

Lesen Sie GPT-4o vs. GPT-4 Turbo in einem Artikel

Hallo Leute, ich bin Luga, heute werden wir über Technologien im Zusammenhang mit dem ökologischen Bereich der künstlichen Intelligenz (KI) sprechen – GPT-4o-Modell.
Am 13. Mai 2024 brachte OpenAI innovativ sein fortschrittlichstes und modernstes Modell GPT-4o auf den Markt, das einen großen Durchbruch auf dem Gebiet der Chatbots mit künstlicher Intelligenz und groß angelegter Sprachmodelle darstellt. GPT-4o läutet eine neue Ära der Fähigkeiten der künstlichen Intelligenz ein und verfügt über erhebliche Leistungsverbesserungen, die seinen Vorgänger GPT-4 sowohl in Bezug auf Geschwindigkeit als auch Vielseitigkeit übertreffen.
Diese bahnbrechende Weiterentwicklung löst die Latenzprobleme, die beim Vorgänger häufig auftraten, und sorgt für ein nahtloses und reaktionsschnelles Benutzererlebnis.

Was ist GPT-4o?
Am 13. Mai 2024 veröffentlichte OpenAI sein neuestes und fortschrittlichstes Modell für künstliche Intelligenz GPT-4o, wobei das „o“ für „omni“ steht, was „alle“ oder „alle“ bedeutet "Universal". Dieses Modell ist eine neue Generation eines großen Sprachmodells, das auf GPT-4 Turbo basiert. Im Vergleich zu früheren Modellen hat sich GPT-4o in Bezug auf Ausgabegeschwindigkeit, Antwortqualität und unterstützte Sprachen erheblich verbessert und revolutionäre Innovationen im Format der Verarbeitung von Eingabedaten vorgenommen.
Die bemerkenswerteste Neuerung des GPT-4o+-Modells besteht darin, dass es die Praxis des Vorgängermodells aufgibt, unabhängige neuronale Netze zur Verarbeitung verschiedener Arten von Eingabedaten zu verwenden, und stattdessen ein einziges einheitliches neuronales Netz zur Verarbeitung aller Eingaben verwendet. Dieses innovative Design verleiht GPT-4o+ beispiellose multimodale Fusionsfähigkeiten. Unter multimodaler Fusion versteht man die Integration verschiedener Arten von Eingabedaten (wie Bilder, Text, Audio usw.) zur Verarbeitung, um umfassendere und genauere Ergebnisse zu erhalten. Frühere Modelle mussten bei der Verarbeitung multimodaler Daten unterschiedliche Netzwerkstrukturen entwerfen, was viel Rechenressourcen und Zeit in Anspruch nahm. Durch die Verwendung eines einheitlichen neuronalen Netzwerks erreicht GPT-4o+ eine nahtlose Verbindung verschiedener Arten von Eingabedaten, wodurch die Verarbeitungseffizienz erheblich verbessert wird. Herkömmliche Sprachmodelle können normalerweise nur reine Texteingaben verarbeiten und können keine Nicht-Text-Daten wie Sprache und Bilder verarbeiten. Das Besondere an GPT-4o ist jedoch, dass es nicht-textliche Signale wie Hintergrundgeräusche, mehrere Tonquellen und emotionale Farben in der Spracheingabe gleichzeitig erkennen und analysieren und diese multimodalen Informationen in den semantischen Verständnis- und Generierungsprozess integrieren kann Erzeugen Sie eine reichhaltigere, kontextbezogenere Ausgabe.
Neben der Verarbeitung multimodaler Eingaben zeigt GPT-4o+ auch hervorragende Ausgabefähigkeiten bei der Generierung mehrsprachiger Ausgaben. Es liefert nicht nur eine höhere Qualität, grammatikalisch korrektere und prägnantere Ausdrücke in gängigen Sprachen wie Englisch, sondern GPT-4o+ kann auch in nicht-englischsprachigen Szenarien das gleiche Ausgabeniveau beibehalten. Dadurch wird sichergestellt, dass sowohl englische als auch andere Sprachbenutzer die überlegenen Funktionen von GPT-4o+ zur Generierung natürlicher Sprache nutzen können.
