
 Technologie-Peripheriegeräte
KI
Handzerreißen von Llama3 Schicht 1: Implementierung von llama3 von Grund auf
Technologie-Peripheriegeräte
KI
Handzerreißen von Llama3 Schicht 1: Implementierung von llama3 von Grund auf
Handzerreißen von Llama3 Schicht 1: Implementierung von llama3 von Grund auf

1. Architektur von Llama3
In dieser Artikelserie implementieren wir Lama3 von Grund auf.
Die Gesamtarchitektur von Llama3:
 Bilder
Bilder
Die Modellparameter von Llama3:
Werfen wir einen Blick auf die tatsächlichen Werte dieser Parameter im LlaMa 3-Modell.
 Bilder
Bilder
[1] Kontextfenster (Kontextfenster)
Beim Instanziieren der LlaMa-Klasse definiert die Variable max_seq_len das Kontextfenster. Es gibt andere Parameter in der Klasse, aber dieser Parameter steht in direktem Zusammenhang mit dem Transformatormodell. Die max_seq_len beträgt hier 8K.
 Bilder
Bilder
[2] Vokabulargröße und Aufmerksamkeitsebenen
Die Transformer-Klasse ist ein Modell, das Vokabular und Anzahl der Ebenen definiert. Vokabular bezieht sich hier auf die Menge an Wörtern (und Token), die das Modell erkennen und verarbeiten kann. Aufmerksamkeitsschichten beziehen sich auf den im Modell verwendeten Transformatorblock (eine Kombination aus Aufmerksamkeits- und Feed-Forward-Schichten).
 Bilder
Bilder
Diesen Zahlen zufolge hat LlaMa 3 einen Wortschatz von 128K, was ziemlich groß ist. Darüber hinaus verfügt es über 32 Transformatorblöcke.
[3] Feature-Dimension und Aufmerksamkeitsköpfe
Feature-Dimension und Aufmerksamkeitsköpfe werden in das Modul Selbstaufmerksamkeit eingeführt. Die Merkmalsdimension bezieht sich auf die Vektorgröße von Token im Einbettungsraum (die Merkmalsdimension bezieht sich auf die Dimensionsgröße der Eingabedaten oder des Einbettungsvektors), während Aufmerksamkeitsköpfe das QK-Modul umfassen, das den Selbstaufmerksamkeitsmechanismus in Transformatoren steuert.
 Bilder
Bilder
[4] Versteckte Dimensionen
Versteckte Dimensionen beziehen sich auf die Dimensionsgröße der verborgenen Schicht im Feed-Forward-Neuronalen Netzwerk (Feed Forward). Feedforward-Neuronale Netze enthalten normalerweise eine oder mehrere verborgene Schichten, und die Abmessungen dieser verborgenen Schichten bestimmen die Kapazität und Komplexität des Netzwerks. Im Transformer-Modell beträgt die verborgene Schichtdimension des vorwärtsgerichteten neuronalen Netzwerks normalerweise ein Vielfaches der Merkmalsdimension, um die Darstellungsfähigkeit des Modells zu erhöhen. In LLama3 beträgt die verborgene Dimension das 1,3-fache der Feature-Dimension. Es ist zu beachten, dass es sich bei verborgenen Schichten und verborgenen Dimensionen um zwei Konzepte handelt.
Eine höhere Anzahl verborgener Ebenen ermöglicht es dem Netzwerk, intern umfangreichere Darstellungen zu erstellen und zu bearbeiten, bevor sie wieder in kleinere Ausgabedimensionen projiziert werden.
 Bild
Bild
[5] Kombinieren Sie die oben genannten Parameter zu einem Transformator
Die erste Matrix ist die Eingabe-Feature-Matrix, die von der Aufmerksamkeitsschicht verarbeitet wird, um aufmerksamkeitsgewichtete Features zu generieren. In diesem Bild ist die Eingabe-Feature-Matrix nur 5 x 3 groß, aber im echten Llama 3-Modell wächst sie auf 8K x 4096, was riesig ist.
Als nächstes folgen die verborgenen Schichten im Feed-Forward-Netzwerk, die auf 5325 anwachsen und dann in der letzten Schicht auf 4096 zurückfallen.
 Bilder
Bilder
[6] Mehrere Ebenen von Transformer-Blöcken
LlaMa 3 kombiniert die oben genannten 32 Transformer-Blöcke und die Ausgabe wird von einem Block zum nächsten weitergeleitet, bis sie den letzten erreicht.
 Bilder
Bilder
[7] Alles zusammenfügen
Sobald wir mit allen oben genannten Teilen begonnen haben, ist es an der Zeit, sie zusammenzusetzen und zu sehen, wie sie den LlaMa-Effekt erzeugen.
 Bilder
Bilder
Schritt 1: Zuerst haben wir unsere Eingabematrix mit der Größe 8K (Kontextfenster) x 128K (Vokabulargröße). Diese Matrix durchläuft einen Einbettungsprozess, um diese hochdimensionale Matrix in eine niedrigdimensionale Matrix umzuwandeln.
Schritt 2: In diesem Fall wird dieses niedrigdimensionale Ergebnis zu 4096, was der angegebenen Dimension der Features im LlaMa-Modell entspricht, das wir zuvor gesehen haben.
In neuronalen Netzen sind Dimensionsverstärkung und Dimensionsreduktion übliche Vorgänge, die jeweils unterschiedliche Zwecke und Auswirkungen haben.
Dimensionserweiterung dient normalerweise dazu, die Kapazität des Modells zu erhöhen, damit es komplexere Merkmale und Muster erfassen kann. Wenn die Eingabedaten in einen höherdimensionalen Raum abgebildet werden, können verschiedene Merkmalskombinationen vom Modell leichter unterschieden werden. Dies ist besonders nützlich, wenn es um nichtlineare Probleme geht, da es dem Modell helfen kann, komplexere Entscheidungsgrenzen zu lernen.
Dimensionalitätsreduzierung dient dazu, die Komplexität des Modells und das Risiko einer Überanpassung zu verringern. Durch die Reduzierung der Dimensionalität des Merkmalsraums kann das Modell gezwungen werden, verfeinerte und allgemeinere Merkmalsdarstellungen zu lernen. Darüber hinaus kann die Dimensionsreduktion als Regularisierungsmethode verwendet werden, um die Generalisierungsfähigkeit des Modells zu verbessern. In einigen Fällen kann die Reduzierung der Dimensionalität auch die Rechenkosten senken und die Betriebseffizienz des Modells verbessern.
In praktischen Anwendungen kann die Strategie der Dimensionserhöhung und anschließenden Dimensionsreduzierung als Prozess der Merkmalsextraktion und -transformation angesehen werden. In diesem Prozess untersucht das Modell zunächst die intrinsische Struktur der Daten durch Erhöhen der Dimensionalität und extrahiert dann die nützlichsten Merkmale und Muster durch Reduzieren der Dimensionalität. Dieser Ansatz kann dazu beitragen, dass das Modell eine Überanpassung an die Trainingsdaten vermeidet und gleichzeitig eine ausreichende Komplexität beibehält.
