
 Web-Frontend
HTML-Tutorial
Der Auswahlmechanismus des DOCTYPE-Modus durch bekannte Browser_HTML/Xhtml_Webseitenproduktion
Web-Frontend
HTML-Tutorial
Der Auswahlmechanismus des DOCTYPE-Modus durch bekannte Browser_HTML/Xhtml_Webseitenproduktion
Der Auswahlmechanismus des DOCTYPE-Modus durch bekannte Browser_HTML/Xhtml_Webseitenproduktion

Dokumentumfang
Die in diesem Artikel enthaltene Modusumschaltung gilt für Firefox und andere Gecko-basierte Browser, Safari, Chrome und andere Webkit-basierte Browser, Opera, Konqueror, Internet Explorer für Mac, Internet Explorer für Windows und eingebettete IE-Browser. Vermeiden Sie die Nennung des Namens der Browser-Engine und nennen Sie stattdessen den Namen des bekanntesten Browsers, der diese Engine verwendet.
Dieser Artikel konzentriert sich auf den Modusauswahlmechanismus und nicht auf die Dokumentation des genauen Verhaltens jedes Modus.
Modus
Hier sind die verschiedenen Modi:
Modus mit Inhaltstyp text/html
Die Modusauswahl für Text-/HTML-Inhalte hängt vom Doctype-Sniffing ab (wird später in diesem Artikel besprochen). Im IE8 hängt der Modus auch von anderen Faktoren ab. Allerdings hängt der Modus für Nicht-Intranet-Sites, die nicht auf der Blacklist von Microsoft stehen, im IE8 standardmäßig vom Dokumenttyp ab.
Es kann nicht genug betont werden, dass das genaue Verhalten von Mustern in jedem Browser unterschiedlich ist, auch wenn es in diesem Artikel einheitlich besprochen wird.
- Quirks-Modus
- Im Quirks-Modus verstößt der Browser gegen moderne Webformate, um zu verhindern, dass Seiten beschädigt werden, die auf in den späten 1990er Jahren beliebten Praktiken erstellt wurden. Verschiedene Browser implementieren unterschiedliche Macken. In Internet Explorer 6, 7 und 8 friert der Quirks-Modus IE 5.5 effektiv ein. In anderen Browsern ist der Quirks-Modus eine kleine Abweichung vom Standardmodus.
- Wenn Sie eine neue Webseite erstellen, sollten Sie relevante Spezifikationen (insbesondere CSS2.1) einhalten und den Standardmodus verwenden.
- Standardmodus
- Im Standardsmodus versucht der Browser, standardkonforme Dokumente genauso normativ korrekt zu behandeln wie im angegebenen Browser.
- Unterschiedliche Browser folgen unterschiedlichen Phasen, daher ist der Standardmodus kein einziges Ziel.
- HTML5 nennt diesen Modus „No-Quirks-Modus“
- Almost-Standards-Modus (Almost-Standards-Modus)
- Auch Firefox, Safari, Chrome, Opera (ab 7.5) und IE8 verfügen über einen Modus namens „Quasi-Standard-Modus“, der die vertikale Größe von Tabellenzellen nach herkömmlichen Methoden implementiert, anstatt sich strikt an die CSS2-Spezifikationen zu halten. Mac IE5, Windows IE6 und 7, Versionen vor Opera7.5 und Konqueror benötigen keinen Quasi-Standardmodus, da sie sich zumindest nicht strikt an die CSS2-Spezifikation halten, um die vertikalen Abmessungen von Tabellenzellen in ihren jeweiligen Standardmodi zu implementieren. Tatsächlich ähnelt ihr Standardmodus eher dem Quasi-Standardmodus von Mozilla als dem Standardmodus von Mozilla.
- HTML5 nennt diesen Modus „Limited Quirks Mode“.
- IE7-Modus
- IE8 verfügt über einen Modus, der hauptsächlich eine Kopie des IE7-Standardmodus einfriert. Kein anderer Browser verfügt über einen solchen Modus und er wird auch nicht von HTML5 spezifiziert.
Modus mit Inhaltstyp application/xhtml xml (XML-Modus)
In Firefox, Safari, Chrome und Opera löst der XML-HTTP-Inhaltstyp application/xhtml (kein Metaelement und kein Doctype!) den XML-Modus aus. Im XML-Modus versucht der Browser, das XML-Dokument in dem im Browser angegebenen Umfang spezifikationsgerecht zu verarbeiten.
IE6, 7 und 8 unterstützen weder application/xhtml xml noch Mac IE5.
