

影响Lucene索引速度原因以及提高索引速度技巧

在网上看了一篇外文文章,里面介绍了提高Lucene索引速度的技巧,分享给大家。 先来看下影响索引的主要因素: MaxMergeDocs 该参数决定写入内存索引文档个数,到达该数目后就把该内存索引写入硬盘,生成一个新的索引segment文件。 所以该参数也就是一个内存bu
在网上看了一篇外文文章,里面介绍了提高Lucene索引速度的技巧,分享给大家。 先来看下影响索引的主要因素:
先来看下影响索引的主要因素:
MaxMergeDocs
该参数决定写入内存索引文档个数,到达该数目后就把该内存索引写入硬盘,生成一个新的索引segment文件。
所以该参数也就是一个内存buffer,一般来说越大索引速度越快。
MaxBufferedDocs这个参数默认是disabled的,因为Lucene中还用另外一个参数(RAMBufferSizeMB)控制这个bufffer的索引文档个数。
其实MaxBufferedDocs和RAMBufferSizeMB这两个参数是可以一起使用的,一起使用时只要有一个触发条件满足就写入硬盘,生成一个新的索引segment文件。
RAMBufferSizeMB
控制用于buffer索引文档的内存上限,如果buffer的索引文档个数到达该上限就写入硬盘。当然,一般来说也只越大索引速度越快。
当我们对文档大小不太确定时,这个参数就相当有用,不至于outofmemory error.
MergeFactor
这个参数是用于子索引(Segment)合并的。
Lucene中索引总体上是这样进行,索引现写到内存,触发一定限制条件后写入硬盘,生成一个独立的子索引-lucene中叫Segment。一般来说这些子索引需要合并成一个索引,也就是optimize(),否则会影响检索速度,而且也可能导致open too many files。
MergeFactor 这个参数就是控制当硬盘中有多少个子索引segments,我们就需要现把这些索引合并冲一个稍微大些的索引了。
MergeFactor这个不能设置太大,特别是当MaxBufferedDocs比较小时(segment 越多),否则会导致open too many files错误,甚至导致虚拟机外面出错。
Note: Lucene 中默认索引合并机制并不是两两合并,好像是多个segment 合并成最终的一个大索引,所以MergeFactor越大耗费内存越多,索引速度也会快些,但我的感觉太大譬如300,最后合并的时候还是很满。Batch indexing 应 MergeFactor>10
21世纪开运网星座紫微斗数在线排盘加快索引的一些技巧:
? 确认你在使用最新的Lucene版本。
? 尽量使用本地文件系统
远程文件系统一般来说都会降低索引速度。如果索引必须分布在远程服务器,请尝试先在本地生成索引,然后分发到远程服务器上。
? 使用更快的硬件设备,特别是更快的IO设备
? 在索引期间复用单一的IndexWriter实例
? 使用按照内存消耗Flush代替根据文档数量Flush
在Lucene 2.2之前的版本,可以在每次添加文档后调用ramSizeInBytes方法,当索引消耗过多的内存时,然后在调用flush()方法。这样做在索引大量小文档或者文档大小不定的情况下尤为有效。你必须先把maxBufferedDocs参数设置足够大,以防止writer基于文档数量flush。但是注意,别把这个值设置的太大,否则你将遭遇Lucene-845号BUG。不过这个BUG已经在2.3版本中得到解决。
在Lucene2.3之后的版本。IndexWriter可以自动的根据内存消耗调用flush()。你可以通过writer.setRAMBufferSizeMB()来设置缓存大小。当你打算按照内存大小flush后,确保没有在别的地方设置MaxBufferedDocs值。否则flush条件将变的不确定(谁先符合条件就按照谁)。
? 在你能承受的范围内使用更多的内存
在flush前使用更多的内存意味着Lucene将在索引时生成更大的segment,也意味着合并次数也随之减少。在Lucene-843中测试,大概48MB内存可能是一个比较合适的值。但是,你的程序可能会是另外一个值。这跟不同的机器也有一定的关系,请自己多加测试,选择一个权衡值。
? 关闭复合文件格式
调用setUseCompoundFile(false)可以关闭复合文件选项。生成复合文件将消耗更多的时间(经过Lucene-888测试,大概会增加7%-33%的时间)。但是请注意,这样做将大大的增加搜索和索引使用的文件句柄的数量。如果合并因子也很大的话,你可能会出现用光文件句柄的情况。
? 重用Document和Field实例
在lucene 2.3中,新增了一个叫setValue的方法,可以允许你改变字段的值。这样的好处是你可以在整个索引进程中复用一个Filed实例。这将极大的减少GC负担。
最好创建一个单一的Document实例,然后添加你想要的字段到文档中。同时复用添加到文档的Field实例,通用调用相应的SetValue方法改变相应的字段的值。然后重新将Document添加到索引中。
注意:你不能在一个文档中多个字段共用一个Field实例,在文档添加到索引之前,Field的值都不应该改变。也就是说如果你有3个字段,你必须创建3个Field实例,然后再之后的Document添加过程中复用它们。
? 在你的分析器Analyzer中使用一个单一的Token实例
在分析器中共享一个单一的token实例也将缓解GC的压力。
? 在Token中使用char[]接口来代替String接口来表示数据
