

Was ist „Dolmetschermodus“?
Öffnen Sie zunächst „GOF“ und schauen Sie sich die Definition an:
Definieren Sie bei einer gegebenen Sprache eine Darstellung ihrer Grammatik und einen Interpreter, der diese Darstellung verwendet, um Sätze in der Sprache zu interpretieren.
Bevor ich anfange, muss ich noch ein paar Konzepte bekannt machen:
Abstrakter Syntaxbaum:
Der Interpretermodus erklärt nicht, wie man eine abstrakte Syntax erstellt Baum. Es beinhaltet keine Syntaxanalyse. Der abstrakte Syntaxbaum kann durch einen tabellengesteuerten Parser vervollständigt oder durch einen handgeschriebenen (normalerweise rekursiven) Parser erstellt oder direkt vom Client bereitgestellt werden.
Parser:
bezieht sich auf ein Programm, das Ausdrücke analysiert, die Client-Aufrufanforderungen beschreiben, um einen abstrakten Syntaxbaum zu bilden.
Interpreter:
bezieht sich auf das Programm, das den abstrakten Syntaxbaum interpretiert und die jedem Knoten entsprechende Funktion ausführt.
Um den Interpretermodus nutzen zu können, ist eine wichtige Voraussetzung die Definition eines Satzes grammatikalischer Regeln, auch Grammatik genannt. Unabhängig davon, ob die Regeln dieser Grammatik einfach oder komplex sind, müssen diese Regeln vorhanden sein, da der Interpretermodus entsprechende Funktionen gemäß diesen Regeln analysiert und ausführt.
Werfen wir zunächst einen Blick auf das Strukturdiagramm und die Beschreibung des Interpretermodus:
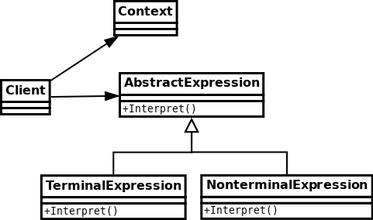
AbstractExpression: Definieren Sie die Schnittstelle des Dolmetschers und vereinbaren Sie den Dolmetscherbetrieb des Dolmetschers.
TerminalExpression: Terminal-Interpreter wird verwendet, um Operationen im Zusammenhang mit Terminalsymbolen in Grammatikregeln zu implementieren. Er enthält keine anderen Interpreter mehr. Wenn Sie den Kombinationsmodus zum Erstellen eines abstrakten Syntaxbaums verwenden, ist dies der Fall Für Blattobjekte im zusammengesetzten Modus kann es mehrere Terminalinterpreter geben.
Nichtterminaler Ausdruck: Nichtterminaler Interpreter, der zum Implementieren von Operationen im Zusammenhang mit nichtterminalen Symbolen in Grammatikregeln verwendet wird. Normalerweise entspricht ein Interpreter einer Grammatikregel und kann andere Interpreter einschließen Abstrakter Syntaxbaum, der dem Kombinationsobjekt im Kombinationsmuster entspricht. Es kann mehrere nichtterminale Interpreter geben.
Kontext: Kontext enthält normalerweise Daten oder öffentliche Funktionen, die von jedem Interpreter benötigt werden.
Client: Der Client bezieht sich auf den Client, der den Interpreter verwendet. Normalerweise werden Ausdrücke, die gemäß der Grammatik der Sprache erstellt wurden, mithilfe des Interpreterobjekts in abstrakte Syntaxbäume umgewandelt und dann als Explain bezeichnet Betrieb.