Im Browser des Nokia S60, der auf WebKit basiert, kann der HTTP-Inhaltstyp application/xhtml xml den XML-Modus nicht auslösen, da der Schwerpunkt in mobilen Walled Gardens auf der Kompatibilität mit nicht standardmäßigen Inhalten liegt. (Ältere „mobile Browser“ können keine echten XML-Parser verwenden , da nicht-kanonische Inhalte als XML markiert sind.)
Da ich Konqueror nicht ausreichend getestet habe, kann ich nicht genau sagen, was in diesem Browser passieren wird.
Nicht-Web-Modi
Einige Engines verfügen über Modi, die nichts mit Webinhalten zu tun haben. Der Vollständigkeit halber werden sie hier nur erwähnt. Opera verfügt über einen WML2.0-Modus. WebKit auf Leopard verfügt über einen speziellen Modus für ältere Dashboard-Widgets.
Auswirkungen
Hier sind die wichtigsten Auswirkungen dieser Muster:
Layout
Der Text/HTML-Modus wirkt sich hauptsächlich auf das CSS-Layout aus. Es ist zum Beispiel eine Eigenart, dass Tabellen keine Stile erben. In einigen Browser-Mackenmodi wird das Box-Modell zum IE5.5-Box-Modell. In diesem Dokument werden nicht alle Layout-Macken aufgeführt.
Im Semi-Standard-Modus (in Browsern mit diesem Modus) unterscheidet sich nur die Höhe der Tabellenzelle, die das Bild enthält, von der im Standard-Modus.
Im XML-Modus weisen Selektoren ein unterschiedliches Verhalten auf, bei dem die Groß-/Kleinschreibung beachtet wird. Darüber hinaus gelten die spezifischen Regeln für das HTML-Body-Element nicht für ältere Browser, die die neuesten CSS 2.1-Änderungen nicht implementieren.
Analyse
Es gibt auch Macken, die sich auf die Analyse von HTML und CSS auswirken und dazu führen können, dass standardkonforme Webseiten falsch analysiert werden. Das Quirk-Layout bestimmt, ob diese Macken aktiviert sind oder nicht. Unabhängig davon ist es wichtig, die wichtigsten Gemeinsamkeiten und Unterschiede zwischen dem Quirks-Modus und dem Standards-Modus beim CSS-Layout und beim Parsen (nicht beim HTML-Parsen) zu verstehen.
Manche Leute bezeichnen den Standardmodus fälschlicherweise als „strengen Analysemodus“, was zu Missverständnissen über die Fähigkeit des Browsers, HTML-Syntaxregeln durchzusetzen, und die Fähigkeit des Browsers, Markup auf Korrektheit zu prüfen, führt. Dies ist nicht der Fall. Selbst wenn das Standardmodus-Layout in Kraft ist, führen Browser immer noch Korrekturarbeiten an der Tag-Suppe (http://en.wikipedia.org/wiki/Tag_soup) durch. (Vor der Veröffentlichung von Netscape 6 im Jahr 2000 verfügte Mozilla über Parsing-Modi zur Durchsetzung von HTML-Syntaxregeln. Diese Modi waren mit vorhandenen Webinhalten nicht kompatibel und wurden aufgegeben.)
Ein weiteres häufiges Missverständnis betrifft das XHTML-Parsing. Es wird allgemein angenommen, dass die Verwendung des XHTML-Dokumenttyps zu einer unterschiedlichen Analyse führt. Tatsächlich ist dies nicht der Fall. XHTML-Dokumente mit dem Inhaltstyp text/html verwenden denselben Parser wie HTML-Dokumente. Derzeit kümmern sich Browser nur darum, dass XHTML mit dem Dokumenttyp text/html nur „Tag-Suppe mit Croutons“ ist (überall zusätzliche Schrägstriche).
Nur wenn Dokumente, die den XML-Dokumenttyp verwenden (z. B. application/xhtml xml oder xmapplication/), den XML-Modus zum Parsen auslösen, unterscheidet sich der Parser zu diesem Zeitpunkt vollständig vom HTML-Parser.
Skript
Während es im Quirks-Modus hauptsächlich um CSS geht, geht es auch ein wenig um Skripting. Beispielsweise erstellt das HTML-ID-Attribut im Quirks-Modus von Firefox eine globale Objektreferenz im Skriptbereich, genau wie im IE. Die Auswirkungen von Skripten im IE8 verdienen mehr Aufmerksamkeit als in anderen Browsern.
Im XML-Modus ist das Verhalten einiger DOM-APIs völlig anders, da das Verhalten der DOM-API von XML nicht mit dem Verhalten von HTML kompatibel ist, wenn es definiert ist.
Doctype-Sniffing (auch Doctype-Konvertierung genannt)
Moderne Browser verwenden Doctype-Sniffing, um den Engine-Modus von Text-/HTML-Dokumenten zu bestimmen. Dies bedeutet, dass die Wahl des Modus auf der Dokumenttypdeklaration (oder dem Fehlen einer solchen) am Anfang des HTML-Dokuments basiert. (Dies gilt nicht für Dokumente, die den XML-Dokumenttyp verwenden.)