在Lucene 2.3中,Token可以使用char数组来表示他的数据。这样可以避免构建字符串以及GC回收字符串的消耗。通过配合使用单一Token实例和使用char[]接口你可以避免创建新的对象。
? 设置autoCommit为false
在Lucene 2.3中对拥有存储字段和Term向量的文档进行了大量的优化,以节省大索引合并的时间。你可以将单一复用的IndexWriter实例的autoCommit设置为false来见证这些优化带来的好处。注意这样做将导致searcher在IndexWriter关闭之前不会看到任何索引的更新。如果你认为这个对你很重要,你可以继续将autoCommit设置为true,或者周期性的打开和关闭你的writer。
? 如果你要索引很多小文本字段,如果没有特别需求,建议你将这些小文本字段合并为一个大的contents字段,然后只索引contents。(当然你也可以继续存储那些字段)
? 加大mergeFactor合并因子,但不是越大越好
大的合并因子将延迟segment的合并时间,这样做可以提高索引速度,因为合并是索引很耗时的一个部分。但是,这样做将降低你的搜索速度。同时,你有可能会用光你的文件句柄如果你把合并因子设置的太大。值太大了设置可能降低索引速度,因为这意味着将同时合并更多的segment,将大大的增加硬盘的负担。
? 关闭所有你实际上没有使用的功能
如果你存储了字段,但是在查询时根本没有用到它们,那么别存储它们。同样Term向量也是如此。如果你索引很多的字段,关闭这些字段的不必要的特性将对索引速度提升产生很大的帮助。
? 使用一个更快的分析器
有时间分析文档将消耗很长的时间。举例来说,StandardAnalyzer就比较耗时,尤其在Lucene 2.3版本之前。你可以尝试使用一个更简单更快但是符合你需求的分析器。
? 加速文档的构建时间
在通常的情况下,文档的数据来源可能是外部(比如数据库,文件系统,蜘蛛从网站上的抓取等),这些通常都比较耗时,尽量优化获取它们的性能。
? 在你真的需要之前不要随意的优化optimize索引(只有在需要更快的搜索速度的时候)
? 在多线程中共享一个IndexWriter
最新的硬件都是适合高并发的(多核CPU,多通道内存构架等),所以使用多线程添加文档将会带来不小的性能提升。就算是一台很老的机器,并发添加文档都将更好的利用IO和CPU。多测试并发的线程数目,获得一个临界最优值。
? 将文档分组在不同的机器上索引然后再合并
如果你有大量的文本文档需要索引,你可以把你的文档分为若干组,在若干台机器上分别索引不同的组,然后利用writer.addIndexesNoOptimize来将它们合并到最终的一个索引文件中。
? 运行性能测试程序
如果以上的建议都没有发生效果。建议你运行下性能检测程序。找出你的程序中哪个部分比较耗时。这通常会给你想不到的惊喜。
http://wiki.apache.org/jakarta-lucene/ImproveIndexingSpeed
http://www.21kaiyun.com

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

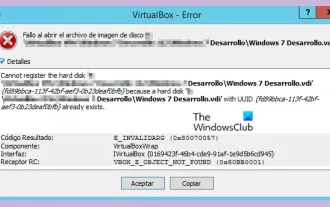 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox-Fehler
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox-Fehler
Mar 24, 2024 am 09:51 AM
Wenn Sie versuchen, ein Disk-Image in VirtualBox zu öffnen, wird möglicherweise eine Fehlermeldung angezeigt, die darauf hinweist, dass die Festplatte nicht registriert werden kann. Dies geschieht normalerweise, wenn die VM-Disk-Image-Datei, die Sie öffnen möchten, dieselbe UUID wie eine andere virtuelle Disk-Image-Datei hat. In diesem Fall zeigt VirtualBox den Fehlercode VBOX_E_OBJECT_NOT_FOUND(0x80bb0001) an. Wenn dieser Fehler auftritt, machen Sie sich keine Sorgen, es gibt einige Lösungen, die Sie ausprobieren können. Zunächst können Sie versuchen, mit den Befehlszeilentools von VirtualBox die UUID der Disk-Image-Datei zu ändern, um Konflikte zu vermeiden. Sie können den Befehl „VBoxManageinternal“ ausführen
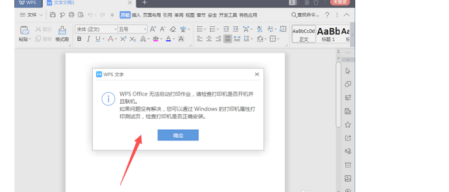 Was führt dazu, dass WPS Office einen Druckauftrag nicht starten kann?