Nachfolgend verwenden wir ein XML-Beispiel, um den Interpretermodus zu verstehen:
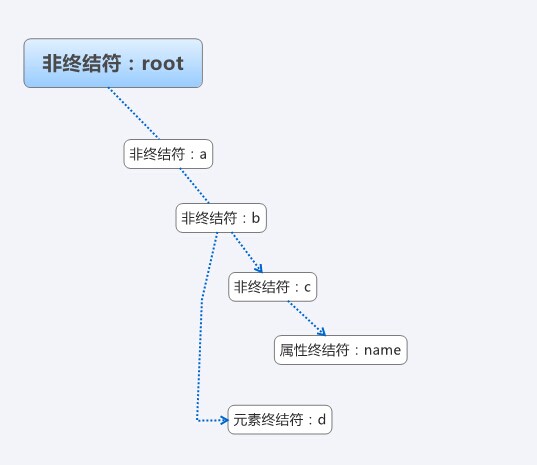
Zunächst müssen wir eine einfache Grammatik für Ausdrücke entwerfen. Aus Gründen der Universalität verwenden wir root, um das Wurzelelement, abc usw. darzustellen. Um Elemente darzustellen, ein einfaches XML Wie folgt:
Die Grammatik des vereinbarten Ausdrucks lautet wie folgt:
1. Ermitteln Sie den Wert eines einzelnen Elements: Beginnen Sie mit dem Wurzelelement und gehen Sie zu dem Element, in dem Sie den Wert erhalten möchten durch „/“ getrennt, vor dem Stammelement nicht „/“ hinzufügen. Beispielsweise bedeutet der Ausdruck „root/a/b/c“, den Wert der Elemente a, b und c unter dem Wurzelelement zu erhalten.
2. Holen Sie sich den Wert des Attributs eines einzelnen Elements: Natürlich gibt es mehrere. Das Attribut, um den Wert zu erhalten, muss das Attribut des letzten Elements des Ausdrucks sein Fügen Sie dann den Namen des Attributs hinzu. Der Ausdruck „root/a/b/c.name“ bedeutet beispielsweise, den Wert des Namensattributs der Elemente a, Element b und Element c unter dem Stammelement abzurufen.
3. Rufen Sie den Wert desselben Elementnamens ab. Natürlich gibt es mehrere. Das Element, um den Wert zu erhalten, muss das letzte Element des Ausdrucks sein. Fügen Sie nach dem letzten Element „$“ hinzu. Beispielsweise bedeutet der Ausdruck „root/a/b/d$“, die Wertemenge mehrerer d-Elemente unter dem Wurzelelement, unter dem a-Element und unter dem b-Element zu erhalten.
4. Rufen Sie den Wert des Attributs mit demselben Elementnamen ab. Natürlich gibt es mehrere: Das Element, um den Attributwert zu erhalten, muss das letzte Element des Ausdrucks sein. Fügen Sie nach dem letzten Element „$“ hinzu. Beispielsweise bedeutet der Ausdruck „root/a/b/d$.id$“, den Satz von ID-Attributwerten mehrerer d-Elemente unter dem Wurzelelement, unter dem a-Element und unter dem b-Element zu erhalten.
Die obige XML, der entsprechende abstrakte Syntaxbaum, die mögliche Struktur ist wie in der Abbildung dargestellt:
Werfen wir einen Blick auf den spezifischen Code:
1. Kontext definieren:
Context.prototype = {
// Kontext neu initialisieren
reInit: function () {
this.preEle = null;
},
/**
* Von verschiedenen Ausdrücken häufig verwendete Methoden
* Rufen Sie das aktuelle Element basierend auf dem Namen des übergeordneten Elements und dem aktuellen Element ab
* @param {Element} pEle [Übergeordnetes Element]
* @param {String} eleName [Aktueller Elementname]
* @return {Element|null} [Aktuelles Element gefunden]
*/
getNowEle: function (pEle, eleName) {
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i < len; i ) {
if ((nowEle = tempNodeList[i]).nodeType === 1)
if (nowEle .nodeName === eleName)
return null;
getPreEle: function () {
return this.preEle;
},
setPreEle: function (preEle) {
this.preEle = preEle;
},
getDocument: function () {
return this.document;
}
};
Das Folgende ist der Code des Interpreters:
Code kopieren
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i < len; i++) {
if (ele === this.eles[i])
this.eles.splice(i--, 1);
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEle = context.getPreEle();
if (!pEle) {
// 说明现在获取的是根元素
context.setPreEle(context.getDocument().documentElement);
} else {
// 根据父级元素和要查找的元素的名称来获取当前的元素
