

编写Python脚本抓取网络小说来制作自己的阅读器

你是否苦恼于网上无法下载的“小说在线阅读”内容?或是某些文章的内容让你很有收藏的冲动,却找不到一个下载的链接?是不是有种自己写个程序把全部搞定的冲动?是不是学了 python,想要找点东西大展拳脚,告诉别人“哥可是很牛逼的!”?那就让我们开始吧! 哈哈~
好吧,我就是最近写 Yii 写多了,想找点东西调剂一下.... = =
本项目以研究为目的,所有版权问题我们都是站在作者的一边,以看盗版小说为目的的读者们请自行面壁!
说了这么多,我们要做的就是把小说正文的内容从网页上爬下来,我们的研究对象是全本小说网....再次声明,不对任何版权负责....
一开始先做最基础的内容,就是把某一章的内容抓取下来。
环境:Ubuntu, Python 2.7
基础知识
这个程序涉及到的知识点有几个,在这里列出来,不详细讲,有疑问的直接百度会有一堆的。
1.urllib2 模块的 request 对像来设置 HTTP 请求,包括抓取的 url,和伪装浏览器的代理。然后就是 urlopen 和 read 方法,都很好理解。
2.chardet 模块,用于检测网页的编码。在网页上抓取数据很容易遇到乱码的问题,为了判断网页是 gtk 编码还是 utf-8 ,所以用 chardet 的 detect 函数进行检测。在用 Windows 的同学可以在这里 http://download.csdn.net/detail/jcjc918/8231371 下载,解压到 python 的 lib 目录下就好。
3. decode 函数将字符串从某种编码转为 unicode 字符,而 encode 把 unicode 字符转为指定编码格式的字符串。
4. re 模块正则表达式的应用。search 函数可以找到和正则表达式对应匹配的一项,而 replace 则是把匹配到的字符串替换。
思路分析:
我们选取的 url 是 http://www.quanben.com/xiaoshuo/0/910/59302.html,斗罗大陆的第一章。你可以查看网页的源代码,会发现只有一个 content 标签包含了所有章节的内容,所以可以用正则把 content 的标签匹配到,抓取下来。试着把这一部分内容打印出来,会发现很多
和 ,
要替换成换行符, 是网页中的占位符,即空格,替换成空格就好。这样一章的内容就很美观的出来了。完整起见,同样用正则把标题爬下来。
程序
# -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一个章节
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshuo/0/910/59302.html";
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先检测网页的字符编码,最后统一转为 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取标题
my_title = re.search('<h1 id="">(.*?)</h1>',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('<div.*?id="htmlContent" class="contentbox">(.*?)<div',unicodePage,re.S)
my_content = my_content.group(1)
except:
print "内容 HTML 变化,请重新分析!"
return False
#替换正文中的网页代码
my_content = my_content.replace("<br />","\n")
my_content = my_content.replace(" "," ")
#用字典存储一章的标题和内容
onePage = {'title':my_title,'content':my_content}
return onePage
# 用于加载章节
def LoadPage(self):
try:
# 获取新的章节
myPage = self.GetPage()
if myPage == False:
print '抓取失败!'
return False
self.pages.append(myPage)
except:
print '无法连接服务器!'