Mar 20, 2024 am 09:52 AM
Was führt dazu, dass WPS Office einen Druckauftrag nicht starten kann?
Mar 20, 2024 am 09:52 AM
Beim Anschließen eines Druckers an ein lokales Netzwerk und beim Starten eines Druckauftrags können einige kleinere Probleme auftreten. Beispielsweise tritt gelegentlich das Problem „wpsoffice kann den Druckauftrag nicht starten“ auf, was dazu führt, dass Dateien nicht gedruckt werden können usw ., was unsere Arbeit und unser Studium verzögert und negative Auswirkungen hat. Lassen Sie mich Ihnen sagen, wie Sie das Problem lösen können, dass wpsoffice den Druckauftrag nicht starten kann. Natürlich können Sie die Software oder den Treiber aktualisieren, um das Problem zu lösen, aber das wird lange dauern. Im Folgenden gebe ich Ihnen eine Lösung, die in wenigen Minuten gelöst werden kann. Zunächst ist mir aufgefallen, dass wpsoffice den Druckauftrag nicht starten kann, was dazu führt, dass nicht gedruckt werden kann. Um dieses Problem zu lösen, müssen wir es einzeln untersuchen. Stellen Sie außerdem sicher, dass der Drucker eingeschaltet und angeschlossen ist. Im Allgemeinen führt dies zu einer abnormalen Verbindung
 Umfassender Leitfaden zu PHP 500-Fehlern: Ursachen, Diagnose und Korrekturen
Mar 22, 2024 pm 12:45 PM
Umfassender Leitfaden zu PHP 500-Fehlern: Ursachen, Diagnose und Korrekturen
Mar 22, 2024 pm 12:45 PM
Ein umfassender Leitfaden zu PHP500-Fehlern: Ursachen, Diagnose und Korrekturen Während der PHP-Entwicklung stoßen wir häufig auf Fehler mit dem HTTP-Statuscode 500. Dieser Fehler wird normalerweise „500InternalServerError“ genannt, was bedeutet, dass bei der Verarbeitung der Anfrage auf der Serverseite einige unbekannte Fehler aufgetreten sind. In diesem Artikel untersuchen wir die häufigsten Ursachen von PHP500-Fehlern, wie man sie diagnostiziert und behebt und stellen spezifische Codebeispiele als Referenz bereit. Häufige Ursachen für 1.500 Fehler 1.
 Teilen von Win11-Tipps: Ein Trick, um die Anmeldung mit einem Microsoft-Konto zu überspringen
Mar 27, 2024 pm 02:57 PM
Teilen von Win11-Tipps: Ein Trick, um die Anmeldung mit einem Microsoft-Konto zu überspringen
Mar 27, 2024 pm 02:57 PM
Teilen von Win11-Tipps: Ein Trick, um die Anmeldung bei einem Microsoft-Konto zu überspringen Windows 11 ist das neueste Betriebssystem von Microsoft mit neuem Designstil und vielen praktischen Funktionen. Für einige Benutzer kann es jedoch etwas nervig sein, sich bei jedem Systemstart bei ihrem Microsoft-Konto anmelden zu müssen. Wenn Sie einer von ihnen sind, können Sie auch die folgenden Tipps ausprobieren, die es Ihnen ermöglichen, die Anmeldung mit einem Microsoft-Konto zu überspringen und direkt auf die Desktop-Oberfläche zuzugreifen. Zunächst müssen wir anstelle eines Microsoft-Kontos ein lokales Konto im System erstellen, um uns anzumelden. Der Vorteil dabei ist
 Ein Muss für Veteranen: Tipps und Vorsichtsmaßnahmen für * und & in C-Sprache
Apr 04, 2024 am 08:21 AM
Ein Muss für Veteranen: Tipps und Vorsichtsmaßnahmen für * und & in C-Sprache
Apr 04, 2024 am 08:21 AM
In der C-Sprache stellt es einen Zeiger dar, der die Adresse anderer Variablen speichert; & stellt den Adressoperator dar, der die Speicheradresse einer Variablen zurückgibt. Zu den Tipps zur Verwendung von Zeigern gehören das Definieren von Zeigern, das Dereferenzieren von Zeigern und das Sicherstellen, dass Zeiger auf gültige Adressen zeigen. Tipps zur Verwendung von Adressoperatoren sowie das Abrufen von Variablenadressen und das Zurückgeben der Adresse des ersten Elements des Arrays beim Abrufen der Adresse eines Array-Elements . Ein praktisches Beispiel, das die Verwendung von Zeiger- und Adressoperatoren zum Umkehren einer Zeichenfolge veranschaulicht.