Im Allgemeinen besteht das größte Highlight von GPT-4o+ darin, dass es die Einschränkungen einer einzelnen Modalität durchbricht und modalübergreifende umfassende Verständnis- und Generierungsfähigkeiten erreicht. Mit Hilfe einer innovativen neuronalen Netzwerkarchitektur und eines Trainingsmechanismus kann GPT-4o+ nicht nur Informationen von mehreren Sinneskanälen erhalten, sondern diese auch während der Generierung integrieren, um eine kontextbezogenere und personalisiertere Reaktion zu erzeugen.
GPT-4o- und GPT-4-Turbo-Leistung?
GPT-4 ist das neueste multimodale Großmodell, das von OpenAI eingeführt wurde. Seine Leistung ist ein qualitativer Sprung im Vergleich zum GPT-4 Turbo der vorherigen Generation. Hier können wir eine vergleichende Analyse der beiden in den folgenden Schlüsselaspekten durchführen. Erstens gibt es einen Unterschied in der Modellgröße zwischen GPT-4 und GPT-4 Turbo. GPT-4 verfügt über eine größere Anzahl an Parametern als GPT-4 Turbo, was bedeutet, dass es komplexere Aufgaben und größere Datensätze bewältigen kann. Dies ermöglicht GPT-4 eine höhere Genauigkeit und Fließfähigkeit beim semantischen Verständnis, bei der Textgenerierung usw. Seine
1. Inferenzgeschwindigkeit
Laut den von OpenAI veröffentlichten Daten ist die Inferenzgeschwindigkeit von GPT-4o unter denselben Hardwarebedingungen doppelt so hoch wie die von GPT-4 Turbo. Diese deutliche Leistungssteigerung ist vor allem auf die innovative Einzelmodell-Architektur zurückzuführen, die den durch den Moduswechsel verursachten Effizienzverlust vermeidet. Die Single-Model-Architektur vereinfacht nicht nur den Berechnungsprozess, sondern reduziert auch den Ressourcenaufwand erheblich, sodass GPT-4o Anfragen schneller verarbeiten kann. Eine höhere Inferenzgeschwindigkeit bedeutet, dass GPT-4o Benutzern Antworten mit geringerer Latenz liefern kann, was das interaktive Erlebnis erheblich verbessert. Ob bei Echtzeitgesprächen, bei der Verarbeitung komplexer Aufgaben oder bei Anwendungen in Umgebungen mit hoher Parallelität – Benutzer können reibungslosere und unmittelbarere Servicereaktionen erleben. Diese Leistungsoptimierung verbessert nicht nur die Gesamteffizienz des Systems, sondern bietet auch eine zuverlässigere und effizientere Unterstützung für verschiedene Anwendungsszenarien.
 GPT-4o vs. GPT-4 Turbo-Latenzdurchsatz
GPT-4o vs. GPT-4 Turbo-Latenzdurchsatz
2. Es ist bekannt, dass frühe GPT-Modelle in Bezug auf den Durchsatz etwas hinterherhinken. Beispielsweise kann der neueste GPT-4 Turbo nur 20 Token pro Sekunde generieren. Allerdings hat GPT-4o in dieser Hinsicht einen großen Durchbruch erzielt und 109 Token pro Sekunde generieren können. Diese Verbesserung hat die Verarbeitungsgeschwindigkeit von GPT-4o erheblich verbessert und sorgt für eine höhere Effizienz für verschiedene Anwendungsszenarien.
Trotzdem ist GPT-4o immer noch nicht das schnellste Modell. Am Beispiel von Llama, das auf Groq gehostet wird, kann es 280 Token pro Sekunde generieren, was weit über GPT-4o liegt. Die Vorteile von GPT-4o gehen jedoch über die Geschwindigkeit hinaus. Seine fortschrittlichen Funktionen und Argumentationsfähigkeiten zeichnen es in Echtzeit-KI-Anwendungen aus. Die Einzelmodellarchitektur und der Optimierungsalgorithmus von GPT-4o verbessern nicht nur die Recheneffizienz, sondern verkürzen auch die Reaktionszeit erheblich, was ihm einzigartige Vorteile beim interaktiven Erlebnis verschafft.