Die Dokumenttypdeklaration (Doctype) ist eine grammatikalische Fälschung von SGML, einem Markup-Framework alten Stils, und HTML, bevor HTML5 darauf basiert. In der HTML4.01-Spezifikation beschreibt die Dokumenttypdeklaration die Versionsinformationen von HTML. Trotz des Namens „Document Type Declaration“ und der HTML 4.01-Spezifikation, die „Versionsinformationen“ beschreibt, klassifiziert eine Document Type Declaration ein SGML- oder XML-Dokument nicht als einen bestimmten Dokumenttyp, auch wenn es (aufgrund des Namens) so aussieht. . (Mehr im Anhang)
Weder die HTML4.01-Spezifikation noch ISO 8879 (SGML) sagen etwas über die Verwendung von Dokumenttypdeklarationen als Engine-Modus-Konvertierungen aus. Doctype Sniffing basiert auf der Beobachtung, dass zum Zeitpunkt der Entwicklung von Doctype Sniffing die überwiegende Mehrheit der eigenartigen Dokumente weder eine Dokumenttypdeklaration noch einen Verweis auf eine ältere DTD hatte. HTML5 akzeptiert diese Tatsache und definiert den Doctype in text/html als einzige Moduskonvertierung.
Eine typische Dokumenttypdeklaration vor HTML5 enthält (durch Leerzeichen getrennt) die Zeichenfolge „“. Die Dokumenttypdeklaration wird vor dem öffnenden Tag des Stammelements des Dokuments platziert.
Dokumenttyp auswählen
text/html
Hier ist eine einfache Anleitung zur Auswahl eines Dokumenttyps beim Erstellen eines neuen Text-/HTML-Dokuments:
- Standardmodus, modernste Validierung
- Wenn Sie verifizieren möchten, z. B , und neue Funktionen wie ARIA, dann ist dies das Richtige. Beachten Sie, dass sich die effektive Definition von HTML5 noch ändert. Testen Sie daher unbedingt die Bildausrichtung in Firefox, Safari, Chrome, Opera9 oder Opera10. Das Testen der Bildausrichtung im Internet Explorer reicht nicht aus. Testen Sie auf jeden Fall auch im IE8.
- Standardmodus, stabileres Überprüfungsziel
- Dieser Dokumenttyp löst auch den Standardmodus aus und die 10 Jahre alte gültige HTML4.01-Definition ist stabil. Bitte testen Sie die Bildausrichtung unbedingt in Firefox, Safari, Chrome, Opera9 oder Opera10. Das Testen der Bildausrichtung im Internet Explorer reicht nicht aus. Testen Sie auf jeden Fall auch im IE8.
- Um den Standardmodus zu verwenden, aber dennoch sicherzustellen, dass Markup oder die Verwendung von Slices-Bildern in Tabellenlayouts nicht empfohlen wird und Sie diese nicht beheben möchten.
- Es löst den Halbstandardmodus (und den alten Vollstandardmodus in Mozilla) aus. Bitte beachten Sie, dass Layouts, die auf segmentierten Bildern basieren, die mithilfe von Tabellen implementiert wurden, bei einer zukünftigen Portierung nach HTML5 fehlerhaft sein können (dasselbe gilt für den vollständigen Standardmodus).
- Verwendung des Quirks-Modus mit Absicht
- Kein Doctype.
- Bitte tun Sie dies nicht. Das absichtliche Entwerfen für den Quirks-Modus wird Sie stören, und in Zukunft wird sich keiner Ihrer Kollegen oder Nachfolger mehr für Windows IE6 interessieren (niemand kümmert sich mehr um Netscape 4.x und IE5). Für den Quirks-Modus zu entwerfen ist eine schlechte Idee. Glauben Sie mir.
- Wenn Sie Windows IE6 weiterhin unterstützen möchten, ist es besser, einen speziellen Hack dafür zu erstellen, indem Sie bedingte Kommentare verwenden, als andere Browser dazu zu bringen, in den Mackenmodus zurückzukehren.
