

Die beliebte Denkkettentechnologie könnte gestürzt werden!
Immer noch überrascht, dass große Modelle mithilfe von Denkketten tatsächlich Schritt für Schritt denken können?
Haben Sie immer noch Schwierigkeiten, die Aufforderungswörter der Gedankenkette zu schreiben?
Forscher der New York University sagten: „Es spielt keine Rolle, es ist alles das Gleiche.“
Der Argumentationsschritt ist nicht wichtig, wenn Sie dies nicht tun Wenn Sie möchten, verwenden Sie stattdessen einfach Auslassungspunkte.

Papieradresse: https://arxiv.org/pdf/2404.15758
Der Titel dieses Artikels verwendet sogar direkt „Lass uns Punkt für Punkt denken“, um den „Lass uns denken“-Schritt der Denkkette zu bewerten Schritt für Schritt“, was die Kraft der „Ellipse“ zeigt.
Forscher haben herausgefunden, dass das Ersetzen der spezifischen Schritte im Chain-of-Thought (CoT)-Denken durch bedeutungsloses „...“ zu ganz unterschiedlichen Ergebnissen führt.
Zum Beispiel im folgenden Beispiel: Lassen Sie das Modell zählen, wie viele der ersten 6 Zahlen größer als 5 sind.

Wenn Sie die Frage direkt stellen und das Modell beantworten lassen, wird das Ergebnis unglaublich sein: 6 von 7.
Im Gegensatz dazu vergleicht das Modell mithilfe der Gedankenkettenaufforderung Schritt für Schritt die Größe und erhält schließlich die richtige Antwort: „25, 15, 25 , das sind 3 Ziffern".
Aber was noch empörender ist, ist die in diesem Artikel verwendete „metaphysische“ Methode: Es ist nicht nötig, die Schritte aufzuschreiben, man muss nur die gleiche Anzahl von „Punkten“ ausgeben, und das hat keinen Einfluss auf das Endergebnis Ergebnis.
——Das ist kein Zufall. Eine Vielzahl von Experimenten hat gezeigt, dass die Leistung der beiden letztgenannten Methoden nahe beieinander liegt.
Mit anderen Worten, wir dachten, dass die Verbesserung der Modellleistung durch „Schritt-für-Schritt-Denken“ zustande kam, aber tatsächlich könnte es einfach daran liegen, dass LLM die Rechenleistung von mehr Token erhalten hat!
Du denkst, das Model denkt, aber in Wirklichkeit grillt es.

——Dumme Menschen, ihr versucht mir tatsächlich beizubringen, wie man mit naiven Beispielen argumentiert. Weißt du, dass ich nur Berechnungen will?
„Die Gedankenkette hat nie existiert und wird auch in Zukunft nie existieren“ (Gotou).
Jacob Pfau, der Autor des Artikels, sagte, dass diese Arbeit beweist, dass das Modell nicht von der sprachlichen Argumentation der Denkkette profitiert. Die Verwendung wiederholter „…“ zum Füllen des Tokens kann den gleichen Effekt erzielen als CoT.

Natürlich wirft dies auch die Frage der Ausrichtung auf: Denn diese Tatsache zeigt, dass das Modell versteckte Überlegungen anstellen kann, die in CoT nicht sichtbar sind und sich bis zu einem gewissen Grad außerhalb der menschlichen Kontrolle befinden.
Man kann sagen, dass die Schlussfolgerung des Artikels unser langjähriges Wissen untergraben hat: Sie haben die Essenz der Maske gelernt.
„Was bedeutet das wirklich: Das Modell kann diese Token verwenden, um ohne unser Wissen unabhängig zu denken.“

Einige Internetnutzer sagten, kein Wunder, dass ich immer gerne „...“ verwende. „

Einige Internetnutzer haben direkt mit der praktischen Prüfung begonnen:

