

Recognizing the Power of Hadoop: Platfora BI Is Be

Recognizing the Power of Hadoop: Platfora BI Is Better on Hadoop: Ben Werther announcing the general availability of the Platfora BI: At Platfora, we made a bet that Hadoop’s destiny wasn’t simply to be a cheaper, slower cousin of the re
Recognizing the Power of Hadoop: Platfora BI Is Better on Hadoop:Ben Werther announcing the general availability of the Platfora BI:
At Platfora, we made a bet that Hadoop’s destiny wasn’t simply to be a cheaper, slower cousin of the relational data warehouse. […] Hadoop is superb at two things — it provides a near-infinite data reservoir where data of all kinds can be landed without needing to figure out how it will be used ahead of time, and it is a slow lumbering freight-train of an engine for crunching and aggregating batches of millions or billions of rows.
They are neither the first, nor the last to understand and bet on Hadoop. But in some cases this bet originates only in the financial potential of the Hadoop market and less so on the technological potential.
Indeed it’s rarely the case that these two can leave alone. When they do, it leads to either a smaller market segment or to a shorter life time. Looking around at what’s happening in the Hadoop space, technologically and business wise, I assume many economists would recognize the signs of a long lived opportunity.
As a side note, I find it interesting that very few articles are looking at two other fundamental aspects of the Hadoop platform, which, in my opinion, were, are and will remain critical to the growth of this market: open source and extensibility. Without any of these two, what would we see would be tons of copy cats wasting resources in creating small indistinguishable clones, plus countless and endless negotiations to extend and integrate the platform. Hadoop is open source and the open source developers working on it have built it with extensibility in mind. The proof is out there and is clear: look at the breadth and depth of the tools around Hadoop.
That’s the power of open source. The way of the future.
Original title and link: Recognizing the Power of Hadoop: Platfora BI Is Better on Hadoop (NoSQL database?myNoSQL)

原文地址:Recognizing the Power of Hadoop: Platfora BI Is Be, 感谢原作者分享。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Power BI kann keine Verbindung herstellen. Beim Versuch, eine Verbindung herzustellen, ist ein Fehler aufgetreten
Feb 18, 2024 pm 05:48 PM
Power BI kann keine Verbindung herstellen. Beim Versuch, eine Verbindung herzustellen, ist ein Fehler aufgetreten
Feb 18, 2024 pm 05:48 PM
PowerBI kann auf Schwierigkeiten stoßen, wenn keine Verbindung zu einer Datenquelle hergestellt werden kann, bei der es sich um eine XLS-, SQL- oder Excel-Datei handelt. In diesem Artikel werden mögliche Lösungen untersucht, die Ihnen bei der Lösung dieses Problems helfen. In diesem Artikel erfahren Sie, was zu tun ist, wenn während des Verbindungsvorgangs Fehler oder Verbindungsfehler auftreten. Wenn Sie also mit diesem Problem konfrontiert sind, lesen Sie weiter und wir werden Ihnen einige nützliche Vorschläge unterbreiten. Was ist der Gateway-Verbindungsfehler in PowerBI? Gateway-Fehler in PowerBI werden häufig durch eine Nichtübereinstimmung zwischen den Datenquelleninformationen und dem zugrunde liegenden Datensatz verursacht. Um dieses Problem zu lösen, müssen Sie sicherstellen, dass die auf dem lokalen Datengateway definierte Datenquelle korrekt und mit der im PowerBI-Desktop angegebenen Datenquelle übereinstimmt. PowerBI kann keine Verbindung herstellen
