
 Technologie-Peripheriegeräte
KI
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Technologie-Peripheriegeräte
KI
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung

1. Einführung
Die derzeit führenden Objektdetektoren sind zweistufige oder einstufige Netzwerke, die auf dem umfunktionierten Backbone-Klassifizierungsnetzwerk von Deep CNN basieren. YOLOv3 ist ein solcher bekannter hochmoderner einstufiger Detektor, der ein Eingabebild empfängt und es in eine gleich große Gittermatrix aufteilt. Für die Erkennung spezifischer Ziele sind Gitterzellen mit Zielzentren zuständig.
Was wir heute geteilt haben, ist, eine neue mathematische Methode vorzuschlagen, die jedem Ziel mehrere Gitter zuordnet, um eine genaue Vorhersage des eng anliegenden Begrenzungsrahmens zu erreichen. Die Forscher schlugen außerdem eine „effektive Offline-Datenverbesserung durch Kopieren und Einfügen zur Zielerkennung“ vor. Die neu vorgeschlagene Methode übertrifft einige aktuelle Objektdetektoren auf dem neuesten Stand der Technik deutlich und verspricht eine bessere Leistung. 2. Hintergrund
Objekterkennungsnetzwerke dienen dazu, Objekte auf Bildern zu lokalisieren und sie mithilfe präzise passender Begrenzungsrahmen genau zu kennzeichnen. In letzter Zeit gibt es zwei verschiedene Möglichkeiten, dies zu erreichen. Die erste Methode ist hinsichtlich der Leistung die zweistufige Objekterkennung. Der beste Vertreter ist das regionale Faltungs-Neuronale Netzwerk (RCNN) und seine Ableitungen [Schnelleres R-CNN: Auf dem Weg zur Echtzeit-Objekterkennung mit Regionsvorschlagsnetzwerken ], [Schnelles R-CNN]. Im Gegensatz dazu ist die zweite Gruppe von Objekterkennungsimplementierungen für ihre hervorragende Erkennungsgeschwindigkeit und ihr geringes Gewicht bekannt und wird als einstufige Netzwerke bezeichnet. Ein repräsentatives Beispiel ist [Sie schauen nur einmal: Einheitliche Echtzeit-Objekterkennung], [SSD: Single-Shot-Multibox-Detektor], [Fokusverlust für die Erkennung dichter Objekte]. Das zweistufige Netzwerk basiert auf einem Vorschlagsnetzwerk für latente Regionen, das Kandidatenregionen von Bildern generiert, die möglicherweise interessierende Objekte enthalten. Die von diesem Netzwerk generierten Kandidatenregionen können den interessierenden Bereich des Objekts enthalten. Bei der einstufigen Objekterkennung erfolgt die Erkennung gleichzeitig mit der Klassifizierung und Lokalisierung in einem vollständigen Vorwärtsdurchlauf. Daher sind einstufige Netzwerke typischerweise leichter, schneller und einfacher zu implementieren.Die heutige Forschung hält immer noch an der YOLO-Methode, insbesondere YOLOv3, und schlägt einen einfachen Hack vor, der mehrere Netzwerkeinheitselemente gleichzeitig verwenden kann, um Zielkoordinaten, Kategorien und Zielvertrauen vorherzusagen. Der Grundgedanke hinter Multi-Netzwerk-Einheitselementen pro Objekt besteht darin, die Wahrscheinlichkeit der Vorhersage eng anliegender Begrenzungsrahmen zu erhöhen, indem mehrere Einheitselemente gezwungen werden, an demselben Objekt zu arbeiten.

Zu den Vorteilen der Multi-Grid-Zuweisung gehören:

(b+) Weniger zufällige und unsichere Begrenzungsrahmenvorhersagen, was eine hohe Präzision und Wiedererkennung bedeutet, da benachbarte Netzwerkeinheiten darauf trainiert sind, dieselbe Objektkategorie und dieselben Koordinaten vorherzusagen Objekte von Interesse und Gitterzellen ohne Objekte von Interesse.