Schritt 3: Diese Funktion wird durch den Transformer-Block verarbeitet, zuerst durch die Aufmerksamkeitsschicht und dann durch die FFN-Schicht. Die Aufmerksamkeitsschicht verarbeitet Features horizontal, während die FFN-Schicht dimensionsübergreifend vertikal verarbeitet.
Schritt 4: Schritt 3 wird für 32 Schichten des Transformer-Blocks wiederholt. Schließlich sind die Abmessungen der resultierenden Matrix dieselben wie die für die Merkmalsabmessungen verwendeten.
Schritt 5: Abschließend wird diese Matrix wieder in die ursprüngliche Vokabularmatrixgröße von 128 KB konvertiert, damit das Modell die im Vokabular verfügbaren Wörter auswählen und zuordnen kann.
So schneidet LlaMa 3 in diesen Benchmarks gut ab und erzeugt den LlaMa 3-Effekt.
Wir fassen einige leicht zu verwechselnde Begriffe kurz zusammen:
1. max_seq_len (maximale Sequenzlänge)
Dies ist die maximale Anzahl von Token, die das Modell in einer einzelnen Verarbeitung akzeptieren kann.
Im LlaMa 3-8B-Modell ist dieser Parameter auf 8.000 Token eingestellt, d. h. Kontextfenstergröße = 8K. Das bedeutet, dass das Modell maximal 8.000 Token in einer einzelnen Verarbeitung berücksichtigen kann. Dies ist entscheidend, um lange Texte zu verstehen oder den Kontext langfristiger Gespräche aufrechtzuerhalten.
2. Vokabulargröße
Dies ist die Anzahl aller verschiedenen Token, die das Modell erkennen kann. Dazu gehören alle möglichen Wörter, Satzzeichen und Sonderzeichen. Der Wortschatz des Modells beträgt 128.000, ausgedrückt als Vokabulargröße = 128 KB. Das bedeutet, dass das Modell 128.000 verschiedene Token erkennen und verarbeiten kann, darunter verschiedene Wörter, Satzzeichen und Sonderzeichen.
3. Aufmerksamkeitsschichten
Eine Hauptkomponente im Transformer-Modell. Es ist hauptsächlich für die Verarbeitung von Eingabedaten verantwortlich, indem es lernt, welche Teile der Eingabedaten am wichtigsten sind (d. h. welche Token „beaufsichtigt“ werden). Ein Modell kann über mehrere solcher Ebenen verfügen, von denen jede versucht, die Eingabedaten aus einer anderen Perspektive zu verstehen.
Das Modell LlaMa 3-8B enthält 32 Verarbeitungsebenen, d. h. Anzahl der Ebenen = 32. Zu diesen Schichten gehören mehrere Aufmerksamkeitsschichten und andere Arten von Netzwerkschichten, von denen jede die Eingabedaten aus einer anderen Perspektive verarbeitet und versteht.
4. Transformer-Block
Enthält Module aus mehreren verschiedenen Schichten, normalerweise einschließlich mindestens einer Aufmerksamkeitsschicht und eines Feed-Forward-Netzwerks. Ein Modell kann mehrere Transformatorblöcke haben, die nacheinander verbunden sind und der Ausgang jedes Blocks der Eingang des nächsten Blocks ist. Der Transformatorblock kann auch als Decoderschicht bezeichnet werden.
Im Kontext des Transformer-Modells sagen wir normalerweise, dass das Modell „32 Schichten“ hat, was gleichbedeutend damit sein kann, dass das Modell „32 Transformer-Blöcke“ hat. Jeder Transformer-Block enthält normalerweise eine Selbstaufmerksamkeitsschicht und eine Feed-Forward-Neuronale Netzwerkschicht. Diese beiden Unterschichten bilden zusammen eine vollständige Verarbeitungseinheit oder „Schicht“.
Wenn wir also sagen, dass das Modell 32 Transformer-Blöcke hat, beschreiben wir eigentlich, dass das Modell aus 32 solchen Verarbeitungseinheiten besteht, von denen jede zur Selbstaufmerksamkeitsverarbeitung und zur Feed-Forward-Netzwerkverarbeitung von Daten fähig ist. Diese Präsentation betont die hierarchische Struktur des Modells und seine Verarbeitungsmöglichkeiten auf jeder Ebene.
Zusammenfassend sind „32 Schichten“ und „32 Transformer-Blöcke“ bei der Beschreibung der Transformer-Modellstruktur grundsätzlich synonym. Beide bedeuten, dass das Modell 32 unabhängige Datenverarbeitungszyklen enthält und jeder Zyklus Selbstaufmerksamkeit und Feedforward-Netzwerkbetrieb umfasst.
5. Feature-Dimension
Dies ist die Dimension jedes Vektors, wenn das Eingabetoken als Vektor im Modell dargestellt wird.
Jedes Token wird in einen Vektor umgewandelt, der 4096 Features im Modell enthält, d. h. Feature-Dimension = 4096. Diese hohe Dimension ermöglicht es dem Modell, umfangreichere semantische Informationen und Kontextbeziehungen zu erfassen.
6. Aufmerksamkeitsköpfe
In jeder Aufmerksamkeitsebene kann es mehrere Aufmerksamkeitsköpfe geben, und jeder Kopf analysiert die Eingabedaten unabhängig aus verschiedenen Perspektiven.
Jede Aufmerksamkeitsschicht enthält 32 unabhängige Aufmerksamkeitsköpfe, d. h. Anzahl der Aufmerksamkeitsköpfe = 32. Diese Köpfe analysieren Eingabedaten unter verschiedenen Aspekten und bieten gemeinsam umfassendere Datenanalysefunktionen.
7. Versteckte Dimensionen
Dies bezieht sich normalerweise auf die Breite der Schicht im Feed-Forward-Netzwerk, also auf die Anzahl der Neuronen in jeder Schicht. Normalerweise sind versteckte Dimensionen größer als Feature-Dimensionen, wodurch das Modell intern eine umfassendere Datendarstellung erstellen kann.
In Feed-Forward-Netzwerken beträgt die Dimension der verborgenen Schicht 5325, d. h. versteckte Dimensionen = 5325. Dies ist größer als die Feature-Dimension, sodass das Modell eine tiefere Feature-Übersetzung und ein tieferes Lernen zwischen internen Schichten durchführen kann.
Beziehungen und Werte:
Beziehung zwischen Aufmerksamkeitsebenen und Aufmerksamkeitsköpfen: Jede Aufmerksamkeitsebene kann mehrere Aufmerksamkeitsköpfe enthalten.