Obwohl wir nicht wissen, ob sein Verständnis richtig ist~
Einige Internetnutzer denken jedoch, dass die versteckten Argumente von LLM in der Denkkette unbegründet sind. Schließlich basiert die Ausgabe großer Modelle im Prinzip eher auf Wahrscheinlichkeit als auf bewusstem Denken.
CoT-Hinweise machen nur eine Teilmenge statistischer Muster explizit, Modelle simulieren Inferenz, indem sie Text generieren, der mit dem Muster übereinstimmt, aber sie haben nicht die Möglichkeit, ihre Ausgabe zu überprüfen oder zu reflektieren.
Wenn wir mit komplexen Problemen konfrontiert werden, denken wir Menschen unbewusst Schritt für Schritt.
Davon inspiriert veröffentlichten Google-Forscher im Jahr 2022 die berühmte Chain-of-Thought.
Die Methode, bei der das Sprachmodell das Problem Schritt für Schritt lösen muss, ermöglicht es dem Modell, Probleme zu lösen, die zuvor unlösbar schienen, wodurch die Leistung von LLM erheblich verbessert oder das Potenzial von LLM ausgeschöpft wird.

Papieradresse: https://arxiv.org/pdf/2201.11903
Obwohl zunächst nicht jeder wusste, warum dieses Ding funktionierte, wurde es schnell populär, weil es wirklich einfach zu bedienen war. verbreiten.

Mit der Einführung großer Modelle und prompter Word-Projekte ist CoT zu einem leistungsstarken Werkzeug für LLM geworden, um komplexe Probleme zu lösen.
Natürlich gibt es in diesem Prozess viele Forschungsteams, die das Funktionsprinzip von CoT erforschen.
Die durch die Denkkette bewirkte Leistungsverbesserung liegt darin, dass das Modell wirklich lernt, das Problem Schritt für Schritt zu lösen, oder liegt es nur an dem zusätzlichen Rechenaufwand, der durch die längere Anzahl von verursacht wird Token?
Da Sie nicht sicher sind, ob logisches Denken funktioniert, verzichten Sie einfach auf Logik und ersetzen Sie alle Argumentationsschritte durch „…“, was definitiv nutzlos ist. Dies nennt man Fülltoken.
Die Forscher verwendeten ein „kleines Alpaka“-Modell: ein 34M-Parameter-Lama mit 4 Schichten, 384 versteckten Dimensionen und 6 Aufmerksamkeitsköpfen. Die Modellparameter wurden zufällig initialisiert.
Bedenken Sie hier zwei Fragen:
(1) Welche Arten von Bewertungsdaten können von Padding-Tokens profitieren
(2) Welche Art von Trainingsdaten werden benötigt, um dem Modell beizubringen, Padding-Tokens zu verwenden
In diesem Zusammenhang entwarfen die Forscher zwei Aufgaben und erstellten entsprechende synthetische Datensätze. Jeder Datensatz hob eine andere Bedingung hervor, unter der das Füllen von Token Leistungsverbesserungen für Transformer bewirken kann.
3SUM
Schauen wir uns zunächst die erste schwierigere Aufgabe an: 3SUM. Das Modell muss drei Zahlen in der Folge auswählen, die die Bedingungen erfüllen. Beispielsweise hat die Summe der drei Zahlen dividiert durch 10 einen Rest von 0.

Im schlimmsten Fall ist die Komplexität dieser Aufgabe die dritte Potenz von N, und die Rechenkomplexität zwischen Transformer-Schichten ist die zweite Potenz von N,
Also, wenn die Länge der Eingabe Da die Sequenz sehr groß ist, übersteigt das 3SUM-Problem natürlich die Ausdrucksfähigkeit von Transformer.
Das Experiment richtete drei Gruppen von Kontrollen ein:
1. Fülltoken: Die Sequenz verwendet wiederholte „. . .“ als mittlere Auffüllung, wie zum Beispiel „A05
B75 C22 D13“. : .
Jeder Punkt stellt einen separaten Token dar, der dem Token in der folgenden Denkkette entspricht.
2. Parallelisierbare CoT-Lösung, die Reihenfolge hat die Form: „A05 B75 C22 D13 : AB 70 AC 27 AD 18 BC 97 BD 88 CD B ANS True“.
Denkkette reduziert das 3SUM-Problem auf eine Reihe von 2SUM-Problemen, indem alle relevanten Zwischensummen geschrieben werden (wie in der Abbildung unten dargestellt). Diese Methode reduziert den Rechenaufwand des Problems auf die Potenz N – der Transformator kann damit umgehen und kann parallelisiert werden.

