

php采集入门教程,教你如何写采集

php采集入门教程,教你如何写采集
我们第一步是采集所有的连接,我们这个可不是简单的采集一篇文章哦,我们要做的是采集整本书,并且保存到一个文本,因为现在MP3普及了,都可以看电子书了。
一本书要怎么保存呢,当然是要用书名保存便于查找拉,我们先来采集这本书的标题,
先来看一下原形:
规律是:
我们来写一下正则表达式吧,不要告诉我不会,不会就来湖南拉,嘿嘿很多大鸟的。
正则表达式:
下面开始开工拉!我们首先要获得资源,这里需要用到一个函数:
file_get_contents()
介绍:
主要功能:将整个文件读入一个字符串
原形是:string file_get_contents
( string filename [, bool use_include_path [, resource context [, int offset [, int maxlen]]]] )
具体什么意思呢,其实就是告诉你在某个资源内搜索符合规定的字符串并赋予给一个变量
上边是开始需要用到的,我们了解一点就开始写一点那样更能够深刻的理解并且能记住,我来分析下写程序的思路:
我们采集一个地址,不会是就采集一本书把所以我们的采集地址是变化的,变化的用什么呢?这个时候一个硕大的粉笔扔了过来,我不是告诉你了吗?变量,一个严厉的王建军老师,用尽了全身力气,汇集在粉笔上对我无情的扔了过来,我想哭。。。。。。。老师打人了!!!!!!!!打家来看啊。
用变量好的,那就用变量,我们获取地址,代码如下:
$url = "http://book.sina.com.cn/nzt/lit/zhuxian2/index.shtml";// 图书地址
有了上边讲的,现在应该可以完全写出来了,开始代码:
//****************************************************************
$url = "http://book.sina.com.cn/nzt/lit/zhuxian2/index.shtml";// 图书地址
$ver = "old"; //新旧版本
//因为图书他的页面又两种板式,所以我们要在这里区别一下
//****************************************************************
// 获取页面代码 file_get_contents() 把文件读入一个字符串,下边的时候需要用到
$r = file_get_contents($url);
//在上边获取的字符串中搜索标题,并赋值给变量$booktitle,$booktitle是数组,/is就凑活理解成开始吧!
preg_match("//is",$r,$booktitle);
//把第一个出现捕获的标题赋值给变量bookname。
$bookname = $booktitle[1]; //书名
//print_r ($booktitle);die();不理解的输出这个看看,嘿嘿,帮助大家理解
/*************************************************************************************
*原形:
*规律是:
*ISU是正则的一种模式,该模式是非贪婪模式,也就是说只要匹配上就结束
*************************************************************************************/
$preg = '/
/********************************************************************************
*preg_match_all进行全局正则表达式匹配
*原形:
*
int preg_match_all
*
( string pattern, string subject, array matches [, int flags] )
*意思是:在全局搜索资源变量$preg,得到一个数组赋值给一个变量$zj,这个变量也就是数组了。
*取得其中的资源的时候用标示就可以,不会的看下数组哦!
*汪老师说了,不会数组的给我出去啃书,什么时候会了进来
**********************************************************************************/
preg_match_all($preg, $r, $zj);
//print_r ($zj);die();不理解的输出这个看看,嘿嘿,帮助大家理解
// 计算标题数量,我是问了最后提示大家看又多少章节,采集了多少
$bookzj = count($zj[1]);
//判断你要采集的板式是那种哦,因为内容开始不一样哦,其实可以自动判断的,我也写成了,但是不发布,因为很简单
if ($ver=="new"){
$content_start = "";
$content_end = "";
}
if ($ver=="old"){
$content_start = "";
$content_end = "
";
}
//采集后的文件,然后那来进行处理.这个是设置编码的,为什么是这个呢,因为你看下网站源码,嘿嘿!!!
header("Content-Type:text/html;charset=gb2312");
/*****************************************************************************************
*从1到136页的内容一次合并.这个是最爽的...打个版权,以免有人侵权,嘿嘿,好像我就在侵权哦!!!
*某某一定想杀人,这句意思就是写个版权,创建文件。
*****************************************************************************************/
writer($bookname." 共".$bookzj."节rn帅哥刘并于".date("D M j G:i:s T Y")."为了毕业而设计小说整理收集rn", "./ljy/".$bookname.".txt","w+");
/*****************************************************************************************
*从1到136页的内容一次合并.这个是最爽的...打个版权,以免有人侵权,嘿嘿,好像我就在侵权哦!!!
