
 Technologie-Peripheriegeräte
KI
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
Technologie-Peripheriegeräte
KI
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AMVorher geschrieben
Heute diskutieren wir, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten zeigen wir, dass SL-SLAM modernste SLAM-Algorithmen in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit übertrifft.
Projektlink: https://github.com/zzzzxxxx111/SLslam.
(Wischen Sie mit dem Daumen nach oben, klicken Sie auf die obere Karte, um mir zu folgen, Der gesamte Vorgang dauert nur 1,328 Sekunden und dauert dann weg die Zukunft, alles, kostenlose, trockene Informationen, falls irgendwelche Inhalte für Sie hilfreich sind ~)
Einführung in den aktuellen SLAM-Anwendungshintergrund
SLAM (Simultaneous Positioning and Map Construction) ist eine Technologie in der Robotik, Autonomes Fahren und 3D-Rekonstruktion Die Schlüsseltechnologie besteht darin, gleichzeitig die Position des Sensors zu bestimmen (Lokalisierung) und eine Karte der Umgebung zu erstellen. Vision- und Trägheitssensoren sind die am häufigsten verwendeten Sensorgeräte, und verwandte Lösungen wurden eingehend diskutiert und untersucht. Nach jahrzehntelanger Entwicklung hat das Verarbeitungsgerüst des visuellen (Trägheits-)SLAM ein Grundgerüst gebildet, das Tracking, Kartenkonstruktion und Schleifenerkennung umfasst. Im SLAM-Algorithmus ist das Tracking-Modul für die Schätzung der Flugbahn des Roboters verantwortlich, das Kartenerstellungsmodul dient zur Generierung und Aktualisierung der Umgebungskarte und die Schleifenerkennung dient zur Identifizierung der besuchten Orte. Diese Module arbeiten zusammen, um ein Bewusstsein für den Zustand und die Umgebung des Roboters zu schaffen. Zu den häufig verwendeten Algorithmen im visuellen SLAM gehören die Feature-Point-Methode, die direkte Methode und die semidirekte Methode. Bei der Feature-Point-Methode werden die Kameraposition und die dreidimensionale Punktwolke durch Extrahieren und Anpassen von Feature-Punkten geschätzt. Bei der direkten Methode werden die Kameraposition und die dreidimensionale Punktwolke direkt durch Minimierung der Bildgraustufendifferenz geschätzt Die Forschung konzentrierte sich auf die Verbesserung der Robustheit unter extremen Bedingungen und der Anpassungsfähigkeit. Aufgrund der langen Entwicklungsgeschichte der SLAM-Technologie gibt es viele repräsentative SLAM-Arbeiten, die auf traditionellen geometrischen Methoden basieren, wie ORB-SLAM, VINS-Mono, DVO, MSCKF usw. Es bleiben jedoch einige ungelöste Fragen. In anspruchsvollen Umgebungen wie schlechten Lichtverhältnissen oder dynamischer Beleuchtung, starkem Jitter und schwachen Texturbereichen berücksichtigen herkömmliche Merkmalsextraktionsalgorithmen nur die lokalen Informationen des Bildes, ohne die strukturellen und semantischen Informationen des Bildes zu berücksichtigen, wenn die oben genannten Situationen auftreten Die Verfolgung des SLAM-Systems kann instabil und ineffektiv werden. Unter diesen Bedingungen kann die Verfolgung des SLAM-Systems daher instabil und ineffektiv werden.
Die rasante Entwicklung des Deep Learning hat revolutionäre Veränderungen im Bereich Computer Vision mit sich gebracht. Durch die Nutzung großer Datenmengen für das Training können Deep-Learning-Modelle komplexe Szenenstrukturen und semantische Informationen simulieren und so die Fähigkeit des SLAM-Systems verbessern, Szenen zu verstehen und auszudrücken. Diese Methode ist hauptsächlich in zwei Ansätze unterteilt. Der erste ist ein End-to-End-Algorithmus, der auf Deep Learning basiert, wie z. B. Droid-Slam, NICE-SLAM und DVI-SLAM. Allerdings erfordern diese Methoden eine große Datenmenge für das Training, hohe Rechenressourcen und Speicherplatz, was es schwierig macht, eine Echtzeitverfolgung zu erreichen. Der zweite Ansatz heißt Hybrid-SLAM und nutzt Deep Learning, um bestimmte Module im SLAM zu verbessern. Hybrid SLAM nutzt die Vorteile traditioneller geometrischer Methoden und Deep-Learning-Methoden voll aus und kann ein Gleichgewicht zwischen nahezu allen Einschränkungen und semantischem Verständnis finden. Obwohl es in diesem Bereich einige Studien gibt, ist die effektive Integration von Deep-Learning-Technologie immer noch eine Richtung, die weiterer Forschung bedarf.
