

搭建Hadoop环境的详细过程

即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们想先搭建hadoop环境,在这个过程中慢慢体会一下hadoop。 我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,在这里我
即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们想先搭建hadoop环境,在这个过程中慢慢体会一下hadoop。
我在这里说的是hadoop伪分布式模式(Pseudo-Distributed Mode),其实网上已经有很多教程,在这里我详详细细的描述整个搭建过程,也算是自己重新回忆一下。
准备阶段(下载地址我这里就不给出了):
Win7旗舰版 Vmware-9.0.2
ubuntu-12.04 hadoop-0.20.2 jdk-8u5-linux-i586-demos
搭建流程:
1、装机阶段:
一、安装Ubuntu操作系统
二、在Ubuntu下创建hadoop用户组和用户
三、在Ubuntu下安装JDK
四、修改机器名
五、安装ssh服务
六、建立ssh无密码登录本机
七、安装hadoop
八、在单机上运行hadoop
一、安装Ubuntu操作系统
略……
二、在Ubuntu下创建hadoop用户组和用户
(1)安装Ubuntu时已经建立了一个用户,但是为了以后Hadoop操作,专门渐建立一个hadoop用户组和hadoop用户。

(2)给hadoop用户添加权限,打开/etc/sudoers文件。
sudo gedit /etc/sudoers
打开/etc/sudoers文件了,给hadoop用户赋予root用户同样的权限。在
root ALL=(ALL:ALL) ALL
下添加:
hadoop ALL=(ALL:ALL) ALL
三、在Ubuntu下安装JDK
1、创建JDK安装目录
(1)由于我使用的是VMware安装的Ubuntu系统,设置本地thisceshi文件夹共享到Ubuntu系统,指定的安装目录是:/usr/local/java。可是系统安装后在/usr/local下并没有java目录,这需要我们去创建一个java文件夹,
进入/usr/local文件夹
cd /usr/local
创建java文件夹,
sudo mkdir /usr/local/java
(2)解压JDK到目标目录
进入共享文件夹thisceshi,
cd /mnt/hgfs/thisceshi
然后进入到共享文件夹中,继续我们解压JDK到之前建好的java文件夹中,
sudo cp jdk-8u5-linux-i586-demos.tar.gz /usr/local/java
2、安装jdk
(1)切换到root用户下,
hadoop@s15:/mnt/hgfs/thisceshi$ su 密码:
(2)解压jdk-8u5-linux-i586-demos.tar.gz
sudo tar -zxf jdk-8u5-linux-i586-demos.tar.gz
此时java目录中多了一个jdk1.6.0_30文件夹。
3、配置环境变量
(1)打开/etc/profile文件,
sudo gedit /etc/profile
(2)添加变量,
#set java environment export JAVA_HOME=/usr/local/java/jdk1.6.0_30 export JRE_HOME=/usr/local/java/jdk1.6.0_30/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
一般更改/etc/profile文件后,需要重启机器才能生效,在这里我们可以使用如下指令可使配置文件立即生效,
source /etc/profile
(3)查看java环境变量是否配置成功,
java -version
显示如下:
java version "1.6.0_30" Java(TM) SE Runtime Environment (build 1.6.0_30-b12) Java HotSpot(TM) Client VM (build 20.5-b03, mixed mode, sharing)
但是在root下一切正常,在hadoop用户下就出现了问题,
程序“java”已包含在下列软件包中: * gcj-4.4-jre-headless * openjdk-6-jre-headless * cacao * gij-4.3 * jamvm
在终端中我们分别运行下面指令,
sudo update-alternatives --install /usr/bin/java java /usr/local/java/jdk1.6.0_30/bin/java 300 sudo update-alternatives --install /usr/bin/javac javac /usr/local/java/jdk1.6.0_30/bin/javac 300
问题解决。
四、修改机器名
当ubuntu安装成功时,我们的机器名都默认为:ubuntu ,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。这是我开始是根据网上教程也给修改了,其实伪分布式搭建的时候,可以省了,不然还造成一些不必要的麻烦。
1、打开/etc/hostname文件,运行指令,
sudo gedit /etc/hostname
2、然后hostname中添加s15五、安装ssh服务保存退出,即s15是当前用户别名。在这里需要重启系统后才会生效。
hadoop@s15:~$
五、安装ssh服务
1、安装openssh-server
sudo apt-get install openssh-server
2、等待安装,即可。