#显示一章
def ShowPage(self,curPage):
print curPage['title']
print curPage['content']
def Start(self):
print u'开始阅读......\n'
#把这一页加载进来
self.LoadPage()
# 如果self的pages数组中存有元素
if self.pages:
nowPage = self.pages[0]
self.ShowPage(nowPage)
#----------- 程序的入口处 -----------
print u"""
---------------------------------------
程序:阅读呼叫转移
版本:0.1
作者:angryrookie
日期:2014-07-05
语言:Python 2.7
功能:按下回车浏览章节
---------------------------------------
"""
print u'请按下回车:'
raw_input()
myBook = Book_Spider()
myBook.Start()
程序运行完在我这里可是很好看的,不信请看:^_^
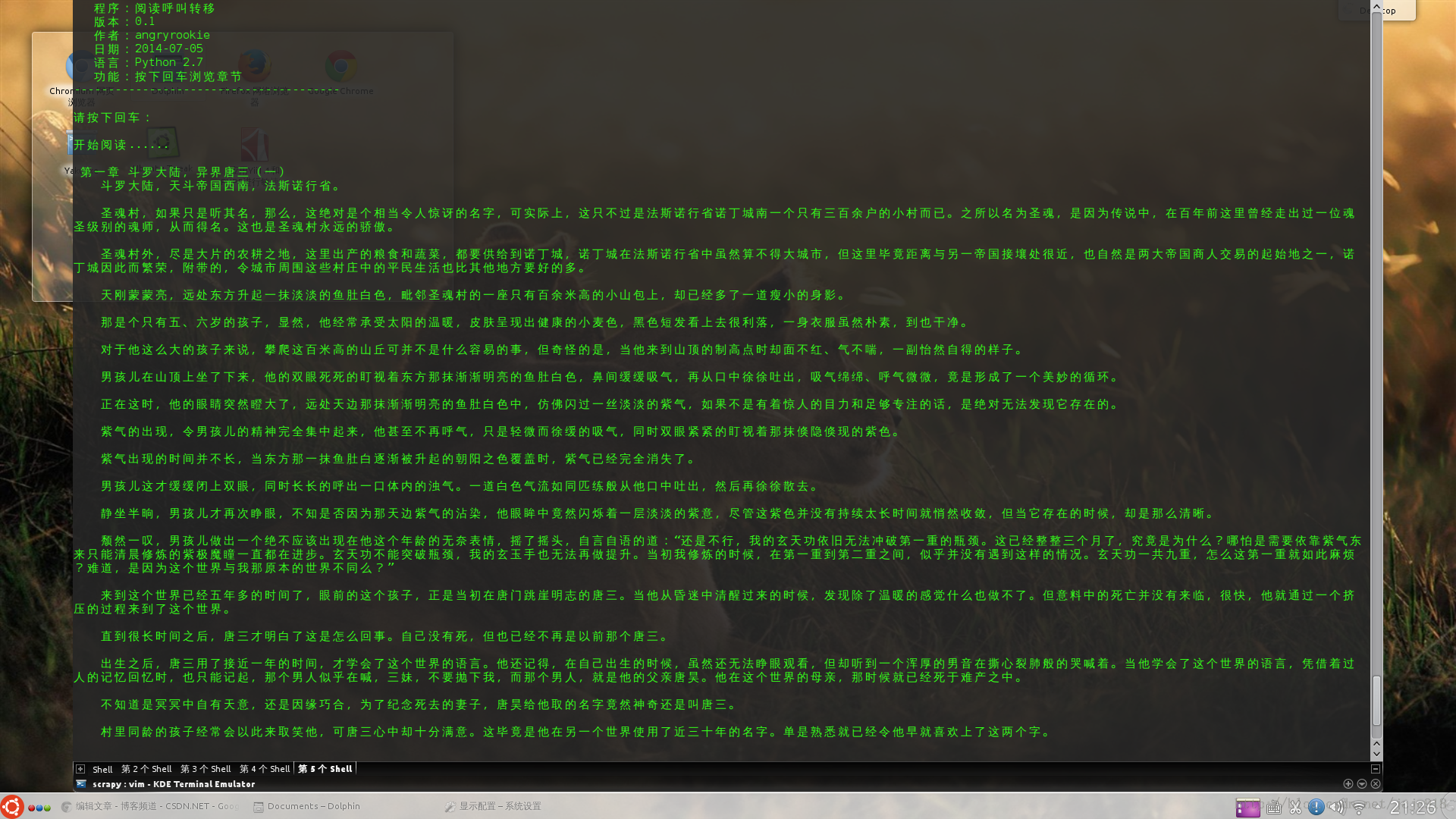
理所当然地,接下来我们要把整本小说都爬下来。首先,我们要把程序从原来的读完一章就结束,改成读完一章之后可以继续进行下一章的阅读。
注意到每个小说章节的网页下面都有下一页的链接。通过查看网页源代码,稍微整理一下( 不显示了),我们可以看到这一部分的 HTML 是下面这种格式的:
<div id="footlink"> <script type="text/javascript" charset="utf-8" src="/scripts/style5.js"></script> <a href="http://www.quanben.com/xiaoshuo/0/910/59301.html">上一页</a> <a href="http://www.quanben.com/xiaoshuo/0/910/">返回目录</a> <a href="http://www.quanben.com/xiaoshuo/0/910/59303.html">下一页</a> </div>
上一页 、返回目录、下一页都在一个 id 为 footlink 的 div 中,如果想要对每个链接进行匹配的话,会抓取到网页上大量的其他链接,但是 footlink 的 div 只有一个啊!我们可以把这个 div 匹配到,抓下来,然后在这个抓下来的 div 里面再匹配 的链接,这时就只有三个了。只要取最后一个链接就是下一页的 url 的,用这个 url 更新我们抓取的目标 url ,这样就能一直抓到下一页。用户阅读逻辑为每读一个章节后,等待用户输入,如果是 quit 则退出程序,否则显示下一章。
基础知识:
上一篇的基础知识加上 Python 的 thread 模块.
源代码:
# -*- coding: utf-8 -*-
import urllib2
import re
import thread
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
self.page = 1
self.flag = True
self.url = "http://www.quanben.com/xiaoshuo/10/10412/2095096.html"
# 将抓取一个章节
def GetPage(self):
myUrl = self.url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
# 找出 id="content"的div标记
try:
#抓取标题
my_title = re.search('<h1 id="">(.*?)</h1>',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('<div.*?id="htmlContent" class="contentbox">(.*?)<div',unicodePage,re.S)
my_content = my_content.group(1)