var nowEle = context.getNowEle(pEle, this.eleName);
// 把当前获取的元素放到上下文中
context.setPreEle(nowEle);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i < len; i++) {
ss = this.eles[i].interpret(context);
}
// 返回最后一个解释器的解释结果,一般最后一个解释器就是终结符解释器了
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEle = context.getPreEle();
var ele = null;
if (!pEle) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEle(pEle, this.eleName);
context.setPreEle(ele);
}
Den Wert des Elements ermitteln
/**
* Der dem Attribut entsprechende Interpreter als Terminalsymbol
* @param {String} propName [Name des Attributs]
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// Den Wert des letzten Elementattributs direkt abrufen
}
};
Sehen wir uns zunächst an, wie man den Interpreter verwendet, um den Wert eines einzelnen Elements zu ermitteln:
Code kopieren
console.log('Der Wert von c ist = ' root.interpret(c));
}();
Ausgabe: Der Wert von c ist = 12345
Code kopieren
// Kombination
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(cEle);
cEle.addEle(prop);
console.log('Der Attributnamenswert von c ist = ' root.interpret(c));
// Wenn Sie denselben Kontext für kontinuierliches Parsen verwenden möchten, müssen Sie das Kontextobjekt neu initialisieren
// Wenn Sie beispielsweise den Wert des Attributnamens kontinuierlich neu abrufen möchten, von Natürlich können Sie die Elemente neu kombinieren
/ / Neu analysieren, solange Sie denselben Kontext verwenden, müssen Sie das Kontextobjekt neu initialisieren
c.reInit();
} ();
输出: c的属性name值是 = testC 重新获取c的属性name值是 = testC
讲解:
1.解释器模式功能:
解释器模式使用解释器对象来表示和处理相应的语法规则,一般一个解释器处理一条语法规则。理论上来说,只要能用解释器对象把符合语法的表达式表示出来,而且能够构成抽象的语法树,就可以使用解释器模式来处理。
2.语法规则和解释器
语法规则和解释器之间是有对应关系的,一般一个解释器处理一条语法规则,但是反过来并不成立,一条语法规则是可以有多种解释和处理的,也就是一条语法规则可以对应多个解释器。
3.上下文的公用性
上下文在解释器模式中起着非常重要的作用。由于上下文会被传递到所有的解释器中。因此可以在上下文中存储和访问解释器的状态,比如,前面的解释器可以存储一些数据在上下文中,后面的解释器就可以获取这些值。
另外还可以通过上下文传递一些在解释器外部,但是解释器需要的数据,也可以是一些全局的,公共的数据。
上下文还有一个功能,就是可以提供所有解释器对象的公共功能,类似于对象组合,而不是使用继承来获取公共功能,在每个解释器对象中都可以调用
4.谁来构建抽象语法树
在前面的示例中,是自己在客户端手工构建抽象语法树,是很麻烦的,但是在解释器模式中,并没有涉及这部分功能,只是负责对构建好的抽象语法树进行解释处理。后面会介绍可以提供解析器来实现把表达式转换成为抽象语法树。
还有一个问题,就是一条语法规则是可以对应多个解释器对象的,也就是说同一个元素,是可以转换成多个解释器对象的,这也就意味着同样一个表达式,是可以构成不用的抽象语法树的,这也造成构建抽象语法树变得很困难,而且工作量非常大。
5.谁负责解释操作
只要定义好了抽象语法树,肯定是解释器来负责解释执行。虽然有不同的语法规则,但是解释器不负责选择究竟用哪个解释器对象来解释执行语法规则,选择解释器的功能在构建抽象语法树的时候就完成了。
6.解释器模式的调用顺序
1)创建上下文对象
2)创建多个解释器对象,组合抽象语法树
3)调用解释器对象的解释操作
3.1)通过上下文来存储和访问解释器的状态。
对于非终结符解释器对象,递归调用它所包含的子解释器对象。
解释器模式的本质:*分离实现,解释执行*
解释器模使用一个解释器对象处理一个语法规则的方式,把复杂的功能分离开;然后选择需要被执行的功能,并把这些功能组合成为需要被解释执行的抽象语法树;再按照抽象语法树来解释执行,实现相应的功能。
从表面上看,解释器模式关注的是我们平时不太用到的自定义语法的处理;但从实质上看,解释器模式的思想然后是分离,封装,简化,和很多模式是一样的。
比如,可以使用解释器模式模拟状态模式的功能。如果把解释器模式要处理的语法简化到只有一个状态标记,把解释器看成是对状态的处理对象,对同一个表示状态的语法,可以有很多不用的解释器,也就是有很多不同的处理状态的对象,然后再创建抽象语法树的时候,简化成根据状态的标记来创建相应的解释器,不用再构建树了。
同理,解释器模式可以模拟实现策略模式的功能,装饰器模式的功能等,尤其是模拟装饰器模式的功能,构建抽象语法树的过程,自然就对应成为组合装饰器的过程。
解释器模式执行速度通常不快(大多数时候非常慢),而且错误调试比较困难(附注:虽然调试比较困难,但事实上它降低了错误的发生可能性),但它的优势是显而易见的,它能有效控制模块之间接口的复杂性,对于那种执行频率不高但代码频率足够高,且多样性很强的功能,解释器是非常适合的模式。此外解释器还有一个不太为人所注意的优势,就是它可以方便地跨语言和跨平台。
解释器模式的优缺点:
优点:
1.易于实现语法
在解释器模式中,一条语法规则用一个解释器对象来解释执行。对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就可以了,其他的都不用管。 2.易于扩展新的语法
