

用Python的pandas框架操作Excel文件中的数据教程

引言
本文的目的,是向您展示如何使用pandas 来执行一些常见的Excel任务。有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要。作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的。
有道理吧?让我们开始吧。
为某行添加求和项
我要介绍的第一项任务是把某几列相加然后添加一个总和栏。
首先我们将excel 数据 导入到pandas数据框架中。
import pandas as pd
import numpy as np
df = pd.read_excel("excel-comp-data.xlsx")
df.head()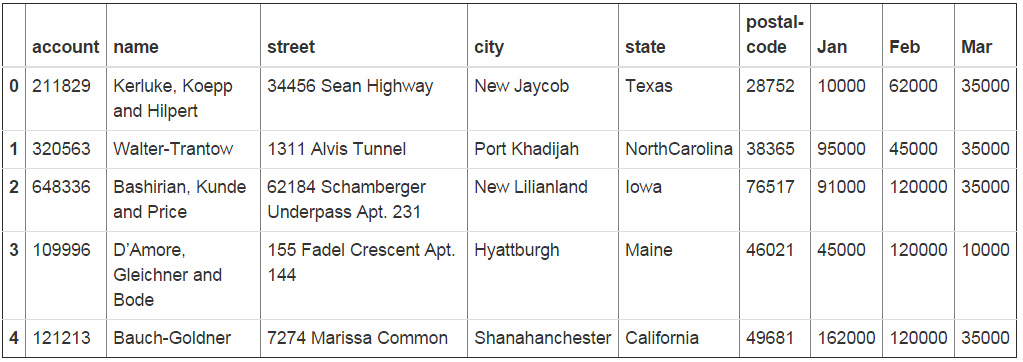
我们想要添加一个总和栏来显示Jan、Feb和Mar三个月的销售总额。
在Excel和pandas中这都是简单直接的。对于Excel,我在J列中添加了公式sum(G2:I2)。在Excel中看上去是这样的:
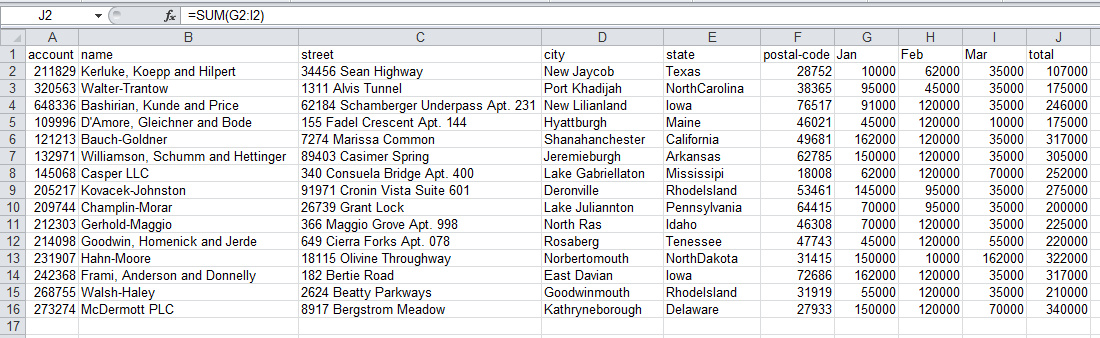
下面,我们是这样在pandas中操作的:
df["total"] = df["Jan"] + df["Feb"] + df["Mar"] df.head()
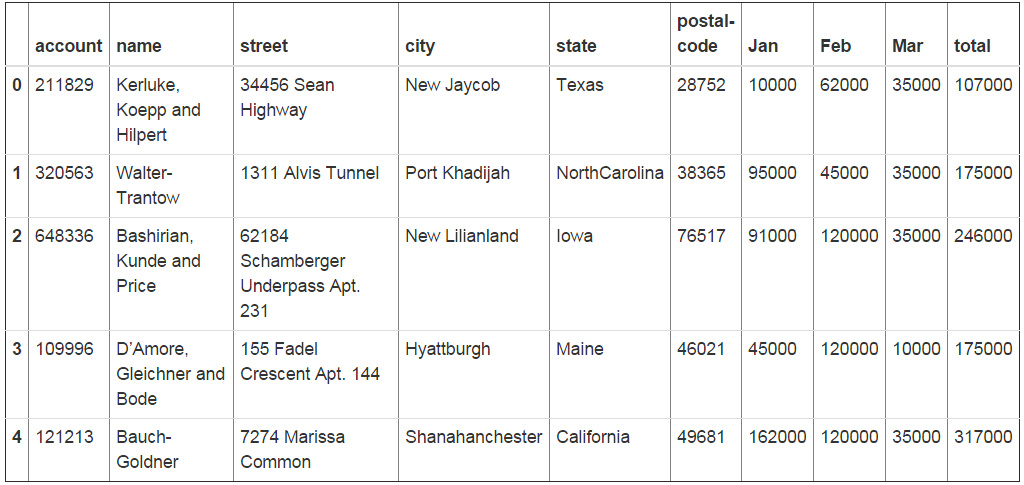
接下来,让我们对各列计算一些汇总信息以及其他值。如下Excel表所示,我们要做这些工作:
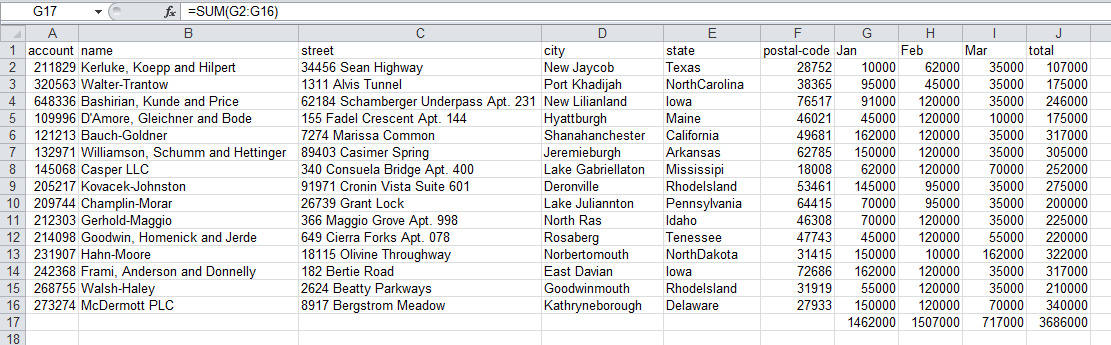
如你所见,我们在表示月份的列的第17行添加了SUM(G2:G16),来取得每月的总和。
进行在pandas中进行列级别的分析很简单。下面是一些例子:
df["Jan"].sum(), df["Jan"].mean(),df["Jan"].min(),df["Jan"].max() (1462000, 97466.666666666672, 10000, 162000)
现在我们要把每月的总和相加得到它们的和。这里pandas和Excel有点不同。在Excel的单元格里把每个月的总和相加很简单。由于pandas需要维护整个DataFrame的完整性,所以需要一些额外的步骤。
首先,建立所有列的总和栏