except:
print "内容 HTML 变化,请重新分析!"
return False
my_content = my_content.replace("<br />","\n")
my_content = my_content.replace(" "," ")
#用字典存储一章的标题和内容
onePage = {'title':my_title,'content':my_content}
try:
#找到页面下方的连接区域
foot_link = re.search('<div.*?class="chapter_Turnpage">(.*?)</div>',unicodePage,re.S)
foot_link = foot_link.group(1)
#在连接的区域找下一页的连接,根据网页特点为第三个
nextUrl = re.findall(u'<a.*?href="(.*?)".*?>(.*?)</a>',foot_link,re.S)
nextUrl = nextUrl[2][0]
# 更新下一次进行抓取的链接
self.url = nextUrl
except:
print "底部链接变化,请重新分析!"
return False
return onePage
# 用于加载章节
def LoadPage(self):
while self.flag:
if(len(self.pages) - self.page < 3):
try:
# 获取新的页面
myPage = self.GetPage()
if myPage == False:
print '抓取失败!'
self.flag = False
self.pages.append(myPage)
except:
print '无法连接网页!'
self.flag = False
#显示一章
def ShowPage(self,curPage):
print curPage['title']
print curPage['content']
print "\n"
user_input = raw_input("当前是第 %d 章,回车读取下一章或者输入 quit 退出:" % self.page)
if(user_input == 'quit'):
self.flag = False
print "\n"
def Start(self):
print u'开始阅读......\n'
# 新建一个线程
thread.start_new_thread(self.LoadPage,())
# 如果self的page数组中存有元素
while self.flag:
if self.page <= len(self.pages):
nowPage = self.pages[self.page-1]
self.ShowPage(nowPage)
self.page += 1
print u"本次阅读结束"
#----------- 程序的入口处 -----------
print u"""
---------------------------------------
程序:阅读呼叫转移
版本:0.2
作者:angryrookie
日期:2014-07-07
语言:Python 2.7
功能:按下回车浏览下一章节
---------------------------------------
"""
print u'请按下回车:'
raw_input(' ')
myBook = Book_Spider()
myBook.Start()
现在这么多小说阅读器,我们只需要把我们要的小说抓取到本地的 txt 文件里就好了,然后自己选个阅读器看,怎么整都看你了。
其实上个程序我们已经完成了大部分逻辑,我们接下来的改动只需要把抓取到每一章的时候不用显示出来,而是存入 txt 文件之中。另外一个是程序是不断地根据下一页的 Url 进行抓取的,那么什么时候结束呢?注意当到达小说的最后一章时下一页的链接是和返回目录的链接是一样的。所以我们抓取一个网页的时候就把这两个链接拿出来,只要出现两个链接一样的时候,就停止抓取。最后就是我们这个程序不需要多线程了,我们只要一个不断在抓取小说页面的线程就行了。
不过,小说章节多一点时候,等待完成的时间会有点久。目前就不考虑这么多了,基本功能完成就 OK....
