

Papiertitel:
DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
Papierautor:
Peijin Jia, Tuopu Wen, Ziang Luo, Mengmeng Yang, Kun Jiang, Zhiquan. Lei, Xuewei Tang, Ziyuan Liu, Le Cui, Kehua Sheng, Bo Zhang, Diange Yang
Für selbstfahrende Fahrzeuge können hochauflösende (HD) Karten dabei helfen, ihr Verständnis der Umwelt zu verbessern (Wahrnehmung) ) Genauigkeit und Navigationspräzision. Bei der manuellen Zuordnung bestehen jedoch die Probleme der Komplexität und der hohen Kosten. Zu diesem Zweck integriert die aktuelle Forschung die Kartenkonstruktion in die BEV-Wahrnehmungsaufgabe (Vogelperspektive). Die Konstruktion einer gerasterten HD-Karte im BEV-Raum wird als Segmentierungsaufgabe betrachtet, die als Hinzufügung der Verwendung von etwas Ähnlichem wie FCN verstanden werden kann (vollständiges Volumen) nach Erhalt der BEV-Funktionen des Produktnetzwerks. HDMapNet kodiert beispielsweise Sensormerkmale über LSS (Lift, Splat, Shoot) und verwendet dann FCN mit mehreren Auflösungen zur semantischen Segmentierung, Instanzerkennung und Richtungsvorhersage, um eine Karte zu erstellen.
Allerdings weisen solche Methoden (pixelbasierte Klassifizierungsmethoden) derzeit noch inhärente Einschränkungen auf, einschließlich der Möglichkeit, bestimmte Klassifizierungsattribute zu ignorieren, was zu Verzerrungen und Unterbrechungen von Mittelstreifen, unscharfen Fußgängerüberwegen und anderen Arten von Artefakten führen kann Lärm, wie in Abbildung 1(a) dargestellt. Diese Probleme wirken sich nicht nur auf die strukturelle Genauigkeit der Karte aus, sondern können sich auch direkt auf das nachgelagerte Pfadplanungsmodul des autonomen Fahrsystems auswirken.
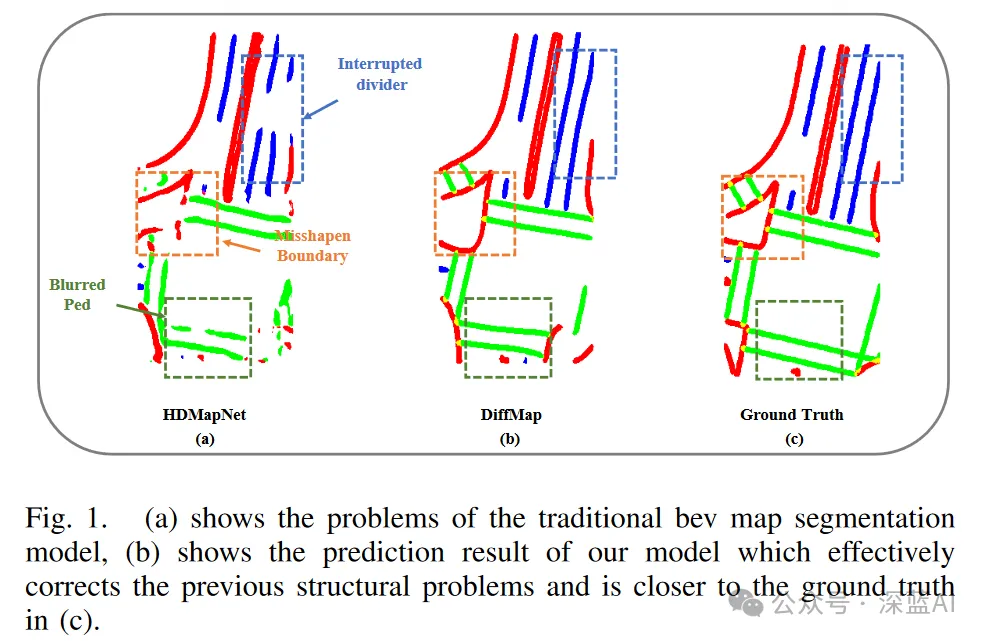
▲ Abbildung 1|Vergleich der Auswirkungen von HDMapNet, DiffMap und GroundTruth
Daher ist es für das Modell am besten, die strukturellen Vorinformationen der HD-Karte zu berücksichtigen, z. B. parallel und gerade Eigenschaften von Fahrspurlinien. Einige generative Modelle verfügen über diese Fähigkeit, die Authentizität und die inhärenten Eigenschaften von Bildern zu erfassen. Beispielsweise hat LDM (Latent Diffusion Model) großes Potenzial bei der Generierung von Bildern mit hoher Wiedergabetreue gezeigt und seine Wirksamkeit bei Aufgaben im Zusammenhang mit der Segmentierungsverbesserung unter Beweis gestellt. Darüber hinaus können Steuervariablen eingeführt werden, um die Bilderzeugung weiter zu steuern und spezifische Steueranforderungen zu erfüllen. Daher wird erwartet, dass die Anwendung generativer Modelle zur Erfassung von Kartenstrukturprioris Segmentierungsartefakte reduziert und die Leistung der Kartenkonstruktion verbessert.
