It contains the TPA2016D2 WCSP (YZH) Class-D audio power amplifier.

图4. TPA2016D2EVM
[1] [2]


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Das Stable Diffusion 3-Papier wird endlich veröffentlicht und die architektonischen Details werden enthüllt. Wird es helfen, Sora zu reproduzieren?
Mar 06, 2024 pm 05:34 PM
Der Artikel von StableDiffusion3 ist endlich da! Dieses Modell wurde vor zwei Wochen veröffentlicht und verwendet die gleiche DiT-Architektur (DiffusionTransformer) wie Sora. Nach seiner Veröffentlichung sorgte es für großes Aufsehen. Im Vergleich zur Vorgängerversion wurde die Qualität der von StableDiffusion3 generierten Bilder erheblich verbessert. Es unterstützt jetzt Eingabeaufforderungen mit mehreren Themen, und der Textschreibeffekt wurde ebenfalls verbessert, und es werden keine verstümmelten Zeichen mehr angezeigt. StabilityAI wies darauf hin, dass es sich bei StableDiffusion3 um eine Reihe von Modellen mit Parametergrößen von 800 M bis 8 B handelt. Durch diesen Parameterbereich kann das Modell direkt auf vielen tragbaren Geräten ausgeführt werden, wodurch der Einsatz von KI deutlich reduziert wird
 DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
DualBEV: BEVFormer und BEVDet4D deutlich übertreffen, öffnen Sie das Buch!
Mar 21, 2024 pm 05:21 PM
In diesem Artikel wird das Problem der genauen Erkennung von Objekten aus verschiedenen Blickwinkeln (z. B. Perspektive und Vogelperspektive) beim autonomen Fahren untersucht, insbesondere wie die Transformation von Merkmalen aus der Perspektive (PV) in den Raum aus der Vogelperspektive (BEV) effektiv ist implementiert über das Modul Visual Transformation (VT). Bestehende Methoden lassen sich grob in zwei Strategien unterteilen: 2D-zu-3D- und 3D-zu-2D-Konvertierung. 2D-zu-3D-Methoden verbessern dichte 2D-Merkmale durch die Vorhersage von Tiefenwahrscheinlichkeiten, aber die inhärente Unsicherheit von Tiefenvorhersagen, insbesondere in entfernten Regionen, kann zu Ungenauigkeiten führen. Während 3D-zu-2D-Methoden normalerweise 3D-Abfragen verwenden, um 2D-Features abzutasten und die Aufmerksamkeitsgewichte der Korrespondenz zwischen 3D- und 2D-Features über einen Transformer zu lernen, erhöht sich die Rechen- und Bereitstellungszeit.
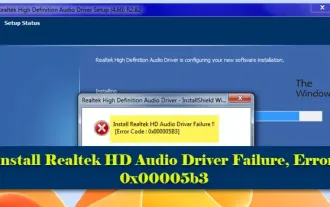 Die Installation des Realtek HD-Audiotreibers ist mit Fehler 0x00005b3 fehlgeschlagen
Feb 19, 2024 am 10:42 AM
Die Installation des Realtek HD-Audiotreibers ist mit Fehler 0x00005b3 fehlgeschlagen
Feb 19, 2024 am 10:42 AM
Wenn auf einem Windows 11/10-PC der Fehlercode 0x00005b3 für den RealtekHD-Audiotreiberfehler auftritt, befolgen Sie bitte die folgenden Schritte, um das Problem zu beheben. Wir begleiten Sie bei der Fehlerbehebung und Behebung des Fehlers. Der Fehlercode 0x00005b3 kann durch Probleme bei der Installation des Audiotreibers verursacht werden. Möglicherweise ist der aktuelle Treiber beschädigt oder teilweise deinstalliert, was sich auf die Installation des neuen Treibers auswirkt. Dieses Problem kann auch durch unzureichenden Speicherplatz oder einen Audiotreiber verursacht werden, der mit Ihrer Windows-Version nicht kompatibel ist. Die Installation des RealtekHD-Audiotreibers ist fehlgeschlagen! ! [Fehlercode: 0x00005B3] Wenn ein Problem mit dem Realtek Audio Driver Installation Wizard auftritt, lesen Sie weiter
 So richten Sie PPT für die automatische Wiedergabe mehrerer Audios ein
Mar 26, 2024 pm 06:21 PM
So richten Sie PPT für die automatische Wiedergabe mehrerer Audios ein
Mar 26, 2024 pm 06:21 PM
1. Öffnen Sie PPT, klicken Sie in der Menüleiste auf [Einfügen] und dann auf [Audio]. 2. Wählen Sie im sich öffnenden Dateiauswahlfeld die erste Audiodatei aus, die Sie einfügen möchten. 3. Nachdem das Einfügen erfolgreich war, wird in der PPT ein Lautsprechersymbol angezeigt, das die gerade eingefügte Datei darstellt. Sie können sie abspielen und anhören und die Lautstärke anpassen, um die Lautstärke während des PPT-Überprüfungsvorgangs zu steuern. 4. Folgen Sie der gleichen Methode und fügen Sie die zweite Audiodatei ein. Zu diesem Zeitpunkt werden in der PPT zwei Lautsprechersymbole angezeigt, die jeweils zwei Audiodateien darstellen. 5. Klicken Sie auf das erste Audiodateisymbol, um es auszuwählen, und klicken Sie dann auf das Menü [Wiedergabe]. 6. Wählen Sie in der Symbolleiste unter „Start“ die Option „Folienübergreifend abspielen“, um diesen Ton so einzustellen, dass er auf jeder Folie ohne menschliches Eingreifen abgespielt wird. 7. Befolgen Sie die Schritte in Schritt 6