3. Adaptive CoT-Lösung , die Reihenfolge hat die Form: „A15 B75 C22 D13: A B C 15 75 22 2 B C D 75 22 13 0 ANS True“.
Im Gegensatz zur obigen Lösung, die 3SUM geschickt in parallelisierbare Teilprobleme zerlegt, hoffen wir hier, mithilfe heuristischer Methoden flexible Denkketten zu generieren, um menschliches Denken nachzuahmen. Diese Art der instanzadaptiven Berechnung ist mit der parallelen Struktur der Fülltokenberechnung nicht kompatibel.
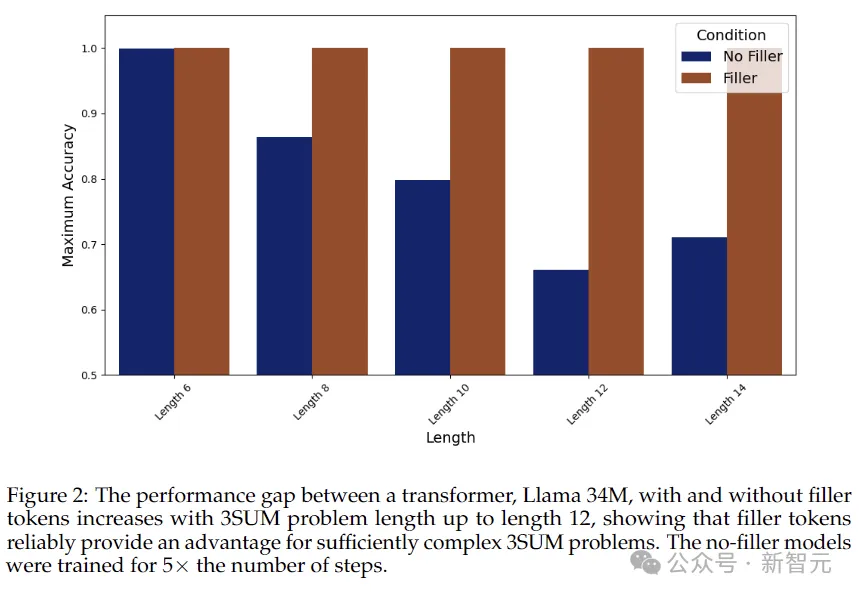
Wie aus den Ergebnissen in der obigen Abbildung ersichtlich ist, nimmt die Genauigkeit des Modells ohne Ausgabe von Fülltokens im Allgemeinen ab, wenn die Sequenz länger wird, während die Genauigkeit bei Verwendung von Fülltokens bei 100 % bleibt .
2SUM-Transformation
Die zweite Aufgabe ist 2SUM-Transformation. Sie müssen nur beurteilen, ob die Summe zweier Zahlen die Anforderungen erfüllt, und der Berechnungsbetrag unterliegt der Kontrolle von Transformer.

Um jedoch zu verhindern, dass das Modell „schummelt“, wird der Eingabetoken vor Ort berechnet und jede eingegebene Zahl wird um einen zufälligen Offset verschoben.

