

IntegrationServices架构概述

Integration Services平台包括许多组件,但在最高层次上,它由4个主要部分组成。 1、Integration Services运行时。SSIS运行时提供了运行SSIS包所需的核心功能,包括执行、记录、配置、调试等。 2、数据流引擎。SSIS数据库引擎(也成为管道)提供了将数据从源
Integration Services平台包括许多组件,但在最高层次上,它由4个主要部分组成。
1、Integration Services运行时。SSIS运行时提供了运行SSIS包所需的核心功能,包括执行、记录、配置、调试等。
2、数据流引擎。SSIS数据库引擎(也成为管道)提供了将数据从源移动到SSIS包中的目标所需的核心ETL功能,包括管理管道所基于的内存缓冲区,以及组成包的数据流逻辑的源、转换盒目标。
3、Integration Services对象模型。SSIS对象模型是一个托管.net应用程序编程接口(API),支持工具、使用工具和组件与SSIS运行时和数据流引擎交互。
4、Integration Services服务。SSIS服务是一种 Windows服务,提供了存储和管理SSIS包的功能。
这4个关键组件构成了SSIS的基础,但实际上它们只是SSIS架构的冰山一角。当然,主要的工作单元是SSIS包。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Das Konzept des Deep Learning stammt aus der Erforschung künstlicher neuronaler Netze. Ein mehrschichtiges Perzeptron, das mehrere verborgene Schichten enthält, ist eine Deep-Learning-Struktur. Deep Learning kombiniert Funktionen auf niedriger Ebene, um abstraktere Darstellungen auf hoher Ebene zu bilden, um Kategorien oder Merkmale von Daten darzustellen. Es ist in der Lage, verteilte Merkmalsdarstellungen von Daten zu erkennen. Deep Learning ist eine Form des maschinellen Lernens, und maschinelles Lernen ist der einzige Weg, künstliche Intelligenz zu erreichen. Was sind also die Unterschiede zwischen verschiedenen Deep-Learning-Systemarchitekturen? 1. Vollständig verbundenes Netzwerk (FCN) Ein vollständig verbundenes Netzwerk (FCN) besteht aus einer Reihe vollständig verbundener Schichten, wobei jedes Neuron in jeder Schicht mit jedem Neuron in einer anderen Schicht verbunden ist. Sein Hauptvorteil besteht darin, dass es „strukturunabhängig“ ist, d. h. es sind keine besonderen Annahmen über die Eingabe erforderlich. Obwohl dieser strukturelle Agnostiker das Ganze abschließt
 Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Vor einiger Zeit löste ein Tweet, der auf die Inkonsistenz zwischen dem Transformer-Architekturdiagramm und dem Code im Papier „AttentionIsAllYouNeed“ des Google Brain-Teams hinwies, viele Diskussionen aus. Manche Leute halten Sebastians Entdeckung für einen unbeabsichtigten Fehler, aber sie ist auch überraschend. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz schließlich tausendmal erwähnt werden müssen. Sebastian Raschka antwortete auf Kommentare von Internetnutzern, dass der „originellste“ Code zwar mit dem Architekturdiagramm übereinstimme, die 2017 eingereichte Codeversion jedoch geändert, das Architekturdiagramm jedoch nicht gleichzeitig aktualisiert worden sei. Dies ist auch die Ursache für „inkonsistente“ Diskussionen.
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
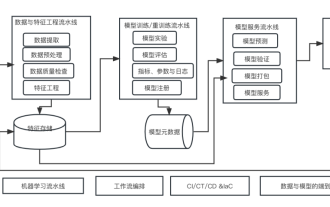 Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Dies ist eine Ära der Stärkung der KI, und maschinelles Lernen ist ein wichtiges technisches Mittel zur Verwirklichung von KI. Gibt es also eine universelle Systemarchitektur für maschinelles Lernen? Im kognitiven Bereich erfahrener Programmierer ist „Alles“ nichts, insbesondere für die Systemarchitektur. Es ist jedoch möglich, eine skalierbare und zuverlässige Systemarchitektur für maschinelles Lernen aufzubauen, sofern diese auf die meisten auf maschinellem Lernen basierenden Systeme oder Anwendungsfälle anwendbar ist. Aus Sicht des Lebenszyklus des maschinellen Lernens deckt diese sogenannte universelle Architektur wichtige Phasen des maschinellen Lernens ab, von der Entwicklung von Modellen für maschinelles Lernen bis hin zur Bereitstellung von Schulungssystemen und Servicesystemen in Produktionsumgebungen. Wir können versuchen, eine solche Systemarchitektur für maschinelles Lernen anhand der Dimensionen von 10 Elementen zu beschreiben. 1.
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
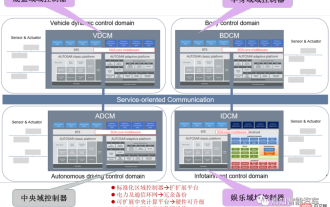 Software-Architekturdesign und Software- und Hardware-Entkopplungsmethodik in SOA
Apr 08, 2023 pm 11:21 PM
Software-Architekturdesign und Software- und Hardware-Entkopplungsmethodik in SOA
Apr 08, 2023 pm 11:21 PM
Für die nächste Generation zentralisierter elektronischer und elektrischer Architektur ist die Verwendung einer zentralen + zonalen zentralen Recheneinheit und eines regionalen Controller-Layouts für verschiedene OEMs oder Tier-1-Player zu einer unverzichtbaren Option geworden. In Bezug auf die Architektur der zentralen Recheneinheit gibt es drei Möglichkeiten: Trennung SOC, Hardware-Isolation, Software-Virtualisierung. Die zentralisierte zentrale Recheneinheit wird die Kerngeschäftsfunktionen der drei Hauptbereiche autonomes Fahren, intelligentes Cockpit und Fahrzeugsteuerung integrieren. Der standardisierte regionale Controller hat drei Hauptaufgaben: Stromverteilung, Datendienste und regionales Gateway. Daher wird die zentrale Recheneinheit einen Hochdurchsatz-Ethernet-Switch integrieren. Da der Integrationsgrad des gesamten Fahrzeugs immer höher wird, werden immer mehr Steuergerätefunktionen langsam in die Regionalsteuerung übernommen. Und Plattformisierung
 Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Wie steil ist die Lernkurve der Golang-Framework-Architektur?
Jun 05, 2024 pm 06:59 PM
Die Lernkurve der Go-Framework-Architektur hängt von der Vertrautheit mit der Go-Sprache und der Backend-Entwicklung sowie der Komplexität des gewählten Frameworks ab: einem guten Verständnis der Grundlagen der Go-Sprache. Es ist hilfreich, Erfahrung in der Backend-Entwicklung zu haben. Frameworks mit unterschiedlicher Komplexität führen zu unterschiedlichen Lernkurven.
