Die AIxiv-Kolumne ist eine Kolumne, in der akademische und technische Inhalte auf dieser Website veröffentlicht werden. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Im Trainingsprozess großer Sprachmodelle ist die Art der Datenverarbeitung von entscheidender Bedeutung. Herkömmliche Methoden verbinden und teilen normalerweise eine große Anzahl von Dokumenten in Trainingssequenzen auf, die der Kontextlänge des Modells entsprechen. Obwohl dies die Trainingseffizienz verbessert, führt es häufig zu unnötigem Abschneiden von Dokumenten, beeinträchtigt die Datenintegrität und führt zum Verlust wichtiger Kontextinformationen, was sich wiederum auf die logische Kohärenz und die sachliche Konsistenz der vom Modell gelernten Inhalte auswirkt und das Ergebnis beeinträchtigt Modell leichter zu Halluzinationen. Forscher der AWS AI Labs führten eingehende Untersuchungen zu dieser gängigen Splicing-Chunking-Textverarbeitungsmethode durch und stellten fest, dass sie die Fähigkeit des Modells, kontextuelle Kohärenz und sachliche Konsistenz zu verstehen, erheblich beeinträchtigt. Dies wirkt sich nicht nur auf die Leistung des Modells bei nachgelagerten Aufgaben aus, sondern erhöht auch das Risiko von Halluzinationen. Als Reaktion auf dieses Problem schlugen sie eine innovative Strategie zur Dokumentenverarbeitung vor – Best-Fit-Packing (Best-Fit-Packing), die unnötige Textkürzungen durch Optimierung der Dokumentenkombination eliminiert und die Leistung des Modells erheblich verbessert und reduziert Modellillusion. Diese Forschung wurde in ICML 2024 aufgenommen. 
Artikeltitel: Weniger Kürzungen verbessern die SprachmodellierungPapierlink: https://arxiv.org/pdf/2404.10830 In traditionellen großen Sprachen In Bei Modelltrainingsmethoden fügen Forscher zur Verbesserung der Effizienz normalerweise mehrere Eingabedokumente zusammen und segmentieren diese verbundenen Dokumente dann in Sequenzen fester Länge. Obwohl diese Methode einfach und effizient ist, verursacht sie ein großes Problem – das Abschneiden von Dokumenten, was die Datenintegrität beeinträchtigt. Das Abschneiden eines Dokuments führt zum Verlust der im Dokument enthaltenen Informationen. Darüber hinaus reduziert die Dokumentkürzung den Kontextumfang in jeder Sequenz, was dazu führen kann, dass die Vorhersage des nächsten Wortes für das vorherige irrelevant ist, was das Modell anfälliger für Halluzinationen macht. Das folgende Beispiel zeigt die Probleme, die durch das Abschneiden von Dokumenten verursacht werden:
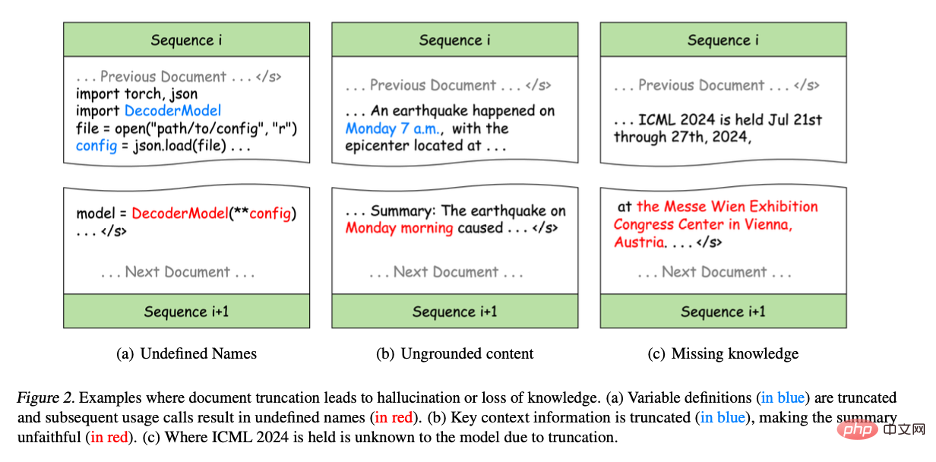
- Abbildung 2(a): Obwohl der Originalcode in der Python-Programmierung korrekt ist, teilt er die Variablendefinition und -verwendung in verschiedene Syntaxfehler auf werden in die Trainingssequenz eingeführt, was dazu führt, dass einige Variablen in nachfolgenden Trainingssequenzen undefiniert bleiben, was dazu führt, dass das Modell falsche Muster lernt und möglicherweise Halluzinationen in nachgelagerten Aufgaben erzeugt. Beispielsweise können Modelle bei Programmsyntheseaufgaben Variablen direkt verwenden, ohne sie zu definieren.