? in den Fusionsfähigkeiten führt zu erheblichen Leistungsunterschieden. Hier analysieren wir hauptsächlich die Unterschiede zwischen den beiden drei repräsentativen Aufgabentypen: Datenextraktion, Klassifizierung und Argumentation. 1. Datenextraktion
1. Datenextraktion
Bei Textdatenextraktionsaufgaben verlässt sich GPT-4 Turbo auf seine leistungsstarken Fähigkeiten zum Verstehen natürlicher Sprache, um eine gute Leistung zu erzielen. Wenn es jedoch um Szenen geht, die unstrukturierte Daten wie Bilder und Tabellen enthalten, sind die Möglichkeiten etwas eingeschränkt.
Im Gegensatz dazu kann GPT-4o Daten verschiedener Modalitäten nahtlos integrieren, egal ob es sich um strukturierten Text oder unstrukturierte Daten wie Bilder und PDFs handelt, es kann die erforderlichen Informationen effizient identifizieren und extrahieren. Dieser Vorteil macht GPT-4o wettbewerbsfähiger bei der Verarbeitung komplexer gemischter Daten.
Hier nehmen wir das Vertragsszenario eines bestimmten Unternehmens. Der Datensatz umfasst den Master Service Agreement (MSA) zwischen dem Unternehmen und dem Kunden. Verträge sind unterschiedlich lang, einige sind nur 5 Seiten kurz und andere sind länger als 50 Seiten.
In dieser Auswertung extrahieren wir insgesamt 12 Felder, wie Vertragstitel, Kundenname, Lieferantenname, Einzelheiten zur Kündigungsklausel, ob höhere Gewalt vorliegt usw. Durch die Erfassung realer Daten zu 10 Verträgen wurden 12 benutzerdefinierte Bewertungsindikatoren erstellt. Diese Metriken werden verwendet, um unsere realen Daten mit der LLM-Ausgabe für jeden Parameter im vom Modell generierten JSON zu vergleichen. Anschließend haben wir GPT-4 Turbo und GPT-4o getestet. Das Folgende sind die Ergebnisse unseres Bewertungsberichts:
Bewertungsergebnisse für die 12 Indikatoren, die jeder Eingabeaufforderung entsprechenIn den obigen Vergleichsergebnissen können wir schlussfolgern dass unter diesen 12 Feldern GPT-4o in 6 Feldern eine bessere Leistung als GPT-4 Turbo erbringt, in 5 Feldern die gleichen Ergebnisse erzielt und in einem Feld etwas schlechter abschneidet. Absolut gesehen identifizieren GPT-4 und GPT-4o in den meisten Feldern nur 60–80 % der Daten korrekt. Bei komplexen Datenextraktionsaufgaben, die eine hohe Genauigkeit erfordern, schnitten beide Modelle unterdurchschnittlich ab. Bessere Ergebnisse können durch den Einsatz fortschrittlicher Aufforderungstechniken wie Schussaufforderungen oder Kettengedankenaufforderungen erzielt werden. Darüber hinaus ist GPT-4o im TTFT (Time to First Token) 50-80 % schneller als GPT-4 Turbo, was GPT-4o im direkten Vergleich einen Vorteil verschafft. Die abschließende Schlussfolgerung ist, dass GPT-4o GPT-4 Turbo aufgrund seiner höheren Qualität und geringeren Latenz übertrifft.
Darüber hinaus ist GPT-4o im TTFT (Time to First Token) 50-80 % schneller als GPT-4 Turbo, was GPT-4o im direkten Vergleich einen Vorteil verschafft. Die abschließende Schlussfolgerung ist, dass GPT-4o GPT-4 Turbo aufgrund seiner höheren Qualität und geringeren Latenz übertrifft.
2. Klassifizierung
Klassifizierungsaufgaben erfordern häufig das Extrahieren von Merkmalen aus multimodalen Informationen wie Text und Bildern und die anschließende Durchführung von Verständnis und Beurteilung auf semantischer Ebene. Da GPT-4 Turbo derzeit nur auf die Verarbeitung einer einzigen Textmodalität beschränkt ist, sind seine Klassifizierungsmöglichkeiten relativ begrenzt.
GPT-4o kann multimodale Informationen zu einer umfassenderen semantischen Darstellung zusammenführen und zeigt so hervorragende Klassifizierungsfähigkeiten in Bereichen wie Textklassifizierung, Bildklassifizierung, Stimmungsanalyse usw., insbesondere bei einigen schwierigen modalübergreifenden Aufgaben das dynamische Klassifizierungsszenario.