Gerade aufgrund der Art und Weise, wie ein Interpreterobjekt für eine Grammatikregel verantwortlich ist, ist es sehr einfach, neue Grammatiken zu erweitern. Um die neue Syntax zu erweitern, müssen Sie lediglich das entsprechende Interpreterobjekt erstellen und dieses neue Interpreterobjekt beim Erstellen des abstrakten Syntaxbaums verwenden.
Nachteile:
Nicht für komplexe Syntax geeignet
Wenn die Grammatik besonders komplex ist, ist der Aufbau des für den Interpretermodus erforderlichen abstrakten Syntaxbaums sehr mühsam und es müssen möglicherweise mehrere abstrakte Syntaxbäume erstellt werden. Daher ist der Interpretermodus nicht für komplexe Grammatiken geeignet. Möglicherweise ist es besser, einen Parser oder Compiler-Generator zu verwenden.
Wann verwenden?
Wenn eine Sprache interpretiert und ausgeführt werden muss und die Sätze in der Sprache als abstrakter Syntaxbaum dargestellt werden können, können Sie die Verwendung des Interpretermodus in Betracht ziehen.
Bei der Verwendung des Interpretermodus müssen zwei weitere Merkmale berücksichtigt werden. Zum einen ist die Grammatik zu einfach und für die Verwendung des Interpretermodus nicht geeignet Anforderungen sind nicht sehr hoch; hoch, nicht für den Einsatz geeignet.
Im vorherigen Artikel wurde erläutert, wie der Wert eines einzelnen Elements und der Wert eines einzelnen Elementattributs ermittelt werden. Schauen wir uns an, wie der Wert mehrerer Elemente sowie die Werte der Namen ermittelt werden Mehrere Elemente sowie die vorherigen Tests haben auch den folgenden einfachen Parser implementiert, um Ausdrücke, die der zuvor definierten Grammatik entsprechen, in den abstrakten Syntaxbaum des zuvor implementierten Interpreters zu konvertieren: Ich habe den Code gepostet direkt:
Context.prototype = {
// 重新初始化上下文
reInit: function () {
this.preEles = [];
},
/**
* 各个Expression公共使用的方法
* 根据父元素和当前元素的名称来获取当前元素
* @param {Element} pEle [父元素]
* @param {String} eleName [当前元素名称]
* @return {Element|null} [找到的当前元素]
*/
getNowEles: function (pEle, eleName) {
var elements = [];
var tempNodeList = pEle.childNodes;
var nowEle;
for (var i = 0, len = tempNodeList.length; i < len; i++) {
if ((nowEle = tempNodeList[i]).nodeType === 1) {
if (nowEle.nodeName === eleName) {
elements.push(nowEle);
}
}
}
return elements;
},
getPreEles: function () {
return this.preEles;
},
setPreEles: function (nowEles) {
this.preEles = nowEles;
},
getDocument: function () {
return this.document;
}
};
// 工具对象
// 解析xml,获取相应的Document对象
var XmlUtil = {
getRoot: function (filePathName) {
var parser = new DOMParser();
var xmldom = parser.parseFromString('
return xmldom;
}
};
/**
* 元素作为非终结符对应的解释器,解释并执行中间元素
* @param {String} eleName [元素的名称]
*/
function ElementExpression(eleName) {
this.eles = [];
this.eleName = eleName;
}
ElementExpression.prototype = {
addEle: function (eleName) {
this.eles.push(eleName);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i < len; i++) {
if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
},
interpret: function (context) {
// 先取出上下文中的当前元素作为父级元素
// 查找到当前元素名称所对应的xml元素,并设置回到上下文中
var pEles = context.getPreEles();
var ele = null;
var nowEles = [];
if (!pEles.length) {
// 说明现在获取的是根元素
ele = context.getDocument().documentElement;
pEles.push(ele);
context.setPreEles(pEles);
} else {
var tempEle;
for (var i = 0, len = pEles.length; i < len; i++) {
tempEle = pEles[i];