六、 建立ssh无密码登录本机
在这里,我自己还是模模糊糊的。
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、创建ssh-key,,这里我们采用rsa方式,
ssh-keygen -t rsa -P ''
网上教程中后面是双引号,我在执行出现错误,换成单引号,则可以执行。

进入ssh,查看里面文件
hadoop@s15:~$ cd .ssh hadoop@s15:~/.ssh$ ls id_rsa id_rsa.pub
2、进入~/.ssh/目录下,将idrsa.pub追加到authorizedkeys授权文件中,开始是没有authorized_keys文件的,
cat id_rsa.pub >> authorized_keys
3、登录localhost,
hadoop@s15:~/.ssh$ ssh localhost Welcome to Ubuntu 12.04 LTS (GNU/Linux 3.2.0-61-generic-pae i686) * Documentation: https://help.ubuntu.com/ 663 packages can be updated. 266 updates are security updates. Last login: Sat May 10 13:08:03 2014 from localhost
4、执行退出命令,
hadoop@s15:~$ exit 登出 Connection to localhost closed.
七、安装hadoop
1、从共享文件夹thisceshi中将hadoop-0.20.2.tar.gz复制到安装目录 /usr/local/下
2、解压hadoop-0.20.203.tar.gz,
3、将解压出的文件夹改名为hadoop,
4、将该hadoop文件夹的属主用户设为hadoop,
sudo chown -R hadoop:hadoop hadoop
5、打开hadoop/conf/hadoop-env.sh文件,
6、配置conf/hadoop-env.sh(找到#export JAVA_HOME=…,去掉#,然后加上本机jdk的路径)
# The java implementation to use. Required. export JAVA_HOME=/usr/local/java/jdk1.6.0_30 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin
让环境立即生效,
source /usr/local/hadoop/conf/hadoop-env.sh
7、打开conf/core-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> fs.default.name hdfs://localhost:9000
8、打开conf/mapred-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> mapred.job.tracker localhost:9001
9、打开conf/hdfs-site.xml文件,编辑如下:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="http://www.cndwzone.com/archives/configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> dfs.name.dir /usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2 dfs.data.dir /usr/local/hadoop/data1,/usr/local/hadoop/data2 dfs.replication 2
10、打开conf/masters文件,添加作为secondarynamenode的主机名,因为是伪分布式,只有一个节点,这里只需填写localhost就可以。
11、打开conf/slaves文件,添加作为slave的主机名,一行一个。因为是伪分布式,只有一个节点,这里也只需填写localhost就可以。
八、在单机上运行hadoop
1、进入hadoop目录下,格式化hdfs文件系统,初次运行hadoop时一定要有该操作,当你看到下图时,就说明你的hdfs文件系统格式化成功了。

3、进入bin目录启动start-all.sh,
4、检测hadoop是否启动成功,

到此,hadoop伪分布式环境搭建完成。
在搭建过程中可能会遇到各种问题,到时大家不用着急,可以谷歌,百度一下。解决问题的过程就是加深学习的过程。我当时都忘了花了多久才将环境搭建好,最初的时候,连最基本的指令也不懂,也不知道怎么运行。我在这里说出来就是想说,开始的一无所知不要害怕,慢慢来就好,在那么一刻你就会有所知,有所明白。之后的文章中会介绍在hadoop环境下运行WordCount,hadoop中的HelloWorld。
 即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们 […]
即上一篇《初步了解Hadoop》已经过去好多天了,今天继续hadoop学习之旅。大体了解hadoop原理,我们 […]