sum_row=df[["Jan","Feb","Mar","total"]].sum() sum_row Jan 1462000 Feb 1507000 Mar 717000 total 3686000 dtype: int64
这很符合直觉,不过如果你希望将总和值显示为表格中的单独一行,你还需要做一些微调。
我们需要把数据进行变换,把这一系列数字转换为DataFrame,这样才能更加容易的把它合并进已经存在的数据中。T 函数可以让我们把按行排列的数据变换为按列排列。
df_sum=pd.DataFrame(data=sum_row).T df_sum
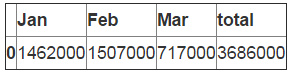
在计算总和之前我们要做的最后一件事情是添加丢失的列。我们使用reindex来帮助我们完成。技巧是添加全部的列然后让pandas去添加所有缺失的数据。
df_sum=df_sum.reindex(columns=df.columns) df_sum

现在我们已经有了一个格式良好的DataFrame,我们可以使用append来把它加入到已有的内容中。
df_final=df.append(df_sum,ignore_index=True) df_final.tail()
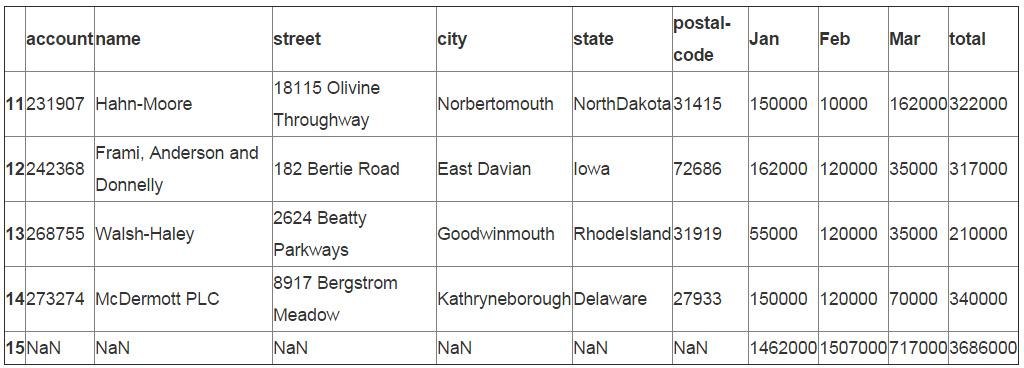
额外的数据变换
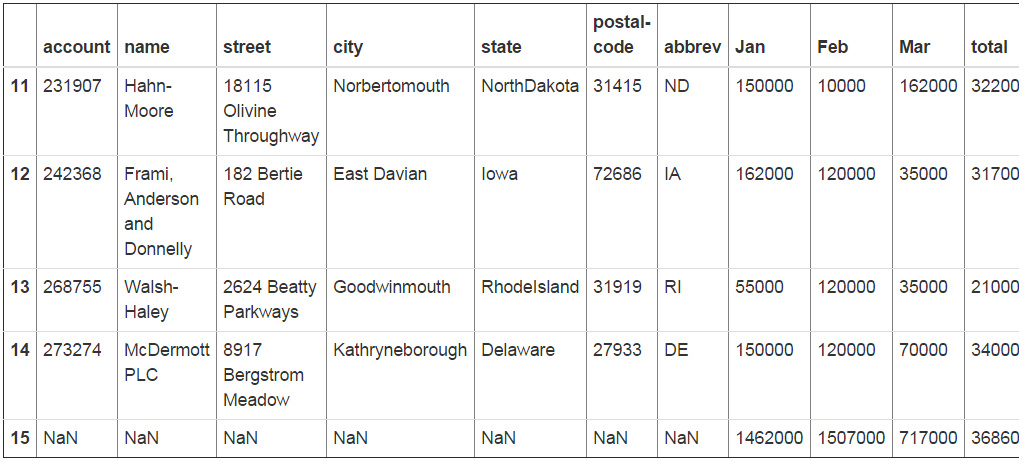
另外一个例子,让我们尝试给数据集添加状态的缩写。
对于Excel,最简单的方式是添加一个新的列,对州名使用vlookup函数并填充缩写栏。
我进行了这样的操作,下面是其结果的截图:
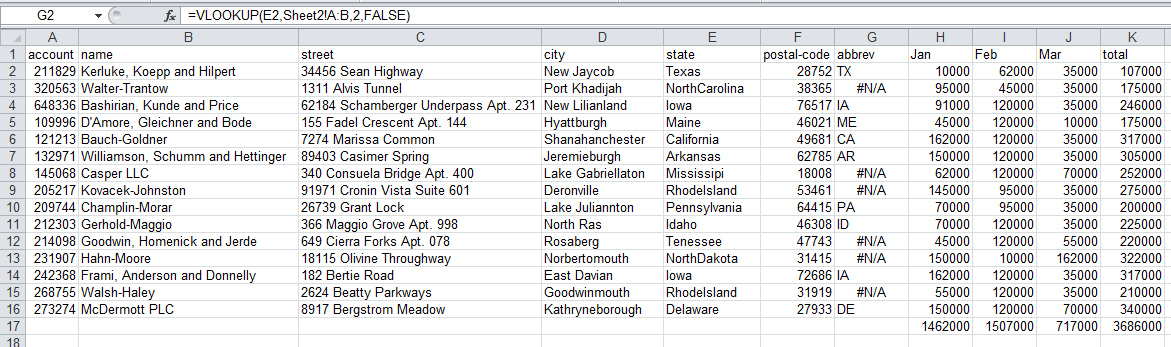
你可以注意到,在进行了vlookup后,有一些数值并没有被正确的取得。这是因为我们拼错了一些州的名字。在Excel中处理这一问题是一个巨大的挑战(对于大型数据集而言)
幸运的是,使用pandas我们可以利用强大的python生态系统。考虑如何解决这类麻烦的数据问题,我考虑进行一些模糊文本匹配来决定正确的值。
幸运的是其他人已经做了很多这方面的工作。fuzzy wuzzy库包含一些非常有用的函数来解决这类问题。首先要确保你安装了他。
我们需要的另外一段代码是州名与其缩写的映射表。而不是亲自去输入它们,谷歌一下你就能找到这段代码code。
首先导入合适的fuzzywuzzy函数并且定义我们的州名映射表。
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