In unseren Tipps geben wir klare Anweisungen, wann Kundentickets geschlossen werden, und fügen mehrere Beispiele hinzu, die bei der Lösung der schwierigsten Fälle helfen.
Durch Ausführen der Auswertung, um zu testen, ob die Ausgabe des Modells mit den Grundwahrheitsdaten für 100 gekennzeichnete Testfälle übereinstimmt, sind hier die relevanten Ergebnisse:
Bewertungsreferenz zur KlassifizierungsanalyseGPT-4o zeigte zweifellos einen überwältigenden sexuellen Vorteil. Durch eine Reihe von Tests und Vergleichen zu verschiedenen komplexen Aufgaben können wir feststellen, dass der GPT-4o andere Konkurrenzmodelle in der Gesamtgenauigkeit weit übertrifft und ihn in vielen Anwendungsbereichen zur ersten Wahl macht. Obwohl wir GPT-4o als allgemeine Lösung bevorzugen, müssen wir auch bedenken, dass die Auswahl des besten KI-Modells kein Entscheidungsprozess über Nacht ist. Schließlich hängt die Leistung von KI-Modellen oft von spezifischen Anwendungsszenarien und Kompromisspräferenzen für verschiedene Indikatoren wie Präzision, Rückruf und Zeiteffizienz ab.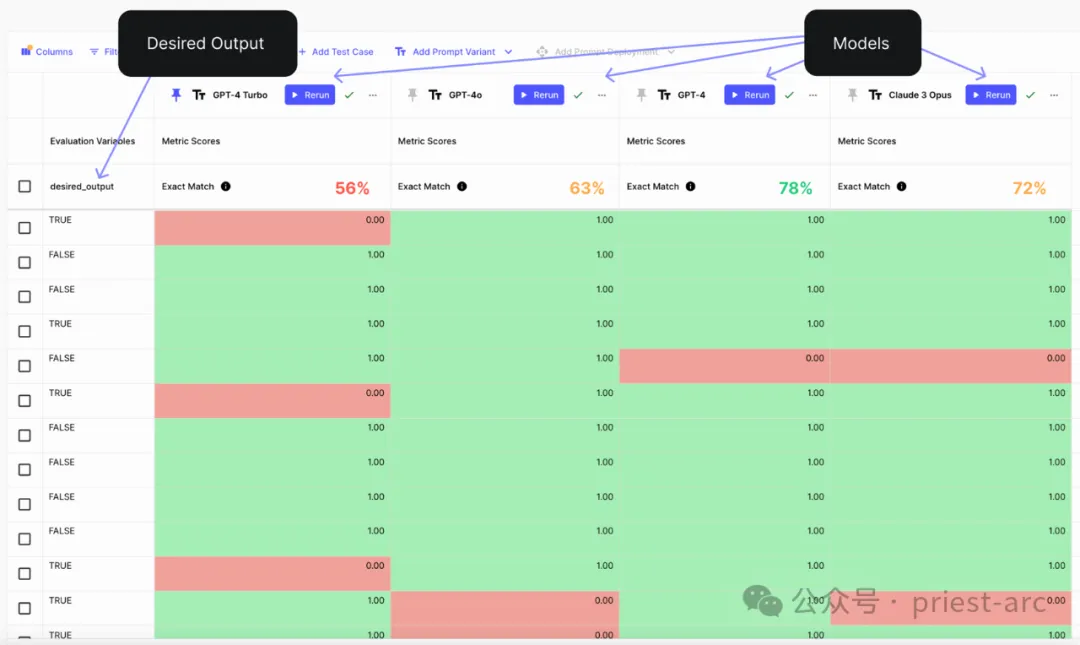 3. Argumentation
3. Argumentation
Argumentation ist eine kognitive Fähigkeit höherer Ordnung von Systemen der künstlichen Intelligenz, die erfordert, dass das Modell aus gegebenen Voraussetzungen vernünftige Schlussfolgerungen ableitet. Dies ist entscheidend für Aufgaben wie logisches Denken und Frage-und-Antwort-Denken.
GPT-4 Turbo hat bei Text-Argumentation-Aufgaben gute Ergebnisse erzielt, seine Fähigkeiten sind jedoch begrenzt, wenn Situationen auftreten, die eine multimodale Informationsfusion erfordern.
