

MongoDB入门学习(四):MongoDB的索引

上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集
上一篇讲到了MongoDB的基本操作增删查改,对于查询来说,必须按照我们的查询要求去集合中,并将查找到的结果返回,在这个过程中其实是对整个集合中每个文档进行了扫描,如果满足我们的要求就添加到结果集中最后返回。对于小集合来说,这个过程没什么,但是集合中数据很大的时候,进行表扫描是一个非常恐怖的事情,于是有了索引一说,索引是用来加速查询的,相当于书籍的目录,有了目录可以很精准的定位要查找内容的位置,从而减少无谓的查找。
1.索引的类型
创建索引可以是在单个字段上,也可以是在多个字段上,这个根据自己的实际情况来选择,创建索引时字段的顺序也是有讲究的。创建索引是通过ensureIndex()方法,需要给该方法传递一个文档形式的数据,其中指定索引的字段和顺序,1代表升序,-1代表降序。
1).默认索引
还记得"_id"吗,这个字段的数据是不能重复的,它就是MongoDB的默认索引,而且不能被删除。
2).单列索引
在单个字段上创建的索引就是单列索引,在查询的过程中可以对该加速对该键的查询,然而对其他键的查询是没有帮助的。单列索引的顺序是不会影响对该键的随即查询,创建单列索引:
> db.people.ensureIndex({"name" : 1})3).组合索引
还可以在多个键上创建组合索引,此时键的位置和索引的顺序都会影响查询的效率,看下面创建组合索引:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.ensureIndex({"age" : 1, "name" : 1})第一种情况会对name排序组织,当name一样时在对age排序,所以对{"name" : 1}和{“name” : 1, "age" : 1}的查询更高效,而第二种情况则对age排序,当age一样再对name排序,所以对{"age" : 1}和{"age" : 1, "name" : 1}的查询更高效。当组合索引包含很多字段的时候,会对前几个键的查询有帮助。
4).内嵌文档索引
还可以对内嵌文档创建索引,和普通键创建索引一样差不多,也可以对内嵌文档创建组合索引:
> db.people.ensureIndex({"friends.name" : 1})
> db.people.ensureIndex({"friends.name" : 1, "friends.age" : 1})在来看看其他几种形式的索引:
唯一索引
> db.people.ensureIndex({"name" : 1}, {"unique" : true})
> db.people.ensureIndex({"name" : 1}, {"unique" : true, "dropDups" : true})
松散索引
> db.people.ensureIndex({"name" : 1}, {"sparse" : true})
多值索引
> db.people.find()
{"name" : ["mary", "rose"]}
> db.people.ensureIndex({"name" : 1})唯一索引unique可以保证该键对应的值在集合中是唯一的,如果创建唯一索引的时候,该字段原来就存在了重复的数据,那么就会创建失败,可以加上dropDups字段来消除重复数据,它会保留发现的第一个文档,其他有重复数据的文档都将被删除。
集合中有的文档不存在某些字段,或者某些字段的值为null,那么我们在该字段上创建索引的时候不希望让这些空值的文档参与,那么就定义为松散索引sparse,比如在name上创建索引时,发现有的人在数据库中只有学号,没有名字,那么我们不希望把它们也包含进来,此时就定义为松散索引。
一个键对应的值是一个数组,在该键上创建索引时是一个多值索引,会为数组中每个值生成一个索引元素,相当于分裂成了几个独立的索引项,但是它们还是对应同一个文档数据。
2.索引的管理
索引固然是为查询而生,而且可以为每个键都创建索引,但是索引是需要存储空间的,所以索引不是越多越好,而且创建索引后,每次的插入,更新和删除文档都会产生额外的开销,因为数据库中不但要执行这些操作,而且还要在集合索引中标记这些操作。所以要根据实际情况来创建索引,索引没用之后将其删除。
创建索引是ensureIndex()方法,创建完成后可以通过getIndexes()来查看集合中创建的索引情况:
> db.people.ensureIndex({"name" : 1, "age" : 1})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "name_1_age_1"
}
]可以看到people集合创建了两个索引,一个是"_id",这个是默认索引,另外一个是name和age的组合索引,名字为keyname1_dir_keyname2_dir_...,keyname代表索引的键,dir代表方向,1代表升序,-1代表降序。当然我们也可以自定义索引的名称:
> db.people.ensureIndex({"name" : 1, "age" : 1}, {"name" : "myIndex"})
> db.people.getIndexes()
[
{
"v" : 1,
"key" : {
"_id" : 1
},
"ns" : "test.people",
"name" : "_id_"
},
{
"v" : 1,
"key" : {
"name" : 1,
"age" : 1
},
"ns" : "test.people",
"name" : "myIndex"
}
]删除索引是通过dropIndex():
方式一:
> db.people.dropIndex({"name" : 1, "age" : 1})
{ "nIndexesWas" : 2, "ok" : 1 }
方式二:
> db.runCommand({"dropIndexes" : "people", "index" : "myIndex"})
{ "nIndexesWas" : 2, "ok" : 1 }索引的元信息存储在每个数据库的system.indexes集合中,不能对其进行插入和删除文档的操作,只能通过ensureIndex和dropIndex进行。
> db.system.indexes.find()
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.people", "name" : "_id_" }
{ "v" : 1, "key" : { "name" : 1, "age" : 1 }, "ns" : "test.people", "name" : "myIndex" }清空集合中所有的文档是不会将索引删除的,原来创建的索引依然存在,但是直接删除集合的话,该集合的索引也是会被删除的。