state_to_code = {"VERMONT": "VT", "GEORGIA": "GA", "IOWA": "IA", "Armed Forces Pacific": "AP", "GUAM": "GU",
"KANSAS": "KS", "FLORIDA": "FL", "AMERICAN SAMOA": "AS", "NORTH CAROLINA": "NC", "HAWAII": "HI",
"NEW YORK": "NY", "CALIFORNIA": "CA", "ALABAMA": "AL", "IDAHO": "ID", "FEDERATED STATES OF MICRONESIA": "FM",
"Armed Forces Americas": "AA", "DELAWARE": "DE", "ALASKA": "AK", "ILLINOIS": "IL",
"Armed Forces Africa": "AE", "SOUTH DAKOTA": "SD", "CONNECTICUT": "CT", "MONTANA": "MT", "MASSACHUSETTS": "MA",
"PUERTO RICO": "PR", "Armed Forces Canada": "AE", "NEW HAMPSHIRE": "NH", "MARYLAND": "MD", "NEW MEXICO": "NM",
"MISSISSIPPI": "MS", "TENNESSEE": "TN", "PALAU": "PW", "COLORADO": "CO", "Armed Forces Middle East": "AE",
"NEW JERSEY": "NJ", "UTAH": "UT", "MICHIGAN": "MI", "WEST VIRGINIA": "WV", "WASHINGTON": "WA",
"MINNESOTA": "MN", "OREGON": "OR", "VIRGINIA": "VA", "VIRGIN ISLANDS": "VI", "MARSHALL ISLANDS": "MH",
"WYOMING": "WY", "OHIO": "OH", "SOUTH CAROLINA": "SC", "INDIANA": "IN", "NEVADA": "NV", "LOUISIANA": "LA",
"NORTHERN MARIANA ISLANDS": "MP", "NEBRASKA": "NE", "ARIZONA": "AZ", "WISCONSIN": "WI", "NORTH DAKOTA": "ND",