In diesem Artikel erwähnte der Autor das DiffMap-Netzwerk. Zum ersten Mal führt dieses Netzwerk eine kartenstrukturierte vorherige Modellierung auf vorhandenen Segmentierungsmodellen durch und unterstützt Plug-and-Play durch die Verwendung von verbessertem LDM als Erweiterungsmodul. DiffMap lernt nicht nur die Karte im Vorfeld durch den Prozess des Hinzufügens und Entfernens von Rauschen, um sicherzustellen, dass die Ausgabe mit der aktuellen Frame-Beobachtung übereinstimmt, sondern kann auch BEV-Funktionen als Steuersignal integrieren, um sicherzustellen, dass die Ausgabe mit der aktuellen Frame-Beobachtung übereinstimmt. Experimentelle Ergebnisse zeigen, dass DiffMap effektiv glattere und vernünftigere Kartensegmentierungsergebnisse generieren kann, während gleichzeitig Artefakte erheblich reduziert und die Gesamtleistung der Kartenerstellung verbessert werden.
2.1 Semantische Kartenkonstruktion
Bei der herkömmlichen hochauflösenden (HD) Kartenkonstruktion werden semantische Karten normalerweise manuell oder halbautomatisch auf der Grundlage von LIDAR-Punktwolken annotiert. Im Allgemeinen wird eine global konsistente Karte basierend auf dem SLAM-Algorithmus erstellt und der Karte werden manuell semantische Anmerkungen hinzugefügt. Allerdings ist dieser Ansatz zeit- und arbeitsintensiv und stellt außerdem erhebliche Herausforderungen bei der Aktualisierung der Karte dar, wodurch ihre Skalierbarkeit und Echtzeitleistung eingeschränkt wird.