Da die Multi-Grid-Zuweisung außerdem eine mathematische Nutzung vorhandener Parameter ist und keine zusätzlichen Schlüsselpunkt-Pooling-Ebenen und Nachbearbeitung erfordert, um Schlüsselpunkte mit ihren entsprechenden Zielen wie CenterNet und CornerNet neu zu kombinieren, kann man sagen, dass dies der Fall ist ist ein natürlicherer Weg, um das zu erreichen, was ankerfreie oder schlüsselpunktbasierte Objektdetektoren erreichen wollen. Zusätzlich zu den redundanten Anmerkungen mit mehreren Rastern führten die Forscher auch eine neue, auf Offline-Kopieren und Einfügen basierende Datenverbesserungstechnologie für eine genaue Objekterkennung ein.
3. MULTI-GITTER-AUFGABE
Das obige Bild enthält drei Ziele, nämlich Hunde, Fahrräder und Autos. Der Kürze halber erklären wir unsere Multi-Grid-Zuweisung an einem Objekt. Das Bild oben zeigt die Begrenzungsrahmen von drei Objekten, mit weiteren Details zum Begrenzungsrahmen des Hundes. Das Bild unten zeigt einen verkleinerten Bereich des Bildes oben, wobei der Schwerpunkt auf der Mitte des Begrenzungsrahmens des Hundes liegt. Die obere linke Koordinate der Gitterzelle, die die Mitte des Begrenzungsrahmens des Hundes enthält, ist mit der Zahl 0 beschriftet, während die anderen acht Gitterzellen, die das Gitter umgeben, das die Mitte enthält, Beschriftungen von 1 bis 8 haben.

Bisher habe ich die grundlegenden Fakten erklärt, wie ein Netz, das die Mitte des Begrenzungsrahmens eines Objekts enthält, ein Objekt mit Anmerkungen versehen. Diese Abhängigkeit von nur einer Gitterzelle pro Objekt, um die schwierige Aufgabe der Vorhersage von Kategorien und präzisen, eng anliegenden Begrenzungsrahmen zu erfüllen, wirft viele Probleme auf, wie zum Beispiel:
(a) Riesige Lücke zwischen positiven und negativen Gittern, Ungleichgewicht, d. h. mit und ohne Gitterkoordinaten des Objektzentrums
(b) Langsame Konvergenz des Begrenzungsrahmens zu GT
(c) Fehlen von Mehrwinkelansichten (Winkelansichten) des vorherzusagenden Objekts.
Eine natürliche Frage, die hier gestellt werden sollte, lautet also: „Offensichtlich enthalten die meisten Objekte Bereiche mit mehr als einer Gitterzelle. Gibt es also eine einfache mathematische Möglichkeit, mehr dieser Gitterzellen zuzuweisen, um zu versuchen, die Kategorien und Koordinaten des Objekts vorherzusagen?“ zusammen mit der mittleren Gitterzelle?“ Einige Vorteile davon sind (a) ein geringeres Ungleichgewicht, (b) ein schnelleres Training zur Konvergenz zu Begrenzungsrahmen, da jetzt mehrere Gitterzellen gleichzeitig auf dasselbe Objekt zielen, (c) eine verbesserte Vorhersage eng anliegender Begrenzungsrahmen. Möglichkeit (d) bietet Raster- basierte Detektoren wie YOLOv3 mit Mehrfachansichten anstelle von Einzelpunktansichten von Objekten. Die neu vorgeschlagene Multigrid-Allokation versucht, die oben genannten Fragen zu beantworten. ?? äh und schneller. Ein Faltungsblock verfügt über eine Conv2D+Batch-Normalisierung+LeakyRelu. Die entfernten Blöcke stammen nicht aus dem Klassifizierungs-Backbone, also Darknet53. Entfernen Sie sie stattdessen aus drei Multiskalen-Erkennungs-Ausgangsnetzwerken oder -Köpfen, zwei aus jedem Ausgangsnetzwerk. Obwohl tiefe Netzwerke im Allgemeinen eine gute Leistung erbringen, neigen zu tiefe Netzwerke auch dazu, schnell überzupassen oder das Netzwerk erheblich zu verlangsamen.