Derzeit gibt es beim bestehenden Hybrid-SLAM einige Einschränkungen. DXNet ersetzt einfach ORB-Feature-Punkte durch Deep-Feature-Punkte, verwendet aber weiterhin traditionelle Methoden, um diese Features zu verfolgen. Daher kann dies zu einer Inkohärenz der Tiefenmerkmalsinformationen führen. SP-Loop führt nur Deep-Learning-Feature-Punkte in das Closed-Loop-Modul ein, während an anderer Stelle traditionelle Methoden zur Feature-Punkt-Extraktion beibehalten werden. Daher kombinieren diese hybriden SLAM-Methoden die Deep-Learning-Technologie nicht effektiv und umfassend, was in einigen komplexen Szenen zu einem Rückgang der Tracking- und Mapping-Effekte führt.
Um diese Probleme zu lösen, wird hier ein multifunktionales SLAM-System vorgeschlagen, das auf Deep Learning basiert. Integrieren Sie das Superpoint-Feature-Point-Extraktionsmodul in das System und verwenden Sie es durchgehend als einzige Ausdrucksform. Darüber hinaus weisen herkömmliche Feature-Matching-Methoden in komplexen Umgebungen häufig Instabilität auf, was zu einer Verschlechterung der Tracking- und Mapping-Qualität führt. Jüngste Fortschritte bei Deep-Learning-basierten Feature-Matching-Methoden haben jedoch gezeigt, dass das Potenzial für eine verbesserte Matching-Leistung in komplexen Umgebungen besteht. Diese Methoden nutzen Vorinformationen und strukturelle Details der Szene, um die Effektivität des Matchings zu verbessern. Als neueste SOTA-Matching-Methode (State-of-the-Art) bietet Lightglue aufgrund seiner effizienten und leichten Eigenschaften Vorteile für SLAM-Systeme, die eine hohe Echtzeitleistung erfordern. Aus diesem Grund haben wir die Feature-Matching-Methode im gesamten SLAM-System durch Lightglue ersetzt, was die Robustheit und Genauigkeit im Vergleich zu herkömmlichen Methoden verbessert.
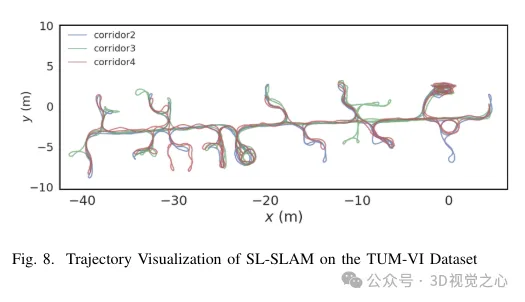
Bei der Verarbeitung von Superpoint-Feature-Point-Deskriptoren verarbeiten wir diese vor, damit sie mit dem Training der entsprechenden Menge an visuellen Wörtern übereinstimmen. In Kombination mit Lightglue erreicht dieser Ansatz eine präzise Szenenerkennung. Gleichzeitig wird eine Strategie zur Auswahl von Merkmalspunkten entwickelt, um das Gleichgewicht zwischen Genauigkeit und Effizienz aufrechtzuerhalten. Im Hinblick auf Skalierbarkeit, Portabilität und Echtzeitleistung nutzen wir die ONNX+Runtime-Bibliothek, um diese Deep-Learning-Modelle bereitzustellen. Schließlich soll eine Reihe von Experimenten beweisen, dass die Methode die Genauigkeit der Flugbahnvorhersage und die Tracking-Robustheit des SLAM-Algorithmus in einer Vielzahl anspruchsvoller Szenarien verbessert, wie in Abbildung 8 dargestellt.
SL-SLAM-Systemrahmen
Die Systemstruktur von SL-SLAM ist in Abbildung 2 dargestellt. Das System verfügt hauptsächlich über vier Sensorkonfigurationen, nämlich monokular, monokulare Trägheit, binokular und binokulare Trägheit. Das System basiert auf ORB-SLAM3 als Basis und enthält drei Hauptmodule: Tracking, lokale Zuordnung und Schleifenerkennung. Um Deep-Learning-Modelle in das System zu integrieren, wird das Deep-Learning-Deployment-Framework ONNX Runtime verwendet, das SuperPoint- und LightGlue-Modelle kombiniert.
Für jedes Eingabebild gibt das System es zunächst in das SuperPoint-Netzwerk ein, um den Wahrscheinlichkeitstensor und den Deskriptortensor der Merkmalspunkte zu erhalten. Das System initialisiert dann mit zwei Frames und führt bei jedem nachfolgenden Frame eine Grobverfolgung durch. Durch die Verfolgung lokaler Karten wird die Posenschätzung weiter verfeinert. Im Falle eines Tracking-Fehlers verwendet das System entweder einen Referenzrahmen zum Tracking oder führt eine Neulokalisierung durch, um die Pose erneut zu erfassen. Bitte beachten Sie, dass LightGlue für den Feature-Abgleich während der Grobverfolgung, Initialisierung, Referenzbildverfolgung und Verschiebung verwendet wird. Dies stellt genaue und robuste Matching-Beziehungen sicher und erhöht dadurch die Tracking-Effektivität.
