

HDFS集中式的缓存管理原理与代码剖析

Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。 主要解决了哪些问题 1.用户可
Hadoop 2.3.0已经发布了,其中最大的亮点就是集中式的缓存管理(HDFS centralized cache management)。这个功能对于提升Hadoop系统和上层应用的执行效率与实时性有很大帮助,本文从原理、架构和代码剖析三个角度来探讨这一功能。
主要解决了哪些问题
1.用户可以根据自己的逻辑指定一些经常被使用的数据或者高优先级任务对应的数据常驻内存而不被淘汰到磁盘。例如在Hive或Impala构建的数据仓库应用中fact表会频繁地与其他表做JOIN,显然应该让fact常驻内存,这样DataNode在内存使用紧张的时候也不会把这些数据淘汰出去,同时也实现了对于?mixed workloads的SLA。
2.centralized cache是由NameNode统一管理的,那么HDFS client(例如MapReduce、Impala)就可以根据block被cache的分布情况去调度任务,做到memory-locality。
3.HDFS原来单纯靠DataNode的OS buffer cache,这样不但没有把block被cache的分布情况对外暴露给上层应用优化任务调度,也有可能会造成cache浪费。例如一个block的三个replica分别存储在三个DataNote 上,有可能这个block同时被这三台DataNode的OS buffer cache,那么从HDFS的全局看就有同一个block在cache中存了三份,造成了资源浪费。?
4.加快HDFS client读速度。过去NameNode处理读请求时只根据拓扑远近决定去哪个DataNode读,现在还要加入speed的因素。当HDFS client和要读取的block被cache在同一台DataNode的时候,可以通过zero-copy read直接从内存读,略过磁盘I/O、checksum校验等环节。
5.即使数据被cache的DataNode节点宕机,block移动,集群重启,cache都不会受到影响。因为cache被NameNode统一管理并被被持久化到FSImage和EditLog,如果cache的某个block的DataNode宕机,NameNode会调度其他存储了这个replica的DataNode,把它cache到内存。
基本概念
cache directive: 表示要被cache到内存的文件或者目录。
cache pool: 用于管理一系列的cache directive,类似于命名空间。同时使用UNIX风格的文件读、写、执行权限管理机制。命令例子:
hdfs cacheadmin -addDirective -path /user/hive/warehouse/fact.db/city -pool financial -replication 1?
以上代码表示把HDFS上的文件city(其实是hive上的一个fact表)放到HDFS centralized cache的financial这个cache pool下,而且这个文件只需要被缓存一份。
系统架构与原理
 用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
用户可以通过hdfs cacheadmin命令行或者HDFS API显式指定把HDFS上的某个文件或者目录放到HDFS?centralized?cache中。这个centralized?cache由分布在每个DataNode节点的off-heap内存组成,同时被NameNode统一管理。每个DataNode节点使用mmap/mlock把存储在磁盘文件中的HDFS block映射并锁定到off-heap内存中。
DFSClient读取文件时向NameNode发送getBlockLocations RPC请求。NameNode会返回一个LocatedBlock列表给DFSClient,这个LocatedBlock对象里有这个block的replica所在的DataNode和cache了这个block的DataNode。可以理解为把被cache到内存中的replica当做三副本外的一个高速的replica。
注:centralized cache和distributed cache的区别:
distributed cache将文件分发到各个DataNode结点本地磁盘保存,并且用完后并不会被立即清理的,而是由专门的一个线程根据文件大小限制和文件数目上限周期性进行清理。本质上distributed cache只做到了disk locality,而centralized cache做到了memory locality。
实现逻辑与代码剖析
HDFS centralized cache涉及到多个操作,其处理逻辑非常类似。为了简化问题,以addDirective这个操作为例说明。
1.NameNode处理逻辑
 NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
NameNode内部主要的组件如图所示。FSNamesystem里有个CacheManager是centralized cache在NameNode端的核心组件。我们都知道BlockManager负责管理分布在各个DataNode上的block replica,而CacheManager则是负责管理分布在各个DataNode上的block cache。
DFSClient给NameNode发送名为addCacheDirective的RPC, 在ClientNamenodeProtocol.proto这个文件中定义相应的接口。
NameNode接收到这个RPC之后处理,首先把这个需要被缓存的Path包装成CacheDirective加入CacheManager所管理的directivesByPath中。这时对应的File/Directory并没有被cache到内存。