- Abbildung 2(b): Kürzung schadet auch der Integrität der Informationen. Beispielsweise kann „Montagmorgen“ in der Zusammenfassung keinem Kontext in der Trainingssequenz entsprechen, was zu ungenauen Inhalten führt. Diese Art unvollständiger Informationen verringert die Empfindlichkeit des Modells gegenüber Kontextinformationen erheblich, was dazu führt, dass der generierte Inhalt nicht mit der tatsächlichen Situation übereinstimmt, was als sogenannte untreue Generation bezeichnet wird.
- Abbildung 2(c): Kürzungen behindern auch den Wissenserwerb während des Trainings, da die Darstellung von Wissen in Texten häufig auf vollständigen Sätzen oder Absätzen beruht. Beispielsweise kann das Modell den Ort der ICML-Konferenz nicht lernen, da der Name und der Ort der Konferenz in verschiedenen Trainingssequenzen verteilt sind.
Abbildung 2. Beispiel einer Dokumentenkürzung, die zu Illusionen oder Wissensverlust führt.
(a) Die Variablendefinition (blauer Teil) wird abgeschnitten und nachfolgende Verwendungsaufrufe führen zu einem undefinierten Namen (roter Teil).
(b) Wichtige Kontextinformationen werden abgeschnitten (blauer Teil), wodurch die Zusammenfassung weniger genau ist als der Originaltext (roter Teil).
(c) Aufgrund der Kürzung weiß das Modell nicht, wo ICML 2024 stattfinden wird.
Als Reaktion auf dieses Problem schlugen Forscher Best-fit Packing vor. Diese Methode nutzt längenbewusste kombinatorische Optimierungstechniken, um Dokumente effizient in Trainingssequenzen zu packen und unnötige Kürzungen vollständig zu vermeiden. Dadurch wird nicht nur die Trainingseffizienz herkömmlicher Methoden aufrechterhalten, sondern durch die Reduzierung der Datenfragmentierung wird auch die Qualität des Modelltrainings erheblich verbessert. Der Autor unterteilt jeden Text zunächst in eine oder mehrere Sequenzen, die höchstens der Modellkontextlänge L entsprechen. Die Einschränkung dieses Schritts ergibt sich aus dem Modell und muss daher ausgeführt werden. Basierend auf einer großen Anzahl von Dateiblöcken mit einer Länge von höchstens L hoffen die Forscher nun, diese sinnvoll zu kombinieren und so wenige Trainingssequenzen wie möglich zu erhalten. Dieses Problem kann als Bin-Packing-Problem angesehen werden. Das Montageoptimierungsproblem ist NP-schwer. Wie im folgenden Algorithmus gezeigt, verwenden sie hier die heuristische Strategie des Best-Fit-Decreasing (BFD). Als nächstes diskutieren wir die Machbarkeit von BFD aus der Perspektive der Zeitkomplexität (Time Complexity) und der Kompaktheit (Compactness).
Die Zeitkomplexität sowohl beim Sortieren als auch beim Packen von BFD beträgt O(N log N), wobei N die Anzahl der Dokumentblöcke ist. Da bei der Datenverarbeitung vor dem Training die Länge des Dokumentblocks eine ganze Zahl und begrenzt ist ([1, L]), kann die Zählsortierung verwendet werden, um die zeitliche Komplexität der Sortierung auf O(N) zu reduzieren. In der Verpackungsphase benötigt jeder Vorgang zum Finden des am besten passenden Containers unter Verwendung der Segmentbaum-Datenstruktur nur logarithmische Zeit, d. h. O (log L). Und weil L < Dokumentation) nur 3 Stunden dauert.
Kompaktheit ist ein weiterer wichtiger Indikator, um die Wirkung des Verpackungsalgorithmus zu messen, ohne die Integrität des Originaldokuments zu zerstören Es ist möglich, die Effizienz des Modelltrainings zu verbessern. In praktischen Anwendungen kann das Best-Fit-Packen durch die präzise Steuerung der Füllung und Anordnung von Sequenzen eine nahezu gleiche Anzahl von Trainingssequenzen wie herkömmliche Methoden generieren und gleichzeitig den Datenverlust aufgrund von Kürzungen erheblich reduzieren.