 Java-Fehler: Hadoop-Fehler, wie man damit umgeht und sie vermeidet
Jun 24, 2023 pm 01:06 PM
Java-Fehler: Hadoop-Fehler, wie man damit umgeht und sie vermeidet
Jun 24, 2023 pm 01:06 PM
Java-Fehler: Hadoop-Fehler, wie man damit umgeht und sie vermeidet Wenn Sie Hadoop zur Verarbeitung großer Datenmengen verwenden, stoßen Sie häufig auf einige Java-Ausnahmefehler, die sich auf die Ausführung von Aufgaben auswirken und zum Scheitern der Datenverarbeitung führen können. In diesem Artikel werden einige häufige Hadoop-Fehler vorgestellt und Möglichkeiten aufgezeigt, mit ihnen umzugehen und sie zu vermeiden. Java.lang.OutOfMemoryErrorOutOfMemoryError ist ein Fehler, der durch unzureichenden Speicher der Java Virtual Machine verursacht wird. Wenn Hadoop ist
 Power BI Wir können keine Verbindung herstellen, da diese Ressource diesen Anmeldeinformationstyp nicht unterstützt
Feb 19, 2024 am 10:57 AM
Power BI Wir können keine Verbindung herstellen, da diese Ressource diesen Anmeldeinformationstyp nicht unterstützt
Feb 19, 2024 am 10:57 AM
Beim Versuch, PowerBI mit SharePoint zu verbinden, tritt möglicherweise die Fehlermeldung auf, dass der Typ der bereitgestellten Anmeldeinformationen von einer bestimmten Ressource nicht unterstützt wird. Dies wirkt sich auf den Arbeitsablauf aus und muss umgehend behoben werden. In diesem Artikel erfahren Sie, wie Sie mit der PowerBI-Meldung umgehen, dass keine Verbindung hergestellt werden kann, weil die Ressource den Anmeldeinformationstyp nicht unterstützt. PowerBI Wir können keine Verbindung herstellen, weil diese Ressource diesen Anmeldeinformationstyp nicht unterstützt. Wenn PowerBI die Meldung „Wir können keine Verbindung herstellen, weil diese Ressource diesen Anmeldeinformationstyp nicht unterstützt“ anzeigt, befolgen Sie die unten aufgeführten Lösungen. Bearbeiten Sie Berechtigungen für die Datenquelle. Löschen Sie den Cache und/oder ändern Sie Berechtigungen. Ändern Sie den Standardbrowser. Löschen Sie die Datenquelle. Verwenden Sie ODataFeed. Kontaktieren Sie den PowerBI-Support. Lassen Sie uns im Detail sprechen. 1]
 Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Nach 2 Monaten kann der humanoide Roboter Walker S Kleidung falten
Apr 03, 2024 am 08:01 AM
Herausgeber des Machine Power Report: Wu Xin Die heimische Version des humanoiden Roboters + eines großen Modellteams hat zum ersten Mal die Betriebsaufgabe komplexer flexibler Materialien wie das Falten von Kleidung abgeschlossen. Mit der Enthüllung von Figure01, das das multimodale große Modell von OpenAI integriert, haben die damit verbundenen Fortschritte inländischer Kollegen Aufmerksamkeit erregt. Erst gestern veröffentlichte UBTECH, Chinas „größter Bestand an humanoiden Robotern“, die erste Demo des humanoiden Roboters WalkerS, der tief in das große Modell von Baidu Wenxin integriert ist und einige interessante neue Funktionen aufweist. Jetzt sieht WalkerS, gesegnet mit Baidu Wenxins großen Modellfähigkeiten, so aus. Wie Figure01 bewegt sich WalkerS nicht umher, sondern steht hinter einem Schreibtisch, um eine Reihe von Aufgaben zu erledigen. Es kann menschlichen Befehlen folgen und Kleidung falten
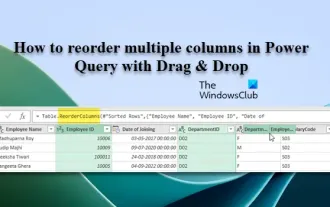 So ordnen Sie mehrere Spalten in Power Query per Drag & Drop neu an
Mar 14, 2024 am 10:55 AM
So ordnen Sie mehrere Spalten in Power Query per Drag & Drop neu an
Mar 14, 2024 am 10:55 AM