Ich empfehle keinen XHTML-Dokumenttyp, da XHTML, das als Text/HTML verwendet wird, als schädlich gilt . Wenn Sie sich jedoch für die Verwendung des XHTML-Dokumenttyps entscheiden, beachten Sie, dass XML-Deklarationen den Quirks-Modus in IE6 (aber nicht in IE7!) auslösen.
application/xhtml xml
Eine einfache Richtlinie für application/xhtml XML ist, niemals Doctype zu verwenden. Webseiten auf diese Weise sind nicht „streng konsistent“ mit XHMTL 1.0, aber das spielt keine Rolle. (Siehe bitte den Anhang hinten)
IE8-Komplikationen
A List Apart hat einmal eingeführt , dass IE8 zusätzlich zum Doctype die Moduskonvertierung basierend auf Metaelementen als einen der Faktoren bei der Modusauswahl verwenden wird. (Siehe Ian Hickson, David Baron, David Baron again, Robert O'Callahan und Maciej Stachowiak Kommentare . )
IE8 verfügt über 4 Modi: IE5.5-Quirks-Modus, IE7-Standardmodus, IE8-Quasi-Standardmodus und IE8-Standardmodus. Die Wahl des Modus hängt von Daten aus mehreren Quellen ab: Dokumenttyp, Metaelemente, HTTP-Header, periodische Download-Daten von Microsoft, LAN-Domäne, vom Benutzer vorgenommene Einstellungen, vom LAN-Administrator vorgenommene Einstellungen und der Modus des übergeordneten Frames (falls vorhanden). beliebig) Kompatibel mit der Adressleisten-Ansichtsschaltfläche wird vom Benutzer ausgelöst. (Bei anderen in die Engine eingebetteten Apps hängt der Modus auch von der eingebetteten App ab.)
Glücklicherweise verwendet IE8 im Allgemeinen Doctype-Sniffing wie andere Browser, wenn:
- Der Autor hat den X-UA-kompatiblen HTTP-Header nicht festgelegt
- Der Autor hat das X-UA-kompatible Meta-Tag nicht gesetzt
- Microsoft hat den Domänennamen dieser Website nicht auf die schwarze Liste gesetzt
- Der LAN-Administrator hat diese Site nicht auf die Blacklist gesetzt
- Der Benutzer hat nicht auf die Schaltfläche „Kompatibilitätsansicht“ geklickt (oder wurde anderweitig zu einer bestimmten Benutzer-Blacklist hinzugefügt)
- Diese Site befindet sich nicht in der LAN-Domäne
- Der Benutzer hat nicht ausgewählt, alle Websites in IE7 anzuzeigen
- Die Seite ist nicht über den Frame in die Kompatibilitätsmodusseite eingebettet
Mit Ausnahme der beiden oben genannten Fälle bezüglich X-UA-Kompatibilität führt IE8 das Doctype-Sniffing wie IE7 durch. Die IE7-Emulation wird als Kompatibilitätsansicht bezeichnet.
Im Fall von X-UA-Compatible verhält sich IE8 völlig anders als andere Browser. Ich würde gerne den Anhang oder das Flussdiagramm in den Formaten PDF und PNG auf dieser Seite sehen.
Leider ermöglicht IE8 Benutzern ohne den X-UA-kompatiblen HTTP-Header oder Meta-Tag, selbst mit dem entsprechenden Dokumenttyp, versehentlich ein Downgrade der Seite vom IE8-Standardmodus auf den IE7-Modus, bei dem es sich um eine Emulation des IE7-Standardmodus handelt. Schlimmer noch, LAN-Administratoren können dies auch tun. Microsoft kann auch alle von Ihnen verwendeten Domänennamen auf die schwarze Liste setzen.
Um mit diesen Effekten umzugehen, reicht der Doctype nicht aus, Sie benötigen einen X-UA-kompatiblen HTTP-Header und ein Meta-Tag.
Im Folgenden finden Sie eine einfache Anleitung zur Auswahl des X-UA-kompatiblen HTTP-Headers oder Meta-Tags für neue Text-/HTML-Dokumente, die bereits über einen Dokumenttyp verfügen, der in anderen Browsern den Standardmodus oder Quasi-Standardmodus auslöst:
- Ihre Domain steht nicht auf der Blacklist von Microsoft und es geht Ihnen mehr darum, keine browserspezifischen Belästigungen zu verursachen, als sicherzustellen, dass Benutzer nicht auf das IE7-Verhalten zurückgreifen können.
- Sie müssen den X-UA-kompatiblen HTTP-Header oder Meta-Tag nicht einschließen.