3.索引的效率
如果我们定义了很多的索引,那么MongoDB会根据我们的查询选项重新排序,并智能的选择一个最优的来使用,比如我们创建了{"name" : 1, "age" : 1}和{"age" : 1, "class" : 1}两个索引,但是我们的查询项为find({"age" : 10, "name" : "mary"}),那么MongoDB会自动重新排序为find({"name" : "mary", "age" : 10}),并且利用索引{"name" : 1, "age" : 1}来查询。
MongoDB提供了explain工具来帮助我们获得查询方面的很多有用信息,只要对游标调用这个方法就可以得到查询的细节。下面给math集合中添加10W个文档,再来看看使用索引前后的效率对比:
> var arr = [];
> for(var i = 0; i < 100000; i++){
... var doc = {};
... var value = Math.floor(Math.random() * 1000);
... doc["number"] = value;
... arr.push(doc);
... }
100000
> db.math.insert(arr)
> db.math.count()
100000
> db.math.find().limit(10)
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe5"), "number" : 462 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe6"), "number" : 123 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe7"), "number" : 90 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe8"), "number" : 46 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fe9"), "number" : 244 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fea"), "number" : 972 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61feb"), "number" : 925 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fec"), "number" : 110 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fed"), "number" : 739 }
{ "_id" : ObjectId("53a7f7c6e4fd24348ce61fee"), "number" : 945 }通过for循环给arr数组中添加10W条数据,然后再批量插入这些数据到math集合中,查看前10条数据,因为是随即生成的值,所以number字段的值会有重复值,我们就来查询462这个值:
创建索引前:
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BasicCursor",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 100000,
"nscanned" : 100000,
"nscannedObjectsAllPlans" : 100000,
"nscannedAllPlans" : 100000,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 35,
"indexBounds" : {
},
"server" : "server0.169:9352"
}
创建索引后:
> db.math.ensureIndex({"number" : 1})
> db.math.find({"number" : 462}).explain()
{
"cursor" : "BtreeCursor number_1",
"isMultiKey" : false,
"n" : 94,
"nscannedObjects" : 94,
"nscanned" : 94,
"nscannedObjectsAllPlans" : 94,
"nscannedAllPlans" : 94,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"number" : [
[
462,
462
]
]
},
"server" : "server0.169:9352"
}这里来看一下有用的信息,"cursor"指用的哪个索引,"nscanned"代表查找了多少个文档,"n"指返回文档的数量,"millis"表示查询所花时间,单位是毫秒。可以看出创建索引前没有使用索引,在全部的文档中查询的,花费了35毫秒,而创建索引后,使用了number_1索引查询,索引存储在B树结构中,只在94个文档中查询,几乎不花时间。
如果有很多索引的话,MongoDB会自动选一个来查询,你也可以通过hint来强制使用某个索引,这里强制使用{"age" : 1, "name" : 1}这个索引:
> db.people.find({"age" : {"$gt" : 10}, "name" : "mary"}).hint({"age" : 1, "name" : 1})
Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Generieren Sie PPT mit einem Klick! Kimi: Lassen Sie zuerst die „PPT-Wanderarbeiter' populär werden
Aug 01, 2024 pm 03:28 PM
