

In Bezug auf das Lernen von Robotern besteht ein gängiger Ansatz darin, einen Datensatz zu sammeln, der für einen bestimmten Roboter und eine bestimmte Aufgabe spezifisch ist, und ihn dann zum Trainieren einer Richtlinie zu verwenden. Wenn diese Methode jedoch verwendet wird, um von Grund auf zu lernen, müssen für jede Aufgabe ausreichend Daten gesammelt werden, und die Generalisierungsfähigkeit der resultierenden Richtlinie ist normalerweise schlecht.
„Grundsätzlich können Erfahrungen, die mit anderen Robotern und Aufgaben gesammelt wurden, mögliche Lösungen liefern, die es dem Modell ermöglichen, eine Vielzahl von Robotersteuerungsproblemen zu erkennen, und diese Probleme können die allgemeine Leistung des Roboters bei nachgelagerten Aufgaben verbessern.“ Da es sich um allgemeine Modelle handelt, die eine Vielzahl natürlicher Sprach- und Computer-Vision-Aufgaben bewältigen können, ist es immer noch schwierig, ein „universelles Robotermodell“ zu erstellen, um eine einheitliche Steuerungsstrategie für den Roboter zu trainieren. Extrem schwierig und mit vielen Schwierigkeiten verbunden, einschließlich der Bedienung verschiedener Roboterkörper. Sensorkonfigurationen, Aktionsräume, Aufgabenspezifikationen, Umgebungen und Rechenbudgets.
Um dieses Ziel zu erreichen, sind einige Forschungsergebnisse im Zusammenhang mit dem „Roboter-Grundmodell“ erschienen. Ihr Ansatz besteht darin, Roboterbeobachtungen direkt in Aktionen abzubilden und sie dann durch Null-Beispiel-Lösungen auf neue Bereiche oder neue Roboter zu übertragen. Diese Modelle werden oft als „generalistische Roboterrichtlinien“ oder GRPs bezeichnet, die die Fähigkeit des Roboters betonen, eine visuomotorische Kontrolle auf niedriger Ebene über eine Vielzahl von Aufgaben, Umgebungen und Robotersystemen hinweg durchzuführen.
GNM (Allgemeines Navigationsmodell) eignet sich für eine Vielzahl unterschiedlicher Roboternavigationsszenarien. RT-X kann je nach Missionsziel fünf verschiedene Roboterkörper bedienen. Obwohl diese Modelle tatsächlich einen wichtigen Fortschritt darstellen, weisen sie auch mehrere Einschränkungen auf: Ihre Eingabebeobachtungen sind oft vordefiniert und oft begrenzt (z. B. ist es schwierig, sie in diesen Bereichen effektiv zu optimieren); Modelle Die größten Versionen stehen nicht zur Nutzung zur Verfügung (das ist wichtig).
Kürzlich veröffentlichte das Octo Model Team, bestehend aus 18 Forschern der University of California, Berkeley, der Stanford University, der Carnegie Mellon University und Google DeepMind, seine bahnbrechenden Forschungsergebnisse: das Octo-Modell. Dieses Projekt überwindet effektiv die oben genannten Einschränkungen.

Der Kern des Modells ist die Transformer-Architektur, die beliebige Eingabe-Tokens (basierend auf Beobachtungen und Aufgaben erstellt) in Ausgabe-Tokens abbildet (die dann in Aktionen kodiert werden) und diese Architektur kann mit verschiedenen Roboter- und Aufgabendatensätzen verwendet werden Zug. Die Richtlinie kann ohne zusätzliche Schulung verschiedene Kamerakonfigurationen akzeptieren, verschiedene Roboter steuern und sich durch verbale Befehle oder Zielbilder leiten lassen – alles durch einfaches Ändern der in das Modell eingegebenen Token.
Am wichtigsten ist, dass sich das Modell auch an neue Roboterkonfigurationen mit unterschiedlichen Sensoreingängen, Betriebsräumen oder Robotermorphologien anpassen kann. Dazu ist lediglich die Übernahme eines geeigneten Adapters und die Verwendung eines kleinen Zieldomänendatensatzes und einer kleinen Menge erforderlich Berechnen Sie das Budget für die Feinabstimmung.
