
 Technologie-Peripheriegeräte
KI
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Technologie-Peripheriegeräte
KI
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?

Im gestrigen Interview wurde ich gefragt, ob ich jemals Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben.
Das Long-Tail-Problem selbstfahrender Autos bezieht sich auf Randfälle bei selbstfahrenden Autos, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten.
Edge-Szenarien beim autonomen Fahren
Der „Long Tail“ bezieht sich auf Edge-Cases bei autonomen Fahrzeugen (AV). Edge-Cases sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Diese seltenen Ereignisse werden in Datensätzen häufig übersehen, da sie seltener auftreten und einzigartiger sind. Während Menschen von Natur aus gut im Umgang mit Grenzfällen sind, kann man das nicht von der KI behaupten. Zu den Faktoren, die Randszenen verursachen können, gehören: Lastkraftwagen oder speziell geformte Fahrzeuge mit Vorsprüngen, Fahrzeuge, die scharf abbiegen, das Fahren in Menschenmengen, Fußgänger, die über die Straße laufen, extremes Wetter oder schlechte Lichtverhältnisse, Personen mit Regenschirmen, Personen in Autos, dann Umzugskartons, umstürzende Bäume mitten auf der Straße usw.Beispiel:
- Legen Sie eine transparente Folie vor das Auto. Wird das transparente Objekt erkannt und wird das Fahrzeug langsamer?
- Das Lidar-Unternehmen Aeye hat eine Herausforderung durchgeführt: Wie geht autonomes Fahren damit um? ein Ballon, der mitten auf der Straße schwebt? Selbstfahrende Autos der Stufe L4 neigen dazu, Kollisionen zu vermeiden. In diesem Fall werden sie ausweichen oder die Bremsen betätigen, um unnötige Unfälle zu vermeiden. Der Ballon ist ein weicher Gegenstand und kann ohne Hindernisse direkt passieren.
Methoden zur Lösung des Long-Tail-Problems
Synthetische Daten sind ein großes Konzept, und Wahrnehmungsdaten (Nerf, Kamera-/Sensorsimulation) sind nur einer der herausragenderen Zweige. In der Branche sind synthetische Daten längst zur Standardlösung für Longtail-Verhaltenssimulationen geworden. Synthetische Daten oder spärliches Signal-Upsampling sind eine der ersten Lösungen für das Long-Tail-Problem. Die Long-Tail-Fähigkeit ist das Produkt aus der Generalisierungsfähigkeit des Modells und der in den Daten enthaltenen Informationsmenge.Tesla-Lösung:
Verwenden Sie synthetische Daten, um Kantenszenen zu generieren und den Datensatz zu erweitern. Prinzip der Daten-Engine: Erkennen Sie zunächst Ungenauigkeiten im vorhandenen Modell und verwenden Sie dann diesen Klassenfall, der zu seinen Komponententests hinzugefügt wird . Außerdem werden mehr Daten zu ähnlichen Fällen gesammelt, um das Modell neu zu trainieren. Dieser iterative Ansatz ermöglicht es, so viele Randfälle wie möglich zu erfassen. Die größte Herausforderung bei der Erstellung von Randfällen besteht darin, dass die Kosten für das Sammeln und Beschriften von Randfällen relativ hoch sind und dass das Sammelverhalten möglicherweise sehr gefährlich oder sogar unmöglich zu erreichen ist.