一旦CacheManager那边添加了新的CacheDirective,触发CacheReplicationMonitor.rescan()来扫描并把需要通知DataNode做cache的block加入到CacheReplicationMonitor. cachedBlocks映射中。这个rescan操作在NameNode启动时也会触发,同时在NameNode运行期间以固定的时间间隔触发。
Rescan()函数主要逻辑如下:
rescanCacheDirectives()->rescanFile():依次遍历每个等待被cache的directive(存储在CacheManager. directivesByPath里),把每个等待被cache的directive包含的block都加入到CacheReplicationMonitor.cachedBlocks集合里面。
rescanCachedBlockMap():调用CacheReplicationMonitor.addNewPendingCached()为每个等待被cache的block选择一个合适的DataNode去cache(一般是选择这个block的三个replica所在的DataNode其中的剩余可用内存最多的一个),加入对应的DatanodeDescriptor的pendingCached列表。
2.NameNode与DataNode的RPC逻辑
DataNode定期向NameNode发送heartbeat RPC用于表明它还活着,同时DataNode还会向NameNode定期发送block report(默认6小时)和cache block(默认10秒)用于同步block和cache的状态。
NameNode会在每次处理某一DataNode的heartbeat RPC时顺便检查该DataNode的pendingCached列表是否为空,不为空的话发送DatanodeProtocol.DNA_CACHE命令给具体的DataNode去cache对应的block replica。
3.DataNode处理逻辑
 DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
DataNode内部主要的组件如图所示。DataNode启动的时候只是检查了一下dfs.datanode.max.locked.memory是否超过了OS的限制,并没有把留给Cache使用的内存空间锁定。
在DataNode节点上每个BlockPool对应有一个BPServiceActor线程向NameNode发送heartbeat、接收response并处理。如果接收到来自NameNode的RPC里面的命令是DatanodeProtocol.DNA_CACHE,那么调用FsDatasetImpl.cacheBlock()把对应的block cache到内存。
这个函数先是通过RPC传过来的blockId找到其对应的FsVolumeImpl (因为执行cache block操作的线程cacheExecutor是绑定在对应的FsVolumeImpl里的);然后调用FsDatasetCache.cacheBlock()把这个block封装成MappableBlock加入到mappableBlockMap里统一管理起来,然后向对应的FsVolumeImpl.cacheExecutor线程池提交一个CachingTask异步任务(cache的过程是异步执行的)。
FsDatasetCache有个成员mappableBlockMap(HashMap)管理着这台DataNode的所有的MappableBlock及其状态(caching/cached/uncaching)。目前DataNode中”哪些block被cache到内存里了”也是只保存了soft state(和NameNode的block map一样),是DataNode向NameNode 发送heartbeat之后从NameNode那问回来的,没有持久化到DataNode本地硬盘。
CachingTask的逻辑: 调用MappableBlock.load()方法把对应的block从DataNode本地磁盘通过mmap映射到内存中,然后通过mlock锁定这块内存空间,并对这个映射到内存的block做checksum检验其完整性。这样对于memory-locality的DFSClient就可以通过zero-copy直接读内存中的block而不需要校验了。
4.DFSClient读逻辑:
HDFS的读主要有三种: 网络I/O读 -> short circuit read -> zero-copy read。网络I/O读就是传统的HDFS读,通过DFSClient和Block所在的DataNode建立网络连接传输数据。?
当DFSClient和它要读取的block在同一台DataNode时,DFSClient可以跨过网络I/O直接从本地磁盘读取数据,这种读取数据的方式叫short circuit read。目前HDFS实现的short circuit read是通过共享内存获取要读的block在DataNode磁盘上文件的file descriptor(因为这样比传递文件目录更安全),然后直接用对应的file descriptor建立起本地磁盘输入流,所以目前的short circuit read也是一种zero-copy read。
增加了Centralized cache的HDFS的读接口并没有改变。DFSClient通过RPC获取LocatedBlock时里面多了个成员表示哪个DataNode把这个block cache到内存里面了。如果DFSClient和该block被cache的DataNode在一起,就可以通过zero-copy read大大提升读效率。而且即使在读取的过程中该block被uncache了,那么这个读就被退化成了本地磁盘读,一样能够获取数据。?