GPT-4o hat diese Einschränkung nicht. Es kann semantische Informationen aus mehreren Modalitäten wie Text, Bildern und Sprache frei integrieren und auf dieser Grundlage komplexeres logisches Denken, kausales Denken und induktives Denken durchführen, wodurch das System der künstlichen Intelligenz „humanisiertere“ Argumentations- und Urteilsfähigkeiten erhält. .
Schauen wir uns immer noch basierend auf dem obigen Szenario den Vergleich zwischen den beiden auf der Inferenzebene an. Die spezifische Referenz lautet wie folgt:

Bewertungsreferenz für 16 Inferenzaufgaben
Gemäß dem Beispieltest von Das GPT-4o-Modell. Wir können beobachten, dass es bei den folgenden Inferenzaufgaben zunehmend besser abschneidet, wie folgt:
- Kalenderberechnungen: GPT-4o ist in der Lage, wiederkehrende Zeiten für bestimmte Daten genau zu identifizieren, was bedeutet, dass es mit Datumsangaben umgehen kann. damit verbundene Berechnungen und Überlegungen.
- Zeit- und Winkelberechnungen: GPT-4o ist in der Lage, Winkel auf Uhren genau zu berechnen, was bei der Lösung von Problemen im Zusammenhang mit Uhren und Winkeln sehr nützlich ist.
- Wortschatz (Antonymerkennung): GPT-4o kann effektiv Antonyme identifizieren und die Bedeutung von Wörtern verstehen, was für das semantische Verständnis und das lexikalische Denken sehr wichtig ist.
Obwohl GPT-4o bei bestimmten Denkaufgaben besser wird, steht es bei Aufgaben wie Wortmanipulation, Mustererkennung, analogem Denken und räumlichem Denken immer noch vor Herausforderungen. Zukünftige Verbesserungen und Optimierungen könnten die Leistung des Modells in diesen Bereichen weiter verbessern.
Zusammenfassend lässt sich sagen, dass GPT-4o basierend auf der Ratenbegrenzung von bis zu 10 Millionen Token pro Minute das Fünffache von GPT-4 beträgt. Dieser aufregende Leistungsindikator wird zweifellos die Popularisierung künstlicher Intelligenz in vielen intensiven Computerszenarien beschleunigen, insbesondere in der Echtzeit-Videoanalyse, der intelligenten Sprachinteraktion und anderen Bereichen. Die hohe Parallelitätsreaktionsfähigkeit von GPT-4o wird konkurrenzlose Vorteile zeigen.
Die herausragendste Innovation von GPT-4o ist zweifellos sein revolutionäres Design, das Text, Bilder, Sprache und andere multimodale Eingaben und Ausgaben nahtlos integriert. Durch die direkte Integration und Verarbeitung von Daten aus jeder Modalität über ein einziges neuronales Netzwerk löst GPT-4o grundlegend die fragmentierte Erfahrung beim Wechsel zwischen vorherigen Modellen und ebnet den Weg für die Entwicklung einheitlicher KI-Anwendungen.
Nach der Realisierung der Modalfusion wird GPT-4o beispiellose breite Perspektiven in Anwendungsszenarien haben. Ob es um die Kombination von Computer-Vision-Technologie geht, um intelligente Bildanalysetools zu erstellen, um die nahtlose Integration mit Spracherkennungs-Frameworks, um multimodale virtuelle Assistenten zu erstellen, oder um die Generierung hochauflösender grafischer Werbung auf der Grundlage von Text- und Bild-Dual-Modalität – alles konnte nur durch erreicht werden Durch die Integration unabhängiger Untermodelle werden die erledigten Aufgaben, angetrieben durch die große Intelligenz von GPT-4o, neue einheitliche und effiziente Lösungen haben.