"Armed Forces Europe": "AE", "PENNSYLVANIA": "PA", "OKLAHOMA": "OK", "KENTUCKY": "KY", "RHODE ISLAND": "RI",
"DISTRICT OF COLUMBIA": "DC", "ARKANSAS": "AR", "MISSOURI": "MO", "TEXAS": "TX", "MAINE": "ME"}这里有些介绍模糊文本匹配函数如何工作的例子。
process.extractOne("Minnesotta",choices=state_to_code.keys())
('MINNESOTA', 95)
process.extractOne("AlaBAMMazzz",choices=state_to_code.keys(),score_cutoff=80)现在我知道它是如何工作的了,我们创建自己的函数来接受州名这一列的数据然后把他转换为一个有效的缩写。这里我们使用score_cutoff的值为80。你可以做一些调整,看看哪个值对你的数据来说比较好。你会注意到,返回值要么是一个有效的缩写,要么是一个np.nan 所以域中会有一些有效的值。
def convert_state(row):
abbrev = process.extractOne(row["state"],choices=state_to_code.keys(),score_cutoff=80)
if abbrev:
return state_to_code[abbrev[0]]
return np.nan把这列添加到我们想要填充的单元格,然后用NaN填充它
df_final.insert(6, "abbrev", np.nan) df_final.head()
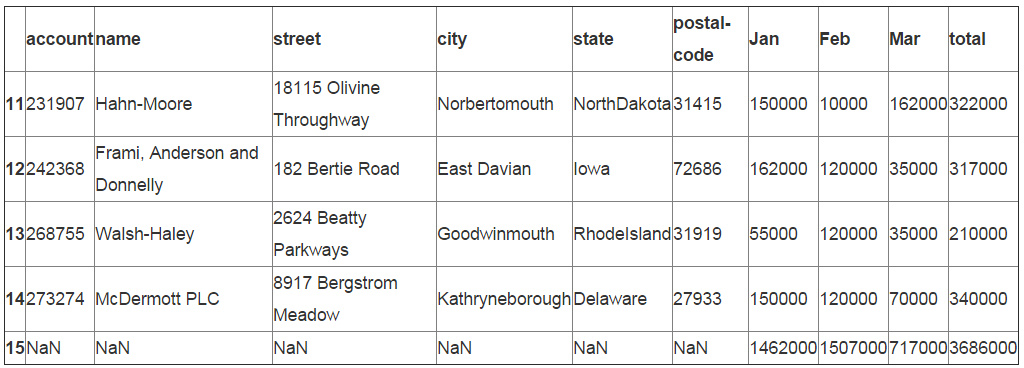
我们使用apply 来把缩写添加到合适的列中。
df_final['abbrev'] = df_final.apply(convert_state, axis=1) df_final.tail()
我觉的这很酷。我们已经开发出了一个非常简单的流程来智能的清理数据。显然,当你只有15行左右数据的时候这没什么了不起的。但是如果是15000行呢?在Excel中你就必须进行一些人工清理了。
分类汇总
在本文的最后一节中,让我们按州来做一些分类汇总(subtotal)。
在Excel中,我们会用subtotal 工具来完成。