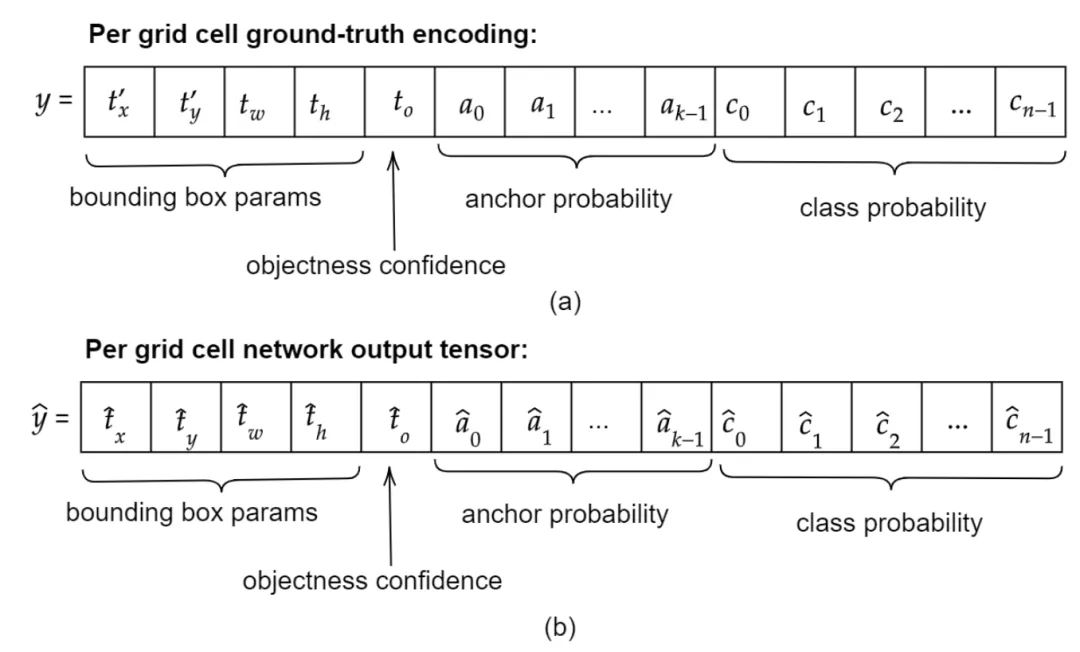 B. Die Verlustfunktion
B. Die Verlustfunktion
Koordinatenaktivierungsfunktionsdiagramm mit verschiedenen β-Werten
C. Datenerweiterung
Die manuelle Trainingsbildsynthese funktioniert wie folgt : Erstens: Verwenden Sie ein einfaches Bildsuchskript, um Tausende von objektfreien Hintergrundbildern von Google Bilder mit Schlüsselwörtern wie Wahrzeichen, Regen, Wald usw. herunterzuladen, d. h. Bilder ohne das Objekt, das uns interessiert. Anschließend wählen wir iterativ p Objekte und ihre Begrenzungsrahmen aus zufälligen q Bildern des gesamten Trainingsdatensatzes aus. Anschließend generieren wir alle möglichen Kombinationen von p ausgewählten Begrenzungsrahmen unter Verwendung ihrer Indizes als IDs. Aus der kombinierten Menge wählen wir eine Teilmenge von Begrenzungsrahmen aus, die die folgenden zwei Bedingungen erfüllen:
Wenn sie in zufälliger Reihenfolge nebeneinander angeordnet sind, müssen sie in einen bestimmten Zielhintergrundbildbereich passen
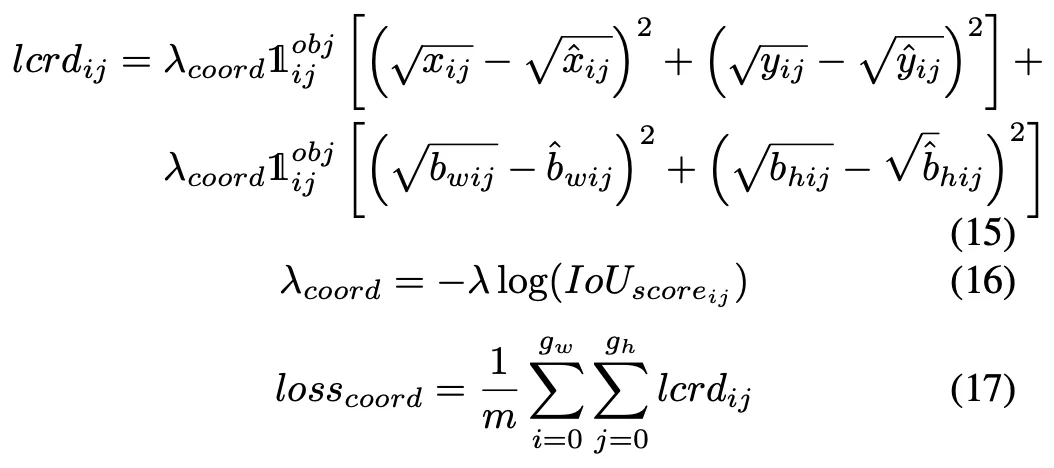
und sollten Nutzen Sie den gesamten Hintergrundbildraum oder zumindest den größten Teil davon effizient, ohne dass sich die Objekte überschneiden. Leistungsvergleich im Coco-Datensatz. Wie aus der Abbildung ersichtlich ist, zeigt die erste Zeile die sechs Eingabebilder, während die zweite Zeile das Netzwerk vor der nicht-maximalen Unterdrückung (NMS) zeigt. Die letzte Zeile zeigt die endgültige Bounding-Box-Vorhersage von MultiGridDet für das Eingabebild nach NMS. 
Das obige ist der detaillierte Inhalt vonRedundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1664
1664
 14
1422
52
1316
25
1267
29
1239
24
14
1422
52
1316
25
1267
29
1239
24

 Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
Redundante Begrenzungsrahmenanmerkung mit mehreren Gittern für eine genaue Objekterkennung
Jun 01, 2024 pm 09:46 PM