HDMapNet schlägt eine Methode zum dynamischen Erstellen lokaler semantischer Karten mithilfe integrierter Sensoren vor. Es kodiert Lidar-Punktwolken und Panoramabildmerkmale in den BEV-Raum (Bird's Eye View) und dekodiert sie mithilfe von drei verschiedenen Köpfen, wodurch letztendlich eine vektorisierte lokale semantische Karte erstellt wird. SuperFusion konzentriert sich auf die Erstellung hochpräziser semantischer Karten über große Entfernungen, die Verwendung von LIDAR-Tiefeninformationen zur Verbesserung der Bildtiefenschätzung und die Verwendung von Bildmerkmalen zur Steuerung der Vorhersage von LIDAR-Merkmalen über große Entfernungen. Anschließend wird ein Kartenerkennungskopf ähnlich wie HDMapNet verwendet, um die semantische Karte zu erhalten. MachMap unterteilt die Aufgabe in Polylinienerkennung und Polygoninstanzsegmentierung und verfeinert die Maske mithilfe der Nachbearbeitung, um das Endergebnis zu erhalten. Nachfolgende Forschung konzentriert sich auf die End-to-End-Online-Kartierung, um direkt vektorisierte hochauflösende Karten zu erhalten. Durch die dynamische Erstellung semantischer Karten ohne manuelle Annotation werden die Erstellungskosten effektiv gesenkt. 2.2 Auf Segmentierung und Erkennung angewendetes Diffusionsmodell für verschiedene Aufgaben wie Segmentierung und Erkennung. SegDiff wendet das Diffusionsmodell auf die Bildsegmentierungsaufgabe an, wobei der verwendete UNet-Encoder weiter in drei Module entkoppelt wird: E, F und G. Die Module G und F kodieren das Eingabebild I bzw. die Segmentierungskarte, die dann in E additiv zusammengeführt werden, um die Segmentierungskarte iterativ zu verfeinern. DDPMS verwendet ein Basissegmentierungsmodell, um einen anfänglichen Vorhersage-Priorit zu generieren, und ein Diffusionsmodell, um den Prior zu verfeinern. DiffusionDet erweitert das Diffusionsmodell auf das Zielerkennungs-Framework und modelliert die Zielerkennung als entrauschenden Diffusionsprozess von der Rauschbox zur Zielbox.
Diffusionsmodelle werden auch im Bereich des autonomen Fahrens verwendet, z. B. MagicDrive, das geometrische Einschränkungen zur Synthese von Straßenszenen verwendet, und Motiondiffuser, das das Diffusionsmodell auf Probleme bei der Bewegungsvorhersage mit mehreren Agenten erweitert.
2.3 Kartenpriorität
Es gibt derzeit mehrere Methoden, um die Robustheit des Modells zu verbessern und die Belastung der Fahrzeugsensoren zu verringern, indem vorherige Informationen (einschließlich expliziter Standardkarteninformationen und impliziter Zeitinformationen) genutzt werden. Unsicherheit. MapLite2.0 verwendet die vorherige SD-Karte (Standard Definition) als Ausgangspunkt und kombiniert sie mit integrierten Sensoren, um in Echtzeit lokale hochauflösende Karten abzuleiten. MapEx und SMERF nutzen Standardkartendaten, um die Fahrspurerkennung und das topologische Verständnis zu verbessern. SMERF verwendet einen Transformer-basierten Standardkartenencoder, um Fahrspurlinien und Fahrspurtypen zu kodieren, und berechnet dann die Queraufmerksamkeit zwischen den Standardkarteninformationen und sensorbasierten BEV-Funktionen (Vogelperspektive), um die Standardkarteninformationen zu integrieren. NMP bietet Langzeitspeicherfähigkeiten für autonome Fahrzeuge, indem es frühere Kartendaten mit aktuellen Wahrnehmungsdaten kombiniert. MapPrior kombiniert diskriminierende und generative Modelle, kodiert vorläufige Vorhersagen, die auf der Grundlage vorhandener Modelle generiert wurden, als Priors während der Vorhersagephase, fügt den diskreten latenten Raum des generativen Modells ein und verwendet dann das generative Modell, um Vorhersagen zu verfeinern. PreSight nutzt Daten früherer Fahrten, um das neuronale Strahlungsfeld im Stadtmaßstab zu optimieren, neuronale Prioritäten zu generieren und die Online-Wahrnehmung bei der anschließenden Navigation zu verbessern.
3.1 Vorbereitung


3.2 Gesamtarchitektur
Wie in Abbildung 2 gezeigt. Als Decoder integriert DiffMap das Diffusionsmodell in das semantische Kartensegmentierungsmodell, das umgebende Mehransichtsbilder und LiDAR-Punktwolken als Eingabe verwendet, sie in den BEV-Raum codiert und fusionierte BEV-Merkmale erhält. Dann wird DiffMap als Decoder zum Generieren von Segmentierungskarten verwendet. Im DiffMap-Modul werden BEV-Funktionen als Bedingungen zur Steuerung des Rauschunterdrückungsprozesses verwendet.