Kimi: In nur einem Satz, in nur zehn Sekunden ist ein PPT fertig. PPT ist so nervig! Um ein Meeting abzuhalten, benötigen Sie einen PPT; um einen wöchentlichen Bericht zu schreiben, müssen Sie einen PPT vorlegen, auch wenn Sie jemanden des Betrugs beschuldigen PPT. Das College ähnelt eher dem Studium eines PPT-Hauptfachs. Man schaut sich PPT im Unterricht an und macht PPT nach dem Unterricht. Als Dennis Austin vor 37 Jahren PPT erfand, hatte er vielleicht nicht damit gerechnet, dass PPT eines Tages so weit verbreitet sein würde. Wenn wir über unsere harte Erfahrung bei der Erstellung von PPT sprechen, treiben uns Tränen in die Augen. „Es dauerte drei Monate, ein PPT mit mehr als 20 Seiten zu erstellen, und ich habe es Dutzende Male überarbeitet. Als ich das PPT sah, musste ich mich übergeben.“ war PPT.“ Wenn Sie ein spontanes Meeting haben, sollten Sie es tun
 Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Von Bare-Metal bis hin zu einem großen Modell mit 70 Milliarden Parametern finden Sie hier ein Tutorial und gebrauchsfertige Skripte
Jul 24, 2024 pm 08:13 PM
Wir wissen, dass LLM auf großen Computerclustern unter Verwendung umfangreicher Daten trainiert wird. Auf dieser Website wurden viele Methoden und Technologien vorgestellt, die den LLM-Trainingsprozess unterstützen und verbessern. Was wir heute teilen möchten, ist ein Artikel, der tief in die zugrunde liegende Technologie eintaucht und vorstellt, wie man einen Haufen „Bare-Metals“ ohne Betriebssystem in einen Computercluster für das LLM-Training verwandelt. Dieser Artikel stammt von Imbue, einem KI-Startup, das allgemeine Intelligenz durch das Verständnis der Denkweise von Maschinen erreichen möchte. Natürlich ist es kein einfacher Prozess, einen Haufen „Bare Metal“ ohne Betriebssystem in einen Computercluster für das Training von LLM zu verwandeln, aber Imbue hat schließlich erfolgreich ein LLM mit 70 Milliarden Parametern trainiert der Prozess akkumuliert
 KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
KI im Einsatz |. AI hat einen Lebens-Vlog eines allein lebenden Mädchens erstellt, der innerhalb von drei Tagen Zehntausende Likes erhielt
Aug 07, 2024 pm 10:53 PM
Herausgeber des Machine Power Report: Yang Wen Die Welle der künstlichen Intelligenz, repräsentiert durch große Modelle und AIGC, hat unsere Lebens- und Arbeitsweise still und leise verändert, aber die meisten Menschen wissen immer noch nicht, wie sie sie nutzen sollen. Aus diesem Grund haben wir die Kolumne „KI im Einsatz“ ins Leben gerufen, um detailliert vorzustellen, wie KI durch intuitive, interessante und prägnante Anwendungsfälle für künstliche Intelligenz genutzt werden kann, und um das Denken aller anzuregen. Wir heißen Leser auch willkommen, innovative, praktische Anwendungsfälle einzureichen. Videolink: https://mp.weixin.qq.com/s/2hX_i7li3RqdE4u016yGhQ Vor kurzem wurde der Lebens-Vlog eines allein lebenden Mädchens auf Xiaohongshu populär. Eine Animation im Illustrationsstil, gepaart mit ein paar heilenden Worten, kann in nur wenigen Tagen leicht erlernt werden.
 Ein weiterer Spieler auf Sora-Niveau kommt auf die Straße! Wir haben es mit Sora und Keling verglichen.