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Die Windows-Wiederherstellungsumgebung kann nicht gestartet werden
Feb 19, 2024 pm 11:12 PM
Die Windows-Wiederherstellungsumgebung kann nicht gestartet werden
Feb 19, 2024 pm 11:12 PM
Windows Recovery Environment (WinRE) ist eine Umgebung zur Reparatur von Windows-Betriebssystemfehlern. Nach dem Aufrufen von WinRE können Sie eine Systemwiederherstellung, einen Werksreset, die Deinstallation von Updates usw. durchführen. Wenn Sie WinRE nicht starten können, führt Sie dieser Artikel durch Korrekturen zur Behebung des Problems. Die Windows-Wiederherstellungsumgebung kann nicht gestartet werden. Wenn Sie die Windows-Wiederherstellungsumgebung nicht starten können, verwenden Sie die unten bereitgestellten Korrekturen: Überprüfen Sie den Status der Windows-Wiederherstellungsumgebung. Verwenden Sie andere Methoden, um die Windows-Wiederherstellungsumgebung aufzurufen. Haben Sie versehentlich die Windows-Wiederherstellungspartition gelöscht? Führen Sie unten ein direktes Upgrade oder eine Neuinstallation von Windows durch. Wir haben alle diese Korrekturen ausführlich erläutert. 1] WLAN prüfen
 Was sind die Unterschiede zwischen Python und Anaconda?
Sep 06, 2023 pm 08:37 PM
Was sind die Unterschiede zwischen Python und Anaconda?
Sep 06, 2023 pm 08:37 PM
In diesem Artikel lernen wir die Unterschiede zwischen Python und Anaconda kennen. Was ist Python? Python ist eine Open-Source-Sprache, die großen Wert darauf legt, den Code durch Einrücken von Zeilen und Leerzeichen leicht lesbar und verständlich zu machen. Aufgrund seiner Flexibilität und Benutzerfreundlichkeit eignet sich Python ideal für eine Vielzahl von Anwendungen, darunter unter anderem wissenschaftliches Rechnen, künstliche Intelligenz und Datenwissenschaft sowie die Erstellung und Entwicklung von Online-Anwendungen. Wenn Python getestet wird, wird es sofort in Maschinensprache übersetzt, da es sich um eine interpretierte Sprache handelt. Einige Sprachen, wie zum Beispiel C++, erfordern eine Kompilierung, um verstanden zu werden. Kenntnisse in Python sind ein großer Vorteil, da es sehr einfach zu verstehen, zu entwickeln, auszuführen und zu lesen ist. Das macht Python
 Java-Fehler: Hadoop-Fehler, wie man damit umgeht und sie vermeidet
Jun 24, 2023 pm 01:06 PM
Java-Fehler: Hadoop-Fehler, wie man damit umgeht und sie vermeidet
Jun 24, 2023 pm 01:06 PM
Java-Fehler: Hadoop-Fehler, wie man damit umgeht und sie vermeidet Wenn Sie Hadoop zur Verarbeitung großer Datenmengen verwenden, stoßen Sie häufig auf einige Java-Ausnahmefehler, die sich auf die Ausführung von Aufgaben auswirken und zum Scheitern der Datenverarbeitung führen können. In diesem Artikel werden einige häufige Hadoop-Fehler vorgestellt und Möglichkeiten aufgezeigt, mit ihnen umzugehen und sie zu vermeiden. Java.lang.OutOfMemoryErrorOutOfMemoryError ist ein Fehler, der durch unzureichenden Speicher der Java Virtual Machine verursacht wird. Wenn Hadoop ist
 So erstellen Sie schnell ein statistisches Diagrammsystem unter dem Vue-Framework
Aug 21, 2023 pm 05:48 PM
So erstellen Sie schnell ein statistisches Diagrammsystem unter dem Vue-Framework
Aug 21, 2023 pm 05:48 PM
So erstellen Sie schnell ein statistisches Diagrammsystem unter dem Vue-Framework. In modernen Webanwendungen sind statistische Diagramme ein wesentlicher Bestandteil. Als beliebtes Front-End-Framework bietet Vue.js viele praktische Tools und Komponenten, die uns beim schnellen Aufbau eines statistischen Diagrammsystems helfen können. In diesem Artikel wird erläutert, wie Sie mit dem Vue-Framework und einigen Plug-Ins ein einfaches statistisches Diagrammsystem erstellen. Zuerst müssen wir eine Vue.js-Entwicklungsumgebung vorbereiten, einschließlich der Installation von Vue-Scaffolding und einigen zugehörigen Plug-Ins. Führen Sie den folgenden Befehl in der Befehlszeile aus