Numerische Beziehung: Ein Modell kann mehrere Transformatorblöcke haben, jeder Block enthält eine Aufmerksamkeitsschicht und eine oder mehrere andere Schichten. Jede Aufmerksamkeitsschicht kann mehrere Aufmerksamkeitsköpfe haben. Auf diese Weise führt das gesamte Modell eine komplexe Datenverarbeitung in verschiedenen Schichten und Köpfen durch.
Laden Sie das offizielle Linkskript des Llama3-Modells herunter: https://llama.meta.com/llama-downloads/
2. Sehen Sie sich das Modell an
Der folgende Code zeigt, wie Sie die Tiktoken-Bibliothek zum Laden und Verwenden von a verwenden Bytepaarbasierter Tokenizer für die Kodierung (BPE). Dieser Tokenizer wurde für die Verarbeitung von Textdaten entwickelt, insbesondere für den Einsatz in Modellen zur Verarbeitung natürlicher Sprache und für maschinelles Lernen.
Wir betreten „Hallo Welt“ und sehen, wie der Wortsegmentierer die Wortsegmentierung durchführt.
from pathlib import Pathimport tiktokenfrom tiktoken.load import load_tiktoken_bpeimport torchimport jsonimport matplotlib.pyplot as plttokenizer_path = "Meta-Llama-3-8B/tokenizer.model"special_tokens = ["<|begin_of_text|>","<|end_of_text|>","<|reserved_special_token_0|>","<|reserved_special_token_1|>","<|reserved_special_token_2|>","<|reserved_special_token_3|>","<|start_header_id|>","<|end_header_id|>","<|reserved_special_token_4|>","<|eot_id|>",# end of turn] + [f"<|reserved_special_token_{i}|>" for i in range(5, 256 - 5)]mergeable_ranks = load_tiktoken_bpe(tokenizer_path)tokenizer = tiktoken.Encoding(name=Path(tokenizer_path).name,pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",mergeable_ranks=mergeable_ranks,special_tokens={token: len(mergeable_ranks) + i for i, token in enumerate(special_tokens)},)tokenizer.decode(tokenizer.encode("hello world!")) Bilder
Bilder
Modelldatei lesen

Sehen Sie sich die Namen der ersten 20 Parameter oder Gewichte an, die in der geladenen Modelldatei enthalten sind.
model = torch.load("Meta-Llama-3-8B/consolidated.00.pth")print(json.dumps(list(model.keys())[:20], indent=4)) Pictures
Pictures
- „tok_embeddings.weight“: Dies zeigt an, dass das Modell über eine Worteinbettungsschicht verfügt, die Eingabewörter (oder allgemeiner Token) in Vektoren mit fester Dimension umwandelt. Dies ist der erste Schritt in den meisten Modellen zur Verarbeitung natürlicher Sprache.
- „layers.0.attention…“ und „layers.1.attention…“: Diese Parameter stellen mehrere Schichten dar, wobei jede Schicht ein Aufmerksamkeitsmechanismusmodul enthält. In diesem Modul repräsentieren wq, wk, wv und wo die Gewichtsmatrizen von Abfrage, Schlüssel, Wert und Ausgabe. Dies ist die Kernkomponente des Transformer-Modells und wird verwendet, um die Beziehung zwischen verschiedenen Teilen der Eingabesequenz zu erfassen.
- „layers.0.feed_forward…“ und „layers.1.feed_forward…“: Diese Parameter geben an, dass jede Schicht auch ein Feed-Forward-Netzwerk (Feed Forward Network) enthält, das normalerweise aus zwei linearen Transformationen besteht. In der Mitte gibt es eine nichtlineare Aktivierungsfunktion. w1, w2 und w3 können die Gewichte verschiedener linearer Schichten in diesem Feedforward-Netzwerk darstellen.
- „layers.0.attention_norm.weight“ und „layers.1.attention_norm.weight“: Diese Parameter geben an, dass sich hinter dem Aufmerksamkeitsmodul in jeder Schicht eine Normalisierungsschicht (möglicherweise Layer Normalization) für den Stabilisierungstrainingsprozess befindet.
- "layers.0.ffn_norm.weight" und "layers.1.ffn_norm.weight": Diese Parameter zeigen an, dass sich hinter dem Feedforward-Netzwerk auch eine Normalisierungsschicht befindet. Der Ausgabeinhalt des obigen Codes ist derselbe wie im Bild unten, einem Transformatorblock in Llama3.
 Bilder
Bilder
Insgesamt zeigt diese Ausgabe die Schlüsselkomponenten eines Deep-Learning-Modells auf Basis der Transformer-Architektur. Dieses Modell wird häufig bei der Verarbeitung natürlicher Sprache verwendet, beispielsweise bei der Textklassifizierung, maschinellen Übersetzung, Frage-Antwort-Systemen usw. Die Struktur jeder Schicht ist nahezu gleich, einschließlich Aufmerksamkeitsmechanismus, Feed-Forward-Netzwerk und Normalisierungsschicht, was dem Modell hilft, komplexe Eingabesequenzmerkmale zu erfassen.