1. Einleitung Derzeit sind die führenden Objektdetektoren zweistufige oder einstufige Netzwerke, die auf dem umfunktionierten Backbone-Klassifizierungsnetzwerk von Deep CNN basieren. YOLOv3 ist ein solcher bekannter hochmoderner einstufiger Detektor, der ein Eingabebild empfängt und es in eine gleich große Gittermatrix aufteilt. Für die Erkennung spezifischer Ziele sind Gitterzellen mit Zielzentren zuständig. Was ich heute vorstelle, ist eine neue mathematische Methode, die jedem Ziel mehrere Gitter zuordnet, um eine genaue Vorhersage des Begrenzungsrahmens zu erreichen. Die Forscher schlugen außerdem eine effektive Offline-Datenverbesserung durch Kopieren und Einfügen für die Zielerkennung vor. Die neu vorgeschlagene Methode übertrifft einige aktuelle Objektdetektoren auf dem neuesten Stand der Technik deutlich und verspricht eine bessere Leistung. 2. Das Hintergrundzielerkennungsnetzwerk ist für die Verwendung konzipiert
 Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Neues SOTA zur Zielerkennung: YOLOv9 erscheint und die neue Architektur erweckt die traditionelle Faltung wieder zum Leben
Feb 23, 2024 pm 12:49 PM
Im Bereich der Zielerkennung macht YOLOv9 weiterhin Fortschritte im Implementierungsprozess. Durch die Einführung neuer Architekturen und Methoden wird die Parameternutzung der herkömmlichen Faltung effektiv verbessert, wodurch die Leistung den Produkten der vorherigen Generation weit überlegen ist. Mehr als ein Jahr nach der offiziellen Veröffentlichung von YOLOv8 im Januar 2023 ist YOLOv9 endlich da! Seit Joseph Redmon, Ali Farhadi und andere im Jahr 2015 das YOLO-Modell der ersten Generation vorgeschlagen haben, haben Forscher auf dem Gebiet der Zielerkennung es viele Male aktualisiert und iteriert. YOLO ist ein Vorhersagesystem, das auf globalen Bildinformationen basiert und dessen Modellleistung kontinuierlich verbessert wird. Durch die kontinuierliche Verbesserung von Algorithmen und Technologien haben Forscher bemerkenswerte Ergebnisse erzielt, die YOLO bei Zielerkennungsaufgaben immer leistungsfähiger machen.