 Können im Mistlock Kingdom Gebäude in freier Wildbahn gebaut werden?
Mar 07, 2024 pm 08:28 PM
Können im Mistlock Kingdom Gebäude in freier Wildbahn gebaut werden?
Mar 07, 2024 pm 08:28 PM
Spieler können beim Spielen im Mistlock-Königreich verschiedene Materialien sammeln. Viele Spieler möchten wissen, ob Gebäude im Mistlock-Königreich nicht in der Wildnis gebaut werden können. . Können im Mistlock Kingdom Gebäude in freier Wildbahn gebaut werden? 1. In den wilden Gebieten des Mist Lock Kingdom können keine Gebäude gebaut werden. 2. Das Gebäude muss im Rahmen des Altars errichtet werden. 3. Spieler können den Geisterfeueraltar selbst errichten, aber sobald sie den Bereich verlassen, können sie keine Gebäude mehr errichten. 4. Wir können als Zuhause auch direkt ein Loch in den Berg graben, sodass wir keine Baumaterialien verbrauchen müssen. 5. In den von den Spielern selbst gebauten Gebäuden gibt es einen Komfortmechanismus, d. h. je besser die Innenausstattung, desto höher der Komfort. 6. Hoher Komfort bringt den Spielern Attributsboni, wie z
 Verwendung von Hadoop und HBase in Beego für die Speicherung und Abfrage großer Datenmengen
Jun 22, 2023 am 10:21 AM
Verwendung von Hadoop und HBase in Beego für die Speicherung und Abfrage großer Datenmengen
Jun 22, 2023 am 10:21 AM
Mit dem Aufkommen des Big-Data-Zeitalters sind Datenverarbeitung und -speicherung immer wichtiger geworden und die effiziente Verwaltung und Analyse großer Datenmengen ist für Unternehmen zu einer Herausforderung geworden. Hadoop und HBase, zwei Projekte der Apache Foundation, bieten eine Lösung für die Speicherung und Analyse großer Datenmengen. In diesem Artikel wird erläutert, wie Sie Hadoop und HBase in Beego für die Speicherung und Abfrage großer Datenmengen verwenden. 1. Einführung in Hadoop und HBase Hadoop ist ein verteiltes Open-Source-Speicher- und Computersystem, das dies kann
 Best Practices und Vorsichtsmaßnahmen für den Aufbau eines Webservers unter CentOS 7
Aug 25, 2023 pm 11:33 PM
Best Practices und Vorsichtsmaßnahmen für den Aufbau eines Webservers unter CentOS 7
Aug 25, 2023 pm 11:33 PM
Best Practices und Vorsichtsmaßnahmen für den Aufbau von Webservern unter CentOS7 Einführung: Im heutigen Internetzeitalter sind Webserver eine der Kernkomponenten für den Aufbau und das Hosting von Websites. CentOS7 ist eine leistungsstarke Linux-Distribution, die häufig in Serverumgebungen verwendet wird. In diesem Artikel werden die Best Practices und Überlegungen zum Aufbau eines Webservers unter CentOS7 erläutert und einige Codebeispiele bereitgestellt, die Ihnen das Verständnis erleichtern. 1. Installieren Sie den Apache-HTTP-Server. Apache ist das am weitesten verbreitete W
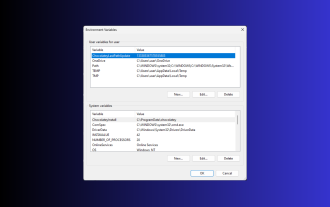 11 Möglichkeiten zum Festlegen von Umgebungsvariablen unter Windows 3
Sep 15, 2023 pm 12:21 PM
11 Möglichkeiten zum Festlegen von Umgebungsvariablen unter Windows 3
Sep 15, 2023 pm 12:21 PM
Das Festlegen von Umgebungsvariablen unter Windows 11 kann Ihnen dabei helfen, Ihr System anzupassen, Skripts auszuführen und Anwendungen zu konfigurieren. In diesem Leitfaden besprechen wir drei Methoden zusammen mit Schritt-für-Schritt-Anleitungen, damit Sie Ihr System nach Ihren Wünschen konfigurieren können. Es gibt drei Arten von Umgebungsvariablen. Systemumgebungsvariablen: Globale Variablen haben die niedrigste Priorität und sind für alle Benutzer und Anwendungen unter Windows zugänglich. Sie werden normalerweise zum Definieren systemweiter Einstellungen verwendet. Benutzerumgebungsvariablen – Höhere Priorität. Diese Variablen gelten nur für den aktuellen Benutzer und Prozess, der unter diesem Konto ausgeführt wird, und werden von dem Benutzer oder der Anwendung festgelegt, die unter diesem Konto ausgeführt wird. Prozessumgebungsvariablen – haben die höchste Priorität, sind temporär und gelten für den aktuellen Prozess und seine Unterprozesse und stellen das Programm bereit
