

四款mysql 分页存储过程实例

四款mysql 分页存储过程实例 本文章收集了四款mysql 分页存储过程实例代码,有高效的分页存储过程以及入门级的和通用的存储过程分页代码,如果你正在学mysql分页存储过程就进来看看吧。
四款mysql教程 分页存储过程实例
本文章收集了四款mysql 分页存储过程实例代码,有高效的分页存储过程以及入门级的和通用的存储过程分页代码,如果你正在学mysql分页存储过程就进来看看吧。
mysql测试版本:5.0.41-community-nt
/*****************************************************
mysql分页存储过程
吴剑 2009-07-02
*****************************************************/
drop procedure if exists pr_pager;
create procedure pr_pager(
in p_table_name varchar(1024), /*表名*/
in p_fields varchar(1024), /*查询字段*/
in p_page_size int, /*每页记录数*/
in p_page_now int, /*当前页*/
in p_order_string varchar(128), /*排序条件(包含order关键字,可为空)*/
in p_where_string varchar(1024), /*where条件(包含where关键字,可为空)*/
out p_out_rows int /*输出记录总数*/
)
not deterministic
sql security definer
comment '分页存储过程'
begin
/*定义变量*/
declare m_begin_row int default 0;
declare m_limit_string char(64);
/*构造语句*/
set m_begin_row = (p_page_now - 1) * p_page_size;
set m_limit_string = concat(' limit ', m_begin_row, ', ', p_page_size);
set @count_string = concat('select count(*) into @rows_total from ', p_table_name, ' ', p_where_string);
set @main_string = concat('select ', p_fields, ' from ', p_table_name, ' ', p_where_string, ' ', p_order_string, m_limit_string);
/*预处理*/
prepare count_stmt from @count_string;
execute count_stmt;
deallocate prepare count_stmt;
set p_out_rows = @rows_total;
prepare main_stmt from @main_string;
execute main_stmt;
deallocate prepare main_stmt;
end
一款高效的存储过程分页代码
存储过程分页的基本原理:我们先对查找到的记录集(支持输入查找条件_whereclause和排列条件_orderby)的key字段临时存放到临时表,然后构建真正的记录集输出。
create procedure `mysqltestuser_select_pageable`(
_whereclause varchar(2000), -- 查找条件
_orderby varchar(2000), -- 排序条件
_pagesize int , -- 每页记录数
_pageindex int , -- 当前页码
_docount bit -- 标志:统计数据/输出数据
)
not deterministic
sql security definer
comment ' '
begin
-- 定义key字段临时表
drop table if exists _temptable_keyid; -- 删除临时表,如果存在
create temporary table _temptable_keyid
(
userid int
)type=heap;
-- 构建动态的sql,输出关键字key的id集合
-- 查找条件
set @sql = 'select userid from mysqltestuser ';
if (_whereclause is not null) and (_whereclause ' ') then
set @sql= concat(@sql, ' where ' ,_whereclause);
end if;
if (_orderby is not null) and (_orderby ' ') then
set @sql= concat( @sql , ' order by ' , _orderby);
end if;
-- 准备id记录插入到临时表
set @sql=concat( 'insert into _temptable_keyid(userid) ', @sql);
prepare stmt from @sql;
execute stmt ;
deallocate prepare stmt;
-- key的id集合 [end]
-- 下面是输出
if (_docount=1) then -- 统计
begin
select count(*) as recordcount from _temptable_keyid;
end;
else -- 输出记录集
begin
-- 计算记录的起点位置
set @startpoint = ifnull((_pageindex-1)*_pagesize,0);
set @sql= ' select a.*
from mysqltestuser a
inner join _temptable_keyid b
on a.userid =b.userid ';
set @sql=concat(@sql, " limit ",@startpoint, " , ",_pagesize);
prepare stmt from @sql;
execute stmt ;
deallocate prepare stmt;
end;
end if;
drop table _temptable_keyid;
end;
下面是mysqltestuser表的ddl:
create table `mysqltestuser` (
`userid` int(11) not null auto_increment,
`name` varchar(50) default null,
`chinesename` varchar(50) default null,
`registerdatetime` datetime default null,
`jf` decimal(20,2) default null,
`description` longtext,
primary key (`userid`)
) engine=innodb default charset=gb2312;
插入些数据:
insert into `mysqltestuser` (`userid`, `name`, `chinesename`, `registerdatetime`, `jf`, `description`) values
(1, 'xuu1 ', 'www.aimeige.com.cn ', '2007-03-29 12:54:41 ',1.5, 'description1 '),
(2, 'xuu2 ', 'www.bKjia.c0m ', '2007-03-29 12:54:41 ',2.5, 'description2 '),
存储过程调用测试:
-- 方法原型 `mysqltestuser_select_pageable`(条件,排列顺序,每页记录数,第几页,是否统计数据)
-- call `mysqltestuser_select_pageable`(_whereclause ,_orderby ,_pagesize ,_pageindex , _docount)
-- 统计数据
call `mysqltestuser_select_pageable`(null, null, null, null, 1)
-- 输出数据,没条件限制,10条记录/页,第一页
call `mysqltestuser_select_pageable`(null, null, 10, 1,0)
-- 输出数据,条件限制,排列, 10条记录/页,第一页
call `mysqltestuser_select_pageable`( 'chinesename like ' '%飞3% ' ' ', 'userid asc ', 10, 1, 0)
一款mysql .net的方法
mysql + asp教程.net来写网站,既然mysql已经支持存储过程了,那么像分页这么常用的东西,当然要用存储过程啦!