Sehen Sie sich die Parameterkonfiguration des Llama3-Modells an:
with open("Meta-Llama-3-8B/params.json", "r") as f:config = json.load(f)config 图片
图片
- 'dim': 4096 - 表示模型中的隐藏层维度或特征维度。这是模型处理数据时每个向量的大小。
- 'n_layers': 32 - 表示模型中层的数量。在基于Transformer的模型中,这通常指的是编码器和解码器中的层的数量。
- 'n_heads': 32 - 表示在自注意力(Self-Attention)机制中,头(head)的数量。多头注意力机制是Transformer模型的关键特性之一,它允许模型在不同的表示子空间中并行捕获信息。
- 'n_kv_heads': 8 - 这个参数不是标准Transformer模型的常见配置,可能指的是在某些特定的注意力机制中,用于键(Key)和值(Value)的头的数量。
- 'vocab_size': 128256 - 表示模型使用的词汇表大小。这是模型能够识别的不同单词或标记的总数。
- 'multiple_of': 1024 - 这可能是指模型的某些维度需要是1024的倍数,以确保模型结构的对齐或优化。
- 'ffn_dim_multiplier': 1.3 - 表示前馈网络(Feed-Forward Network, FFN)的维度乘数。在Transformer模型中,FFN是每个注意力层后的一个网络,这个乘数可能用于调整FFN的大小。
- 'norm_eps': 1e-05 - 表示在归一化层(如Layer Normalization)中使用的epsilon值,用于防止除以零的错误。这是数值稳定性的一个小技巧。
- 'rope_theta': 500000.0 - 这个参数不是标准Transformer模型的常见配置,可能是指某种特定于模型的技术或优化的参数。它可能与位置编码或某种正则化技术有关。
我们使用这个配置来推断模型的细节,比如:
- 模型有32个Transformer层
- 每个多头注意力块有32个头
- 词汇表的大小等等
dim = config["dim"]n_layers = config["n_layers"]n_heads = config["n_heads"]n_kv_heads = config["n_kv_heads"]vocab_size = config["vocab_size"]multiple_of = config["multiple_of"]ffn_dim_multiplier = config["ffn_dim_multiplier"]norm_eps = config["norm_eps"]rope_theta = torch.tensor(config["rope_theta"])
 图片
图片
将Text转化为Token
代码如下:
prompt = "the answer to the ultimate question of life, the universe, and everything is "tokens = [128000] + tokenizer.encode(prompt)print(tokens)tokens = torch.tensor(tokens)prompt_split_as_tokens = [tokenizer.decode([token.item()]) for token in tokens]print(prompt_split_as_tokens)
[128000, 1820, 4320, 311, 279, 17139, 3488, 315, 2324, 11, 279, 15861, 11, 323, 4395, 374, 220]['<|begin_of_text|>', 'the', ' answer', ' to', ' the', ' ultimate', ' question', ' of', ' life', ',', ' the', ' universe', ',', ' and', ' everything', ' is', ' ']
将令牌转换为它们的嵌入表示
截止到目前,我们的[17x1]令牌现在变成了[17x4096],即长度为4096的17个嵌入(每个令牌一个)。
下图是为了验证我们输入的这句话,是17个token。
 图片
图片
代码如下:
embedding_layer = torch.nn.Embedding(vocab_size, dim)embedding_layer.weight.data.copy_(model["tok_embeddings.weight"])token_embeddings_unnormalized = embedding_layer(tokens).to(torch.bfloat16)token_embeddings_unnormalized.shape
 图片
图片
三、构建Transformer的第一层
我们接着使用 RMS 归一化对嵌入进行归一化,也就是图中这个位置:
 图片
图片
使用公式如下:
 图片
图片
代码如下:
# def rms_norm(tensor, norm_weights):# rms = (tensor.pow(2).mean(-1, keepdim=True) + norm_eps)**0.5# return tensor * (norm_weights / rms)def rms_norm(tensor, norm_weights):return (tensor * torch.rsqrt(tensor.pow(2).mean(-1, keepdim=True) + norm_eps)) * norm_weights
这段代码定义了一个名为 rms_norm 的函数,它实现了对输入张量(tensor)的RMS(Root Mean Square,均方根)归一化处理。这个函数接受两个参数:tensor 和 norm_weights。tensor 是需要进行归一化处理的输入张量,而 norm_weights 是归一化时使用的权重。
函数的工作原理如下:
- 首先,计算输入张量每个元素的平方(tensor.pow(2))。
- 然后,对平方后的张量沿着最后一个维度(-1)计算均值(mean),并保持维度不变(keepdim=True),这样得到每个元素的均方值。
- 接着,将均方值加上一个很小的正数 norm_eps(为了避免除以零的情况),然后计算其平方根的倒数(torch.rsqrt),得到RMS的倒数。
- 最后,将输入张量与RMS的倒数相乘,再乘以归一化权重 norm_weights,得到归一化后的张量。
在进行归一化处理后,我们的数据形状仍然保持为 [17x4096],这与嵌入层的形状相同,只不过数据已经过归一化。
token_embeddings = rms_norm(token_embeddings_unnormalized, model["layers.0.attention_norm.weight"])token_embeddings.shape
 图片
图片
 图片
图片
接下来,我们介绍注意力机制的实现,也就是下图中的红框标注的位置:
 图片
图片
 图片
图片
1. 输入句子
- 描述:这是我们的输入句子。
- 解释:输入句子被表示为一个矩阵 ( X ),其中每一行代表一个词的嵌入向量。
2. 嵌入每个词
- 描述:我们对每个词进行嵌入。
- 解释:输入句子中的每个词被转换为一个高维向量,这些向量组成了矩阵 ( X )。
3. 分成8个头
- 描述:将矩阵 ( X ) 分成8个头。我们用权重矩阵 ( W^Q )、( W^K ) 和 ( W^V ) 分别乘以 ( X )。
- 解释:多头注意力机制将输入矩阵 ( X ) 分成多个头(这里是8个),每个头有自己的查询(Query)、键(Key)和值(Value)矩阵。具体来说,输入矩阵 ( X ) 分别与查询权重矩阵 ( W^Q )、键权重矩阵 ( W^K ) 和值权重矩阵 ( W^V ) 相乘,得到查询矩阵 ( Q )、键矩阵 ( K ) 和值矩阵 ( V )。
4. 计算注意力
- 描述:使用得到的查询、键和值矩阵计算注意力。
- 解释:对于每个头,使用查询矩阵 ( Q )、键矩阵 ( K ) 和值矩阵 ( V ) 计算注意力分数。具体步骤包括:
计算 ( Q ) 和 ( K ) 的点积。
对点积结果进行缩放。
应用softmax函数得到注意力权重。
用注意力权重乘以值矩阵 ( V ) 得到输出矩阵 ( Z )。
5. 拼接结果矩阵
- 描述:将得到的 ( Z ) 矩阵拼接起来,然后用权重矩阵 ( W^O ) 乘以拼接后的矩阵,得到层的输出。
- 解释:将所有头的输出矩阵 ( Z ) 拼接成一个矩阵,然后用输出权重矩阵 ( W^O ) 乘以这个拼接后的矩阵,得到最终的输出矩阵 ( Z )。
额外说明
- 查询、键、值和输出向量的形状:在加载查询、键、值和输出向量时,注意到它们的形状分别是 [4096x4096]、[1024x4096]、[1024x4096]、[1024x4096] 和 [4096x4096]。
- 并行化注意力头的乘法:将它们捆绑在一起有助于并行化注意力头的乘法。
这张图展示了Transformer模型中多头注意力机制的实现过程,从输入句子的嵌入开始,经过多头分割、注意力计算,最后拼接结果并生成输出。每个步骤都详细说明了如何从输入矩阵 ( X ) 生成最终的输出矩阵 ( Z )。
当我们从模型中加载查询(query)、键(key)、值(value)和输出(output)向量时,我们注意到它们的形状分别是 [4096x4096]、[1024x4096]、[1024x4096]、[4096x4096]
乍一看这很奇怪,因为理想情况下我们希望每个头的每个q、k、v和o都是单独的
print(model["layers.0.attention.wq.weight"].shape,model["layers.0.attention.wk.weight"].shape,model["layers.0.attention.wv.weight"].shape,model["layers.0.attention.wo.weight"].shape)
 Bild
Bild
Die Form der Abfragegewichtsmatrix (wq.weight) ist [4096, 4096]. Die Form der Schlüsselgewichtsmatrix (wk.weight) ist [1024, 4096]. Die Form der Wertgewichtungsmatrix (wv.weight) ist [1024, 4096]. Die Form der Ausgabegewichtsmatrix (Wo.weight) ist [4096, 4096]. Die Ausgabeergebnisse zeigen, dass die Formen der Gewichtsmatrizen der Abfrage (Q) und der Ausgabe (O) gleich sind, beide [4096, 4096]. Dies bedeutet, dass sowohl das Eingabe-Feature als auch das Ausgabe-Feature sowohl für die Abfrage als auch für die Ausgabe die Dimension 4096 haben. Die Formen der Schlüssel- (K) und Werte- (V) Gewichtsmatrizen sind ebenfalls gleich, beide [1024, 4096]. Dies zeigt, dass die Eingabe-Feature-Abmessungen für Schlüssel und Werte 4096 betragen, die Ausgabe-Feature-Abmessungen jedoch auf 1024 komprimiert sind. Die Form dieser Gewichtsmatrizen spiegelt wider, wie der Modelldesigner die Abmessungen verschiedener Teile des Aufmerksamkeitsmechanismus festlegt. Insbesondere werden die Dimensionen von Schlüsseln und Werten reduziert, wahrscheinlich um die Rechenkomplexität und den Speicherverbrauch zu reduzieren, während Abfragen und Ausgaben höher in der Dimensionalität gehalten werden können, um mehr Informationen zu behalten. Diese Designauswahl hängt von der spezifischen Modellarchitektur und dem Anwendungsszenario ab.