*某某一定想杀人,这句意思就是写个版权,创建文件。
*****************************************************************************************/
for ($i=0;$i
//echo "http://book.sina.com.cn".$zj[1][$i]".shtml";die();
$str = file_get_contents("http://book.sina.com.cn".$zj[1][$i].".shtml");
preg_match("/(
$title = str_replace("_读书频道_新浪网","",preg_replace("//s","",$title[2]));
/***************************************************************************
*preg_replace执行正则表达式的搜索和替换
*str_replace用法真的不好说,就看例子吧!其实就是一个替换
* str = "abcabc".replace(/a/g, "d"); //结果为 dbcdbc
* str = "abcabc".replace(/a/, "d"); //结果为 dbcabc
***************************************************************************/
preg_match("/(".$content_start.")(.*?)(".$content_end.")/is",$str,$content);
$content = preg_replace("//s","",str_replace("
$content = str_replace("
","",preg_replace("/^[s]*n/is","",$content));
$content = str_replace(" ? "," ",preg_replace("/^[s]*n/is","",$content));
$result = " rn第".($i+1)."节--------".$title."_汪老师就是帅 --------- rn".$content;
//var_dump ($result);die();
writer($result, "./ailaopo/".$bookname.".txt","a+");
echo "小说".$bookname."共".$bookzj."节,现在整理到第".$i."节 _".$title."
";
}
echo "小说".$bookname."共".$bookzj."节 已全部整理完成!";
function writer($content,$url,$mode)
{
$fp = fopen($url, $mode);
fwrite($fp, $content);
fclose($fp);
}
?>

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Lösung: Ihre Organisation verlangt von Ihnen, dass Sie Ihre PIN ändern
Oct 04, 2023 pm 05:45 PM
Lösung: Ihre Organisation verlangt von Ihnen, dass Sie Ihre PIN ändern
Oct 04, 2023 pm 05:45 PM
Auf dem Anmeldebildschirm wird die Meldung „Ihre Organisation hat Sie gebeten, Ihre PIN zu ändern“ angezeigt. Dies geschieht, wenn das PIN-Ablauflimit auf einem Computer erreicht wird, der organisationsbasierte Kontoeinstellungen verwendet und die Kontrolle über persönliche Geräte hat. Wenn Sie Windows jedoch über ein persönliches Konto einrichten, sollte die Fehlermeldung im Idealfall nicht erscheinen. Obwohl dies nicht immer der Fall ist. Die meisten Benutzer, die auf Fehler stoßen, melden dies über ihre persönlichen Konten. Warum fordert mich meine Organisation auf, meine PIN unter Windows 11 zu ändern? Es ist möglich, dass Ihr Konto mit einer Organisation verknüpft ist. Ihr primärer Ansatz sollte darin bestehen, dies zu überprüfen. Die Kontaktaufnahme mit Ihrem Domain-Administrator kann hilfreich sein! Darüber hinaus können falsch konfigurierte lokale Richtlinieneinstellungen oder falsche Registrierungsschlüssel Fehler verursachen. Im Augenblick
 So passen Sie die Fensterrahmeneinstellungen unter Windows 11 an: Farbe und Größe ändern
Sep 22, 2023 am 11:37 AM
So passen Sie die Fensterrahmeneinstellungen unter Windows 11 an: Farbe und Größe ändern
Sep 22, 2023 am 11:37 AM
Windows 11 bringt frisches und elegantes Design in den Vordergrund; die moderne Benutzeroberfläche ermöglicht es Ihnen, feinste Details, wie zum Beispiel Fensterränder, zu personalisieren und zu ändern. In diesem Leitfaden besprechen wir Schritt-für-Schritt-Anleitungen, die Ihnen dabei helfen, eine Umgebung zu erstellen, die Ihrem Stil im Windows-Betriebssystem entspricht. Wie ändere ich die Fensterrahmeneinstellungen? Drücken Sie +, um die Einstellungen-App zu öffnen. WindowsIch gehe zu Personalisierung und klicke auf Farbeinstellungen. Farbänderung Fensterränder Einstellungen Fenster 11" Breite="643" Höhe="500" > Suchen Sie die Option Akzentfarbe auf Titelleiste und Fensterrändern anzeigen und schalten Sie den Schalter daneben um. Um Akzentfarben im Startmenü und in der Taskleiste anzuzeigen Um die Designfarbe im Startmenü und in der Taskleiste anzuzeigen, aktivieren Sie „Design im Startmenü und in der Taskleiste anzeigen“.