- Ihr Domänenname steht auf der schwarzen Liste von Microsoft. Da andere Autoren in Ihrem Domänennamen die Website beschädigt oder Benutzer dazu veranlasst haben, die Kompatibilitätsansicht für die gesamte Domäne zu aktivieren, befürchten Sie, dass Google oder Digg Frames zum Einbetten verwenden Site oder Ihre Site. Um sicherzustellen, dass Benutzer keine kompatiblen Ansichten verwenden können
- Fügen Sie zunächst das folgende Metaelement in Ihre Seite ein (es ist in HTML5 illegal) (vor jedem Skriptelement) oder legen Sie den folgenden HTTP-Header fest: Breaking
- in IE8 Fügen Sie zunächst das folgende Metaelement in Ihre Seite ein (it ist in HTML5 illegal) (vor einem beliebigen Skriptelement) oder legen Sie den folgenden HTTP-Header fest:
- Verwandte Links
Eric Meyer schreibt über Mac IE5-Muster in
- Verwendung des richtigen Dokumenttyps
- Doctype Sniffing für Mozilla
- von David Baron Lance Silver bespricht Modus- und Doctype-Sniffing in Windows IE6 in CSS-Verbesserungen in IE6
- Doctype-Konvertierung für Opera9
- Faruk Ateşs IE8- und X-UA-kompatible Lösung
- Nachtrag: Ein Appell an XML-Implementierer und Spezifikationsautoren
Bitte bringen Sie kein Doctype-Sniffing in XML ein.
Doctype Sniffing ist ein Tag-Chowder-ähnlicher Ansatz zur Lösung eines Tag-Chowder-Problems. Doctype-Sniffing ist eine Heuristik, die nach der Veröffentlichung der HTML4- und CSS2-Spezifikationen entwickelt wurde und veraltete Dokumente von Dokumenten unterscheidet, die dem Verhalten entsprechen, das ihre Autoren möglicherweise erwartet hätten.
Gelegentlich wird empfohlen, Doctype Sniffing für XML zu verwenden, um verschiedene Verarbeitungen zu planen, das verwendete Vokabular zu identifizieren oder Funktionen zu aktivieren. Das ist eine schlechte Idee. Planung und Vokabularidentifizierung sollten auf Namespaces basieren, während die Funktionsaktivierung auf expliziten Verarbeitungsanweisungen oder -elementen basieren sollte.
Die gesamte Idee der Wohlgeformtheit besteht darin, das DTD-freie Parsen von XML einzuführen und eine doctype-freie Dokumentation zu fördern. Im formalen Fall, dass zwei XML-Dokumente dieselbe kanonische Form haben und die Anwendung sie unterschiedlich verarbeitet (und der Unterschied nicht auf mangelnde Auswahlmöglichkeiten zur Verarbeitung externer Entitäten zurückzuführen ist), kann die Anwendung fehlerhaft sein. Wenn in der Praxis zwei XML-Dokumente dazu führen, dass derselbe Inhalt an einen SAX2-
