

浅谈Python单向链表的实现

链表由一系列不必在内存中相连的结构构成,这些对象按线性顺序排序。每个结构含有表元素和指向后继元素的指针。最后一个单元的指针指向NULL。为了方便链表的删除与插入操作,可以为链表添加一个表头。
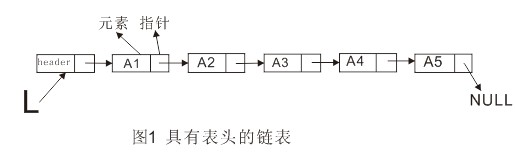
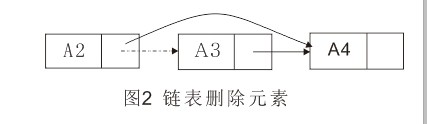
删除操作可以通过修改一个指针来实现。
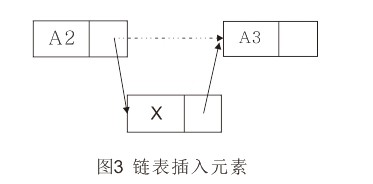
插入操作需要执行两次指针调整。
1. 单向链表的实现
1.1 Node实现
每个Node分为两部分。一部分含有链表的元素,可以称为数据域;另一部分为一指针,指向下一个Node。
class Node():
__slots__=['_item','_next'] #限定Node实例的属性
def __init__(self,item):
self._item=item
self._next=None #Node的指针部分默认指向None
def getItem(self):
return self._item
def getNext(self):
return self._next
def setItem(self,newitem):
self._item=newitem
def setNext(self,newnext):
self._next=newnext
1.2 SinglelinkedList的实现
class SingleLinkedList():
def __init__(self):
self._head=None #初始化链表为空表
self._size=0
1.3 检测链表是否为空
def isEmpty(self): return self._head==None
1.4 add在链表前端添加元素
def add(self,item): temp=Node(item) temp.setNext(self._head) self._head=temp
1.5 append在链表尾部添加元素
def append(self,item):
temp=Node(item)
if self.isEmpty():
self._head=temp #若为空表,将添加的元素设为第一个元素
else:
current=self._head
while current.getNext()!=None:
current=current.getNext() #遍历链表
current.setNext(temp) #此时current为链表最后的元素
1.6 search检索元素是否在链表中
def search(self,item):
current=self._head
founditem=False
while current!=None and not founditem:
if current.getItem()==item:
founditem=True
else:
current=current.getNext()
return founditem
1.7 index索引元素在链表中的位置
def index(self,item):
current=self._head
count=0
found=None
while current!=None and not found:
count+=1
if current.getItem()==item:
found=True
else:
current=current.getNext()
if found:
return count
else:
raise ValueError,'%s is not in linkedlist'%item
1.8 remove删除链表中的某项元素
def remove(self,item):
current=self._head
pre=None
while current!=None:
if current.getItem()==item:
if not pre:
self._head=current.getNext()
else:
pre.setNext(current.getNext())
break
else:
pre=current
current=current.getNext()
1.9 insert链表中插入元素
def insert(self,pos,item):
if pos<=1:
self.add(item)
elif pos>self.size():
self.append(item)
else:
temp=Node(item)
count=1
pre=None
current=self._head
while count<pos:
count+=1
pre=current
current=current.getNext()
pre.setNext(temp)
temp.setNext(current)
全部代码
class Node():
__slots__=['_item','_next']
def __init__(self,item):
self._item=item
self._next=None
def getItem(self):
return self._item
def getNext(self):
return self._next
def setItem(self,newitem):
self._item=newitem
def setNext(self,newnext):
self._next=newnext
class SingleLinkedList():
def __init__(self):
self._head=None #初始化为空链表
def isEmpty(self):
return self._head==None
def size(self):
current=self._head
count=0
while current!=None:
count+=1
current=current.getNext()
return count
def travel(self):
current=self._head
while current!=None:
print current.getItem()
current=current.getNext()
def add(self,item):
temp=Node(item)
temp.setNext(self._head)
self._head=temp
def append(self,item):
temp=Node(item)
if self.isEmpty():
self._head=temp #若为空表,将添加的元素设为第一个元素
else:
current=self._head
while current.getNext()!=None:
current=current.getNext() #遍历链表
current.setNext(temp) #此时current为链表最后的元素
def search(self,item):
current=self._head
founditem=False
while current!=None and not founditem:
if current.getItem()==item:
founditem=True
else:
current=current.getNext()
return founditem
def index(self,item):
current=self._head
count=0
found=None
while current!=None and not found:
count+=1
if current.getItem()==item:
found=True
else:
current=current.getNext()
if found:
return count
else:
raise ValueError,'%s is not in linkedlist'%item
def remove(self,item):
current=self._head
pre=None
while current!=None:
if current.getItem()==item:
if not pre:
self._head=current.getNext()
else:
pre.setNext(current.getNext())
break
else:
pre=current
current=current.getNext()
def insert(self,pos,item):
if pos<=1:
self.add(item)
elif pos>self.size():
self.append(item)
else:
temp=Node(item)
count=1
pre=None
current=self._head
while count<pos:
count+=1
pre=current
current=current.getNext()
pre.setNext(temp)
temp.setNext(current)
if __name__=='__main__':
a=SingleLinkedList()
for i in range(1,10):
a.append(i)
print a.size()
a.travel()
print a.search(6)
print a.index(5)
a.remove(4)
a.travel()
a.insert(4,100)
a.travel()