Aug 02, 2024 am 10:19 AM
Ein weiterer Spieler auf Sora-Niveau kommt auf die Straße! Wir haben es mit Sora und Keling verglichen.
Aug 02, 2024 am 10:19 AM
Als Sora nicht herauskam, nutzten die Gegner von OpenAI ihre Waffen, um die Straßen zu zerstören. Wenn Sora nicht zur Nutzung geöffnet ist, wird es wirklich gestohlen! Heute hat das Startup LumaAI aus San Francisco einen Trumpf ausgespielt und eine neue Generation des KI-Videogenerierungsmodells DreamMachine auf den Markt gebracht. Kostenlos und für alle verfügbar. Berichten zufolge kann das Modell auf Basis einfacher Textbeschreibungen hochwertige, realistische Videos generieren, mit vergleichbaren Effekten wie Sora. Sobald die Nachricht bekannt wurde, strömten zahlreiche Benutzer auf die offizielle Website, um es auszuprobieren. Obwohl Beamte behaupten, dass das Modell in nur zwei Minuten Videos mit 120 Bildern erzeugen kann, warten viele Benutzer aufgrund des Anstiegs der Besuche stundenlang auf die offizielle Website. BarkleyDai, Lumas Leiter für Produktwachstum, musste sich auf Discord äußern
 Kuaishou Keling AI ist weltweit vollständig für interne Tests geöffnet und der Modelleffekt wurde erneut verbessert
Jul 24, 2024 pm 08:34 PM
Kuaishou Keling AI ist weltweit vollständig für interne Tests geöffnet und der Modelleffekt wurde erneut verbessert
Jul 24, 2024 pm 08:34 PM
Am 24. Juli gab das Kuaishou-Videogenerations-Großmodell Keling AI bekannt, dass das Basismodell erneut aktualisiert wurde und vollständig für interne Tests geöffnet ist. Kuaishou sagte, dass es von nun an auf der Grundlage vollständig offener interner Tests auch offiziell ein Mitgliedschaftssystem für verschiedene Kategorien einführen wird, um mehr Benutzern die Nutzung von Keling AI zu ermöglichen und den unterschiedlichen Nutzungsbedürfnissen von Erstellern besser gerecht zu werden Mitglieder stellen entsprechende exklusive funktionale Dienste bereit. Gleichzeitig wurde auch das Basismodell von Keling AI erneut aktualisiert, um das Benutzererlebnis weiter zu verbessern. Der Grundmodelleffekt wurde verbessert, um das Benutzererlebnis weiter zu verbessern. Seit seiner Veröffentlichung vor mehr als einem Monat wurde Keling AI mehrfach aktualisiert und iteriert. Mit der Einführung dieses Mitgliedschaftssystems wurde der Grundmodelleffekt einmal verbessert erneut einer Wandlung unterzogen. Erstens wurden die Bildqualität und die visuellen Effekte durch das verbesserte Basismodell deutlich verbessert
 Warum wusste ich beim Erlernen der Liniengenerierung nicht: Es gibt eine Äquivalenzbeziehung zwischen Matrizen und Graphen?
Aug 19, 2024 pm 04:52 PM
Warum wusste ich beim Erlernen der Liniengenerierung nicht: Es gibt eine Äquivalenzbeziehung zwischen Matrizen und Graphen?