nowEles = nowEles.concat(context.getNowEles(tempEle, this.eleName));
// 找到一个就停止
if (nowEles.length) break;
}
context.setPreEles([nowEles[0]]);
}
var ss;
// 循环调用子元素的interpret方法
for (var i = 0, len = this.eles.length; i < len; i++) {
ss = this.eles[i].interpret(context);
}
return ss;
}
};
/**
* 元素作为终结符对应的解释器
* @param {String} name [元素的名称]
*/
function ElementTerminalExpression(name) {
this.eleName = name;
}
ElementTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var ele = null;
if (!pEles.length) {
ele = context.getDocument().documentElement;
} else {
ele = context.getNowEles(pEles[0], this.eleName)[0];
}
// 获取元素的值
return ele.firstChild.nodeValue;
}
};
/**
* 属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertyTerminalExpression(propName) {
this.propName = propName;
}
PropertyTerminalExpression.prototype = {
interpret: function (context) {
// 直接获取最后的元素属性的值
return context.getPreEles()[0].getAttribute(this.propName);
}
};
/**
* 多个属性作为终结符对应的解释器
* @param {String} propName [属性的名称]
*/
function PropertysTerminalExpression(propName) {
this.propName = propName;
}
PropertysTerminalExpression.prototype = {
interpret: function (context) {
var eles = context.getPreEles();
var ss = [];
for (var i = 0, len = eles.length; i < len; i++) {
ss.push(eles[i].getAttribute(this.propName));
}
return ss;
}
};
/**
* 以多个元素作为终结符的解释处理对象
* @param {[type]} name [description]
*/
function ElementsTerminalExpression(name) {
this.eleName = name;
}
ElementsTerminalExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i < len; i++) {
nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
var ss = [];
for (i = 0, len = nowEles.length; i < len; i++) {
ss.push(nowEles[i].firstChild.nodeValue);
}
return ss;
}
};
/**
* 多个元素作为非终结符的解释处理对象
*/
function ElementsExpression(name) {
this.eleName = name;
this.eles = [];
}
ElementsExpression.prototype = {
interpret: function (context) {
var pEles = context.getPreEles();
var nowEles = [];
for (var i = 0, len = pEles.length; i < len; i++) {
nowEles = nowEles.concat(context.getNowEles(pEles[i], this.eleName));
}
context.setPreEles(nowEles);
var ss;
for (i = 0, len = this.eles.length; i < len; i++) {
ss = this.eles[i].interpret(context);
}
return ss;
},
addEle: function (ele) {
this.eles.push(ele);
return true;
},
removeEle: function (ele) {
for (var i = 0, len = this.eles.length; i < len; i++) {
if (ele === this.eles[i]) {
this.eles.splice(i--, 1);
}
}
return true;
}
};
void function () {
// "root/a/b/d$"
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsTerminalExpression('d');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i < len; i++) {
console.log('d的值是 = ' + ss[i]);
}
}();
void function () {
// a/b/d$.id$
var c = new Context('Interpreter.xml');
var root = new ElementExpression('root');
var aEle = new ElementExpression('a');
var bEle = new ElementExpression('b');
var dEle = new ElementsExpression('d');
var prop = new PropertysTerminalExpression('id');
root.addEle(aEle);
aEle.addEle(bEle);
bEle.addEle(dEle);
dEle.addEle(prop);
var ss = root.interpret(c);
for (var i = 0, len = ss.length; i < len; i++) {
console.log('d的属性id的值是 = ' + ss[i]);
}
}();
// 解析器
/**
* 解析器的实现思路
* 1.把客户端传递来的表达式进行分解,分解成为一个一个的元素,并用一个对应的解析模型来封装这个元素的一些信息。
* 2.根据每个元素的信息,转化成相对应的解析器对象。
* 3.按照先后顺序,把这些解析器对象组合起来,就得到抽象语法树了。
*
* 为什么不把1和2合并,直接分解出一个元素就转换成相应的解析器对象?