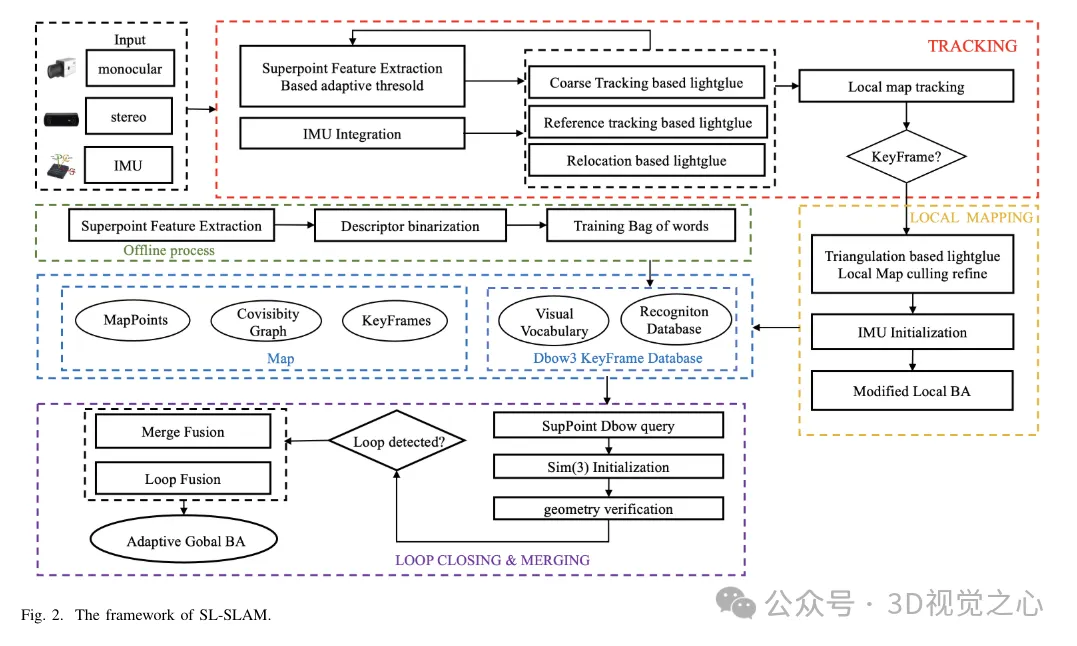
Im Basisalgorithmus besteht die Hauptaufgabe des lokalen Mapping-Threads darin, in Echtzeit dynamisch eine lokale Karte zu erstellen, einschließlich Kartenpunkten und Schlüsselbildern. Es nutzt lokale Karten, um eine Bündelanpassungsoptimierung durchzuführen, wodurch Trackingfehler reduziert und die Konsistenz verbessert werden. Der lokale Mapping-Thread verwendet vom Tracking-Thread ausgegebene Keyframes, LightGlue-basierte Triangulation und adaptive Local Bundle Adjustment (BA)-Optimierung, um genaue Kartenpunkte zu rekonstruieren. Anschließend werden redundante Kartenpunkte und Keyframes unterschieden und entfernt.
Der Closed-Loop-Korrekturthread nutzt eine Keyframe-Datenbank und ein Bag-of-Words-Modell, das auf SuperPoint-Deskriptoren trainiert wurde, um ähnliche Keyframes abzurufen. Verbessern Sie die Abrufeffizienz durch Binarisierung von SuperPoint-Deskriptoren. Ausgewählte Keyframes werden mithilfe von LightGlue zur allgemeinen Überprüfung der Ansichtsgeometrie funktionsabgeglichen, wodurch die Möglichkeit von Nichtübereinstimmungen verringert wird. Abschließend werden eine Closed-Loop-Fusion und eine globale BA (Bündelanpassung) durchgeführt, um die Gesamthaltung zu optimieren.