In diesem Artikel zeigen wir Ihnen, wie Sie mehrere Spalten in PowerQuery per Drag & Drop neu anordnen. Beim Importieren von Daten aus verschiedenen Quellen kann es vorkommen, dass die Spalten nicht in der gewünschten Reihenfolge vorliegen. Durch die Neuordnung von Spalten können Sie diese nicht nur in einer logischen Reihenfolge anordnen, die Ihren Analyse- oder Berichtsanforderungen entspricht, sondern verbessert auch die Lesbarkeit Ihrer Daten und beschleunigt Aufgaben wie Filtern, Sortieren und Durchführen von Berechnungen. Wie ordne ich mehrere Spalten in Excel neu an? Es gibt viele Möglichkeiten, Spalten in Excel neu anzuordnen. Sie können einfach die Spaltenüberschrift auswählen und an die gewünschte Stelle ziehen. Dieser Ansatz kann jedoch umständlich werden, wenn es um große Tabellen mit vielen Spalten geht. Um Spalten effizienter neu anzuordnen, können Sie den erweiterten Abfrageeditor verwenden. Erweiterung der Abfrage
 Verwendung von Hadoop und HBase in Beego für die Speicherung und Abfrage großer Datenmengen
Jun 22, 2023 am 10:21 AM
Verwendung von Hadoop und HBase in Beego für die Speicherung und Abfrage großer Datenmengen
Jun 22, 2023 am 10:21 AM
Mit dem Aufkommen des Big-Data-Zeitalters sind Datenverarbeitung und -speicherung immer wichtiger geworden und die effiziente Verwaltung und Analyse großer Datenmengen ist für Unternehmen zu einer Herausforderung geworden. Hadoop und HBase, zwei Projekte der Apache Foundation, bieten eine Lösung für die Speicherung und Analyse großer Datenmengen. In diesem Artikel wird erläutert, wie Sie Hadoop und HBase in Beego für die Speicherung und Abfrage großer Datenmengen verwenden. 1. Einführung in Hadoop und HBase Hadoop ist ein verteiltes Open-Source-Speicher- und Computersystem, das dies kann
 Wie man PHP und Hadoop für die Big-Data-Verarbeitung verwendet
Jun 19, 2023 pm 02:24 PM
Wie man PHP und Hadoop für die Big-Data-Verarbeitung verwendet
Jun 19, 2023 pm 02:24 PM
Da die Datenmenge weiter zunimmt, sind herkömmliche Datenverarbeitungsmethoden den Herausforderungen des Big-Data-Zeitalters nicht mehr gewachsen. Hadoop ist ein Open-Source-Framework für verteiltes Computing, das das Leistungsengpassproblem löst, das durch Einzelknotenserver bei der Verarbeitung großer Datenmengen verursacht wird, indem große Datenmengen verteilt gespeichert und verarbeitet werden. PHP ist eine Skriptsprache, die in der Webentwicklung weit verbreitet ist und die Vorteile einer schnellen Entwicklung und einfachen Wartung bietet. In diesem Artikel wird die Verwendung von PHP und Hadoop für die Verarbeitung großer Datenmengen vorgestellt. Was ist HadoopHadoop ist
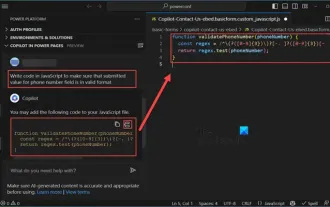 So verwenden Sie Copilot zum Generieren von Code
Mar 23, 2024 am 10:41 AM
So verwenden Sie Copilot zum Generieren von Code
Mar 23, 2024 am 10:41 AM
Als Programmierer bin ich begeistert von Tools, die das Programmiererlebnis vereinfachen. Mithilfe von Tools der künstlichen Intelligenz können wir Democode generieren und die erforderlichen Änderungen entsprechend den Anforderungen vornehmen. Das neu eingeführte Copilot-Tool in Visual Studio Code ermöglicht es uns, KI-generierten Code mit Chat-Interaktionen in natürlicher Sprache zu erstellen. Durch die Erläuterung der Funktionalität können wir die Bedeutung des vorhandenen Codes besser verstehen. Wie verwende ich Copilot zum Generieren von Code? Um zu beginnen, müssen wir zunächst die neueste PowerPlatformTools-Erweiterung herunterladen. Um dies zu erreichen, müssen Sie zur Erweiterungsseite gehen, nach „PowerPlatformTool“ suchen und auf die Schaltfläche „Installieren“ klicken