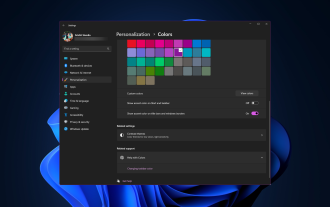 Wie ändere ich die Farbe der Titelleiste unter Windows 11?
Sep 14, 2023 pm 03:33 PM
Wie ändere ich die Farbe der Titelleiste unter Windows 11?
Sep 14, 2023 pm 03:33 PM
Standardmäßig hängt die Farbe der Titelleiste unter Windows 11 vom gewählten Dunkel-/Hell-Design ab. Sie können es jedoch in jede gewünschte Farbe ändern. In diesem Leitfaden besprechen wir Schritt-für-Schritt-Anleitungen für drei Möglichkeiten, wie Sie Ihr Desktop-Erlebnis ändern und personalisieren können, um es optisch ansprechend zu gestalten. Ist es möglich, die Farbe der Titelleiste von aktiven und inaktiven Fenstern zu ändern? Ja, Sie können die Farbe der Titelleiste aktiver Fenster mit der App „Einstellungen“ ändern, oder Sie können die Farbe der Titelleiste inaktiver Fenster mit dem Registrierungseditor ändern. Um diese Schritte zu lernen, fahren Sie mit dem nächsten Abschnitt fort. Wie ändere ich die Farbe der Titelleiste in Windows 11? 1. Drücken Sie in der App „Einstellungen“ +, um das Einstellungsfenster zu öffnen. WindowsIch gehe zu „Personalisierung“ und dann
 OOBELANGUAGE-Fehlerprobleme bei der Reparatur von Windows 11/10
Jul 16, 2023 pm 03:29 PM
OOBELANGUAGE-Fehlerprobleme bei der Reparatur von Windows 11/10
Jul 16, 2023 pm 03:29 PM
Wird auf der Windows Installer-Seite „Ein Problem ist aufgetreten“ zusammen mit der Anweisung „OOBELANGUAGE“ angezeigt? Aufgrund solcher Fehler bricht die Installation von Windows manchmal ab. OOBE bedeutet Out-of-the-Box-Erlebnis. Wie aus der Fehlermeldung hervorgeht, handelt es sich hierbei um ein Problem im Zusammenhang mit der OOBE-Sprachauswahl. Sie müssen sich keine Sorgen machen, Sie können dieses Problem durch eine geschickte Bearbeitung der Registrierung über den OOBE-Bildschirm selbst lösen. Schnelllösung – 1. Klicken Sie unten in der OOBE-App auf die Schaltfläche „Wiederholen“. Dadurch wird der Prozess ohne weitere Probleme fortgesetzt. 2. Verwenden Sie den Netzschalter, um das Herunterfahren des Systems zu erzwingen. Nach dem Neustart des Systems sollte OOBE fortgesetzt werden. 3. Trennen Sie das System vom Internet. Schließen Sie alle Aspekte von OOBE im Offline-Modus ab
 So aktivieren oder deaktivieren Sie die Vorschau von Miniaturansichten in der Taskleiste unter Windows 11
Sep 15, 2023 pm 03:57 PM
So aktivieren oder deaktivieren Sie die Vorschau von Miniaturansichten in der Taskleiste unter Windows 11
Sep 15, 2023 pm 03:57 PM
Miniaturansichten in der Taskleiste können Spaß machen, aber auch ablenken oder stören. Wenn man bedenkt, wie oft Sie mit der Maus über diesen Bereich fahren, haben Sie möglicherweise ein paar Mal versehentlich wichtige Fenster geschlossen. Ein weiterer Nachteil besteht darin, dass es mehr Systemressourcen verbraucht. Wenn Sie also nach einer Möglichkeit suchen, ressourceneffizienter zu arbeiten, zeigen wir Ihnen, wie Sie es deaktivieren können. Wenn Ihre Hardware-Spezifikationen jedoch dafür geeignet sind und Ihnen die Vorschau gefällt, können Sie sie aktivieren. Wie aktiviere ich die Miniaturvorschau der Taskleiste in Windows 11? 1. Tippen Sie in der App „Einstellungen“ auf die Taste und klicken Sie auf „Einstellungen“. Klicken Sie unter Windows auf „System“ und wählen Sie „Info“. Klicken Sie auf Erweiterte Systemeinstellungen. Navigieren Sie zur Registerkarte „Erweitert“ und wählen Sie unter „Leistung“ die Option „Einstellungen“ aus. Wählen Sie „Visuelle Effekte“