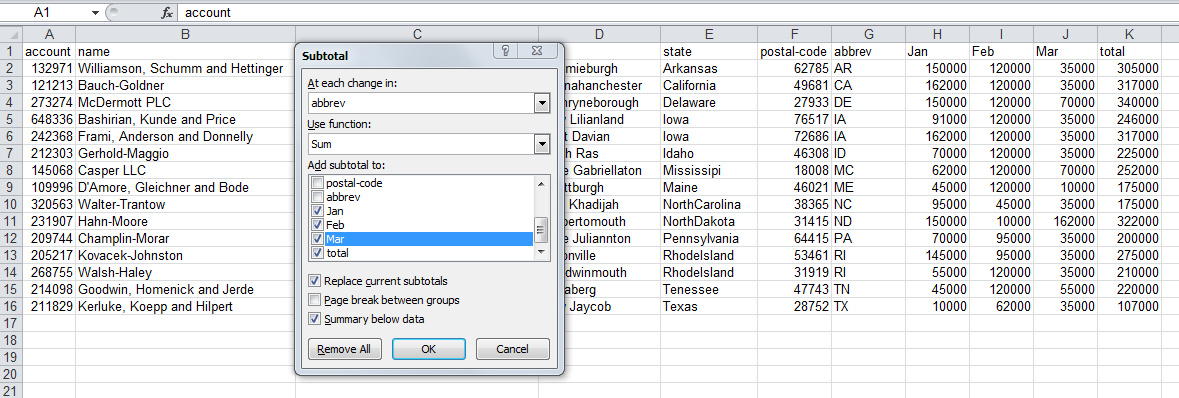
输出如下:
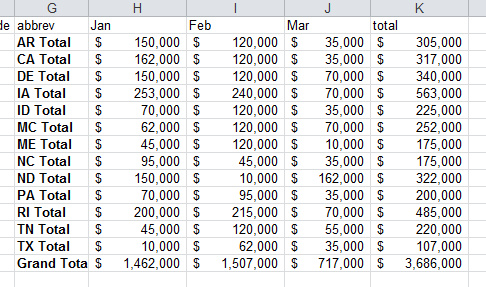
在pandas中创建分类汇总,是使用groupby 来完成的。
df_sub=df_final[["abbrev","Jan","Feb","Mar","total"]].groupby('abbrev').sum() df_sub
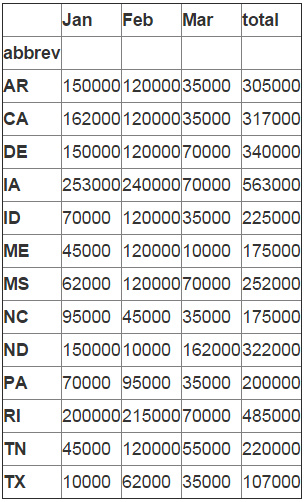
然后,我们想要通过对data frame中所有的值使用 applymap 来把数据单位格式化为货币。
def money(x):
return "${:,.0f}".format(x)
formatted_df = df_sub.applymap(money)
formatted_df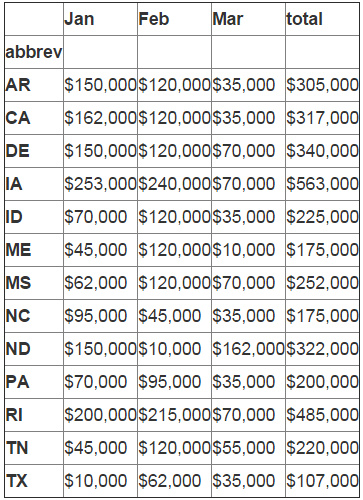
格式化看上去进行的很顺利,现在我们可以像之前那样获取总和了。
sum_row=df_sub[["Jan","Feb","Mar","total"]].sum() sum_row
Jan 1462000 Feb 1507000 Mar 717000 total 3686000 dtype: int64
把值变换为列然后进行格式化。
df_sub_sum=pd.DataFrame(data=sum_row).T df_sub_sum=df_sub_sum.applymap(money) df_sub_sum
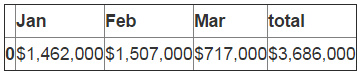
最后,把总和添加到DataFrame中。
final_table = formatted_df.append(df_sub_sum) final_table
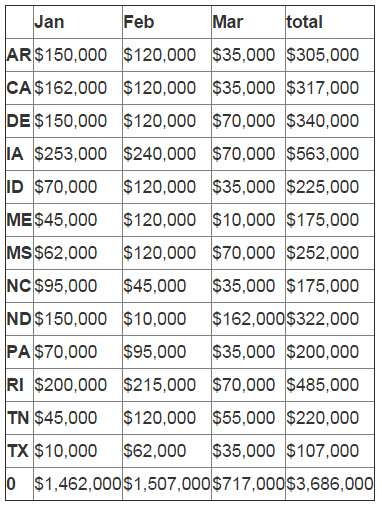
你可以注意到总和行的索引号是‘0'。我们想要使用rename 来重命名它。
final_table = final_table.rename(index={0:"Total"})
final_table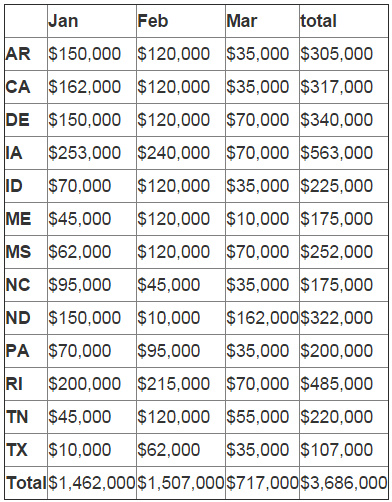
结论
到目前为止,大部分人都已经知道使用pandas可以对数据做很多复杂的操作——就如同Excel一样。因为我一直在学习pandas,但我发现我还是会尝试记忆我是如何在Excel中完成这些操作的而不是在pandas中。我意识到把它俩作对比似乎不是很公平——它们是完全不同的工具。但是,我希望能接触到哪些了解Excel并且想要学习一些可以满足分析他们数据需求的其他替代工具的那些人。我希望这些例子可以帮助到其他人,让他们有信心认为他们可以使用pandas来替换他们零碎复杂的Excel,进行数据操作。