 ▲ Abbildung 2|DiffMap-Architektur ©️[Deep Blue AI] kompiliert
▲ Abbildung 2|DiffMap-Architektur ©️[Deep Blue AI] kompiliert
◆Grundlinie für die semantische Kartenkonstruktion: Die Grundlinie folgt hauptsächlich dem BEV-Encoder-Decoder-Paradigma. Der Encoder-Teil ist dafür verantwortlich, Merkmale aus den Eingabedaten (LiDAR- und/oder Kameradaten) zu extrahieren und in eine hochdimensionale Darstellung umzuwandeln. Gleichzeitig fungiert der Decoder normalerweise als Segmentierungskopf, um hochdimensionale Merkmalsdarstellungen auf entsprechende Segmentierungskarten abzubilden. Baselines spielen im Gesamtrahmen zwei Hauptrollen: Supervisor und Controller. Als Supervisor generiert die Baseline Segmentierungsergebnisse als Hilfsaufsicht. Gleichzeitig stellt es als Regler Zwischeneigenschaften des BEV als bedingte Steuervariablen bereit, um den Generierungsprozess des Diffusionsmodells zu steuern.
◆DiffMap-Modul: Nach LDM stellt der Autor das DiffMap-Modul als Decoder im Basisframework vor. LDM besteht hauptsächlich aus zwei Teilen: einem bildbewussten Komprimierungsmodul (z. B. VQVAE) und einem mit UNet erstellten Diffusionsmodell. Zunächst kodiert der Encoder die Grundwahrheit der Kartensegmentierung in den latenten Raum, wo er die niedrige Dimension des latenten Raums darstellt. Anschließend werden Diffusion und Entrauschen in einem niedrigdimensionalen latenten Variablenraum durchgeführt, und ein Decoder wird verwendet, um den latenten Raum auf den ursprünglichen Pixelraum wiederherzustellen.
Fügen Sie zunächst Rauschen durch einen Diffusionsprozess hinzu und erhalten Sie bei jedem Zeitschritt eine Rauschpotentialkarte, wobei . Während des Entrauschungsprozesses dient UNet dann als Backbone-Netzwerk für die Rauschvorhersage. Um den Überwachungsteil der Segmentierungsergebnisse zu verbessern, wird erwartet, dass das DiffMap-Modell während des Trainings direkt semantische Merkmale für instanzbezogene Vorhersagen bereitstellt. Daher unterteilt der Autor die UNet-Netzwerkstruktur in zwei Zweige: Ein Zweig wird zur Vorhersage von Rauschen verwendet, beispielsweise beim herkömmlichen Diffusionsmodell, und der andere Zweig wird zur Vorhersage von Rauschen im latenten Raum verwendet.
Wie in Abbildung 3 dargestellt. Nachdem die latente Kartenvorhersage erhalten wurde, wird sie als semantische Merkmalskarte in den ursprünglichen Pixelraum dekodiert. Anschließend können daraus Instanzvorhersagen gemäß der von HDMapNet vorgeschlagenen Methode abgerufen und die Vorhersagen von drei verschiedenen Köpfen ausgegeben werden: semantische Segmentierung, Instanzeinbettung und Spurrichtung. Diese Vorhersagen werden dann in einem Nachverarbeitungsschritt verwendet, um die Karte zu vektorisieren.

▲Abbildung 3|Entrauschungsmodul
Der gesamte Prozess ist ein bedingter Generierungsprozess, und die Kartensegmentierungsergebnisse werden basierend auf der aktuellen Sensoreingabe erhalten. Die Wahrscheinlichkeitsverteilung des Ergebnisses kann wie folgt modelliert werden: wobei das Ergebnis der Kartensegmentierung und die bedingte Kontrollvariable, also das BEV-Merkmal, dargestellt werden. Der Autor verwendet hier zwei Methoden zur Integration von Steuervariablen. Da die BEV- und BEV-Merkmale im räumlichen Bereich dieselbe Kategorie und denselben Maßstab haben, werden sie zunächst an die Größe des latenten Raums angepasst und dann als Eingabe des Entrauschungsprozesses verkettet, wie in Gleichung 5 dargestellt.