-Content-Handler gemeldet wird (Qnames werden ignoriert) und die Anwendung die Dokumente unterschiedlich verarbeitet, kann die Anwendung kaputt gehen. In Anbetracht der Tatsache, dass Sie als Webautoren nicht darauf vertrauen können, dass jeder einen XML-Prozessor verwendet, der zusätzliche Entitäten auflöst, um seine Seiten zu analysieren (auch wenn einige Browser dies scheinbar tun, weil sie bestimmte öffentliche Bezeichner einer verkürzten entitätsdefinierenden DTD zuordnen), Einfügen Doctypes in XML für das Web umzuwandeln ist sinnlos und führt oft zu Cargo-Kultgewohnheiten. (Sie verwenden immer noch die DTD-Override-Funktion von W3C Validator, um eine DTD zu validieren, obwohl W3C Validator angibt, dass das Ergebnis nur vorübergehend gültig ist. Oder noch besser, Sie können NG mit Validieren lockern, es verunreinigt nicht das vom Schema referenzierte Dokument. Es ist ziemlich dumm, einen Doctype zu verlangen, um zu schnüffeln, auch wenn das in der HTML-Praxis der Workaround ist. Wenn eine Spezifikation auf niedrigerer Ebene zwei Dinge als gleich definiert, sollte eine Spezifikation auf höherer Ebene nicht versuchen, ihnen unterschiedliche Bedeutungen zu geben. Bitte beachten Sie . Wenn Sie die öffentliche Kennung entfernen, wird weiterhin dieselbe DTD angegeben, sodass doctype bedeutet dasselbe wie der vorherige Dokumenttyp. Sollten sie anders gerochen werden? Kann weitere Theorien aufstellen. Angenommen, eine DTD namens foobar.dtd wird nach example.com kopiert: . Wie kann man das erschnüffeln? Es sollte dasselbe bedeuten. Sogar die gesamte DTD kann an das Dokument angehängt werden. Mit anderen Worten: Wenn #include „foo.h“ vorhanden ist, sollten Sie keine schwarze Magie an den Namen foo.h binden, da dies das Kopieren des Inhalts von foo.h in das Dokument oder das Kopieren von foo ermöglichen sollte. h in bar.h ein und bedeutet #include „bar.h“. Der Grund, warum ich mir keine Sorgen darüber mache, dass HTML und SGML dieselben Parameter erstellen, ist, dass Webbrowser keine echten SGML-Parser zum Parsen von HTML verwenden. Daher halte ich es nicht für sinnvoll, vorzugeben, SGML zu sein. Wie auch immer, wenn Sie noch nicht überzeugt sind, finden Sie hier W. Eliot Kimbers Artikel zu diesem Thema comp.text.sgml In der folgenden Tabelle werden der Quirk-Modus, der Standardmodus und der Quasi-Standard durch Q, S bzw. A dargestellt. Wenn der Browser nur über zwei Modi verfügt und die Zeilenhöhe der Tabellenzelle mit dem Standardmodus von Mozilla übereinstimmt, wird der Standardmodus mit „S“ gekennzeichnet. Wenn die Zeilenhöhe der Tabellenzelle mit dem Quasi-Standardmodus von Mozilla übereinstimmt, wird der Standardmodus mit „S“ gekennzeichnet. dann wird es als „A“ gekennzeichnet. Bitte beachten Sie, dass XHTML, das mit dem XML-Inhaltsmodell bereitgestellt wird, im XML-Modus gerendert wird. Der Zweck dieser Tabelle besteht nicht darin, zu sagen, dass alle Dokumenttypen in der Tabelle eine sinnvolle Wahl für neue Seiten sind. Der Zweck dieser Tabelle besteht darin, zu zeigen, auf welchen Daten meine Empfehlungen basieren. Für Spaltenüberschriften werden folgende Abkürzungssymbole verwendet: Anhang: Umgang mit einigen Dokumenttypen in Text/HTML
Geschichte
