

ApacheHive一点一点进步(1) 简单介绍

Hive是一个 hadoop 的数据仓库,便于对 hadoop 中存储的大数据进行数据汇总,点对点查询,以及分析。 Hive提供了一套管理机制用于管理HDFS中的数据及一套类型于sql的查询语言HiveQL。 同时当HiveQL无法满足逻辑的时候,这种语言支持传统的MR程序,以插件的形
Hive是一个hadoop的数据仓库,便于对hadoop中存储的大数据进行数据汇总,点对点查询,以及分析。
Hive提供了一套管理机制用于管理HDFS中的数据及一套类型于sql的查询语言HiveQL。
同时当HiveQL无法满足逻辑的时候,这种语言支持传统的MR程序,以插件的形式集成到Hive的MR中。
Hive是apache基金会下的一个开源志愿者项目。以前他是一个Hadoop的子项目。但是现在他已经升级为一个顶级项目。
安装
Requirements Java1.6,hadoop0.20.xx选择一个稳定版进行安装 http://hive.apache.org/releases.html解压缩tarball。$ tar -xzvf hive-x.y.z.tar.gz$ cd hive-x.y.z $ export HIVE_HOME={{pwd}}配置 Hive默认的配置是<install-dir>/conf/hive-DEFAULT.xml如果需要变更配置,可以重新配置于 <install-dir>/conf/hive-site.xmlLog4j配置储存于<install-dir>/conf/hive-log4j.propertiesHive的配置是基于对hadoop的一个覆盖,意思是hadoop的配置变量是缺省继承的。Hive变量的配置方法:1.修改hive-site.xml文件2.通过cli客户端使用SET命令进行3.通过授权hive使用如下语法$ bin/hive -hiveconf x1=y1 -hiveconf x2=y2</install-dir></install-dir></install-dir>
运行时配置
Hive的查询是通过MR查询执行的,因此,这样的查询行为都是被hadoop的配置变量进行控制的。hive> SET mapred.job.tracker=myhost.mycompany.com:50030;hive> SET -v;上面的最后一条语句可以显示当前的所有配置。如果不加-v参数,则只显示与基础的hadoop配置不同的配置。
Local模式
hive> SET mapred.job.tracker=LOCAL;hive> SET hive.EXEC.mode.LOCAL.auto=FALSE;$ export PATH=$HIVE_HOME/bin:$PATH
修改Log路径
bin/hive -hiveconf hive.root.logger=INFO,consolebin/hive -hiveconf hive.root.logger=INFO,DRFAMETASTOREmodel描述文件位置:src/contrib/hive/metastore/src/modelDML Operations默认的文件分割呼号是ctr+a文件上传的默认目录是: hive-DEFAULT.xml 中的hive.metastore.warehouse.dir上传文件的两种方式:本地文件LOAD DATA LOCAL INPATH './examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');远程文件 LOAD DATA INPATH '/user/myname/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');上面的命令会发生文件和目录的转移。将结果插入到HDFS INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='2008-08-15';将结果插入到本地文件INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
只定义mapper任务:py
import sysimport datetimeFOR line IN sys.stdin: line = line.strip() userid, movieid, rating, unixtime = line.split('\t') weekday = datetime.datetime.fromtimestamp(FLOAT(unixtime)).isoweekday() print '\t'.JOIN([userid, movieid, rating, str(weekday)])CREATE TABLE u_data_new ( userid INT, movieid INT, rating INT, weekday INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t';ADD FILE weekday_mapper.py;INSERT OVERWRITE TABLE u_data_newSELECT TRANSFORM (userid, movieid, rating, unixtime) USING 'python weekday_mapper.py' AS (userid, movieid, rating, weekday)FROM u_data;SELECT weekday, COUNT(*)FROM u_data_newGROUP BY weekday;原文地址:ApacheHive一点一点进步(1) 简单介绍, 感谢原作者分享。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der einfachste Weg, die Seriennummer der Festplatte abzufragen
Feb 26, 2024 pm 02:24 PM
Der einfachste Weg, die Seriennummer der Festplatte abzufragen
Feb 26, 2024 pm 02:24 PM
Die Seriennummer der Festplatte ist eine wichtige Kennung der Festplatte und dient in der Regel zur eindeutigen Identifizierung der Festplatte und zur Identifizierung der Hardware. In einigen Fällen müssen wir möglicherweise die Seriennummer der Festplatte abfragen, beispielsweise bei der Installation eines Betriebssystems, der Suche nach dem richtigen Gerätetreiber oder der Durchführung von Festplattenreparaturen. In diesem Artikel werden einige einfache Methoden vorgestellt, mit denen Sie die Seriennummer der Festplatte überprüfen können. Methode 1: Verwenden Sie die Windows-Eingabeaufforderung, um die Eingabeaufforderung zu öffnen. Drücken Sie im Windows-System die Tasten Win+R, geben Sie „cmd“ ein und drücken Sie die Eingabetaste, um den Befehl zu öffnen
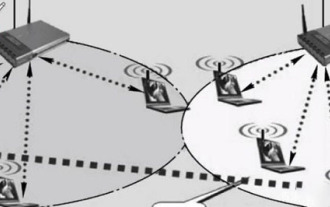 Detaillierte Einführung in Wapi
Jan 07, 2024 pm 09:14 PM
Detaillierte Einführung in Wapi
Jan 07, 2024 pm 09:14 PM