Zweitens ist der Cross-Attention-Mechanismus in jede Schicht des UNet-Netzwerks integriert, als Schlüssel/Wert und Abfrage. Die Formel des Cross-Attention-Moduls lautet wie folgt:
3.3 Spezifische Implementierung
◆Training:

◆Inferenz:

4.1 Experimentelle Details
◆ Datensatz: Validieren Sie DiffMap auf dem nuScenes-Datensatz. Der nuScenes-Datensatz enthält Mehransichtsbilder und Punktwolken von 1000 Szenen, von denen 700 Szenen für das Training, 150 für die Validierung und 150 für Tests verwendet werden. Der nuScenes-Datensatz enthält auch kommentierte semantische Beschriftungen für HD-Karten.
◆Architektur: Verwenden Sie ResNet-101 als Backbone-Netzwerk des Kamerazweigs und PointPillars als LiDAR-Zweig-Backbone-Netzwerk des Modells. Der Segmentierungskopf im Basismodell ist ein ResNet-18-basiertes FCN-Netzwerk. Für den Autoencoder wird VQVAE verwendet und das Modell wird vorab auf dem segmentierten Kartendatensatz von nuScenes trainiert, um Kartenmerkmale zu extrahieren und die Karte in einen latenten Basisraum zu komprimieren. Schließlich wird UNet zum Aufbau des Diffusionsnetzwerks verwendet.
◆Trainingsdetails: Verwenden Sie den AdamW-Optimierer, um das VQVAE-Modell für 30 Epochen zu trainieren. Der verwendete Lernratenplaner ist LambdaLR, der die Lernrate in einem exponentiellen Abfallmodus mit einem Abfallfaktor von 0,95 schrittweise reduziert. Die anfängliche Lernrate ist auf eingestellt und die Stapelgröße beträgt 8. Anschließend wurde das Diffusionsmodell mit dem AdamW-Optimierer für 30 Epochen mit einer anfänglichen Lernrate von 2e-4 von Grund auf trainiert. Es wird der MultiStepLR-Planer übernommen, der die Lernrate entsprechend vorgegebener Meilensteinzeitpunkte (0,7, 0,9, 1,0) und einem Skalierungsfaktor von 1/3 in verschiedenen Trainingsphasen anpasst. Abschließend wird das BEV-Segmentierungsergebnis auf eine Auflösung von 0,15 m eingestellt und die LiDAR-Punktwolke voxelisiert. Der Erkennungsbereich von HDMapNet beträgt [-30m, 30m]×[-15m, 15m]m, daher beträgt die entsprechende BEV-Kartengröße 400×200, während Superfusion [0m, 90m]×[-15m, 15m] verwendet und 600 erhält × 200 Ergebnisse. Aufgrund der Dimensionsbeschränkungen von LDM (8-faches Downsampling in VAE und UNet) muss die Größe der semantischen Ground-Truth-Map auf ein Vielfaches von 64 aufgefüllt werden.
◆Inferenzdetails: Die Vorhersageergebnisse werden durch 20-maliges Ausführen des Entrauschungsprozesses auf der Lärmkarte unter den aktuellen BEV-Funktionsbedingungen erhalten. Der Durchschnitt von 3 Stichproben wird als endgültiges Vorhersageergebnis verwendet.
4.2 Bewertungsindikatoren
werden hauptsächlich für kartensemantische Segmentierungs- und Instanzerkennungsaufgaben ausgewertet. Und es konzentriert sich hauptsächlich auf drei statische Kartenelemente: Fahrspurgrenzen, Fahrspurtrenner und Fußgängerüberwege.


4.3 Bewertungsergebnisse
Tabelle 1 zeigt den IoU-Score-Vergleich für die semantische Kartensegmentierung. DiffMap zeigt deutliche Verbesserungen in allen Intervallen und erzielt insbesondere bei Fahrbahntrennern und Fußgängerüberwegen die besten Ergebnisse.