Darüber hinaus wurde Octo auch mit dem bisher größten Robotermanipulationsdatensatz vorab trainiert – 800.000 Roboterdemonstrationen aus dem Open X-Embodiment-Datensatz. Octo ist nicht nur das erste GRP, das effizient auf neue Beobachtungs- und Aktionsräume abgestimmt ist, es ist auch die erste generalistische Robotermanipulationsstrategie, die vollständig Open Source ist (Trainingsworkflow, Modellkontrollpunkte und Daten). Das Team hob in dem Papier auch den einzigartigen und innovativen Charakter seiner kombinierten Octo-Komponenten hervor.
Octo-Modell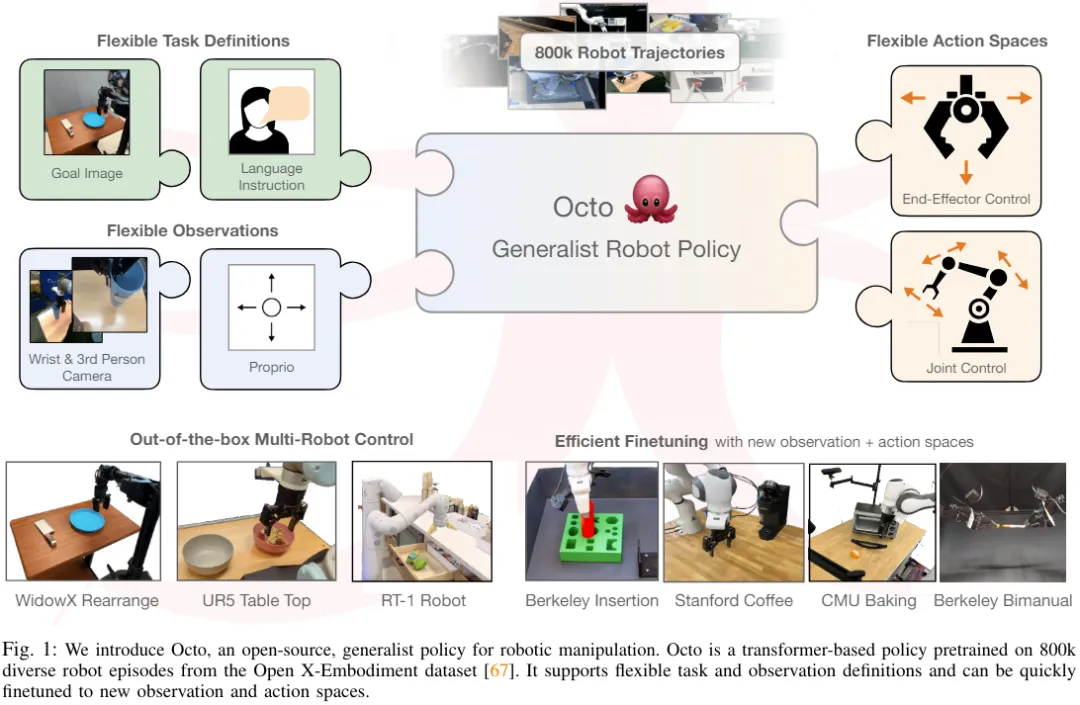
Architektur
Der Kern von Octo basiert auf Transformers Strategie π. Es enthält drei Schlüsselteile: den Eingabe-Tokenizer, das Transformer-Backbone-Netzwerk und den Auslesekopf.