相关文章:

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
MySQL Workbench kann eine Verbindung zu MariADB herstellen, vorausgesetzt, die Konfiguration ist korrekt. Wählen Sie zuerst "Mariadb" als Anschlusstyp. Stellen Sie in der Verbindungskonfiguration Host, Port, Benutzer, Kennwort und Datenbank korrekt ein. Überprüfen Sie beim Testen der Verbindung, ob der Mariadb -Dienst gestartet wird, ob der Benutzername und das Passwort korrekt sind, ob die Portnummer korrekt ist, ob die Firewall Verbindungen zulässt und ob die Datenbank vorhanden ist. Verwenden Sie in fortschrittlicher Verwendung die Verbindungspooling -Technologie, um die Leistung zu optimieren. Zu den häufigen Fehlern gehören unzureichende Berechtigungen, Probleme mit Netzwerkverbindung usw. Bei Debugging -Fehlern, sorgfältige Analyse von Fehlerinformationen und verwenden Sie Debugging -Tools. Optimierung der Netzwerkkonfiguration kann die Leistung verbessern
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
So lösen Sie MySQL können keine Verbindung zum lokalen Host herstellen
Apr 08, 2025 pm 02:24 PM
Die MySQL -Verbindung kann auf die folgenden Gründe liegen: MySQL -Dienst wird nicht gestartet, die Firewall fängt die Verbindung ab, die Portnummer ist falsch, der Benutzername oder das Kennwort ist falsch, die Höradresse in my.cnf ist nicht ordnungsgemäß konfiguriert usw. Die Schritte zur Fehlerbehebung umfassen: 1. Überprüfen Sie, ob der MySQL -Dienst ausgeführt wird. 2. Passen Sie die Firewall -Einstellungen an, damit MySQL Port 3306 anhören kann. 3. Bestätigen Sie, dass die Portnummer mit der tatsächlichen Portnummer übereinstimmt. 4. Überprüfen Sie, ob der Benutzername und das Passwort korrekt sind. 5. Stellen Sie sicher, dass die Einstellungen für die Bindungsadresse in my.cnf korrekt sind.
 Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Als Datenprofi müssen Sie große Datenmengen aus verschiedenen Quellen verarbeiten. Dies kann Herausforderungen für das Datenmanagement und die Analyse darstellen. Glücklicherweise können zwei AWS -Dienste helfen: AWS -Kleber und Amazon Athena.