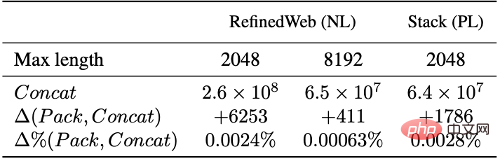
Basierend auf Experimenten mit Datensätzen in natürlicher Sprache (RefinedWeb) und Programmiersprachen (The Stack) haben wir herausgefunden, dass die am besten geeignete Verpackung die Textkürzung erheblich reduziert. Es ist erwähnenswert, dass die meisten Dokumente weniger als 2048 Token enthalten. In diesem Bereich kommt es hauptsächlich zu einer Kürzung aufgrund des herkömmlichen Spleißens und Chunkings, während bei der optimalen Verpackung keine Dokumente mit einer Länge von weniger als L gekürzt werden, sodass diese effektiv beibehalten werden die Integrität der meisten Dokumente.
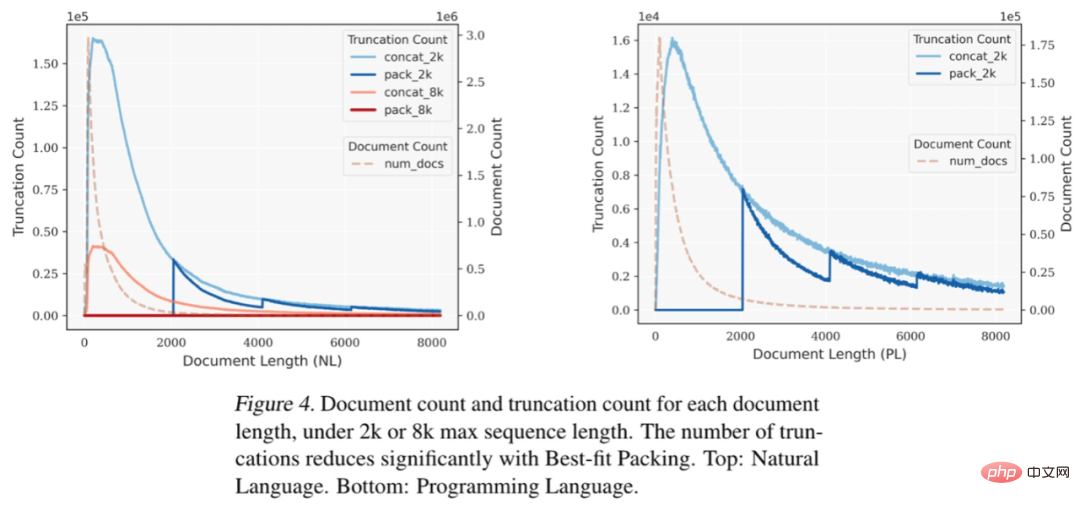
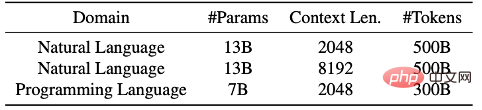
Abbildung 4: Wenn die maximale Sequenzlänge auf 2 KB oder 8 KB eingestellt ist, entsprechen bei unterschiedlichen Dokumentlängen die Anzahl der Dokumente und die Anzahl der Kürzungen jeder Dokumentlänge. Durch den Einsatz der „Best-fit Packing“-Technologie wird die Anzahl der Kürzungen deutlich reduziert. Oben: Natürliche Sprache. Unten: Programmiersprachen. Experimente und ErgebnisseDie Forscher berichteten ausführlich über den Leistungsvergleich von Sprachmodellen, die mit Best-Fit-Packaging und traditionellen Methoden (d. h. Spleißmethoden) für verschiedene Aufgaben trainiert wurden, darunter: Verarbeitung natürlicher Sprache und Programmiersprachenaufgaben, wie Leseverständnis (Reading Comprehension), Inferenz natürlicher Sprache (Natural Language Inference), Kontextverfolgung (Context Following), Textzusammenfassung (Summarization), Weltwissen (Commonsense and Closed-Book QA) und Programmsynthese, insgesamt 22 Teilaufgaben. Die Experimente umfassten Modellgrößen von 7 Milliarden bis 13 Milliarden Parametern, Sequenzlängen von 2.000 bis 8.000 Token und Datensätze, die natürliche Sprachen und Programmiersprachen abdecken. Diese Modelle werden auf großen Datensätzen wie Falcon RefinedWeb und The Stack trainiert und Experimente werden mit der LLaMA-Architektur durchgeführt.