 Anleitung zur Anzeigeskalierung unter Windows 11
Sep 19, 2023 pm 06:45 PM
Anleitung zur Anzeigeskalierung unter Windows 11
Sep 19, 2023 pm 06:45 PM
Wir alle haben unterschiedliche Vorlieben, wenn es um die Anzeigeskalierung unter Windows 11 geht. Manche Leute mögen große Symbole, andere mögen kleine Symbole. Wir sind uns jedoch alle einig, dass die richtige Skalierung wichtig ist. Eine schlechte Schriftartenskalierung oder eine Überskalierung von Bildern kann bei der Arbeit ein echter Produktivitätskiller sein. Sie müssen daher wissen, wie Sie sie anpassen können, um die Fähigkeiten Ihres Systems optimal zu nutzen. Vorteile des benutzerdefinierten Zooms: Dies ist eine nützliche Funktion für Personen, die Schwierigkeiten haben, Text auf dem Bildschirm zu lesen. Es hilft Ihnen, mehr gleichzeitig auf dem Bildschirm zu sehen. Sie können benutzerdefinierte Erweiterungsprofile erstellen, die nur für bestimmte Monitore und Anwendungen gelten. Kann dazu beitragen, die Leistung von Low-End-Hardware zu verbessern. Dadurch haben Sie mehr Kontrolle darüber, was auf Ihrem Bildschirm angezeigt wird. So verwenden Sie Windows 11
 10 Möglichkeiten, die Helligkeit unter Windows 11 anzupassen
Dec 18, 2023 pm 02:21 PM
10 Möglichkeiten, die Helligkeit unter Windows 11 anzupassen
Dec 18, 2023 pm 02:21 PM
Die Bildschirmhelligkeit ist ein wesentlicher Bestandteil der Nutzung moderner Computergeräte, insbesondere wenn Sie über einen längeren Zeitraum auf den Bildschirm schauen. Es hilft Ihnen, die Belastung Ihrer Augen zu reduzieren, die Lesbarkeit zu verbessern und Inhalte einfach und effizient anzuzeigen. Abhängig von Ihren Einstellungen kann es jedoch manchmal schwierig sein, die Helligkeit zu verwalten, insbesondere unter Windows 11 mit den neuen Änderungen an der Benutzeroberfläche. Wenn Sie Probleme beim Anpassen der Helligkeit haben, finden Sie hier alle Möglichkeiten, die Helligkeit unter Windows 11 zu verwalten. So ändern Sie die Helligkeit unter Windows 11 [10 Möglichkeiten erklärt] Benutzer eines einzelnen Monitors können die folgenden Methoden verwenden, um die Helligkeit unter Windows 11 anzupassen. Hierzu zählen sowohl Desktop-Systeme mit einem einzelnen Monitor als auch Laptops. Lasst uns beginnen. Methode 1: Verwenden Sie das Action Center. Das Action Center ist zugänglich
 So beheben Sie den Aktivierungsfehlercode 0xc004f069 in Windows Server
Jul 22, 2023 am 09:49 AM
So beheben Sie den Aktivierungsfehlercode 0xc004f069 in Windows Server
Jul 22, 2023 am 09:49 AM
Der Aktivierungsprozess unter Windows nimmt manchmal eine plötzliche Wendung und zeigt eine Fehlermeldung mit diesem Fehlercode 0xc004f069 an. Obwohl der Aktivierungsprozess online erfolgt, kann dieses Problem bei einigen älteren Systemen mit Windows Server auftreten. Führen Sie diese ersten Prüfungen durch. Wenn sie Ihnen bei der Aktivierung Ihres Systems nicht weiterhelfen, fahren Sie mit der Hauptlösung fort, um das Problem zu beheben. Problemumgehung – Schließen Sie die Fehlermeldung und das Aktivierungsfenster. Starten Sie dann Ihren Computer neu. Wiederholen Sie den Windows-Aktivierungsprozess noch einmal von Grund auf. Fix 1 – Aktivierung über das Terminal. Aktivieren Sie das Windows Server Edition-System über das CMD-Terminal. Stufe – 1 Überprüfen Sie die Windows Server-Version. Sie müssen überprüfen, welchen W-Typ Sie verwenden