Moziilas Doctype-Sniffing-Code wurde im Oktober 2000, September 2001 und Juni 2002 erheblich geändert. Der Status des in diesem Dokument beschriebenen Mozilla-Builds (und Netscape 6.x) kann unter ftp.mozilla.org ab dem 19.10.2000 eingesehen werden. In diesem Dokument wird nicht behandelt, wie das Doctype-Sniffing in Mozilla M18 (und Netscape 6.0 PR3) funktioniert. Auch der Doctype-Sniffing-Code von Safari wurde seit der ersten öffentlichen Betaversion erheblich verändert. Dieses Dokument behandelt kein Verhalten vor Version V73, auch 0.9 genannt.
Der Doctype-Sniffing-Code vor Konqueror 3.5 scheint aus einer sehr frühen Version von Safari zu stammen. Konqueror entspricht jetzt Safari und sein Doctype-Sniffing-Code stammt von Mozilla.
Wie aus der Tabelle hervorgeht, ändert sich das Doctype-Sniffing von Opera regelmäßig von einer Ähnlichkeit mit dem IE zu einer Ähnlichkeit mit Mozilla, obwohl Opera 9.5 und 9.6 auf dem Rückweg sind. Gleichzeitig wurde das Layoutverhalten des Opera-Quirks-Modus von der Emulation des Quirks-Modus von IE6 auf den Quirks-Modus von Mozilla umgestellt.
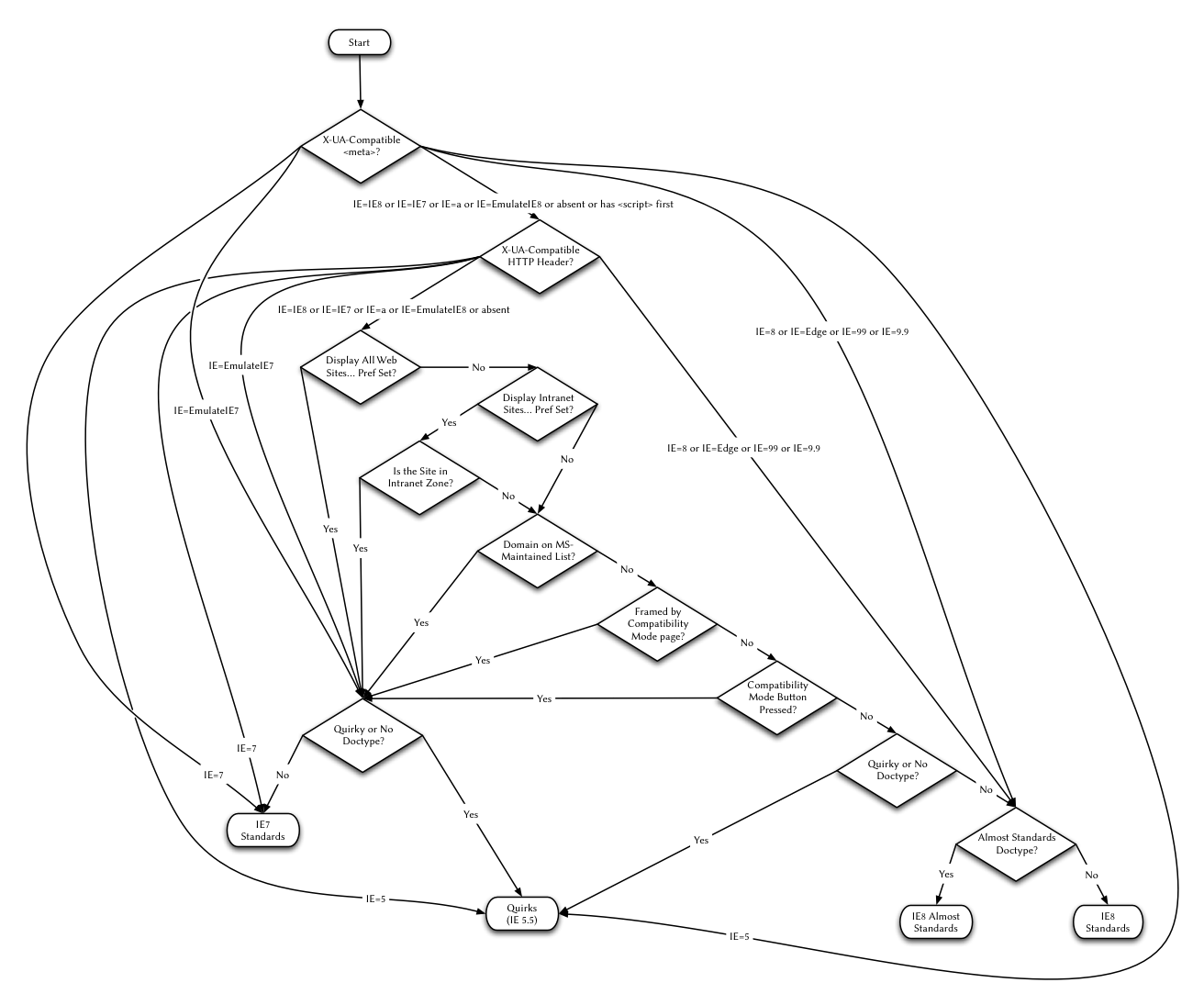
Anhang: Modusauswahl für IE8
- Start: „X-UA-kompatibles Meta?“ eingeben
- X-UA-kompatibles Meta?
- IE=7: IE7-Standard verwenden
- IE=EmulateIE7: Geben Sie „Macken oder kein Doctype? (Kompatibilitätsmodus)“ ein.
- IE=IE8 oder IE=IE7 oder IE=a oder IE=EmulateIE8 oder nein oder erstes Skript: Geben Sie „X-UA-kompatibel“ ein HTTP-Header? 5)
- )“
- IE=IE8 oder IE=IE7 oder IE=a oder IE=EmulateIE8 oder keine: Geben Sie „Alle Websites anzeigen...Voreinstellung?“ ein
- IE=8 oder IE=Edge oder IE=99 oder IE=9.9: „Quasi-Standards-Modus“ aufrufen
- IE=5: Quirks-Modus verwenden (IE5.5)
- Quacks Modus oder kein Doctype? (Kompatibilitätsmodus)
- Ja: Quirks-Modus verwenden (IE5.5)
- Nein: IE7-Standardmodus verwenden
- Alle Websites anzeigen... Voreingestellt ?
- Ja: Geben Sie „Mackenmodus oder kein Dokumenttyp? (Kompatibilitätsmodus)“ ein.
- Nein: Geben Sie „LAN-Site anzeigen...voreingestellt?“ ein.
- LAN-Site anzeigen. ..Voreinstellung eingerichtet?
- Ja: Geben Sie „Die Site befindet sich in der LAN-Domäne ein?“
- Nein: Geben Sie „Der Domänenname steht auf der von Microsoft verwalteten Liste ein?“
- Die Domäne Name steht auf der von Microsoft geführten Liste?
- Ja: Geben Sie „Quirk-Modus oder kein Dokumenttyp? (Kompatibilitätsmodus)“ ein.
- Nein: Geben Sie „Eingebettet in Frame mit Kompatibilitätsmodus-Seite“ ein.
- Kompatibilitätsmodus-Seite Einbettung mit Rahmen?
- Ja: Gehen Sie zu „Quirks-Modus oder kein Dokumenttyp? (Kompatibilitätsmodus)“
- Nein: Gehen Sie zu „Kompatibilitätsmodus-Taste gedrückt?“
- Kompatibilitätsmodus-Taste gedrückt?
- Ja: Geben Sie „Quirks-Modus oder kein Doctype? (Kompatibilitätsmodus)“ ein.
- Nein: Geben Sie „Quirks-Modus oder kein Doctype? (IE8)“ ein.