Die Ergebnisse sind in der obigen Tabelle aufgeführt: Die Genauigkeit der Füll-Token-Methode erreicht 93,6 %, was der Chain-of-Thought sehr nahe kommt. Ohne Zwischenauffüllung beträgt die Genauigkeit nur 78,7 %.
Aber ist diese Verbesserung einfach auf Unterschiede in der Darstellung der Trainingsdaten zurückzuführen, beispielsweise durch Regularisierungsverlustgradienten?
Um zu überprüfen, ob das Füllen von Tokens versteckte Berechnungen im Zusammenhang mit der endgültigen Vorhersage mit sich bringt, haben die Forscher die Modellgewichte eingefroren und nur die letzte Aufmerksamkeitsebene feinabgestimmt.
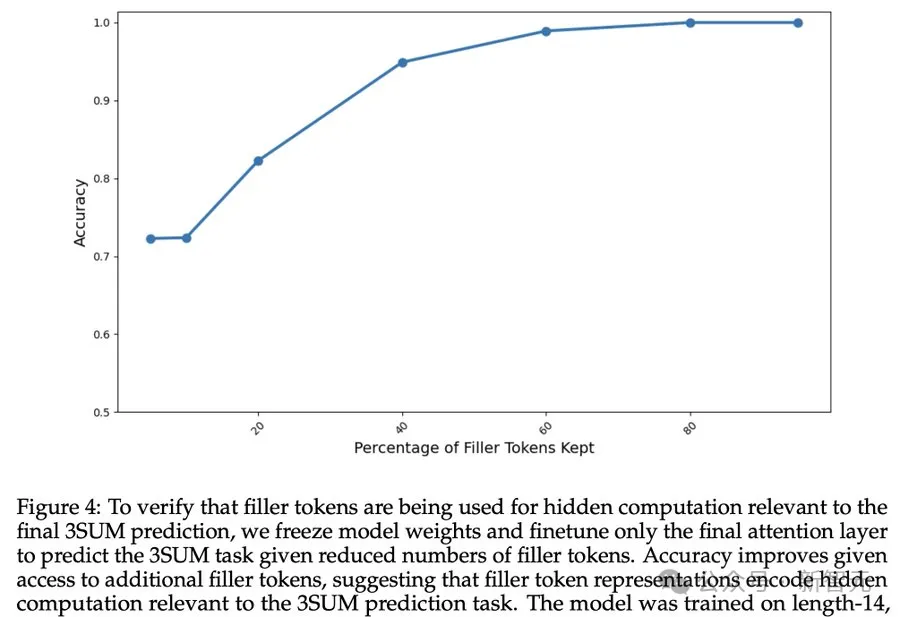
Die obigen Ergebnisse zeigen, dass sich die Genauigkeit des Modells weiter verbessert, wenn mehr Fülltokens verfügbar sind, was darauf hindeutet, dass Fülltokens tatsächlich versteckte Berechnungen im Zusammenhang mit der 3SUM-Vorhersageaufgabe durchführen.
Obwohl die Methode zum Füllen von Token metaphysisch, magisch und sogar effektiv ist, ist es noch zu früh zu sagen, dass die Denkkette umgeworfen wurde.
Der Autor gab außerdem an, dass die Methode zum Füllen von Token die Obergrenze der Rechenkomplexität von Transformer nicht überschreitet.
Und das Erlernen der Verwendung von Padding-Tokens erfordert einen spezifischen Trainingsprozess. In diesem Artikel wird beispielsweise eine intensive Supervision eingesetzt, um das Modell endgültig zusammenzuführen.
Es können jedoch einige Probleme aufgetaucht sein, z. B. versteckte Sicherheitsprobleme, z. B. ob das Prompt-Word-Projekt eines Tages plötzlich nicht mehr existiert?
Das obige ist der detaillierte Inhalt vonDie Gedankenkette existiert nicht mehr? Neueste Forschung der New York University: Der Argumentationsschritt kann weggelassen werden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
Welche Fähigkeiten sind erforderlich, um in der PHP-Branche zu arbeiten?
 Linux-Netzwerkkarte anzeigen
Linux-Netzwerkkarte anzeigen
 bootsqm.dat
bootsqm.dat
 Was sind die Parameter des Festzeltes?
Was sind die Parameter des Festzeltes?
 Merkmale von Managementinformationssystemen
Merkmale von Managementinformationssystemen
 So lösen Sie nicht verfügbar
So lösen Sie nicht verfügbar
 Ajax-Lösung für verstümmelten chinesischen Code
Ajax-Lösung für verstümmelten chinesischen Code
 Was sind die häufigsten Tomcat-Schwachstellen?
Was sind die häufigsten Tomcat-Schwachstellen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