对上层应用的影响
对于HDFS上的某个目录已经被addDirective缓存起来之后,如果这个目录里新加入了文件,那么新加入的文件也会被自动缓存。这一点对于Hive/Impala式的应用非常有用。
HBase in-memory table:可以直接把某个HBase表的HFile放到centralized cache中,这会显著提高HBase的读性能,降低读请求延迟。
和Spark RDD的区别:多个RDD的之间的读写操作可能完全在内存中完成,出错就重算。HDFS centralized cache中被cache的block一定是先写到磁盘上的,然后才能显式被cache到内存。也就是说只能cache读,不能cache写。
目前的centralized cache不是DFSClient读了谁就会把谁cache,而是需要DFSClient显式指定要cache谁,cache多长时间,淘汰谁。目前也没有类似LRU的置换策略,如果内存不够用的时候需要client显式去淘汰对应的directive到磁盘。
现在还没有跟YARN整合,需要用户自己调整好留给DataNode用于cache的内存和NodeManager的内存使用。
参考文献
http://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/CentralizedCacheManagement.html
https://issues.apache.org/jira/browse/HDFS-4949
原文地址:HDFS集中式的缓存管理原理与代码剖析, 感谢原作者分享。

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So zeigen Sie den DNS-Cache unter Linux an und aktualisieren ihn
Mar 07, 2024 am 08:43 AM
So zeigen Sie den DNS-Cache unter Linux an und aktualisieren ihn
Mar 07, 2024 am 08:43 AM
DNS (DomainNameSystem) ist ein System, das im Internet verwendet wird, um Domänennamen in entsprechende IP-Adressen umzuwandeln. In Linux-Systemen ist DNS-Caching ein Mechanismus, der die Zuordnungsbeziehung zwischen Domänennamen und IP-Adressen lokal speichert, was die Geschwindigkeit der Domänennamenauflösung erhöhen und die Belastung des DNS-Servers verringern kann. DNS-Caching ermöglicht es dem System, die IP-Adresse schnell abzurufen, wenn es anschließend auf denselben Domänennamen zugreift, ohne jedes Mal eine Abfrageanforderung an den DNS-Server senden zu müssen, wodurch die Netzwerkleistung und -effizienz verbessert wird. In diesem Artikel erfahren Sie, wie Sie den DNS-Cache unter Linux anzeigen und aktualisieren, sowie zugehörige Details und Beispielcode. Bedeutung des DNS-Cachings In Linux-Systemen spielt das DNS-Caching eine Schlüsselrolle. seine Existenz
 Analyse der Funktion und des Prinzips von Nohup
Mar 25, 2024 pm 03:24 PM
Analyse der Funktion und des Prinzips von Nohup
Mar 25, 2024 pm 03:24 PM
Analyse der Rolle und des Prinzips von nohup In Unix und Unix-ähnlichen Betriebssystemen ist nohup ein häufig verwendeter Befehl, mit dem Befehle im Hintergrund ausgeführt werden können. Selbst wenn der Benutzer die aktuelle Sitzung verlässt oder das Terminalfenster schließt, kann der Befehl ausgeführt werden werden weiterhin ausgeführt. In diesem Artikel werden wir die Funktion und das Prinzip des Nohup-Befehls im Detail analysieren. 1. Die Rolle von Nohup: Befehle im Hintergrund ausführen: Mit dem Befehl Nohup können wir Befehle mit langer Laufzeit weiterhin im Hintergrund ausführen lassen, ohne dass dies dadurch beeinträchtigt wird, dass der Benutzer die Terminalsitzung verlässt. Dies muss ausgeführt werden
 Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
Caching-Mechanismus und Anwendungspraxis in der PHP-Entwicklung
May 09, 2024 pm 01:30 PM
In der PHP-Entwicklung verbessert der Caching-Mechanismus die Leistung, indem er häufig aufgerufene Daten vorübergehend im Speicher oder auf der Festplatte speichert und so die Anzahl der Datenbankzugriffe reduziert. Zu den Cache-Typen gehören hauptsächlich Speicher-, Datei- und Datenbank-Cache. In PHP können Sie integrierte Funktionen oder Bibliotheken von Drittanbietern verwenden, um Caching zu implementieren, wie zum Beispiel Cache_get() und Memcache. Zu den gängigen praktischen Anwendungen gehören das Zwischenspeichern von Datenbankabfrageergebnissen zur Optimierung der Abfrageleistung und das Zwischenspeichern von Seitenausgaben zur Beschleunigung des Renderings. Der Caching-Mechanismus verbessert effektiv die Reaktionsgeschwindigkeit der Website, verbessert das Benutzererlebnis und reduziert die Serverlast.