Wie in Abbildung 2 dargestellt, besteht die Funktion des Eingabe-Tokenizers darin, Sprachanweisungen, Ziele und Beobachtungssequenzen in Token umzuwandeln. Das Transformer-Backbone verarbeitet diese Token in Einbettungen und der Auslesekopf erhält die erforderliche Ausgabe. das heißt, Aktion. „Tokenizer für Aufgaben und Beobachtungen“ Tokenisierer:
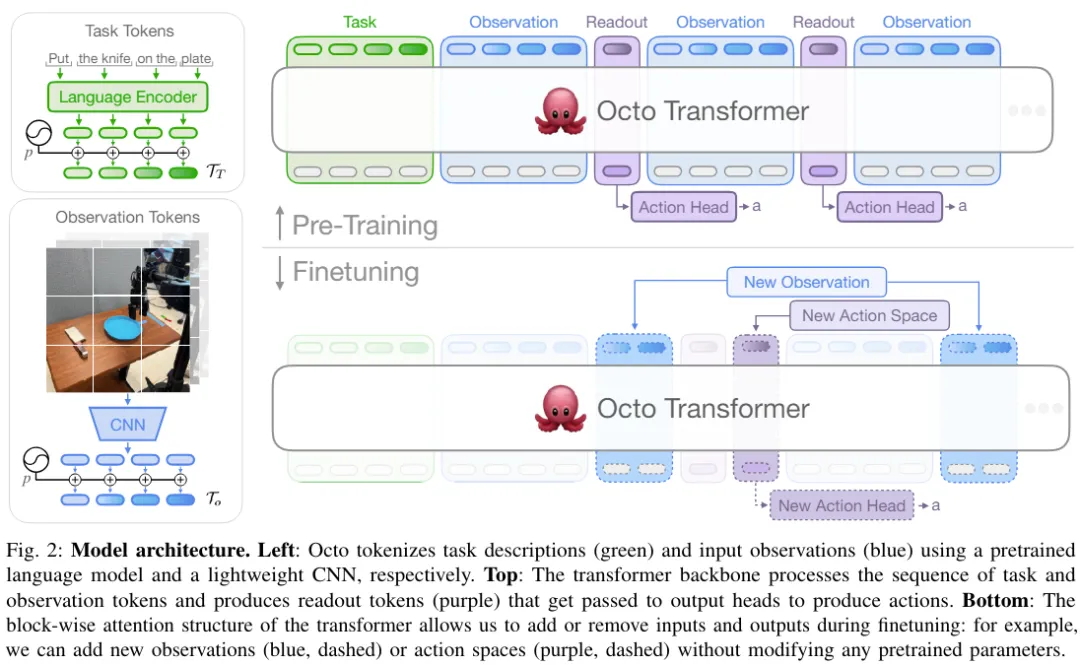 Für die Spracheingabe wird sie zuerst tokenisiert und dann durch einen vorab trainierten Transformer in eine Spracheinbettungs-Tokensequenz verarbeitet. Konkret verwendeten sie das Modell t5-base (111M).
Für die Spracheingabe wird sie zuerst tokenisiert und dann durch einen vorab trainierten Transformer in eine Spracheinbettungs-Tokensequenz verarbeitet. Konkret verwendeten sie das Modell t5-base (111M).
Abschließend wird die Eingabesequenz des Transformers erstellt, indem lernbare Positionseinbettungen zu Aufgaben- und Beobachtungs-Tokens hinzugefügt und in einer bestimmten Reihenfolge angeordnet werden.
Transformer-Rückgrat und Auslesekopf
Nachdem die Eingabe in eine einheitliche Token-Sequenz verarbeitet wurde, kann sie zur Verarbeitung an Transformer übergeben werden. Dies ähnelt früheren Forschungsarbeiten zum Training transformatorbasierter Richtlinien auf der Grundlage von Beobachtungen und Aktionssequenzen.
Octos Aufmerksamkeitsmodus ist die Block-für-Block-Maskierung: Beobachtungstoken können je nach Kausalzusammenhang nur auf Token und Aufgabentoken aus demselben oder einem vorherigen Zeitschritt achten. Token, die nicht vorhandenen Beobachtungen entsprechen, werden vollständig maskiert (z. B. Datensätze ohne Sprachanweisungen). Dieser modulare Aufbau erleichtert das Hinzufügen oder Entfernen von Beobachtungen oder Aufgaben während der Feinabstimmungsphase.
Dieses Design ermöglicht es Benutzern, dem Modell während der nachgelagerten Feinabstimmung flexibel neue Aufgaben und Beobachtungseingabe- oder Aktionsausgabeheader hinzuzufügen. Beim nachgelagerten Hinzufügen neuer Aufgaben, Beobachtungen oder Verlustfunktionen können Sie die vorab trainierten Gewichte des Transformers als Ganzes beibehalten und nur neue Positionseinbettungen, einen neuen Lightweight-Encoder oder neue Header hinzufügen, die aufgrund von Spezifikationsparametern erforderlich sind. Dies unterscheidet sich von früheren Architekturen, die eine Neuinitialisierung oder Neuschulung zahlreicher Komponenten des vorab trainierten Modells erforderten, wenn Bildeingaben hinzugefügt oder entfernt oder Aufgabenspezifikationen geändert wurden.