- Quirks-Modus oder Kein Dokumenttyp? (IE8)
- Ja: „Quirks-Modus verwenden (IE5.5)“
- Nein: „Quasi-Standards-Modus“ aufrufen
- Vorstandards Modus?
- Ja: IE8-Semi-Standardmodus verwenden
- Nein: IE8-Standardmodus verwenden
- Diese Schritte können als Flussdiagramme in den Formaten
- PNG angezeigt werden.
- Danke
Vielen Dank an Simon Pieters, Simon Pieters und Anne van Kesteren für ihre Hilfe bei der Korrektur der Musterblätter für verschiedene Opera-Versionen und für ihre Kommentare. Vielen Dank an Simon Pieters für die Erstellung eines weiteren IE8-Flussdiagramms.

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

{kind=link}
 Wie kann man Lückeneffekt auf das Karten- und Gutscheinlayout mit Gradientenhintergrund erzielen?
Apr 05, 2025 am 07:48 AM
Wie kann man Lückeneffekt auf das Karten- und Gutscheinlayout mit Gradientenhintergrund erzielen?
Apr 05, 2025 am 07:48 AM
Erkennen Sie den Lückeneffekt des Karten -Gutschein -Layouts. Beim Entwerfen von Karten -Gutschein -Layout begegnen Sie häufig die Notwendigkeit, Lücken zu Karten -Gutscheinen hinzuzufügen, insbesondere wenn der Hintergrund Gradient ist ...
 Warum wirkt sich negative Margen in einigen Fällen nicht wirksam? Wie löst ich dieses Problem?
Apr 05, 2025 pm 10:18 PM
Warum wirkt sich negative Margen in einigen Fällen nicht wirksam? Wie löst ich dieses Problem?
Apr 05, 2025 pm 10:18 PM
Warum werden negative Margen in einigen Fällen nicht wirksam? Während der Programmierung negative Margen in CSS (negativ ...
 Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalten Sie Echtzeit-Anwendungs- und Zuschauerdaten auf der Arbeit von 58.com?
Apr 05, 2025 am 08:06 AM
Wie erhalte ich dynamische Daten von 58.com Arbeitsseite beim Kriechen? Wenn Sie eine Arbeitsseite von 58.com mit Crawler -Tools kriechen, können Sie auf diese begegnen ...
 Wie zeige ich die lokal installierte 'Jingnan Mai Round Body' auf der Webseite richtig?
Apr 05, 2025 pm 10:33 PM
Wie zeige ich die lokal installierte 'Jingnan Mai Round Body' auf der Webseite richtig?
Apr 05, 2025 pm 10:33 PM
Mit lokal installierten Schriftdateien auf Webseiten kürzlich habe ich eine kostenlose Schriftart aus dem Internet heruntergeladen und sie erfolgreich in mein System installiert. Jetzt...
 Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Wie kann man das Größensymbol durch CSS anpassen und es mit der Hintergrundfarbe einheitlich machen?
Apr 05, 2025 pm 02:30 PM
Die Methode zur Anpassung der Größe der Größe der Größe der Größe in CSS ist mit Hintergrundfarben einheitlich. In der täglichen Entwicklung begegnen wir häufig Situationen, in denen wir die Details der Benutzeroberfläche wie Anpassung anpassen müssen ...
 Der Text unter Flex -Layout wird weggelassen, aber der Behälter wird geöffnet? Wie löst ich es?
Apr 05, 2025 pm 11:00 PM
Der Text unter Flex -Layout wird weggelassen, aber der Behälter wird geöffnet? Wie löst ich es?
Apr 05, 2025 pm 11:00 PM
Das Problem der Containeröffnung aufgrund einer übermäßigen Auslassung von Text unter Flex -Layout und Lösungen werden verwendet ...
 Wie verwendet ich CSS und Flexbox, um das reaktionsschnelle Layout von Bildern und Text in verschiedenen Bildschirmgrößen zu implementieren?
Apr 05, 2025 pm 06:06 PM
Wie verwendet ich CSS und Flexbox, um das reaktionsschnelle Layout von Bildern und Text in verschiedenen Bildschirmgrößen zu implementieren?
Apr 05, 2025 pm 06:06 PM
Implementieren von Responsive Layouts mit CSS, wenn wir Layoutänderungen unter verschiedenen Bildschirmgrößen im Webdesign, CSS ...
 IconFont -Symbol zeigt zeitweise abnormal? So fördern Sie Codierungsprobleme und lösen Sie Probleme
Apr 05, 2025 am 07:54 AM
IconFont -Symbol zeigt zeitweise abnormal? So fördern Sie Codierungsprobleme und lösen Sie Probleme
Apr 05, 2025 am 07:54 AM
Iconfont ...