不过在网上找了一些,发现都有一个特点——就是不能传出总记录数,干脆自己研究吧。终于,算是搞出来了,效率可能不是很好,但是我也觉得不错了。贴代码吧直接:也算是对自己学习mysql的一个记录。
create procedure p_pagelist
(
m_pageno int ,
m_perpagecnt int ,
m_column varchar(1000) ,
m_table varchar(1000) ,
m_condition varchar(1000),
m_orderby varchar(200) ,
out m_totalpagecnt int
)
begin
set @pagecnt = 1; -- 总记录数
set @limitstart = (m_pageno - 1)*m_perpagecnt;
set @limitend = m_perpagecnt;
set @sqlcnt = concat('select count(1) into @pagecnt from ',m_table); -- 这条语句很关键,用来得到总数值
set @sql = concat('select ',m_column,' from ',m_table);
if m_condition is not null and m_condition '' then
set @sql = concat(@sql,' where ',m_condition);
set @sqlcnt = concat(@sqlcnt,' where ',m_condition);
end if;
if m_orderby is not null and m_orderby '' then
set @sql = concat(@sql,' order by ',m_orderby);
end if;
set @sql = concat(@sql, ' limit ', @limitstart, ',', @limitend);
prepare s_cnt from @sqlcnt;
execute s_cnt;
deallocate prepare s_cnt;
set m_totalpagecnt = @pagecnt;
prepare record from @sql;
execute record;
deallocate prepare record;
end
方法四
mysql的通用存储过程,本着共享的精神,为大家奉献这段mysql分页查询通用存储过程,假设所用数据库教程为guestbook:
use guestbook;
delimiter $$
drop procedure if exists prc_page_result $$
create procedure prc_page_result (
in currpage int,
in columns varchar(500),
in tablename varchar(500),
in scondition varchar(500),
in order_field varchar(100),
in asc_field int,
in primary_field varchar(100),
in pagesize int
)
begin
declare stemp varchar(1000);
declare ssql varchar(4000);
declare sorder varchar(1000);
if asc_field = 1 then
set sorder = concat( order by , order_field, desc );
set stemp =
else
set sorder = concat( order by , order_field, asc );
set stemp = >(select max;
end if;
if currpage = 1 then
if scondition then
set ssql = concat(select , columns, from , tablename, where );
set ssql = concat(ssql, scondition, sorder, limit ?);
else
set ssql = concat(select , columns, from , tablename, sorder, limit ?);
end if;
else
if scondition then
set ssql = concat(select , columns, from , tablename);
set ssql = concat(ssql, where , scondition, and , primary_field, stemp);
set ssql = concat(ssql, (, primary_field, ), from (select );
set ssql = concat(ssql, , primary_field, from , tablename, sorder);
set ssql = concat(ssql, limit , (currpage-1)*pagesize, ) as tabtemp), sorder);
set ssql = concat(ssql, limit ?);
else
set ssql = concat(select , columns, from , tablename);
set ssql = concat(ssql, where , primary_field, stemp);
set ssql = concat(ssql, (, primary_field, ), from (select );
set ssql = concat(ssql, , primary_field, from , tablename, sorder);
set ssql = concat(ssql, limit , (currpage-1)*pagesize, ) as tabtemp), sorder);
set ssql = concat(ssql, limit ?);
end if;
end if;
set @ipagesize = pagesize;
set @squery = ssql;
prepare stmt from @squery;
execute stmt using @ipagesize;
end;
$$
delimiter;
可以存储为数据库脚本,然后用命令导入:
mysql -u root -p
调用:call prc_page_result(1, "*", "tablename", "", "columnname", 1, "pkid", 25);
*/
?>

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Die MySQL-Abfrageleistung kann durch die Erstellung von Indizes optimiert werden, die die Suchzeit von linearer Komplexität auf logarithmische Komplexität reduzieren. Verwenden Sie PreparedStatements, um SQL-Injection zu verhindern und die Abfrageleistung zu verbessern. Begrenzen Sie die Abfrageergebnisse und reduzieren Sie die vom Server verarbeitete Datenmenge. Optimieren Sie Join-Abfragen, einschließlich der Verwendung geeigneter Join-Typen, der Erstellung von Indizes und der Berücksichtigung der Verwendung von Unterabfragen. Analysieren Sie Abfragen, um Engpässe zu identifizieren. Verwenden Sie Caching, um die Datenbanklast zu reduzieren. Optimieren Sie den PHP-Code, um den Overhead zu minimieren.
 Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Das Sichern und Wiederherstellen einer MySQL-Datenbank in PHP kann durch Befolgen dieser Schritte erreicht werden: Sichern Sie die Datenbank: Verwenden Sie den Befehl mysqldump, um die Datenbank in eine SQL-Datei zu sichern. Datenbank wiederherstellen: Verwenden Sie den Befehl mysql, um die Datenbank aus SQL-Dateien wiederherzustellen.
 Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich Daten in eine MySQL-Tabelle ein? Mit der Datenbank verbinden: Stellen Sie mit mysqli eine Verbindung zur Datenbank her. Bereiten Sie die SQL-Abfrage vor: Schreiben Sie eine INSERT-Anweisung, um die einzufügenden Spalten und Werte anzugeben. Abfrage ausführen: Verwenden Sie die Methode query(), um die Einfügungsabfrage auszuführen. Bei Erfolg wird eine Bestätigungsmeldung ausgegeben.
 So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
Eine der wichtigsten Änderungen, die in MySQL 8.4 (der neuesten LTS-Version von 2024) eingeführt wurden, besteht darin, dass das Plugin „MySQL Native Password“ nicht mehr standardmäßig aktiviert ist. Darüber hinaus entfernt MySQL 9.0 dieses Plugin vollständig. Diese Änderung betrifft PHP und andere Apps
 Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
So verwenden Sie gespeicherte MySQL-Prozeduren in PHP: Verwenden Sie PDO oder die MySQLi-Erweiterung, um eine Verbindung zu einer MySQL-Datenbank herzustellen. Bereiten Sie die Anweisung zum Aufrufen der gespeicherten Prozedur vor. Führen Sie die gespeicherte Prozedur aus. Verarbeiten Sie die Ergebnismenge (wenn die gespeicherte Prozedur Ergebnisse zurückgibt). Schließen Sie die Datenbankverbindung.
 Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Das Erstellen einer MySQL-Tabelle mit PHP erfordert die folgenden Schritte: Stellen Sie eine Verbindung zur Datenbank her. Erstellen Sie die Datenbank, falls sie nicht vorhanden ist. Wählen Sie eine Datenbank aus. Tabelle erstellen. Führen Sie die Abfrage aus. Schließen Sie die Verbindung.
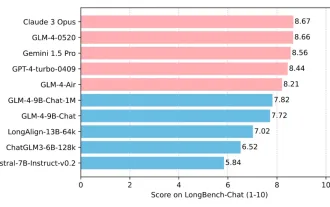 Tsinghua University und Zhipu AI Open Source GLM-4: Start einer neuen Revolution in der Verarbeitung natürlicher Sprache
Jun 12, 2024 pm 08:38 PM
Tsinghua University und Zhipu AI Open Source GLM-4: Start einer neuen Revolution in der Verarbeitung natürlicher Sprache
Jun 12, 2024 pm 08:38 PM
Seit der Einführung von ChatGLM-6B am 14. März 2023 haben die Modelle der GLM-Serie große Aufmerksamkeit und Anerkennung erhalten. Insbesondere nachdem ChatGLM3-6B als Open Source verfügbar war, sind die Entwickler voller Erwartungen an das von Zhipu AI eingeführte Modell der vierten Generation. Diese Erwartung wurde mit der Veröffentlichung von GLM-4-9B endlich vollständig erfüllt. Die Geburt von GLM-4-9B Um kleinen Modellen (10B und darunter) leistungsfähigere Fähigkeiten zu verleihen, hat das GLM-Technikteam nach fast einem halben Jahr dieses neue Open-Source-Modell der GLM-Serie der vierten Generation auf den Markt gebracht: GLM-4-9B Erkundung. Dieses Modell komprimiert die Modellgröße erheblich und stellt gleichzeitig Genauigkeit sicher. Es verfügt über eine schnellere Inferenzgeschwindigkeit und eine höhere Effizienz. Die Untersuchungen des GLM-Technikteams haben dies nicht getan
 Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Oracle-Datenbank und MySQL sind beide Datenbanken, die auf dem relationalen Modell basieren, aber Oracle ist in Bezug auf Kompatibilität, Skalierbarkeit, Datentypen und Sicherheit überlegen, während MySQL auf Geschwindigkeit und Flexibilität setzt und eher für kleine bis mittlere Datensätze geeignet ist. ① Oracle bietet eine breite Palette von Datentypen, ② bietet erweiterte Sicherheitsfunktionen, ③ ist für Anwendungen auf Unternehmensebene geeignet; ① MySQL unterstützt NoSQL-Datentypen, ② verfügt über weniger Sicherheitsmaßnahmen und ③ ist für kleine bis mittlere Anwendungen geeignet.