 ▲Tabelle 1|IoU-Score-Vergleich
▲Tabelle 1|IoU-Score-Vergleich
Wie in Tabelle 2 gezeigt, weist die DiffMap-Methode auch eine deutliche Verbesserung der durchschnittlichen Präzision (AP) auf, was die Wirksamkeit von DiffMap bestätigt.
 ▲Tabelle 2|MAP-Score-Vergleich
▲Tabelle 2|MAP-Score-Vergleich
Wie in Tabelle 3 gezeigt, kann bei der Integration des DiffMap-Paradigmas in HDMapNet beobachtet werden, dass DiffMap die Leistung von HDMapNet verbessern kann, unabhängig davon, ob nur die Kamera oder die Kamera-Lidar-Fusionsmethode verwendet wird. Dies zeigt, dass die DiffMap-Methode bei verschiedenen Segmentierungsaufgaben effektiv ist, einschließlich der Erkennung großer und kurzer Entfernungen. Bei Grenzen schneidet DiffMap jedoch nicht gut ab, da die Formstruktur der Grenzen nicht festgelegt ist und viele unvorhersehbare Verzerrungen auftreten, was die Erfassung a priori struktureller Merkmale erschwert.
 ▲Tabelle 3|Ergebnisse der quantitativen Analyse
▲Tabelle 3|Ergebnisse der quantitativen Analyse
4.4 Ablationsexperiment
Tabelle 4 zeigt den Einfluss verschiedener Downsampling-Faktoren in VQVAE auf die Erkennungsergebnisse. Durch die Analyse des Verhaltens von DiffMap bei einem Downsampling-Faktor von 4, 8 und 16 können wir erkennen, dass die besten Ergebnisse erzielt werden, wenn der Downsampling-Faktor auf 8x eingestellt ist.
 ▲Tabelle 4|Ergebnisse des Ablationsexperiments
▲Tabelle 4|Ergebnisse des Ablationsexperiments
Darüber hinaus hat der Autor auch die Auswirkungen des Löschens des instanzbezogenen Vorhersagemoduls auf das Modell gemessen, wie in Tabelle 5 gezeigt. Experimente zeigen, dass das Hinzufügen dieser Vorhersage die IOU weiter verbessert. Tabelle 5: Ergebnisse des Ablationsexperiments (einschließlich Vorhersagemodul) Es ist offensichtlich, dass die Ergebnisse der Basissegmentierung die Formeigenschaften und die Konsistenz innerhalb der Elemente ignorieren. Im Gegensatz dazu zeigt DiffMap die Fähigkeit, diese Probleme zu korrigieren und eine Segmentierungsausgabe zu erzeugen, die gut auf die Kartenspezifikation abgestimmt ist. Insbesondere in den Fällen (a), (b), (d), (e), (h) und (l) korrigiert DiffMap effektiv ungenau vorhergesagte Fußgängerüberwege. In den Fällen (c), (d), (h), (i), (j) und (l) vervollständigt oder entfernt DiffMap ungenaue Grenzen, wodurch die Ergebnisse realistischeren Grenzgeometrien näher kommen. Darüber hinaus löst DiffMap in den Fällen (b), (f), (g), (h), (k) und (l) das Problem gebrochener Trennlinien und stellt die Parallelität benachbarter Elemente sicher. Abbildung 4: Ergebnisse der qualitativen Analyse Dadurch wird das traditionelle Kartensegmentierungsmodell verbessert. Diese Methode kann als Hilfswerkzeug für jedes Kartensegmentierungsmodell verwendet werden und ihre Vorhersageergebnisse werden sowohl in Fern- als auch in Naherkennungsszenarien erheblich verbessert. Da diese Methode hoch skalierbar ist, eignet sie sich für die Untersuchung anderer Arten von Vorinformationen. Beispielsweise kann die SD-Karte vorab in das zweite Modul von DiffMap integriert werden, um dessen Leistung zu verbessern. Es wird erwartet, dass die Fortschritte bei der vektorisierten Kartenerstellung auch in Zukunft anhalten werden.

Das obige ist der detaillierte Inhalt vonDiffMap: das erste Netzwerk, das LDM nutzt, um die hochpräzise Kartenerstellung zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