Lassen Sie uns den Satz „Ich bewundere Li Hongzhang“ als Beispiel verwenden, um den Implementierungsprozess zur Erläuterung des Aufmerksamkeitsmechanismus in dieser Abbildung zu vereinfachen. Geben Sie den Satz ein: Zuerst haben wir den Satz „Ich bewundere Li Hongzhang“. Bevor wir diesen Satz verarbeiten, müssen wir jedes Wort im Satz in eine mathematisch verarbeitbare Form umwandeln, nämlich in einen Wortvektor. Dieser Vorgang wird Worteinbettung genannt.
Worteinbettung: Jedes Wort, wie „I“, „Appreciation“, „Li Hongzhang“, wird in einen Vektor fester Größe umgewandelt. Diese Vektoren enthalten die semantischen Informationen der Wörter.
In mehrere Köpfe aufteilen: Damit das Modell den Satz aus verschiedenen Perspektiven verstehen kann, teilen wir den Vektor jedes Wortes in mehrere Teile auf, hier sind 8 Köpfe. Jeder Kopf konzentriert sich auf einen anderen Aspekt des Satzes.
Aufmerksamkeit berechnen: Für jeden Kopf berechnen wir etwas namens Aufmerksamkeit. Dieser Prozess umfasst drei Schritte: Nehmen wir „Ich schätze Li Hongzhang“ als Beispiel. Wenn wir uns auf das Wort „Wertschätzung“ konzentrieren wollen, dann ist „Wertschätzung“ die Abfrage und andere Wörter wie „Ich“ und „Li Hongzhang“. sind Schlüssel. Der Vektor von ist der Wert.
Abfrage (F): Dies ist der Teil, in dem wir Informationen finden möchten. Schlüssel (K): Dies ist der Teil, der die Informationen enthält. Wert (V): Dies ist der eigentliche Informationsgehalt. Spleißen und Ausgabe: Nachdem wir die Aufmerksamkeit jedes Kopfes berechnet haben, verketten wir diese Ergebnisse und generieren die endgültige Ausgabe über eine Gewichtsmatrix Wo. Diese Ausgabe wird in der nächsten Verarbeitungsebene oder als Teil des Endergebnisses verwendet.
Bei dem in den Kommentaren zur Abbildung erwähnten Formproblem geht es darum, wie diese Vektoren effizient in einem Computer gespeichert und verarbeitet werden können. Um die Effizienz zu verbessern, können Entwickler bei der tatsächlichen Codeimplementierung die Abfrage-, Schlüssel- und Wertvektoren mehrerer Header zusammenpacken, anstatt jeden Header einzeln zu verarbeiten. Dadurch können die Parallelverarbeitungsfähigkeiten moderner Computer genutzt werden, um Berechnungen zu beschleunigen.
- Die Form der Abfragegewichtsmatrix (wq.weight) ist [4096, 4096].
- Die Form der Schlüsselgewichtsmatrix (wk.weight) ist [1024, 4096]. Die Form der
- Value-Gewichtsmatrix (wv.weight) ist [1024, 4096].
- Die Form der Ausgabegewichtsmatrix (Wo.weight) ist [4096, 4096].
Die Ausgabeergebnisse zeigen, dass:
- Die Formen der Abfrage- (Q) und Ausgabegewichtsmatrizen (O) sind beide gleich [4096, 4096]. Dies bedeutet, dass sowohl das Eingabe-Feature als auch das Ausgabe-Feature sowohl für die Abfrage als auch für die Ausgabe die Dimension 4096 haben.
- Die Formen der Schlüssel- (K) und Wert- (V) Gewichtsmatrizen sind ebenfalls gleich, beide [1024, 4096]. Dies zeigt, dass die Eingabe-Feature-Abmessungen für Schlüssel und Werte 4096 betragen, die Ausgabe-Feature-Abmessungen jedoch auf 1024 komprimiert sind.
Die Form dieser Gewichtsmatrizen spiegelt wider, wie der Modelldesigner die Abmessungen verschiedener Teile des Aufmerksamkeitsmechanismus festlegt. Insbesondere werden die Dimensionen von Schlüsseln und Werten reduziert, wahrscheinlich um die Rechenkomplexität und den Speicherverbrauch zu reduzieren, während Abfragen und Ausgaben höher in der Dimensionalität gehalten werden können, um mehr Informationen zu behalten. Diese Designauswahl hängt von der spezifischen Modellarchitektur und dem Anwendungsszenario ab.
Verwenden wir den Satz „Ich bewundere Li Hongzhang“ als Beispiel, um den Implementierungsprozess zur Erläuterung des Aufmerksamkeitsmechanismus in dieser Abbildung zu vereinfachen.
- Geben Sie den Satz ein: Zuerst haben wir den Satz „Ich bewundere Li Hongzhang“. Bevor wir diesen Satz verarbeiten, müssen wir jedes Wort im Satz in eine mathematisch verarbeitbare Form umwandeln, nämlich in einen Wortvektor. Dieser Vorgang wird Worteinbettung genannt.
- Worteinbettung: Jedes Wort, wie zum Beispiel „I“, „Appreciation“, „Li Hongzhang“, wird in einen Vektor fester Größe umgewandelt. Diese Vektoren enthalten die semantischen Informationen der Wörter.
- In mehrere Köpfe aufteilen: Damit das Modell den Satz aus verschiedenen Perspektiven verstehen kann, teilen wir den Vektor jedes Wortes in mehrere Teile auf, hier sind 8 Köpfe. Jeder Kopf konzentriert sich auf einen anderen Aspekt des Satzes.