NVIDIA-Lösung:
NVIDIA hat kürzlich einen strategischen Ansatz namens „Imitation Training“ vorgeschlagen (Bild unten). Bei diesem Ansatz werden reale Systemausfallfälle in einer simulierten Umgebung nachgestellt und dann als Trainingsdaten für autonome Fahrzeuge verwendet. Dieser Zyklus wird wiederholt, bis die Leistung des Modells konvergiert. Ziel dieses Ansatzes ist es, die Robustheit des autonomen Fahrsystems durch die kontinuierliche Simulation von Fehlerszenarien zu verbessern. Mithilfe von Simulationsschulungen können Entwickler verschiedene Fehlerszenarien in der realen Welt besser verstehen und lösen. Darüber hinaus können schnell große Mengen an Trainingsdaten generiert werden, um die Modellleistung zu verbessern. Durch Wiederholen dieses Zyklus,
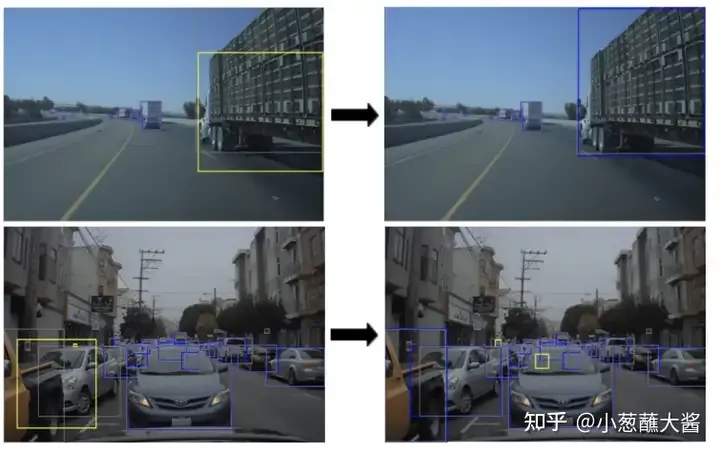
Einige Gedanken:
F: Sind synthetische Daten wertvoll? A: Der Wert ist hier in zwei Typen unterteilt, d. h. die Prüfung, ob in der generierten Szene Mängel im Erkennungsalgorithmus festgestellt werden können wird verwendet Ob das Training des Algorithmus auch die Leistung effektiv verbessern kann. F: Wie kann man virtuelle Daten nutzen, um die Leistung zu verbessern? Ist es wirklich notwendig, Dummy-Daten zum Trainingssatz hinzuzufügen? Wird das Hinzufügen zu einem Leistungsrückgang führen? A: Diese Fragen sind schwer zu beantworten, daher wurden viele verschiedene Lösungen zur Verbesserung der Trainingsgenauigkeit entwickelt:- Hybrides Training: Fügen Sie unterschiedliche Anteile virtueller Daten zu realen Daten hinzu, um die Leistung zu verbessern.
- Lernen übertragen: Verwenden Sie reale Daten, um das Modell vorab zu trainieren, frieren Sie dann bestimmte Ebenen ein und fügen Sie dann gemischte Daten für das Training hinzu.
- Imitationslernen: Es ist auch ganz natürlich, einige Szenarien von Modellfehlern zu entwerfen und einige Daten zu generieren, wodurch die Leistung des Modells schrittweise verbessert wird. Bei der tatsächlichen Datenerfassung und dem Modelltraining werden auch einige ergänzende Daten gezielt erfasst, um die Leistung zu verbessern.
Einige Erweiterungen:
Um die Robustheit eines KI-Systems gründlich zu bewerten, müssen Unit-Tests sowohl allgemeine als auch Randfälle umfassen. Einige Randfälle sind jedoch möglicherweise nicht aus vorhandenen realen Datensätzen verfügbar. Zu diesem Zweck können KI-Praktiker synthetische Daten zum Testen verwenden.
Ein Beispiel ist ParallelEye-CS, ein synthetischer Datensatz, der zum Testen der visuellen Intelligenz autonomer Fahrzeuge verwendet wird. Der Vorteil der Erstellung synthetischer Daten im Vergleich zur Verwendung realer Daten besteht in der mehrdimensionalen Kontrolle über die Szene für jedes Bild.
Synthetische Daten werden als praktikable Lösung für Randfälle in AV-Produktionsmodellen dienen. Es ergänzt reale Datensätze mit Randfällen und stellt sicher, dass AV auch bei ungewöhnlichen Ereignissen robust bleibt. Außerdem sind sie skalierbarer, weniger fehleranfällig und kostengünstiger als reale Daten.
Das obige ist der detaillierte Inhalt vonWie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