Um Octo zu einem echten „generalistischen“ Modell zu machen, ist diese Flexibilität von entscheidender Bedeutung: Da es für uns unmöglich ist, alle möglichen Robotersensor- und Aktionskonfigurationen in der Vortrainingsphase abzudecken, können wir Octo im Fein- anpassen. Tuning-Stufe Sein Input und Output machen es zu einem vielseitigen Werkzeug für die Robotik-Community. Darüber hinaus haben frühere Modelldesigns, die ein Standard-Transformer-Backbone verwendeten oder einen visuellen Encoder mit einem MLP-Ausgabekopf fusionierten, die Art und Reihenfolge der Modelleingänge festgelegt. Im Gegensatz dazu erfordert der Wechsel von Octos Beobachtungen oder Aufgaben keine Neuinitialisierung eines Großteils des Modells.
Trainingsdaten
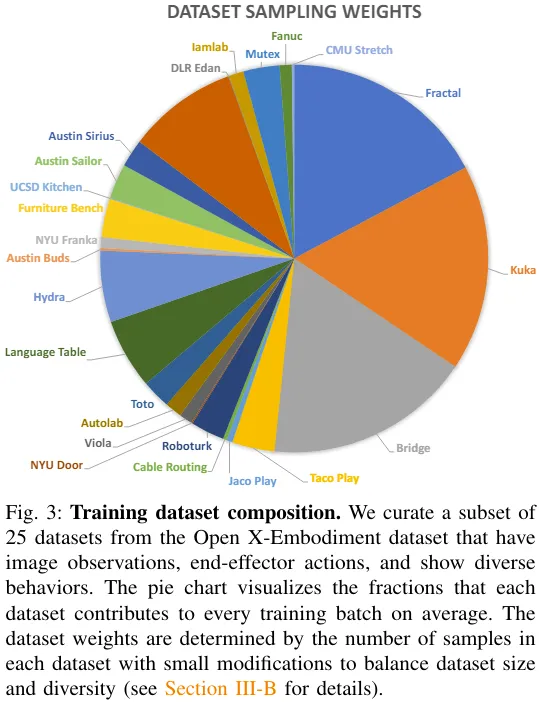
Das Team nahm einen gemischten Datensatz aus 25 Datensätzen von Open X-Embodiment. Abbildung 3 zeigt die Zusammensetzung des Datensatzes.
Weitere Einzelheiten zu den Trainingszielen und der Konfiguration der Trainingshardware finden Sie im Originalpapier.
Modellprüfpunkte und Code
Hier kommt es auf den Punkt! Das Team hat nicht nur Octos Artikel veröffentlicht, sondern auch alle Ressourcen vollständig als Open Source bereitgestellt, darunter:
Das Team führte auch eine empirische Analyse von Octo durch Experimente durch und bewertete seine Leistung als grundlegendes Robotermodell in mehreren Dimensionen:
Abbildung 4 zeigt die 9 Aufgaben zur Bewertung von Octo.

Verwenden Sie Octo direkt, um mehrere Roboter zu steuern.
Das Team verglich die Nullproben-Steuerungsfähigkeiten von Octo, RT-1-X und RT-2-X. Die Ergebnisse sind in dargestellt Abbildung 5.
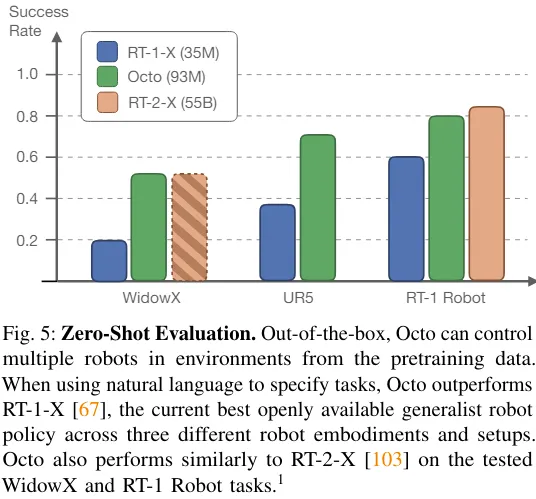
Es ist ersichtlich, dass die Erfolgsquote von Octo 29 % höher ist als die von RT-1-X (35 Millionen Parameter). In der WidowX- und RT-1-Robot-Bewertung entspricht die Leistung von Octo der von RT-2-X mit 55 Milliarden Parametern.