* 1.功能分离,不要让一个方法的功能过于复杂。
* 2.为了今后的修改和扩展,现在语法简单,所以转换成解析器对象需要考虑的东西少,直接转换也不难,但要是语法复杂了,直接转换就很杂乱了。
*/
/**
* 用来封装每一个解析出来的元素对应的属性
*/
function ParserModel() {
// 是否单个值
this.singleValue;
// 是否属性,不是属性就是元素
this.propertyValue;
// 是否终结符
this.end;
}
ParserModel.prototype = {
isEnd: function () {
return this.end;
},
setEnd: function (end) {
this.end = end;
},
isSingleValue: function () {
return this.singleValue;
},
setSingleValue: function (oneValue) {
this.singleValue = oneValue;
},
isPropertyValue: function () {
return this.propertyValue;
},
setPropertyValue: function (propertyValue) {
this.propertyValue = propertyValue;
}
};
var Parser = function () {
var BACKLASH = '/';
var DOT = '.';
var DOLLAR = '$';
// 按照分解的先后记录需要解析的元素的名称
var listEle = null;
// 开始实现第一步-------------------------------------
/**
* 传入一个字符串表达式,通过解析,组合成为一个抽象语法树
* @param {String} expr [描述要取值的字符串表达式]
* @return {Object} [对应的抽象语法树]
*/
function parseMapPath(expr) {
// 先按照“/”分割字符串
var tokenizer = expr.split(BACKLASH);
// 用来存放分解出来的值的表
var mapPath = {};
var onePath, eleName, propName;
var dotIndex = -1;
for (var i = 0, len = tokenizer.length; i < len; i++) {
onePath = tokenizer[i];
if (tokenizer[i + 1]) {
// 还有下一个值,说明这不是最后一个元素
// 按照现在的语法,属性必然在最后,因此也不是属性
setParsePath(false, onePath, false, mapPath);
} else {
// 说明到最后了
dotIndex = onePath.indexOf(DOT);
if (dotIndex >= 0) {
// 说明是要获取属性的值,那就按照“.”来分割
// 前面的就是元素名称,后面的是属性的名字
eleName = onePath.substring(0, dotIndex);
propName = onePath.substring(dotIndex + 1);
// 设置属性前面的那个元素,自然不是最后一个,也不是属性
setParsePath(false, eleName, false, mapPath);
// 设置属性,按照现在的语法定义,属性只能是最后一个
setParsePath(true, propName, true, mapPath);
} else {
// 说明是取元素的值,而且是最后一个元素的值
setParsePath(true, onePath, false, mapPath);
}
break;
}
}
return mapPath;
}
/** * /
Function setparsepath (end, ele, propertyValue, mappath) {
var pm = new parseermodel ();
pm.seitend (end); il y a un symbole "$", cela signifie que ce n'est pas une valeur
/ / Supprimer "$"
ele = ele.replace(DOLLAR, '');
mapPath[ele] = pm;
listEle.push(ele);
}
// Commencez à réaliser la deuxième étape --------------------------------------- -
 Welches System ist QAD?
Welches System ist QAD?
 So beheben Sie einen DNS-Fehler
So beheben Sie einen DNS-Fehler
 Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
Wie man unter Linux mit verstümmelten chinesischen Schriftzeichen umgeht
 Was bedeutet Bildrate?
Was bedeutet Bildrate?
 Der Unterschied zwischen Zugangs- und Trunk-Ports
Der Unterschied zwischen Zugangs- und Trunk-Ports
 So verbinden Sie Breitband mit einem Server
So verbinden Sie Breitband mit einem Server
 So öffnen Sie eine Statusdatei
So öffnen Sie eine Statusdatei
 Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?
Können Douyin-Funken wieder entzündet werden, wenn sie länger als drei Tage ausgeschaltet waren?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