 Schritte zum Einrichten des Kamerarasters auf dem iPhone
Mar 26, 2024 pm 07:21 PM
Schritte zum Einrichten des Kamerarasters auf dem iPhone
Mar 26, 2024 pm 07:21 PM
1. Öffnen Sie den Desktop Ihres iPhones, suchen Sie nach [Einstellungen] und klicken Sie darauf, um sie aufzurufen. 2. Klicken Sie auf der Einstellungsseite auf [Kamera], um sie aufzurufen. 3. Klicken Sie, um den Schalter auf der rechten Seite von [Raster] einzuschalten.
 Wie verwende ich C++ für eine leistungsstarke Bildverfolgung und Zielerkennung?
Aug 26, 2023 pm 03:25 PM
Wie verwende ich C++ für eine leistungsstarke Bildverfolgung und Zielerkennung?
Aug 26, 2023 pm 03:25 PM
Wie verwende ich C++ für eine leistungsstarke Bildverfolgung und Zielerkennung? Zusammenfassung: Mit der rasanten Entwicklung der künstlichen Intelligenz und der Computer-Vision-Technologie sind Bildverfolgung und Zielerkennung zu wichtigen Forschungsbereichen geworden. In diesem Artikel wird erläutert, wie mithilfe der C++-Sprache und einigen Open-Source-Bibliotheken eine leistungsstarke Bildverfolgung und Zielerkennung erreicht werden kann, und es werden Codebeispiele bereitgestellt. Einleitung: Bildverfolgung und Objekterkennung sind zwei wichtige Aufgaben im Bereich Computer Vision. Sie werden in vielen Bereichen eingesetzt, beispielsweise in der Videoüberwachung, beim autonomen Fahren, bei intelligenten Transportsystemen usw. für
 Mehrere SOTAs! OV-Uni3DETR: Verbesserung der Generalisierbarkeit der 3D-Erkennung über Kategorien, Szenen und Modalitäten hinweg (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
Mehrere SOTAs! OV-Uni3DETR: Verbesserung der Generalisierbarkeit der 3D-Erkennung über Kategorien, Szenen und Modalitäten hinweg (Tsinghua & HKU)
Apr 11, 2024 pm 07:46 PM
In diesem Artikel wird der Bereich der 3D-Objekterkennung erörtert, insbesondere die 3D-Objekterkennung für Open-Vocabulary. Bei herkömmlichen 3D-Objekterkennungsaufgaben müssen Systeme die Position von Objekten in realen Szenen, 3D-Begrenzungsrahmen und semantische Kategoriebezeichnungen vorhersagen, was normalerweise auf Punktwolken oder RGB-Bildern beruht. Obwohl die 2D-Objekterkennungstechnologie aufgrund ihrer Allgegenwärtigkeit und Geschwindigkeit gute Leistungen erbringt, zeigen einschlägige Untersuchungen, dass die Entwicklung der universellen 3D-Erkennung im Vergleich zurückbleibt. Derzeit basieren die meisten 3D-Objekterkennungsmethoden immer noch auf vollständig überwachtem Lernen und sind durch vollständig kommentierte Daten in bestimmten Eingabemodi eingeschränkt. Sie können nur Kategorien erkennen, die während des Trainings entstehen, sei es in Innen- oder Außenszenen. In diesem Artikel wird darauf hingewiesen, dass die Herausforderungen bei der universellen 3D-Zielerkennung hauptsächlich darin liegen