1) Merkmalsextraktion
SuperPoint-Netzwerkstruktur: Die SuperPoint-Netzwerkarchitektur besteht hauptsächlich aus drei Teilen: einem gemeinsam genutzten Encoder, einem Feature-Erkennungsdecoder und einem Deskriptor-Decoder. Der Encoder ist ein Netzwerk im VGG-Stil, das Bildabmessungen reduzieren und Merkmale extrahieren kann. Die Aufgabe des Merkmalserkennungsdecoders besteht darin, die Wahrscheinlichkeit jedes Pixels im Bild zu berechnen, um seine Wahrscheinlichkeit zu bestimmen, ein Merkmalspunkt zu sein. Das Deskriptor-Dekodierungsnetzwerk nutzt die Subpixel-Faltung, um die Rechenkomplexität des Dekodierungsprozesses zu reduzieren. Das Netzwerk gibt dann einen halbdichten Deskriptor aus und ein bikubischer Interpolationsalgorithmus wird angewendet, um den vollständigen Deskriptor zu erhalten. Nachdem wir den vom Netzwerk ausgegebenen Merkmalspunkt-Tensor und Deskriptor-Tensor erhalten haben, wenden wir zur Verbesserung der Robustheit der Merkmalsextraktion eine adaptive Schwellenwertauswahlstrategie an, um die Merkmalspunkte zu filtern und Nachbearbeitungsvorgänge durchzuführen, um die Merkmalspunkte und ihre Deskriptoren zu erhalten . Die spezifische Struktur des Merkmalsextraktionsmoduls ist in Abbildung 3 dargestellt.
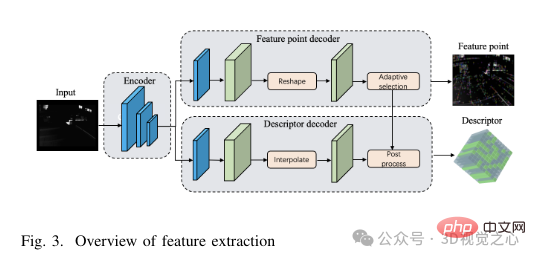
Adaptive Funktionsauswahl: Zuerst wird jedes Bild mit der Bezeichnung I(B × H) in Grau konvertiert, bevor die Größe geändert wird, um den Eingabebildabmessungen (B′ × H′) des SuperPoint-Netzwerkgradbildes zu entsprechen. Zu kleine Bilder können die Merkmalsextraktion behindern und dadurch die Tracking-Leistung verringern, während zu große Bilder zu übermäßigem Rechenaufwand und Speicherverbrauch führen können. Um die Genauigkeit und Effizienz der Merkmalsextraktion in Einklang zu bringen, wählt dieser Artikel daher W′ = 400 und H′ = 300. Anschließend wird ein Tensor der Größe W′ × H′ in das Netzwerk eingespeist, wodurch zwei Ausgabetensoren erzeugt werden: der Score-Tensor S und der Deskriptor-Tensor D. Sobald der Feature-Point-Score-Tensor und der Feature-Deskriptor ermittelt wurden, besteht der nächste Schritt darin, einen Schwellenwert th festzulegen, um die Feature-Punkte zu filtern.
In anspruchsvollen Szenarien wird die Konfidenz jedes Merkmalspunkts verringert, was zu einer Verringerung der Anzahl der extrahierten Merkmale führen kann, wenn ein fester Konfidenzschwellenwert th übernommen wird. Um dieses Problem zu lösen, führen wir eine adaptive SuperPoint-Schwellenwerteinstellungsstrategie ein. Diese adaptive Methode passt den Schwellenwert der Merkmalsextraktion je nach Szene dynamisch an und erreicht so eine robustere Merkmalsextraktion in anspruchsvollen Szenen. Der adaptive Schwellenwertmechanismus berücksichtigt zwei Faktoren: Intra-Feature-Beziehungen und Inter-Frame-Feature-Beziehungen.
In anspruchsvollen Szenarien wird die Konfidenz jedes Merkmalspunkts verringert, was zu einer Verringerung der Anzahl der extrahierten Merkmale führen kann, wenn ein fester Konfidenzschwellenwert th übernommen wird. Um dieses Problem zu lösen, wird eine adaptive SuperPoint-Schwellenwerteinstellungsstrategie eingeführt. Diese adaptive Methode passt die Schwellenwerte für die Merkmalsextraktion basierend auf der Szene dynamisch an und erreicht so eine robustere Merkmalsextraktion in anspruchsvollen Szenen. Der adaptive Schwellenwertmechanismus berücksichtigt zwei Faktoren: Intra-Feature-Beziehungen und Inter-Frame-Feature-Beziehungen.
2) Feature-Matching und Front-End
LightGlue-Netzwerkstruktur: Das LightGlue-Modell besteht aus mehreren identischen Schichten, die gemeinsam zwei Sätze von Features verarbeiten. Jede Ebene enthält Selbstaufmerksamkeits- und Queraufmerksamkeitseinheiten zur Aktualisierung der Darstellung von Punkten. Klassifikatoren in jeder Ebene entscheiden, wo die Inferenz gestoppt werden soll, und vermeiden so unnötige Berechnungen. Schließlich berechnet ein leichtgewichtiger Header Teilübereinstimmungswerte. Die Tiefe des Netzwerks passt sich dynamisch an die Komplexität des Eingabebildes an. Wenn die Bildpaare leicht übereinstimmen, kann aufgrund der hohen Zuverlässigkeit der Tags eine vorzeitige Beendigung erreicht werden. Dadurch verfügt LightGlue über kürzere Laufzeiten und einen geringeren Speicherverbrauch, wodurch es sich für die Integration in Aufgaben eignet, die Echtzeitleistung erfordern.