Benutzer haben möglicherweise den Begriff Wapi bei der Nutzung des Internets gesehen, aber einige Leute wissen definitiv nicht, was Wapi ist. Im Folgenden finden Sie eine detaillierte Einführung, um denjenigen, die es nicht wissen, das Verständnis zu erleichtern. Was ist Wapi: Antwort: Wapi ist die Infrastruktur für WLAN-Authentifizierung und Vertraulichkeit. Dies entspricht Funktionen wie Infrarot und Bluetooth, die im Allgemeinen in der Nähe von Orten wie Bürogebäuden verfügbar sind. Im Grunde sind sie Eigentum einer kleinen Abteilung, sodass der Umfang dieser Funktion nur wenige Kilometer beträgt. Verwandte Einführung in Wapi: 1. Wapi ist ein Übertragungsprotokoll im WLAN. 2. Diese Technologie kann die Probleme der Schmalbandkommunikation vermeiden und eine bessere Kommunikation ermöglichen. 3. Zur Übertragung des Signals ist nur ein Code erforderlich.
 Detaillierte Erklärung, ob Win11 das PUBG-Spiel ausführen kann
Jan 06, 2024 pm 07:17 PM
Detaillierte Erklärung, ob Win11 das PUBG-Spiel ausführen kann
Jan 06, 2024 pm 07:17 PM
Pubg, auch bekannt als PlayerUnknown's Battlegrounds, ist ein sehr klassisches Battle-Royale-Shooter-Spiel, das seit seiner Popularität im Jahr 2016 viele Spieler angezogen hat. Nach der kürzlichen Einführung des Win11-Systems möchten viele Spieler es auf Win11 spielen. Folgen wir dem Editor, um zu sehen, ob Win11 Pubg spielen kann. Kann Win11 Pubg spielen? Antwort: Win11 kann Pubg spielen. 1. Zu Beginn von Win11 wurden viele Spieler von Pubg ausgeschlossen, da Win11 TPM aktivieren musste. 2. Basierend auf dem Feedback der Spieler hat Blue Hole dieses Problem jedoch gelöst, und jetzt können Sie Pubg unter Win11 normal spielen. 3. Wenn Sie eine Kneipe treffen
 Einführung in Python-Funktionen: Einführung und Beispiele der Exec-Funktion
Nov 03, 2023 pm 02:09 PM
Einführung in Python-Funktionen: Einführung und Beispiele der Exec-Funktion
Nov 03, 2023 pm 02:09 PM
Einführung in Python-Funktionen: Einführung und Beispiele der Exec-Funktion Einführung: In Python ist Exec eine integrierte Funktion, die zum Ausführen von Python-Code verwendet wird, der in einer Zeichenfolge oder Datei gespeichert ist. Die exec-Funktion bietet eine Möglichkeit, Code dynamisch auszuführen, sodass das Programm während der Laufzeit nach Bedarf Code generieren, ändern und ausführen kann. In diesem Artikel wird die Verwendung der Exec-Funktion vorgestellt und einige praktische Codebeispiele gegeben. So verwenden Sie die Exec-Funktion: Die grundlegende Syntax der Exec-Funktion lautet wie folgt: exec
 Detaillierte Einführung, ob der i5-Prozessor Win11 installieren kann
Dec 27, 2023 pm 05:03 PM
Detaillierte Einführung, ob der i5-Prozessor Win11 installieren kann
Dec 27, 2023 pm 05:03 PM
i5 ist eine Prozessorserie von Intel. Es gibt verschiedene Versionen des i5 der 11. Generation, und jede Generation hat eine unterschiedliche Leistung. Ob der i5-Prozessor win11 installieren kann, hängt daher davon ab, um welche Generation des Prozessors es sich handelt. Folgen wir dem Editor, um mehr darüber zu erfahren. Kann der i5-Prozessor mit Win11 installiert werden: Antwort: Der i5-Prozessor kann mit Win11 installiert werden. 1. Die Prozessoren der achten Generation und nachfolgender i51, der achten Generation und nachfolgender i5-Prozessoren können die Mindestkonfigurationsanforderungen von Microsoft erfüllen. 2. Daher müssen wir nur die Microsoft-Website aufrufen und einen „Win11-Installationsassistenten“ herunterladen. 3. Nachdem der Download abgeschlossen ist, führen Sie den Installationsassistenten aus und befolgen Sie die Anweisungen zur Installation von Win11. 2. i51 vor der achten Generation und nach der achten Generation
 Wie schreibe ich einen einfachen Generator für Schülerleistungsberichte mit Java?