Darüber hinaus unterstützen RT-1-X und RT-2-X nur Sprachbefehle, während Octo auch bedingte Zielbilder unterstützt. Das Team stellte außerdem fest, dass die Erfolgsquote bei der WidowX-Aufgabe um 25 % höher war, wenn sie auf Zielbildern konditioniert wurde, als wenn sie auf Sprache konditioniert wurde. Dies kann daran liegen, dass Zielbilder mehr Informationen über die Aufgabenerledigung liefern.
Octo kann Daten effizient nutzen, um sich an neue Felder anzupassen
Tabelle 1 enthält die experimentellen Ergebnisse der dateneffizienten Feinabstimmung.

Sie können sehen, dass die Feinabstimmung von Octo bessere Ergebnisse liefert als ein Training von Grund auf oder ein Vortraining mit vorab trainierten VC-1-Gewichten. Über 6 Bewertungseinstellungen hinweg beträgt der durchschnittliche Vorsprung von Octo gegenüber dem Zweitplatzierten 52 %!
Und ich muss erwähnen: Bei all diesen Evaluierungsaufgaben waren die Rezepte und Hyperparameter, die bei der Feinabstimmung von Octo verwendet wurden, alle gleich, was zeigt, dass das Team eine sehr gute Standardkonfiguration gefunden hat.
Entwurfsentscheidungen für das allgemeine Roboterstrategietraining
Die obigen Ergebnisse zeigen, dass Octo tatsächlich als Zero-Shot-Multirobotersteuerung verwendet werden kann und auch als Initialisierungsbasis für die Feinabstimmung von Richtlinien verwendet werden kann . Als nächstes analysierte das Team die Auswirkungen verschiedener Designentscheidungen auf die Leistung der Octo-Strategie. Konkret konzentrieren sie sich auf die folgenden Aspekte: Modellarchitektur, Trainingsdaten, Trainingsziele und Modellgröße. Dazu führten sie Ablationsstudien durch.
Tabelle 2 enthält die Ergebnisse der Ablationsstudie zu Modellarchitektur, Trainingsdaten und Trainingszielen.
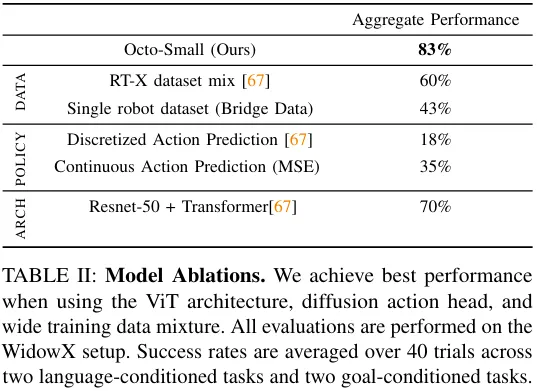
Abbildung 6 zeigt den Einfluss der Modellgröße auf die Erfolgsquote bei Nullstichproben. Es ist ersichtlich, dass größere Modelle über bessere visuelle Szenenwahrnehmungsfähigkeiten verfügen.
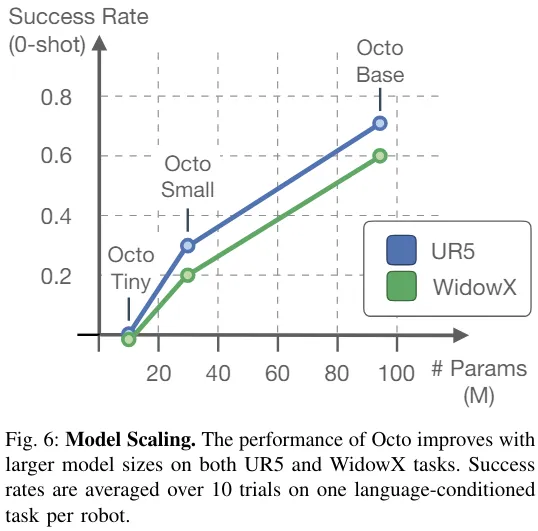
Insgesamt ist die Wirksamkeit der Octo-Komponenten nachgewiesen.
Das obige ist der detaillierte Inhalt vonDurch die Anpassung an verschiedene Formen und Aufgaben wurde das leistungsstärkste Open-Source-Roboter-Lernsystem „Octopus' geboren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