Der Zeitabstand zwischen benachbarten Bildern beträgt normalerweise nur einige zehn Millisekunden. ORB-SLAM3 geht davon aus, dass sich die Kamera während dieser kurzen Zeitspanne mit einer konstanten Geschwindigkeit bewegt. Es verwendet die Pose und Geschwindigkeit des vorherigen Frames, um die Pose des aktuellen Frames abzuschätzen, und verwendet diese geschätzte Pose für den Projektionsabgleich. Anschließend sucht es innerhalb eines bestimmten Bereichs nach passenden Punkten und verfeinert die Pose entsprechend. In der Realität ist die Kamerabewegung jedoch möglicherweise nicht immer gleichmäßig. Plötzliche Beschleunigung, Verzögerung oder Drehung können die Wirksamkeit dieser Methode beeinträchtigen. Lightglue kann dieses Problem effektiv lösen, indem es die Merkmale zwischen dem aktuellen Frame und dem vorherigen Frame direkt abgleicht. Anschließend werden diese übereinstimmenden Merkmale verwendet, um die anfängliche Posenschätzung zu verfeinern und so die negativen Auswirkungen einer plötzlichen Beschleunigung oder Drehung zu reduzieren.
In Situationen, in denen die Bildverfolgung in früheren Bildern fehlschlägt, sei es aufgrund plötzlicher Kamerabewegungen oder anderer Faktoren, müssen Referenz-Keyframes zur Verfolgung oder Neupositionierung verwendet werden. Der Basisalgorithmus verwendet die Bag-of-Words-Methode (BoW), um den Merkmalsabgleich zwischen dem aktuellen Frame und dem Referenzframe zu beschleunigen. Die BoW-Methode wandelt jedoch räumliche Informationen in statistische Informationen basierend auf visuellem Vokabular um, wodurch möglicherweise die genaue räumliche Beziehung zwischen Merkmalspunkten verloren geht. Wenn außerdem das im BoW-Modell verwendete visuelle Vokabular unzureichend oder nicht repräsentativ genug ist, kann es sein, dass es die umfangreichen Merkmale der Szene nicht erfasst, was zu Ungenauigkeiten im Matching-Prozess führt.
Kombiniert mit Lightglue-Tracking: Da der Zeitabstand zwischen benachbarten Bildern sehr kurz ist, normalerweise nur einige zehn Millisekunden, geht ORB-SLAM3 davon aus, dass sich die Kamera in diesem Zeitraum mit einer gleichmäßigen Geschwindigkeit bewegt. Es verwendet die Pose und Geschwindigkeit des vorherigen Frames, um die Pose des aktuellen Frames abzuschätzen, und verwendet diese geschätzte Pose für den Projektionsabgleich. Anschließend sucht es innerhalb eines bestimmten Bereichs nach passenden Punkten und verfeinert die Pose entsprechend. In der Realität ist die Kamerabewegung jedoch möglicherweise nicht immer gleichmäßig. Plötzliche Beschleunigung, Verzögerung oder Drehung können die Wirksamkeit dieser Methode beeinträchtigen. Lightglue kann dieses Problem effektiv lösen, indem es die Merkmale zwischen dem aktuellen Frame und dem vorherigen Frame direkt abgleicht. Anschließend werden diese übereinstimmenden Merkmale verwendet, um die anfängliche Posenschätzung zu verfeinern und so die negativen Auswirkungen einer plötzlichen Beschleunigung oder Drehung zu reduzieren.
In Situationen, in denen die Bildverfolgung in früheren Bildern fehlschlägt, sei es aufgrund plötzlicher Kamerabewegungen oder anderer Faktoren, müssen Referenz-Keyframes zur Verfolgung oder Neupositionierung verwendet werden. Der Basisalgorithmus verwendet die Bag-of-Words-Methode (BoW), um den Merkmalsabgleich zwischen dem aktuellen Frame und dem Referenzframe zu beschleunigen. Die BoW-Methode wandelt jedoch räumliche Informationen in statistische Informationen basierend auf visuellem Vokabular um, wodurch möglicherweise die genaue räumliche Beziehung zwischen Merkmalspunkten verloren geht. Wenn außerdem das im BoW-Modell verwendete visuelle Vokabular unzureichend oder nicht repräsentativ genug ist, kann es sein, dass es die umfangreichen Merkmale der Szene nicht erfasst, was zu Ungenauigkeiten im Matching-Prozess führt.