Referenz:
- [1] https://openai.com/index/hello-gpt-4o/?ref=blog.roboflow.com
- [2] https://blog.roboflow.com/gpt -4-vision/
- [3] https://www.vellum.ai/blog/analysis-gpt-4o-vs-gpt-4-turbo#task1
Das obige ist der detaillierte Inhalt vonLesen Sie GPT-4o vs. GPT-4 Turbo in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Bytedance Cutting führt SVIP-Supermitgliedschaft ein: 499 Yuan für ein fortlaufendes Jahresabonnement, das eine Vielzahl von KI-Funktionen bietet
Jun 28, 2024 am 03:51 AM
Diese Seite berichtete am 27. Juni, dass Jianying eine von FaceMeng Technology, einer Tochtergesellschaft von ByteDance, entwickelte Videobearbeitungssoftware ist, die auf der Douyin-Plattform basiert und grundsätzlich kurze Videoinhalte für Benutzer der Plattform produziert Windows, MacOS und andere Betriebssysteme. Jianying kündigte offiziell die Aktualisierung seines Mitgliedschaftssystems an und führte ein neues SVIP ein, das eine Vielzahl von KI-Schwarztechnologien umfasst, wie z. B. intelligente Übersetzung, intelligente Hervorhebung, intelligente Verpackung, digitale menschliche Synthese usw. Preislich beträgt die monatliche Gebühr für das Clipping von SVIP 79 Yuan, die Jahresgebühr 599 Yuan (Hinweis auf dieser Website: entspricht 49,9 Yuan pro Monat), das fortlaufende Monatsabonnement beträgt 59 Yuan pro Monat und das fortlaufende Jahresabonnement beträgt 499 Yuan pro Jahr (entspricht 41,6 Yuan pro Monat). Darüber hinaus erklärte der Cut-Beamte auch, dass diejenigen, die den ursprünglichen VIP abonniert haben, das Benutzererlebnis verbessern sollen
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
SOTA Performance, eine multimodale KI-Methode zur Vorhersage der Protein-Ligand-Affinität in Xiamen, kombiniert erstmals molekulare Oberflächeninformationen
Jul 17, 2024 pm 06:37 PM
Herausgeber |. KX Im Bereich der Arzneimittelforschung und -entwicklung ist die genaue und effektive Vorhersage der Bindungsaffinität von Proteinen und Liganden für das Arzneimittelscreening und die Arzneimitteloptimierung von entscheidender Bedeutung. Aktuelle Studien berücksichtigen jedoch nicht die wichtige Rolle molekularer Oberflächeninformationen bei Protein-Ligand-Wechselwirkungen. Auf dieser Grundlage schlugen Forscher der Universität Xiamen ein neuartiges Framework zur multimodalen Merkmalsextraktion (MFE) vor, das erstmals Informationen über Proteinoberfläche, 3D-Struktur und -Sequenz kombiniert und einen Kreuzaufmerksamkeitsmechanismus verwendet, um verschiedene Modalitäten zu vergleichen Ausrichtung. Experimentelle Ergebnisse zeigen, dass diese Methode bei der Vorhersage von Protein-Ligand-Bindungsaffinitäten Spitzenleistungen erbringt. Darüber hinaus belegen Ablationsstudien die Wirksamkeit und Notwendigkeit der Proteinoberflächeninformation und der multimodalen Merkmalsausrichtung innerhalb dieses Rahmens. Verwandte Forschungen beginnen mit „S
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
 GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
GlobalFoundries erschließt Märkte wie KI und erwirbt die Galliumnitrid-Technologie von Tagore Technology und zugehörige Teams
Jul 15, 2024 pm 12:21 PM
Laut Nachrichten dieser Website vom 5. Juli veröffentlichte GlobalFoundries am 1. Juli dieses Jahres eine Pressemitteilung, in der die Übernahme der Power-Galliumnitrid (GaN)-Technologie und des Portfolios an geistigem Eigentum von Tagore Technology angekündigt wurde, in der Hoffnung, seinen Marktanteil in den Bereichen Automobile und Internet auszubauen Anwendungsbereiche für Rechenzentren mit künstlicher Intelligenz, um höhere Effizienz und bessere Leistung zu erforschen. Da sich Technologien wie generative künstliche Intelligenz (GenerativeAI) in der digitalen Welt weiterentwickeln, ist Galliumnitrid (GaN) zu einer Schlüssellösung für nachhaltiges und effizientes Energiemanagement, insbesondere in Rechenzentren, geworden. Auf dieser Website wurde die offizielle Ankündigung zitiert, dass sich das Ingenieurteam von Tagore Technology im Rahmen dieser Übernahme mit GF zusammenschließen wird, um die Galliumnitrid-Technologie weiterzuentwickeln. G