 CSS-Layout-Tipps: Best Practices für die Implementierung des kreisförmigen Rastersymbol-Layouts
Oct 20, 2023 am 10:46 AM
CSS-Layout-Tipps: Best Practices für die Implementierung des kreisförmigen Rastersymbol-Layouts
Oct 20, 2023 am 10:46 AM
CSS-Layout-Tipps: Best Practices für die Implementierung des kreisförmigen Rastersymbol-Layouts Das Rasterlayout ist eine gängige und leistungsstarke Layouttechnik im modernen Webdesign. Das kreisförmige Gittersymbol-Layout ist eine einzigartigere und interessantere Designwahl. In diesem Artikel werden einige Best Practices und spezifische Codebeispiele vorgestellt, die Ihnen bei der Implementierung eines kreisförmigen Rastersymbol-Layouts helfen. HTML-Struktur Zuerst müssen wir ein Containerelement einrichten und das Symbol in diesem Container platzieren. Wir können eine ungeordnete Liste (<ul>) als Container verwenden und die Listenelemente (<l
 Beispiel für Computer Vision in Python: Objekterkennung
Jun 10, 2023 am 11:36 AM
Beispiel für Computer Vision in Python: Objekterkennung
Jun 10, 2023 am 11:36 AM
Mit der Entwicklung der künstlichen Intelligenz ist die Computer-Vision-Technologie zu einem Schwerpunkt der Aufmerksamkeit der Menschen geworden. Als effiziente und leicht zu erlernende Programmiersprache genießt Python im Bereich Computer Vision weithin Anerkennung und wird gefördert. Dieser Artikel konzentriert sich auf ein Computer-Vision-Beispiel in Python: Objekterkennung. Was ist Objekterkennung? Die Objekterkennung ist eine Schlüsseltechnologie im Bereich Computer Vision. Ihr Zweck besteht darin, die Position und Größe eines bestimmten Objekts in einem Bild oder Video zu identifizieren. Im Vergleich zur Bildklassifizierung erfordert die Zielerkennung nicht nur die Identifizierung von Bildern
 Die neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +
Apr 09, 2023 am 11:41 AM
Die neueste Deep-Architektur zur Zielerkennung hat die Hälfte der Parameter und ist dreimal schneller +
Apr 09, 2023 am 11:41 AM
Kurze Einleitung Die Autoren der Studie schlagen Matrix Net (xNet) vor, eine neue tiefe Architektur zur Objekterkennung. xNets bilden Objekte mit unterschiedlichen Größenabmessungen und Seitenverhältnissen in Netzwerkschichten ab, wobei die Objekte innerhalb der Schicht nahezu einheitlich in Größe und Seitenverhältnis sind. Daher bieten xNets eine Architektur, die Größe und Seitenverhältnis berücksichtigt. Forscher nutzen xNets, um die schlüsselpunktbasierte Zielerkennung zu verbessern. Die neue Architektur erreicht mit 47,8 mAP im MS COCO-Datensatz eine höhere Zeiteffizienz als jeder andere Single-Shot-Detektor, verwendet dabei die Hälfte der Parameter und ist dreimal schneller zu trainieren als die nächstbesten Framework-Zeiten. Wie in der einfachen Ergebnisanzeige oben gezeigt, übertreffen die Parameter und die Effizienz von xNet die anderer Modelle bei weitem.