Um diese Probleme zu lösen, wurde die BoW-Methode im gesamten System durch Lightglue ersetzt. Diese Änderung erhöht die Wahrscheinlichkeit einer erfolgreichen Verfolgung und Neulokalisierung bei groß angelegten Transformationen erheblich und erhöht dadurch die Genauigkeit und Robustheit unseres Verfolgungsprozesses. Abbildung 4 zeigt die Wirksamkeit verschiedener Matching-Methoden. Es ist zu beobachten, dass die auf Lightglue basierende Matching-Methode eine bessere Matching-Leistung aufweist als die in ORB-SLAM3 verwendete Matching-Methode auf Projektions- oder Bag-of-Words-Basis. Daher wird die Verfolgung von Kartenpunkten während des SLAM-Vorgangs gleichmäßiger und stabiler, wie in Abbildung 6 dargestellt.
Kombiniert mit der lokalen Zuordnung von Lightglue: Im lokalen Zuordnungsthread wird die Triangulation neuer Kartenpunkte durch den aktuellen Keyframe und seine angrenzenden Keyframes abgeschlossen. Um genauere Kartenpunkte zu erhalten, müssen Sie sie mit Keyframes mit einer größeren Grundlinie abgleichen. ORB-SLAM3 verwendet jedoch den Bag-of-Words-Matching (BoW), um dies zu erreichen. Die Leistung des BoW-Feature-Matchings nimmt jedoch ab, wenn die Basislinie groß ist. Im Gegensatz dazu eignet sich der Lightglue-Algorithmus gut für den Abgleich mit großen Basislinien und integriert sich nahtlos in das System. Durch die Verwendung von Lightglue zum Feature-Matching und zur Triangulation von Matching-Punkten können umfassendere und qualitativ hochwertigere Kartenpunkte wiederhergestellt werden.
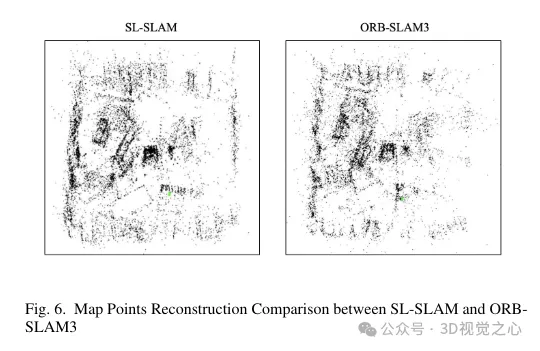
Dies verbessert die lokalen Mapping-Funktionen, indem es mehr Verbindungen zwischen Keyframes schafft und das Tracking stabilisiert, indem die Pose gemeinsam sichtbarer Keyframes und Kartenpunkte gemeinsam optimiert wird. Der Triangulationseffekt von Kartenpunkten ist in Abbildung 6 dargestellt. Es ist zu beobachten, dass die mit unserer Methode erstellten Kartenpunkte im Vergleich zu ORB-SLAM3 die Strukturinformationen der Szene besser widerspiegeln können. Darüber hinaus sind sie gleichmäßiger und weiter im Raum verteilt.
3) Schleifenschluss
Bag-of-Words-Tiefenbeschreibung: Die Bag-of-Words-Methode, die bei der Schleifenschlusserkennung verwendet wird, ist eine Methode, die auf visuellem Vokabular basiert und auf dem Konzept des Bag-of-Words basiert in der Verarbeitung natürlicher Sprache. Zunächst wird das Wörterbuch offline trainiert. Zunächst wird der K-Means-Algorithmus verwendet, um die erkannten Merkmalsdeskriptoren im Trainingsbildsatz in k Sätze zu gruppieren und so die erste Ebene des Wörterbuchbaums zu bilden. Anschließend werden innerhalb jedes Satzes rekursive Operationen durchgeführt, um schließlich den endgültigen Wörterbuchbaum mit der Tiefe L und der Anzahl der Zweige k zu erhalten und ein visuelles Vokabular zu erstellen. Jeder Blattknoten wird als Vokabular betrachtet.
Sobald das Wörterbuchtraining abgeschlossen ist, werden während der Algorithmusausführung aus allen Merkmalspunkten des aktuellen Bildes online Bag-of-Word-Vektoren und Merkmalsvektoren generiert. Mainstream-SLAM-Frameworks neigen aufgrund ihres geringen Speicherbedarfs und der einfachen Vergleichsmethoden dazu, manuell festgelegte binäre Deskriptoren zu verwenden. Um die Effizienz der Methode weiter zu verbessern, verwendet SP-Loop eine Gaußsche Verteilung mit einem Erwartungswert von 0 und einer Standardabweichung von 0,07, um den Wert des Superpunktdeskriptors darzustellen. Daher kann der 256-dimensionale Gleitkomma-Deskriptor des Superpunkts binär codiert werden, um die Abfragegeschwindigkeit der visuellen Standorterkennung zu verbessern. Die binäre Kodierung ist in Gleichung 4 dargestellt.