- Aufmerksamkeit berechnen: Für jeden Kopf berechnen wir etwas namens Aufmerksamkeit. Dieser Prozess umfasst drei Schritte: Nehmen wir „Ich schätze Li Hongzhang“ als Beispiel. Wenn wir uns auf das Wort „Wertschätzung“ konzentrieren wollen, dann ist „Wertschätzung“ die Abfrage und andere Wörter wie „Ich“ und „Li Hongzhang“. sind Schlüssel. Der Vektor von ist der Wert.
Abfrage (F): Dies ist der Teil, in dem wir Informationen finden möchten.
Schlüssel (K): Dies ist der Teil, der Informationen enthält.
Wert (V): Dies ist der eigentliche Informationsgehalt.
- Spleißen und Ausgabe: Nachdem wir die Aufmerksamkeit jedes Kopfes berechnet haben, fügen wir diese Ergebnisse zusammen und generieren die endgültige Ausgabe über eine Gewichtsmatrix Wo. Diese Ausgabe wird in der nächsten Verarbeitungsebene oder als Teil des Endergebnisses verwendet.
Bei dem in den Kommentaren zur Abbildung erwähnten Formproblem geht es darum, wie diese Vektoren effizient in einem Computer gespeichert und verarbeitet werden können. Um die Effizienz zu verbessern, können Entwickler bei der tatsächlichen Codeimplementierung die Abfrage-, Schlüssel- und Wertvektoren mehrerer Header zusammenpacken, anstatt jeden Header einzeln zu verarbeiten. Dadurch können die Parallelverarbeitungsfähigkeiten moderner Computer genutzt werden, um Berechnungen zu beschleunigen.
Wir verwenden weiterhin den Satz „Ich schätze Li Hongzhang“, um die Rolle der Gewichtsmatrizen WQ, WK, WV und WO zu erklären.
Im Transformer-Modell wird jedes Wort durch Worteinbettung in einen Vektor umgewandelt. Diese Vektoren durchlaufen dann eine Reihe linearer Transformationen, um Aufmerksamkeitswerte zu berechnen. Diese linearen Transformationen werden durch die Gewichtsmatrizen WQ, WK, WV und WO umgesetzt.
- WQ (Gewichtsmatrix Q): Diese Matrix wird verwendet, um den Vektor jedes Wortes in einen „Abfrage“-Vektor umzuwandeln. Wenn wir uns in unserem Beispiel auf das Wort „Wertschätzung“ konzentrieren möchten, multiplizieren wir den Vektor „Wertschätzung“ mit WQ, um den Abfragevektor zu erhalten.
- WK (Gewichtsmatrix K): Diese Matrix wird verwendet, um den Vektor jedes Wortes in einen „Schlüssel“-Vektor umzuwandeln. In ähnlicher Weise multiplizieren wir den Vektor jedes Wortes, einschließlich „I“ und „Li Hongzhang“, mit WK, um den Schlüsselvektor zu erhalten.
- WV (Gewichtsmatrix V): Diese Matrix wird verwendet, um den Vektor jedes Wortes in einen „Wert“-Vektor umzuwandeln. Nachdem wir jeden Wortvektor mit WV multipliziert haben, erhalten wir einen Wertevektor. Diese drei Matrizen (WQ, WK, WV) werden verwendet, um für jeden Header unterschiedliche Abfrage-, Schlüssel- und Wertvektoren zu generieren. Auf diese Weise kann sich jeder Kopf auf einen anderen Aspekt des Satzes konzentrieren.
- WQ (Gewichtsmatrix Q), WK (Gewichtsmatrix K), WV (Gewichtsmatrix V) und WO (Gewichtsmatrix O) Diese Matrizen werden während des Modelltrainings durch den Backpropagation-Algorithmus geleitet Der Prozess wird aus Optimierungsmethoden wie dem Gradientenabstieg gelernt.
Im gesamten Prozess werden WQ, WK, WV und WO durch Training gelernt. Sie bestimmen, wie das Modell die eingegebenen Wortvektoren in verschiedene Darstellungen umwandelt und wie diese Darstellungen kombiniert werden, um die endgültige Ausgabe zu erhalten. Diese Matrizen sind der Kernbestandteil des Aufmerksamkeitsmechanismus im Transformer-Modell und ermöglichen es dem Modell, die Beziehung zwischen verschiedenen Wörtern im Satz zu erfassen.
WQ (Gewichtsmatrix Q), WK (Gewichtsmatrix K), WV (Gewichtsmatrix V) und WO (Gewichtsmatrix O) sind Parameter im Transformer-Modell. Sie werden während des Modelltrainingsprozesses durch Backpropagation geleitet Es wird aus Optimierungsmethoden wie Algorithmen und Gradientenabstieg gelernt.
Mal sehen, wie dieser Lernprozess funktioniert:
- 初始化:在训练开始之前,这些矩阵通常会被随机初始化。这意味着它们的初始值是随机选取的,这样可以打破对称性并开始学习过程。
- 前向传播:在模型的训练过程中,输入数据(如句子“我欣赏李鸿章”)会通过模型的各个层进行前向传播。在注意力机制中,输入的词向量会与WQ、WK、WV矩阵相乘,以生成查询、键和值向量。
- 计算损失:模型的输出会与期望的输出(通常是训练数据中的标签)进行比较,计算出一个损失值。这个损失值衡量了模型的预测与实际情况的差距。
- 反向传播:损失值会通过反向传播算法传回模型,计算每个参数(包括WQ、WK、WV和WO)对损失的影响,即它们的梯度。
- 参数更新:根据计算出的梯度,使用梯度下降或其他优化算法来更新这些矩阵的值。这个过程会逐渐减小损失值,使模型的预测更加准确。
- 迭代过程:这个前向传播、损失计算、反向传播和参数更新的过程会在训练数据上多次迭代进行,直到模型的性能达到一定的标准或者不再显著提升。
通过这个训练过程,WQ、WK、WV和WO这些矩阵会逐渐调整它们的值,以便模型能够更好地理解和处理输入数据。在训练完成后,这些矩阵将固定下来,用于模型的推理阶段,即对新的输入数据进行预测。
四、展开查询向量
在本小节中,我们将从多个注意力头中展开查询向量,得到的形状是 [32x128x4096] 这里,32 是 llama3 中注意力头的数量,128 是查询向量的大小,而 4096 是令牌嵌入的大小。
q_layer0 = model["layers.0.attention.wq.weight"]head_dim = q_layer0.shape[0] // n_headsq_layer0 = q_layer0.view(n_heads, head_dim, dim)q_layer0.shape
 图片
图片
这段代码通过对模型中第一层的查询(Q)权重矩阵进行重塑(reshape),将其分解为多个注意力头的形式,从而揭示了32和128这两个维度。
- q_layer0 = model["layers.0.attention.wq.weight"]:这行代码从模型中提取第一层的查询(Q)权重矩阵。
- head_dim = q_layer0.shape[0] // n_heads:这行代码计算每个注意力头的维度大小。它通过将查询权重矩阵的第一个维度(原本是4096)除以注意力头的数量(n_heads),得到每个头的维度。如果n_heads是32(即模型设计为有32个注意力头),那么head_dim就是4096 // 32 = 128。
- q_layer0 = q_layer0.view(n_heads, head_dim, dim):这行代码使用.view()方法重塑查询权重矩阵,使其形状变为[n_heads, head_dim, dim]。这里dim很可能是原始特征维度4096,n_heads是32,head_dim是128,因此重塑后的形状是[32, 128, 4096]。
- q_layer0.shape 输出:torch.Size([32, 128, 4096]):这行代码打印重塑后的查询权重矩阵的形状,确认了其形状为[32, 128, 4096]。
之所以在这段代码中出现了32和128这两个维度,而在之前的代码段中没有,是因为这段代码通过重塑操作明确地将查询权重矩阵分解为多个注意力头,每个头具有自己的维度。32代表了模型中注意力头的数量,而128代表了分配给每个头的特征维度大小。这种分解是为了实现多头注意力机制,其中每个头可以独立地关注输入的不同部分,最终通过组合这些头的输出来提高模型的表达能力。
实现第一层的第一个头
访问了第一层第一个头的查询(query)权重矩阵,这个查询权重矩阵的大小是 [128x4096]。
q_layer0_head0 = q_layer0[0]q_layer0_head0.shape
 图片
图片
我们现在将查询权重与令牌嵌入相乘,以获得令牌的查询
在这里,你可以看到结果形状是 [17x128],这是因为我们有17个令牌,每个令牌都有一个长度为128的查询(每个令牌在一个头上方的查询)。
br
 Bild
Bild
Dieser Code führt eine Matrixmultiplikationsoperation durch und vergleicht die Token-Einbettungen (token_embeddings) mit der Transponierten (.T) der Abfragegewichtsmatrix (q_layer0_head0) des ersten Kopfes der ersten Ebene. Multiplizieren Sie, um eine Per zu generieren -token-Abfragevektor (q_per_token).