 Erstellen Sie Linux-„.a'-Dateien und führen Sie sie aus
Mar 20, 2024 pm 04:46 PM
Erstellen Sie Linux-„.a'-Dateien und führen Sie sie aus
Mar 20, 2024 pm 04:46 PM
Die Arbeit mit Dateien im Linux-Betriebssystem erfordert die Verwendung verschiedener Befehle und Techniken, die es Entwicklern ermöglichen, Dateien, Code, Programme, Skripts und andere Dinge effizient zu erstellen und auszuführen. Im Linux-Umfeld haben Dateien mit der Endung „.a“ als statische Bibliotheken eine große Bedeutung. Diese Bibliotheken spielen eine wichtige Rolle in der Softwareentwicklung und ermöglichen Entwicklern die effiziente Verwaltung und gemeinsame Nutzung gemeinsamer Funktionen über mehrere Programme hinweg. Für eine effektive Softwareentwicklung in einer Linux-Umgebung ist es wichtig zu verstehen, wie „.a“-Dateien erstellt und ausgeführt werden. In diesem Artikel wird erläutert, wie Sie die Linux-Datei „.a“ umfassend installieren und konfigurieren. Lassen Sie uns die Definition, den Zweck, die Struktur und die Methoden zum Erstellen und Ausführen der Linux-Datei „.a“ untersuchen. Was ist L?
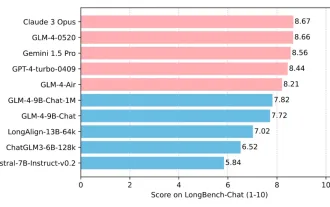 Tsinghua University und Zhipu AI Open Source GLM-4: Start einer neuen Revolution in der Verarbeitung natürlicher Sprache
Jun 12, 2024 pm 08:38 PM
Tsinghua University und Zhipu AI Open Source GLM-4: Start einer neuen Revolution in der Verarbeitung natürlicher Sprache
Jun 12, 2024 pm 08:38 PM
Seit der Einführung von ChatGLM-6B am 14. März 2023 haben die Modelle der GLM-Serie große Aufmerksamkeit und Anerkennung erhalten. Insbesondere nachdem ChatGLM3-6B als Open Source verfügbar war, sind die Entwickler voller Erwartungen an das von Zhipu AI eingeführte Modell der vierten Generation. Diese Erwartung wurde mit der Veröffentlichung von GLM-4-9B endlich vollständig erfüllt. Die Geburt von GLM-4-9B Um kleinen Modellen (10B und darunter) leistungsfähigere Fähigkeiten zu verleihen, hat das GLM-Technikteam nach fast einem halben Jahr dieses neue Open-Source-Modell der GLM-Serie der vierten Generation auf den Markt gebracht: GLM-4-9B Erkundung. Dieses Modell komprimiert die Modellgröße erheblich und stellt gleichzeitig Genauigkeit sicher. Es verfügt über eine schnellere Inferenzgeschwindigkeit und eine höhere Effizienz. Die Untersuchungen des GLM-Technikteams haben dies nicht getan
 Der Zusammenhang zwischen CPU, Speicher und Cache wird ausführlich erklärt!
Mar 07, 2024 am 08:30 AM
Der Zusammenhang zwischen CPU, Speicher und Cache wird ausführlich erklärt!