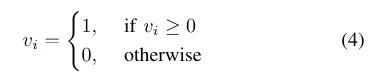
Grundlegender Prozess: Die Erkennung von Schleifenschließungen in SLAM umfasst normalerweise drei Schlüsselphasen: Finden der anfänglichen Schlüsselbilder für Schleifenschließungskandidaten, Überprüfen von Schlüsselbildern für Schleifenschließungskandidaten und Durchführen einer Schleifenschließungskorrektur und einer globalen Bündelanpassung (Bundle Adjustment, BA).
Der erste Schritt im Startvorgang besteht darin, erste Kandidaten-Keyframes für den Schleifenschluss zu identifizieren. Dies wird durch die Nutzung des zuvor trainierten DBoW3-Bag-of-Words-Modells erreicht. Keyframes, die das Vokabular mit dem aktuellen Frame Ka teilen, werden identifiziert, Keyframes, die mit Ka gemeinsam sichtbar sind, werden jedoch ausgeschlossen. Berechnen Sie die Gesamtpunktzahl der mit diesen Kandidaten-Keyframes verbundenen gemeinsam sichtbaren Keyframes. Wählen Sie aus den Top-N-Gruppen mit den höchsten Bewertungen unter den Keyframes der Closed-Loop-Kandidaten den Keyframe mit der höchsten Bewertung aus. Dieser ausgewählte Keyframe wird in km ausgedrückt.
Als nächstes müssen Sie die relative Haltungstransformation Tam von Km zum aktuellen Schlüsselrahmen Ka bestimmen. In ORB-SLAM3 wird eine auf Bag-of-Words basierende Feature-Matching-Methode verwendet, um den aktuellen Schlüsselrahmen mit dem Kandidaten-Schlüsselrahmen Km und seinem gleichzeitig sichtbaren Schlüsselrahmen Kco abzugleichen. Es ist erwähnenswert, dass der Lightglue-Algorithmus die Matching-Effizienz erheblich verbessert und der Matching des aktuellen Frames mit dem Kandidaten-Frame Km zu qualitativ hochwertigen Kartenpunktkorrespondenzen führt. Anschließend wird der RANSAC-Algorithmus angewendet, um Ausreißer zu eliminieren, und die Sim(3)-Transformation wird gelöst, um die anfängliche relative Lage Tam zu bestimmen. Um eine fehlerhafte Positionsidentifizierung zu vermeiden, werden Kandidaten-Keyframes geometrisch überprüft und die nachfolgenden Schritte ähneln ORB-SLAM3.