 Mehr als nur 3D-Gauß! Aktueller Überblick über modernste 3D-Rekonstruktionstechniken
Jun 02, 2024 pm 06:57 PM
Mehr als nur 3D-Gauß! Aktueller Überblick über modernste 3D-Rekonstruktionstechniken
Jun 02, 2024 pm 06:57 PM
Oben geschrieben & Nach persönlichem Verständnis des Autors ist die bildbasierte 3D-Rekonstruktion eine anspruchsvolle Aufgabe, bei der aus einer Reihe von Eingabebildern auf die 3D-Form eines Objekts oder einer Szene geschlossen werden muss. Lernbasierte Methoden haben wegen ihrer Fähigkeit, 3D-Formen direkt abzuschätzen, Aufmerksamkeit erregt. Dieser Übersichtsartikel konzentriert sich auf modernste 3D-Rekonstruktionstechniken, einschließlich der Generierung neuartiger, unsichtbarer Ansichten. Es wird ein Überblick über die jüngsten Entwicklungen bei Gaußschen Splash-Methoden gegeben, einschließlich Eingabetypen, Modellstrukturen, Ausgabedarstellungen und Trainingsstrategien. Auch ungelöste Herausforderungen und zukünftige Ausrichtungen werden besprochen. Angesichts der rasanten Fortschritte auf diesem Gebiet und der zahlreichen Möglichkeiten zur Verbesserung der 3D-Rekonstruktionsmethoden scheint eine gründliche Untersuchung des Algorithmus von entscheidender Bedeutung zu sein. Daher bietet diese Studie einen umfassenden Überblick über die jüngsten Fortschritte in der Gaußschen Streuung. (Wischen Sie mit dem Daumen nach oben
 Rezension! Tiefe Modellfusion (LLM/Basismodell/Verbundlernen/Feinabstimmung usw.)
Apr 18, 2024 pm 09:43 PM
Rezension! Tiefe Modellfusion (LLM/Basismodell/Verbundlernen/Feinabstimmung usw.)
Apr 18, 2024 pm 09:43 PM
Am 23. September wurde das Papier „DeepModelFusion:ASurvey“ von der National University of Defense Technology, JD.com und dem Beijing Institute of Technology veröffentlicht. Deep Model Fusion/Merging ist eine neue Technologie, die die Parameter oder Vorhersagen mehrerer Deep-Learning-Modelle in einem einzigen Modell kombiniert. Es kombiniert die Fähigkeiten verschiedener Modelle, um die Verzerrungen und Fehler einzelner Modelle zu kompensieren und so eine bessere Leistung zu erzielen. Die tiefe Modellfusion bei groß angelegten Deep-Learning-Modellen (wie LLM und Basismodellen) steht vor einigen Herausforderungen, darunter hohe Rechenkosten, hochdimensionaler Parameterraum, Interferenzen zwischen verschiedenen heterogenen Modellen usw. Dieser Artikel unterteilt bestehende Methoden zur Tiefenmodellfusion in vier Kategorien: (1) „Musterverbindung“, die Lösungen im Gewichtsraum über einen verlustreduzierenden Pfad verbindet, um eine bessere anfängliche Modellfusion zu erzielen
 Revolutionäres GPT-4o: Neugestaltung des Mensch-Computer-Interaktionserlebnisses
Jun 07, 2024 pm 09:02 PM
Revolutionäres GPT-4o: Neugestaltung des Mensch-Computer-Interaktionserlebnisses
Jun 07, 2024 pm 09:02 PM
Das von OpenAI veröffentlichte GPT-4o-Modell ist zweifellos ein großer Durchbruch, insbesondere in Bezug auf seine Fähigkeit, mehrere Eingabemedien (Text, Audio, Bilder) zu verarbeiten und entsprechende Ausgaben zu generieren. Diese Fähigkeit macht die Mensch-Computer-Interaktion natürlicher und intuitiver und verbessert die Praktikabilität und Benutzerfreundlichkeit von KI erheblich. Zu den wichtigsten Highlights von GPT-4o gehören: hohe Skalierbarkeit, Multimedia-Ein- und -Ausgabe, weitere Verbesserungen der Fähigkeiten zum Verstehen natürlicher Sprache usw. 1. Medienübergreifende Eingabe/Ausgabe: GPT-4o+ kann jede beliebige Kombination aus Text, Audio und Bildern als Eingabe akzeptieren und direkt eine Ausgabe aus diesen Medien generieren. Dadurch wird die Beschränkung herkömmlicher KI-Modelle aufgehoben, die nur einen einzigen Eingabetyp verarbeiten, wodurch die Mensch-Computer-Interaktion flexibler und vielfältiger wird. Diese Innovation unterstützt intelligente Assistenten