- q_per_token = Torch.matmul(token_embeddings, q_layer0_head0.T):
torch.matmul ist die Matrixmultiplikationsfunktion in PyTorch, die die Multiplikation zweier Tensoren verarbeiten kann.
token_embeddings sollte ein Tensor der Form [17, 4096] sein, der 17 Token darstellt, die jeweils durch einen 4096-dimensionalen Einbettungsvektor dargestellt werden.
q_layer0_head0 ist die Abfragegewichtsmatrix des ersten Kopfes der ersten Ebene und ihre ursprüngliche Form ist [128, 4096]. .T ist die Transponierungsoperation in PyTorch, die die Form von q_layer0_head0 in [4096, 128] transponiert.
Auf diese Weise ist die Matrixmultiplikation von token_embeddings und q_layer0_head0.T die Multiplikation von [17, 4096] und [4096, 128], und das Ergebnis ist ein Tensor mit der Form [17, 128].
- q_per_token.shape und Ausgabe: Torch.Size([17, 128]):
Diese Codezeile gibt die Form des q_per_token-Tensors aus und bestätigt, dass es sich um [17, 128] handelt.
Das bedeutet, dass wir für jeden eingegebenen Token (insgesamt 17) nun einen 128-dimensionalen Abfragevektor haben. Dieser 128-dimensionale Abfragevektor wird durch Multiplikation der Token-Einbettung und der Abfragegewichtsmatrix erhalten und kann für nachfolgende Berechnungen des Aufmerksamkeitsmechanismus verwendet werden.
Zusammenfassend wandelt dieser Code den Einbettungsvektor jedes Tokens durch Matrixmultiplikation in einen Abfragevektor um und bereitet so den nächsten Schritt der Implementierung des Aufmerksamkeitsmechanismus vor. Zu jedem Token gehört nun ein Abfragevektor, und diese Abfragevektoren werden zur Berechnung der Aufmerksamkeitswerte mit anderen Token verwendet.
Das obige ist der detaillierte Inhalt vonHandzerreißen von Llama3 Schicht 1: Implementierung von llama3 von Grund auf. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Vergleichende Analyse von Deep-Learning-Architekturen
May 17, 2023 pm 04:34 PM
Das Konzept des Deep Learning stammt aus der Erforschung künstlicher neuronaler Netze. Ein mehrschichtiges Perzeptron, das mehrere verborgene Schichten enthält, ist eine Deep-Learning-Struktur. Deep Learning kombiniert Funktionen auf niedriger Ebene, um abstraktere Darstellungen auf hoher Ebene zu bilden, um Kategorien oder Merkmale von Daten darzustellen. Es ist in der Lage, verteilte Merkmalsdarstellungen von Daten zu erkennen. Deep Learning ist eine Form des maschinellen Lernens, und maschinelles Lernen ist der einzige Weg, künstliche Intelligenz zu erreichen. Was sind also die Unterschiede zwischen verschiedenen Deep-Learning-Systemarchitekturen? 1. Vollständig verbundenes Netzwerk (FCN) Ein vollständig verbundenes Netzwerk (FCN) besteht aus einer Reihe vollständig verbundener Schichten, wobei jedes Neuron in jeder Schicht mit jedem Neuron in einer anderen Schicht verbunden ist. Sein Hauptvorteil besteht darin, dass es „strukturunabhängig“ ist, d. h. es sind keine besonderen Annahmen über die Eingabe erforderlich. Obwohl dieser strukturelle Agnostiker das Ganze abschließt
 „AI Factory' wird die Neugestaltung des gesamten Software-Stacks vorantreiben, und NVIDIA stellt Llama3-NIM-Container für die Bereitstellung durch Benutzer bereit
Jun 08, 2024 pm 07:25 PM
„AI Factory' wird die Neugestaltung des gesamten Software-Stacks vorantreiben, und NVIDIA stellt Llama3-NIM-Container für die Bereitstellung durch Benutzer bereit
Jun 08, 2024 pm 07:25 PM
Laut Nachrichten dieser Website vom 2. Juni stellte Huang Renxun bei der laufenden Keynote-Rede von Huang Renxun 2024 Taipei Computex vor, dass generative künstliche Intelligenz die Neugestaltung des gesamten Software-Stacks fördern wird, und demonstrierte seine cloudnativen Mikrodienste NIM (Nvidia Inference Microservices). . Nvidia glaubt, dass die „KI-Fabrik“ eine neue industrielle Revolution auslösen wird: Am Beispiel der von Microsoft vorangetriebenen Softwareindustrie glaubt Huang Renxun, dass generative künstliche Intelligenz deren Umgestaltung im gesamten Stack vorantreiben wird. Um die Bereitstellung von KI-Diensten durch Unternehmen jeder Größe zu erleichtern, hat NVIDIA im März dieses Jahres die cloudnativen Mikrodienste NIM (Nvidia Inference Microservices) eingeführt. NIM+ ist eine Suite cloudnativer Mikroservices, die darauf optimiert sind, die Markteinführungszeit zu verkürzen
 Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Multipfad, Multidomäne, alles inklusive! Google AI veröffentlicht das allgemeine Modell MDL für Multi-Domain-Lernen
May 28, 2023 pm 02:12 PM
Deep-Learning-Modelle für Sehaufgaben (z. B. Bildklassifizierung) werden normalerweise durchgängig mit Daten aus einem einzelnen visuellen Bereich (z. B. natürlichen Bildern oder computergenerierten Bildern) trainiert. Im Allgemeinen muss eine Anwendung, die Vision-Aufgaben für mehrere Domänen ausführt, mehrere Modelle für jede einzelne Domäne erstellen und diese unabhängig voneinander trainieren. Während der Inferenz verarbeitet jedes Modell eine bestimmte Domäne. Auch wenn sie auf unterschiedliche Bereiche ausgerichtet sind, sind einige Merkmale der frühen Schichten zwischen diesen Modellen ähnlich, sodass das gemeinsame Training dieser Modelle effizienter ist. Dies reduziert die Latenz und den Stromverbrauch und reduziert die Speicherkosten für die Speicherung jedes Modellparameters. Dieser Ansatz wird als Multi-Domain-Learning (MDL) bezeichnet. Darüber hinaus können MDL-Modelle auch Single-Modelle übertreffen
 Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Was ist die Architektur und das Arbeitsprinzip von Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA basiert auf der JPA-Architektur und interagiert mit der Datenbank über Mapping, ORM und Transaktionsmanagement. Sein Repository bietet CRUD-Operationen und abgeleitete Abfragen vereinfachen den Datenbankzugriff. Darüber hinaus nutzt es Lazy Loading, um Daten nur bei Bedarf abzurufen und so die Leistung zu verbessern.
 Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Dieser „Fehler' ist nicht wirklich ein Fehler: Beginnen Sie mit vier klassischen Aufsätzen, um zu verstehen, was am Transformer-Architekturdiagramm „falsch' ist
Jun 14, 2023 pm 01:43 PM
Vor einiger Zeit löste ein Tweet, der auf die Inkonsistenz zwischen dem Transformer-Architekturdiagramm und dem Code im Papier „AttentionIsAllYouNeed“ des Google Brain-Teams hinwies, viele Diskussionen aus. Manche Leute halten Sebastians Entdeckung für einen unbeabsichtigten Fehler, aber sie ist auch überraschend. Angesichts der Popularität des Transformer-Papiers hätte diese Inkonsistenz schließlich tausendmal erwähnt werden müssen. Sebastian Raschka antwortete auf Kommentare von Internetnutzern, dass der „originellste“ Code zwar mit dem Architekturdiagramm übereinstimme, die 2017 eingereichte Codeversion jedoch geändert, das Architekturdiagramm jedoch nicht gleichzeitig aktualisiert worden sei. Dies ist auch die Ursache für „inkonsistente“ Diskussionen.
 Docker schließt die lokale Bereitstellung des großen Open-Source-Modells LLama3 in drei Minuten ab
Apr 26, 2024 am 10:19 AM
Docker schließt die lokale Bereitstellung des großen Open-Source-Modells LLama3 in drei Minuten ab
Apr 26, 2024 am 10:19 AM
Übersicht LLaMA-3 (LargeLanguageModelMetaAI3) ist ein groß angelegtes Open-Source-Modell für generative künstliche Intelligenz, das von Meta Company entwickelt wurde. Im Vergleich zur Vorgängergeneration LLaMA-2 gibt es keine wesentlichen Änderungen in der Modellstruktur. Das LLaMA-3-Modell ist in verschiedene Maßstabsversionen unterteilt, darunter kleine, mittlere und große, um unterschiedlichen Anwendungsanforderungen und Rechenressourcen gerecht zu werden. Die Parametergröße kleiner Modelle beträgt 8 B, die Parametergröße mittlerer Modelle beträgt 70 B und die Parametergröße großer Modelle erreicht 400 B. Beim Training besteht das Ziel jedoch darin, multimodale und mehrsprachige Funktionalität zu erreichen, und die Ergebnisse werden voraussichtlich mit GPT4/GPT4V vergleichbar sein. Ollama installierenOllama ist ein Open-Source-Großsprachenmodell (LL
 1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms dauert 1,3 ms! Tsinghuas neueste Open-Source-Architektur für mobile neuronale Netzwerke RepViT
Mar 11, 2024 pm 12:07 PM
Papieradresse: https://arxiv.org/abs/2307.09283 Codeadresse: https://github.com/THU-MIG/RepViTRepViT funktioniert gut in der mobilen ViT-Architektur und zeigt erhebliche Vorteile. Als nächstes untersuchen wir die Beiträge dieser Studie. In dem Artikel wird erwähnt, dass Lightweight-ViTs bei visuellen Aufgaben im Allgemeinen eine bessere Leistung erbringen als Lightweight-CNNs, hauptsächlich aufgrund ihres Multi-Head-Selbstaufmerksamkeitsmoduls (MSHA), das es dem Modell ermöglicht, globale Darstellungen zu lernen. Allerdings wurden die architektonischen Unterschiede zwischen Lightweight-ViTs und Lightweight-CNNs noch nicht vollständig untersucht. In dieser Studie integrierten die Autoren leichte ViTs in die effektiven
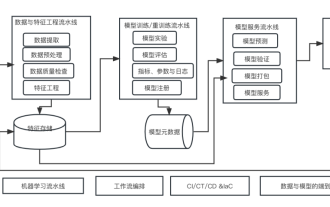 Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Zehn Elemente der Systemarchitektur für maschinelles Lernen
Apr 13, 2023 pm 11:37 PM
Dies ist eine Ära der Stärkung der KI, und maschinelles Lernen ist ein wichtiges technisches Mittel zur Verwirklichung von KI. Gibt es also eine universelle Systemarchitektur für maschinelles Lernen? Im kognitiven Bereich erfahrener Programmierer ist „Alles“ nichts, insbesondere für die Systemarchitektur. Es ist jedoch möglich, eine skalierbare und zuverlässige Systemarchitektur für maschinelles Lernen aufzubauen, sofern diese auf die meisten auf maschinellem Lernen basierenden Systeme oder Anwendungsfälle anwendbar ist. Aus Sicht des Lebenszyklus des maschinellen Lernens deckt diese sogenannte universelle Architektur wichtige Phasen des maschinellen Lernens ab, von der Entwicklung von Modellen für maschinelles Lernen bis hin zur Bereitstellung von Schulungssystemen und Servicesystemen in Produktionsumgebungen. Wir können versuchen, eine solche Systemarchitektur für maschinelles Lernen anhand der Dimensionen von 10 Elementen zu beschreiben. 1.