Mar 07, 2024 am 08:30 AM
Es besteht eine enge Interaktion zwischen der CPU (Zentraleinheit), dem Arbeitsspeicher (Random Access Memory) und dem Cache, die zusammen eine kritische Komponente eines Computersystems bilden. Die Koordination zwischen ihnen gewährleistet den normalen Betrieb und die effiziente Leistung des Computers. Als Gehirn des Computers ist die CPU für die Ausführung verschiedener Anweisungen und die Datenverarbeitung verantwortlich; der Speicher dient zur vorübergehenden Speicherung von Daten und Programmen und sorgt so für schnelle Lese- und Schreibzugriffsgeschwindigkeiten, und der Cache spielt eine Pufferfunktion und beschleunigt den Datenzugriff Geschwindigkeit und Verbesserung Die CPU des Computers ist die Kernkomponente des Computers und für die Ausführung verschiedener Anweisungen, arithmetischer Operationen und logischer Operationen verantwortlich. Es wird als „Gehirn“ des Computers bezeichnet und spielt eine wichtige Rolle bei der Verarbeitung von Daten und der Ausführung von Aufgaben. Der Speicher ist ein wichtiges Speichergerät in einem Computer.
 Erstellen Sie einen Agenten in einem Satz! Robin Li: Die Ära kommt, in der jeder ein Entwickler ist
Apr 17, 2024 pm 02:28 PM
Erstellen Sie einen Agenten in einem Satz! Robin Li: Die Ära kommt, in der jeder ein Entwickler ist
Apr 17, 2024 pm 02:28 PM
Das große Vorbild untergräbt alles und gelangt schließlich an die Spitze dieses Redakteurs. Es ist auch ein Agent, der in nur einem Satz erstellt wurde. Geben Sie ihm auf diese Weise einen Artikel und in weniger als einer Sekunde werden neue Titelvorschläge veröffentlicht. Im Vergleich zu mir kann man von dieser Effizienz nur sagen, dass sie blitzschnell und langsam wie ein Faultier ist ... Was noch unglaublicher ist, ist, dass die Erstellung dieses Agenten tatsächlich nur ein paar Minuten dauert. Prompt gehört Tante Jiang: Und wenn Sie dieses subversive Gefühl auch erleben möchten, kann jetzt jeder auf Basis der neuen intelligenten Wenxin-Plattform von Baidu kostenlos seinen eigenen intelligenten Assistenten erstellen. Sie können Suchmaschinen, intelligente Hardwareplattformen, Spracherkennung, Karten, Autos und andere mobile ökologische Kanäle von Baidu nutzen, damit mehr Menschen Ihre Kreativität nutzen können! Robin Li selbst
 Das Open-Source-Codemodell von Mistral erobert den Thron! Codestral legt großen Wert auf Schulungen in über 80 Sprachen und einheimische Tongyi-Entwickler bitten um Teilnahme!
Jun 08, 2024 pm 09:55 PM
Das Open-Source-Codemodell von Mistral erobert den Thron! Codestral legt großen Wert auf Schulungen in über 80 Sprachen und einheimische Tongyi-Entwickler bitten um Teilnahme!
Jun 08, 2024 pm 09:55 PM
Produziert von 51CTO Technology Stack (WeChat-ID: blog51cto) Mistral hat sein erstes Codemodell Codestral-22B veröffentlicht! Das Verrückte an diesem Modell ist nicht nur, dass es auf über 80 Programmiersprachen trainiert ist, darunter Swift usw., die von vielen Codemodellen ignoriert werden. Ihre Geschwindigkeiten sind nicht genau gleich. Es ist erforderlich, ein „Publish/Subscribe“-System in der Go-Sprache zu schreiben. Der GPT-4o hier wird ausgegeben und Codestral reicht das Papier so schnell ein, dass es kaum zu erkennen ist! Da das Modell gerade erst auf den Markt gekommen ist, wurde es noch nicht öffentlich getestet. Doch laut Mistral-Verantwortlichen ist Codestral derzeit das leistungsstärkste Open-Source-Codemodell. Freunde, die sich für das Bild interessieren, können zu: - Umarmen Sie das Gesicht: https