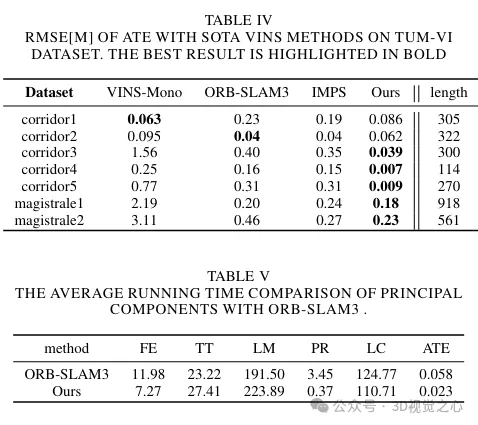
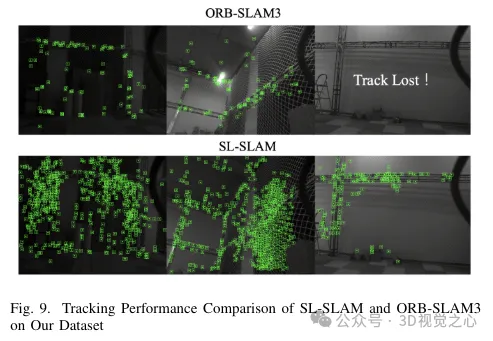
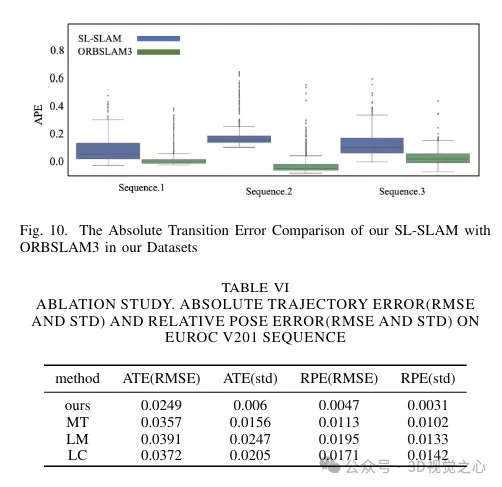
Experimentelle Vergleichsanalyse
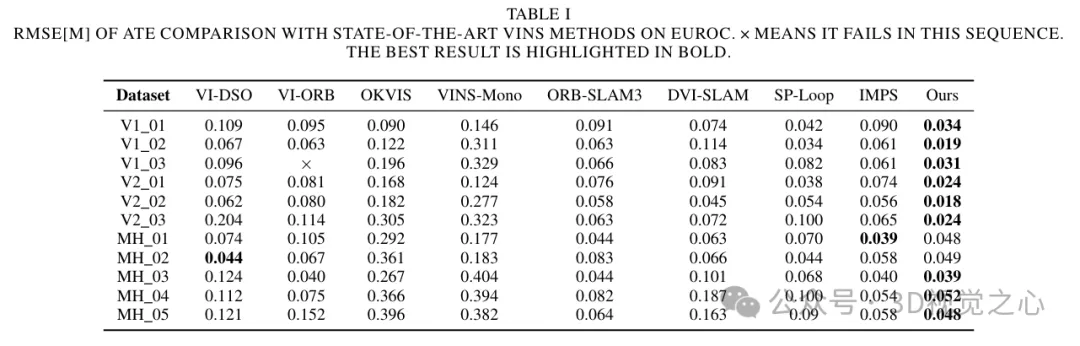
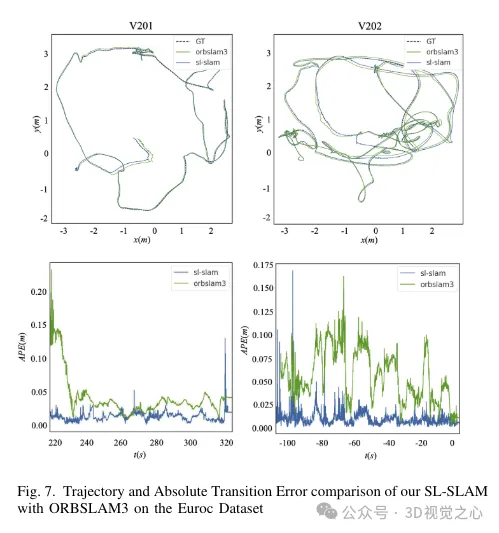
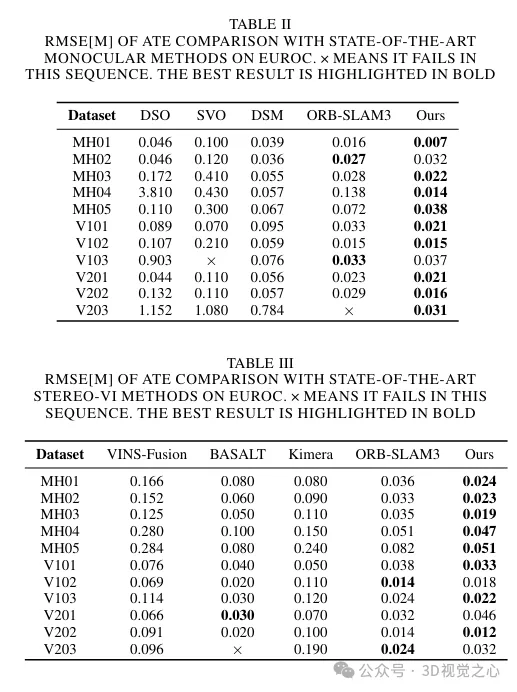
Das obige ist der detaillierte Inhalt vonJenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heißer Artikel

Hot-Tools-Tags

Heißer Artikel

Heiße Artikel -Tags

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
Jan 22, 2024 pm 04:24 PM
Methoden und Schritte zur Verwendung von BERT für die Stimmungsanalyse in Python
 Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
Dec 28, 2023 pm 11:35 PM
Analyse häufig verwendeter KI-Aktivierungsfunktionen: Deep-Learning-Praxis von Sigmoid, Tanh, ReLU und Softmax
 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
 Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latente Raumeinbettung: Erklärung und Demonstration
Jan 22, 2024 pm 05:30 PM
Latente Raumeinbettung: Erklärung und Demonstration
 Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
Mar 02, 2024 am 11:19 AM
Verstehen Sie in einem Artikel: die Zusammenhänge und Unterschiede zwischen KI, maschinellem Lernen und Deep Learning
 Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
Mar 15, 2024 pm 03:46 PM
Super stark! Top 10 Deep-Learning-Algorithmen!
 Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
Jun 02, 2024 pm 03:24 PM
Die erste rein visuelle statische Rekonstruktion des autonomen Fahrens
 So verwenden Sie CNN- und Transformer-Hybridmodelle, um die Leistung zu verbessern
Jan 24, 2024 am 10:33 AM
So verwenden Sie CNN- und Transformer-Hybridmodelle, um die Leistung zu verbessern
Jan 24, 2024 am 10:33 AM
So verwenden Sie CNN- und Transformer-Hybridmodelle, um die Leistung zu verbessern