 Was sind die Tipps für Anfänger zum Erstellen von Formularen?
Mar 21, 2024 am 09:11 AM
Was sind die Tipps für Anfänger zum Erstellen von Formularen?
Mar 21, 2024 am 09:11 AM
Wir erstellen und bearbeiten Tabellen oft in Excel, aber als Neuling, der gerade erst mit der Software in Berührung gekommen ist, ist die Verwendung von Excel zum Erstellen von Tabellen nicht so einfach wie für uns. Im Folgenden führen wir einige Übungen zu einigen Schritten der Tabellenerstellung durch, die Anfänger, also Anfänger, beherrschen müssen. Wir hoffen, dass sie für Bedürftige hilfreich sind. Unten sehen Sie ein Beispielformular für Anfänger: Mal sehen, wie man es ausfüllt! 1. Es gibt zwei Methoden, ein neues Excel-Dokument zu erstellen. Sie können mit der rechten Maustaste auf eine leere Stelle in der Datei [Desktop] – [Neu] – [xls] klicken. Sie können auch [Start]-[Alle Programme]-[Microsoft Office]-[Microsoft Excel 20**] wählen. 2. Doppelklicken Sie auf unser neues Ex
 Wie schalte ich die Kommentarfunktion auf TikTok aus? Was passiert nach dem Deaktivieren der Kommentarfunktion auf TikTok?
Mar 23, 2024 pm 06:20 PM
Wie schalte ich die Kommentarfunktion auf TikTok aus? Was passiert nach dem Deaktivieren der Kommentarfunktion auf TikTok?
Mar 23, 2024 pm 06:20 PM
Auf der Douyin-Plattform können Nutzer nicht nur ihre Lebensmomente teilen, sondern auch mit anderen Nutzern interagieren. Manchmal kann die Kommentarfunktion zu unangenehmen Erlebnissen führen, wie z. B. Online-Gewalt, böswilligen Kommentaren usw. Wie kann man also die Kommentarfunktion von TikTok deaktivieren? 1. Wie schalte ich die Kommentarfunktion von Douyin aus? 1. Melden Sie sich bei der Douyin-App an und geben Sie Ihre persönliche Homepage ein. 2. Klicken Sie unten rechts auf „I“, um das Einstellungsmenü aufzurufen. 3. Suchen Sie im Einstellungsmenü nach „Datenschutzeinstellungen“. 4. Klicken Sie auf „Datenschutzeinstellungen“, um die Benutzeroberfläche für Datenschutzeinstellungen aufzurufen. 5. Suchen Sie in der Benutzeroberfläche für Datenschutzeinstellungen nach „Kommentareinstellungen“. 6. Klicken Sie auf „Kommentareinstellungen“, um die Kommentareinstellungsoberfläche aufzurufen. 7. Suchen Sie in der Benutzeroberfläche für Kommentareinstellungen nach der Option „Kommentare schließen“. 8. Klicken Sie auf die Option „Kommentare schließen“, um abschließende Kommentare zu bestätigen.
 VSCode-Erste-Schritte-Leitfaden: Ein Muss für Anfänger, um die Verwendungsfähigkeiten schnell zu erlernen!
Mar 26, 2024 am 08:21 AM
VSCode-Erste-Schritte-Leitfaden: Ein Muss für Anfänger, um die Verwendungsfähigkeiten schnell zu erlernen!
Mar 26, 2024 am 08:21 AM
VSCode (Visual Studio Code) ist ein von Microsoft entwickelter Open-Source-Code-Editor. Er verfügt über leistungsstarke Funktionen und umfangreiche Plug-in-Unterstützung, was ihn zu einem der bevorzugten Tools für Entwickler macht. Dieser Artikel bietet eine Einführung für Anfänger, die ihnen hilft, schnell die Fähigkeiten im Umgang mit VSCode zu erlernen. In diesem Artikel stellen wir die Installation von VSCode, grundlegende Bearbeitungsvorgänge, Tastenkombinationen, Plug-In-Installation usw. vor und stellen den Lesern spezifische Codebeispiele zur Verfügung. 1. Installieren Sie zuerst VSCode, wir brauchen