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Die Geschwindigkeit der mobilen XML zu PDF hängt von den folgenden Faktoren ab: der Komplexität der XML -Struktur. Konvertierungsmethode für mobile Hardware-Konfiguration (Bibliothek, Algorithmus) -Codierungsoptimierungsmethoden (effiziente Bibliotheken, Optimierung von Algorithmen, Cache-Daten und Nutzung von Multi-Threading). Insgesamt gibt es keine absolute Antwort und es muss gemäß der spezifischen Situation optimiert werden.
 Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Mit einer einzigen Anwendung ist es unmöglich, XML -zu -PDF -Konvertierung direkt auf Ihrem Telefon zu vervollständigen. Es ist erforderlich, Cloud -Dienste zu verwenden, die in zwei Schritten erreicht werden können: 1. XML in PDF in der Cloud, 2. Zugriff auf die konvertierte PDF -Datei auf dem Mobiltelefon konvertieren oder herunterladen.
 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 09:45 PM
Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 09:45 PM
Es gibt keine App, die alle XML -Dateien in PDFs umwandeln kann, da die XML -Struktur flexibel und vielfältig ist. Der Kern von XML zu PDF besteht darin, die Datenstruktur in ein Seitenlayout umzuwandeln, für das XML analysiert und PDF generiert werden muss. Zu den allgemeinen Methoden gehören das Parsen von XML mithilfe von Python -Bibliotheken wie ElementTree und das Generieren von PDFs unter Verwendung der ReportLab -Bibliothek. Für komplexe XML kann es erforderlich sein, XSLT -Transformationsstrukturen zu verwenden. Wenn Sie die Leistung optimieren, sollten Sie Multithread- oder Multiprozesse verwenden und die entsprechende Bibliothek auswählen.
 Empfohlenes XML -Formatierungswerkzeug
Apr 02, 2025 pm 09:03 PM
Empfohlenes XML -Formatierungswerkzeug
Apr 02, 2025 pm 09:03 PM
XML -Formatierungs -Tools können Code nach Regeln eingeben, um die Lesbarkeit und das Verständnis zu verbessern. Achten Sie bei der Auswahl eines Tools auf die Anpassungsfunktionen, den Umgang mit besonderen Umständen, die Leistung und die Benutzerfreundlichkeit. Zu den häufig verwendeten Werkzeugtypen gehören Online-Tools, IDE-Plug-Ins und Befehlszeilen-Tools.
 So konvertieren Sie XML in Bilder
Apr 03, 2025 am 07:39 AM
So konvertieren Sie XML in Bilder
Apr 03, 2025 am 07:39 AM
XML kann mithilfe eines XSLT -Konverters oder einer Bildbibliothek in Bilder konvertiert werden. XSLT -Konverter: Verwenden Sie einen XSLT -Prozessor und Stylesheet, um XML in Bilder zu konvertieren. Bildbibliothek: Verwenden Sie Bibliotheken wie Pil oder Imagemagick, um Bilder aus XML -Daten zu erstellen, z. B. Zeichnen von Formen und Text.
 Wie konvertieren Sie XML mit hoher Qualität auf Ihr Telefon in PDF?
Apr 02, 2025 pm 09:48 PM
Wie konvertieren Sie XML mit hoher Qualität auf Ihr Telefon in PDF?
Apr 02, 2025 pm 09:48 PM
Konvertieren Sie XML in PDF mit hoher Qualität auf Ihrem Mobiltelefon müssen: XML in der Cloud analysieren und PDFs mithilfe einer serverlosen Computerplattform generieren. Wählen Sie eine effiziente Bibliothek für XML -Parser- und PDF -Generation. Fehler korrekt behandeln. Nutzen Sie die Cloud -Computing -Leistung voll, um schwere Aufgaben auf Ihrem Telefon zu vermeiden. Passen Sie die Komplexität gemäß den Anforderungen an, einschließlich der Verarbeitung komplexer XML-Strukturen, der Erzeugung von mehrseitigen PDFs und dem Hinzufügen von Bildern. Drucken Sie Protokollinformationen zum Debuggen. Optimieren Sie die Leistung, wählen Sie effiziente Parser- und PDF -Bibliotheken aus und können asynchrone Programmier- oder Vorverarbeitungs -XML -Daten verwenden. Gewährleisten Sie eine gute Codequalität und -wartbarkeit.
 Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 08:54 PM
Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 08:54 PM
Eine Anwendung, die XML direkt in PDF konvertiert, kann nicht gefunden werden, da es sich um zwei grundlegend unterschiedliche Formate handelt. XML wird zum Speichern von Daten verwendet, während PDF zur Anzeige von Dokumenten verwendet wird. Um die Transformation abzuschließen, können Sie Programmiersprachen und Bibliotheken wie Python und ReportLab verwenden, um XML -Daten zu analysieren und PDF -Dokumente zu generieren.