基础知识:前面的基础知识 - 多线程知识 + 文件操作知识。
源代码:
# -*- coding:utf-8 -*-
import urllib2
import urllib
import re
import thread
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
self.page = 1
self.flag = True
self.url = "http://www.quanben.com/xiaoshuo/0/910/59302.html"
# 将抓取一个章节
def GetPage(self):
myUrl = self.url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
# 找出 id="content"的div标记
try:
#抓取标题
my_title = re.search('<h1 id="">(.*?)</h1>',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '标题 HTML 变化,请重新分析!'
return False
try:
#抓取章节内容
my_content = re.search('<div.*?id="htmlContent" class="contentbox">(.*?)<div',unicodePage,re.S)
my_content = my_content.group(1)
except:
print "内容 HTML 变化,请重新分析!"
return False
my_content = my_content.replace("<br />","\n")
my_content = my_content.replace(" "," ")
#用字典存储一章的标题和内容
onePage = {'title':my_title,'content':my_content}
try:
#找到页面下方的连接区域
foot_link = re.search('<div.*?class="chapter_Turnpage">(.*?)</div>',unicodePage,re.S)
foot_link = foot_link.group(1)
#在连接的区域找下一页的连接,根据网页特点为第三个
nextUrl = re.findall(u'<a.*?href="(.*?)".*?>(.*?)</a>',foot_link,re.S)
#目录链接
dir_url = nextUrl[1][0]
nextUrl = nextUrl[2][0]
# 更新下一次进行抓取的链接
self.url = nextUrl
if(dir_url == nextUrl):
self.flag = False
return onePage
except:
print "底部链接变化,请重新分析!"
return False
# 用于加载章节
def downloadPage(self):
f_txt = open(u"斗罗大陆.txt",'w+')
while self.flag:
try:
# 获取新的页面
myPage = self.GetPage()
if myPage == False:
print '抓取失败!'
self.flag = False
title = myPage['title'].encode('utf-8')
content = myPage['content'].encode('utf-8')
f_txt.write(title + '\n\n')
f_txt.write(content)
f_txt.write('\n\n\n')
print "已下载 ",myPage['title']
except:
print '无法连接服务器!'
self.flag = False
f_txt.close()
def Start(self):
print u'开始下载......\n'
self.downloadPage()
print u"下载完成"
#----------- 程序的入口处 -----------
print u"""
---------------------------------------
程序:阅读呼叫转移
版本:0.3
作者:angryrookie
日期:2014-07-08
语言:Python 2.7
功能:按下回车开始下载
---------------------------------------
"""
print u'请按下回车:'
raw_input(' ')
myBook = Book_Spider()
myBook.Start()

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Wer bekommt mehr Python oder JavaScript bezahlt?
Apr 04, 2025 am 12:09 AM
Es gibt kein absolutes Gehalt für Python- und JavaScript -Entwickler, je nach Fähigkeiten und Branchenbedürfnissen. 1. Python kann mehr in Datenwissenschaft und maschinellem Lernen bezahlt werden. 2. JavaScript hat eine große Nachfrage in der Entwicklung von Front-End- und Full-Stack-Entwicklung, und sein Gehalt ist auch beträchtlich. 3. Einflussfaktoren umfassen Erfahrung, geografische Standort, Unternehmensgröße und spezifische Fähigkeiten.
 Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Ist DifferiDItistinginginging verwandt?
Apr 03, 2025 pm 10:30 PM
Obwohl eindeutig und unterschiedlich mit der Unterscheidung zusammenhängen, werden sie unterschiedlich verwendet: Unterschieds (Adjektiv) beschreibt die Einzigartigkeit der Dinge selbst und wird verwendet, um Unterschiede zwischen den Dingen zu betonen; Das Unterscheidungsverhalten oder die Fähigkeit des Unterschieds ist eindeutig (Verb) und wird verwendet, um den Diskriminierungsprozess zu beschreiben. In der Programmierung wird häufig unterschiedlich, um die Einzigartigkeit von Elementen in einer Sammlung darzustellen, wie z. B. Deduplizierungsoperationen; Unterscheidet spiegelt sich in der Gestaltung von Algorithmen oder Funktionen wider, wie z. B. die Unterscheidung von ungeraden und sogar Zahlen. Bei der Optimierung sollte der eindeutige Betrieb den entsprechenden Algorithmus und die Datenstruktur auswählen, während der unterschiedliche Betrieb die Unterscheidung zwischen logischer Effizienz optimieren und auf das Schreiben klarer und lesbarer Code achten sollte.
 Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
Wie versteht man! X in c?
Apr 03, 2025 pm 02:33 PM
! X Understanding! X ist ein logischer Nicht-Operator in der C-Sprache. Es booleschen den Wert von x, dh wahre Änderungen zu falschen, falschen Änderungen an True. Aber seien Sie sich bewusst, dass Wahrheit und Falschheit in C eher durch numerische Werte als durch Boolesche Typen dargestellt werden, ungleich Null wird als wahr angesehen und nur 0 wird als falsch angesehen. Daher handelt es sich um negative Zahlen wie positive Zahlen und gilt als wahr.
 Können C -Sprachbenutzer -Identifikatoren Räume enthalten?
Apr 03, 2025 pm 01:51 PM
Können C -Sprachbenutzer -Identifikatoren Räume enthalten?
Apr 03, 2025 pm 01:51 PM
C -Sprachkennungen können keine Leerzeichen enthalten, da sie Verwirrung und Schwierigkeiten bei der Aufrechterhaltung verursachen können. Die spezifischen Regeln sind wie folgt: Sie müssen mit Buchstaben oder Unterstrichen beginnen. Kann Buchstaben, Zahlen oder Unterstriche enthalten. Kann illegale Zeichen nicht enthalten (wie besondere Symbole).
 Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Was bedeutet Summe in der C -Sprache?
Apr 03, 2025 pm 02:36 PM
Es gibt keine integrierte Summenfunktion in C für die Summe, kann jedoch implementiert werden durch: Verwenden einer Schleife, um Elemente nacheinander zu akkumulieren; Verwenden eines Zeigers, um auf die Elemente nacheinander zuzugreifen und zu akkumulieren; Betrachten Sie für große Datenvolumina parallele Berechnungen.
 Wie kann ich die Schlangennomenklatur in der C -Sprache anwenden?
Apr 03, 2025 pm 01:03 PM
Wie kann ich die Schlangennomenklatur in der C -Sprache anwenden?
Apr 03, 2025 pm 01:03 PM
In der C -Sprache ist die Snake -Nomenklatur eine Konvention zum Codierungsstil, bei der Unterstriche zum Verbinden mehrerer Wörter mit Variablennamen oder Funktionsnamen angeschlossen werden, um die Lesbarkeit zu verbessern. Obwohl es die Zusammenstellung und den Betrieb nicht beeinträchtigen wird, müssen langwierige Benennung, IDE -Unterstützung und historisches Gepäck berücksichtigt werden.
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