Aug 19, 2024 pm 04:52 PM
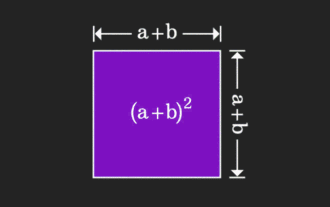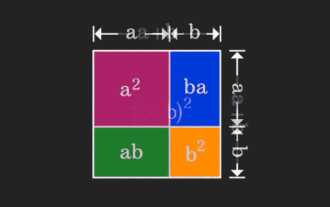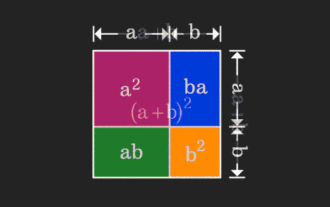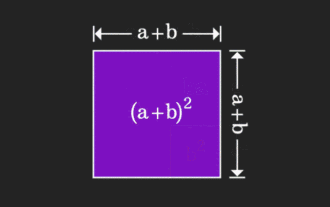
Die Matrix ist schwer zu verstehen, kann aber anders ausfallen, wenn man sie aus einer anderen Perspektive betrachtet. Wenn wir Mathematik lernen, sind wir oft frustriert über die Schwierigkeit und Abstraktheit des gelernten Wissens, aber manchmal können wir einfach durch einen Perspektivenwechsel eine einfache und intuitive Lösung für das Problem finden. Als wir zum Beispiel als Kinder die Formel für die Quadratsumme (a+b)² lernten, verstanden wir vielleicht nicht, warum sie gleich a²+2ab+b² ist. Wir wussten nur, dass sie so geschrieben wurde das Buch und der Lehrer forderten uns auf, uns das so zu merken; bis wir eines Tages dieses animierte Bild sahen: Mir wurde plötzlich klar, dass wir es aus einer geometrischen Perspektive verstehen können! Jetzt tritt dieses Gefühl der Erleuchtung erneut auf: Eine nichtnegative Matrix kann äquivalent in den entsprechenden gerichteten Graphen umgewandelt werden! Wie in der folgenden Abbildung gezeigt, kann die 3 × 3-Matrix auf der linken Seite tatsächlich vorhanden sein
 700.000 Menschen strömten herbei, um es zu erleben! Der neue König der Videogeneration „Keling AI' wurde erneut verbessert
Jul 20, 2024 am 05:09 AM
700.000 Menschen strömten herbei, um es zu erleben! Der neue König der Videogeneration „Keling AI' wurde erneut verbessert
Jul 20, 2024 am 05:09 AM
Ist es möglich, dass die Ära der KI-generierten Kurzdramen wirklich kommt? Die kürzlich von verschiedenen KIs zur Videogenerierung veröffentlichten Demos sind umwerfend. Vom Spielen mit Memes und Längenrätseln bis hin zur Beachtung echter physikalischer Logik ist es schwer, zwischen der endlosen Kreativität der künstlichen Intelligenz zu unterscheiden, und alle müssen mit Sora konkurrieren. Zu diesem Zeitpunkt machte jemand plötzlich einen Schritt weiter und schuf eine Performance auf „Filmniveau“: von echten Licht- und Schatteneffekten: Quelle: https://x.com/i/status/1806383419661730197 bis hin zu reicher Fantasie, alle Elemente Sind abgeschlossen, Es ist machbar: Unerwarteterweise ist es in den Augen der KI tatsächlich Batman, der den Joker unfähig machen kann, die Nerven zu behalten. Quelle: https://x.com/blizaine/status/18
 Entwicklertool! XREAL Air 2 ULTRA kommt zum Verkauf, ein immersives Erlebnis der KI-Entwicklung
Aug 07, 2024 pm 06:40 PM
Entwicklertool! XREAL Air 2 ULTRA kommt zum Verkauf, ein immersives Erlebnis der KI-Entwicklung
Aug 07, 2024 pm 06:40 PM
Am 31. Juli um 14:00 Uhr (Pekinger Zeit) wurde das neueste Mitglied der XREAL-Serie von AR-Brillen, XREAL Air2 Ultra, offiziell in China eingeführt. Es ist derzeit auf JD.com, Tmall, Douyin und anderen Plattformen verfügbar ein anfänglicher Preis von 3.999 Yuan. Diese AR-Brille ist ein Flaggschiffprodukt, das sich hauptsächlich an die Entwicklergemeinschaft richtet. Ziel ist es, die Schwelle für Entwickler zum Einstieg in die räumliche Datenverarbeitung zu senken, Innovationen im Bereich der räumlichen Datenverarbeitung zu fördern und ein florierenderes AR-Ökosystem zu schaffen. Befähigung von Entwicklern mit sechs Kernfunktionen Als zweite 6DoF-Brille (Six Degrees of Freedom, sechs Freiheitsgrade) von XREAL ist die XREAL Air2 Ultra derzeit die einzige in der Branche, die zwei Sensoren zur Umgebungserkennung (SLAM-Kamera) verwendet.