Nov 03, 2023 pm 02:57 PM
Wie schreibe ich einen einfachen Generator für Schülerleistungsberichte mit Java?
Nov 03, 2023 pm 02:57 PM
Wie schreibe ich einen einfachen Generator für Schülerleistungsberichte mit Java? Der Student Performance Report Generator ist ein Tool, das Lehrern und Erziehern dabei hilft, schnell Berichte über die Schülerleistung zu erstellen. In diesem Artikel wird erläutert, wie Sie mit Java einen einfachen Generator für Schülerleistungsberichte schreiben. Zuerst müssen wir das Studentenobjekt und das Studentennotenobjekt definieren. Das Schülerobjekt enthält grundlegende Informationen wie den Namen und die Schülernummer des Schülers, während das Schülerergebnisobjekt Informationen wie die Fachnoten und die Durchschnittsnote des Schülers enthält. Das Folgende ist die Definition eines einfachen Studentenobjekts: öffentlich
 Wir stellen die neueste Sound-Tuning-Methode für Win 11 vor
Jan 08, 2024 pm 06:41 PM
Wir stellen die neueste Sound-Tuning-Methode für Win 11 vor
Jan 08, 2024 pm 06:41 PM
Nach dem Update auf das neueste Win11 stellen viele Benutzer fest, dass sich der Sound ihres Systems leicht verändert hat, sie wissen jedoch nicht, wie sie ihn anpassen können. Deshalb bietet Ihnen diese Website heute eine Einführung in die neueste Win11-Soundanpassungsmethode für Ihren Computer. Die Bedienung ist nicht schwer und die Auswahl ist vielfältig. Laden Sie sie herunter und probieren Sie sie aus. So passen Sie den Sound des neuesten Computersystems Windows 11 an 1. Klicken Sie zunächst mit der rechten Maustaste auf das Soundsymbol in der unteren rechten Ecke des Desktops und wählen Sie „Wiedergabeeinstellungen“. 2. Geben Sie dann die Einstellungen ein und klicken Sie in der Wiedergabeleiste auf „Lautsprecher“. 3. Klicken Sie anschließend unten rechts auf „Eigenschaften“. 4. Klicken Sie in den Eigenschaften auf die Optionsleiste „Erweitern“. 5. Wenn zu diesem Zeitpunkt das √ vor „Alle Soundeffekte deaktivieren“ aktiviert ist, brechen Sie den Vorgang ab. 6. Danach können Sie unten die Soundeffekte zum Einstellen auswählen und klicken
 Wie schreibe ich ein einfaches Online-Reservierungssystem mit PHP?
Sep 26, 2023 pm 09:55 PM
Wie schreibe ich ein einfaches Online-Reservierungssystem mit PHP?
Sep 26, 2023 pm 09:55 PM
So schreiben Sie ein einfaches Online-Reservierungssystem mit PHP Mit der Popularität des Internets und dem Streben der Benutzer nach Bequemlichkeit werden Online-Reservierungssysteme immer beliebter. Ganz gleich, ob es sich um ein Restaurant, ein Krankenhaus, einen Schönheitssalon oder eine andere Dienstleistungsbranche handelt, ein einfaches Online-Reservierungssystem kann die Effizienz steigern und den Benutzern ein besseres Serviceerlebnis bieten. In diesem Artikel wird erläutert, wie Sie mit PHP ein einfaches Online-Reservierungssystem schreiben und spezifische Codebeispiele bereitstellen. Datenbank und Tabellen erstellen Zuerst müssen wir eine Datenbank erstellen, um Reservierungsinformationen zu speichern. In MyS