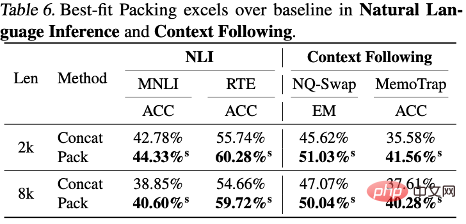
Experimentelle Ergebnisse zeigen, dass die Verwendung einer optimalen Anpassungsverpackung die Modellleistung bei einer Reihe von Aufgaben verbessert, insbesondere beim Leseverständnis (+4,7 %), beim logischen Denken in natürlicher Sprache (+9,3 %) und beim Verfolgen von Kontexten (+16,8 %). Programmsynthese (+15,0 %) und andere Aufgaben (aufgrund der unterschiedlichen Metrikskalen für verschiedene Aufgaben verwendet der Autor standardmäßig die relative Verbesserung, um die Ergebnisse zu beschreiben.) Nach statistischen Tests stellten die Forscher fest, dass alle Ergebnisse vorhanden sind entweder statistisch signifikant besser als die Basislinie (gekennzeichnet als s) oder auf Augenhöhe mit der Basislinie (gekennzeichnet als n), und es wird bei Verwendung der Best-Fit-Verpackung bei allen bewerteten Aufgaben kein signifikanter Leistungsabfall beobachtet. Diese Verbesserung der Konsistenz und Monotonie unterstreicht, dass eine optimale Anpassungsverpackung nicht nur die Gesamtleistung des Modells verbessern, sondern auch Stabilität unter verschiedenen Aufgaben und Bedingungen gewährleisten kann. Detaillierte Ergebnisse und Diskussionen entnehmen Sie bitte dem Text.
Die Autoren konzentrierten sich auf die Untersuchung der Auswirkungen der „best-fit Verpackung“ auf Halluzinationen. Bei der Zusammenfassungsgenerierung wurde mithilfe der QAFactEval-Metrik festgestellt, dass Modelle mit der am besten geeigneten Verpackung
deutlich weniger Halluzinationen hervorriefen. Noch wichtiger ist, dass in der Programmsyntheseaufgabe die Fehler „Undefinierter Name“ um bis zu 58,3 % reduziert wurden, wenn Code mit dem am besten passenden verpackten trainierten Modell generiert wurde, was zeigt, dass das Modell ein umfassenderes Verständnis der Programmstruktur hat und Logik, wodurch Halluzinationen effektiv reduziert werden.
Die Autoren zeigten auch Unterschiede in der Leistung des Modells beim Umgang mit verschiedenen Arten von Wissen auf.
Wie bereits erwähnt, kann eine Kürzung während des Trainings die Integrität der Informationen beeinträchtigen und dadurch den Wissenserwerb behindern. Die Fragen in den meisten Standardbewertungssätzen konzentrieren sich jedoch auf Allgemeinwissen, das in der menschlichen Sprache häufig vorkommt. Selbst wenn also durch Kürzung etwas Wissen verloren geht, hat das Modell immer noch gute Chancen, diese Informationen aus den Dokumentfragmenten zu lernen.
Im Gegensatz dazu ist ungewöhnliches
Tail-Wissen anfälliger für Kürzungen, da die Häufigkeit dieser Art von Informationen in den Trainingsdaten selbst gering ist und es für das Modell schwierig ist, den Verlust aus anderen Quellen zu ergänzen . Wissen.
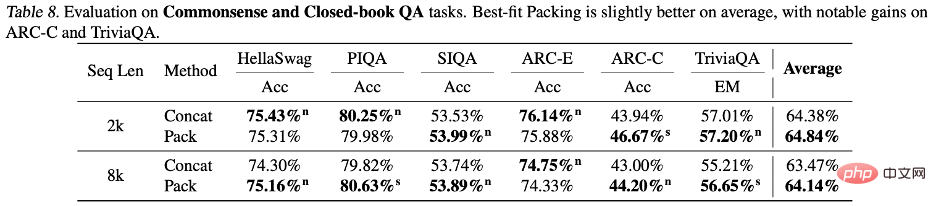
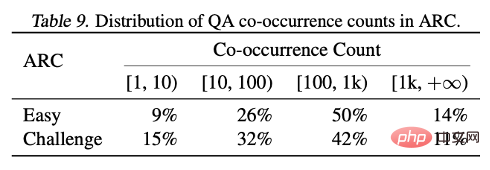
Durch die Analyse der Ergebnisse der beiden Testsätze ARC-C und ARC-E stellten die Forscher fest, dass das Modell im Vergleich zu ARC-E, das mehr allgemeines Wissen enthält, durch die Verwendung einer optimalen Anpassungsverpackung besser in der Eindämmung ist Es gibt bedeutendere Leistungsverbesserungen in ARC-C mit mehr Tail-Wissen.
Dieser Befund wird weiter verifiziert, indem die Anzahl der gleichzeitigen Vorkommen jedes Frage-Antwort-Paares in der von Kandpal et al. vorverarbeiteten Wikipedia-Entitätskarte gezählt wird. Statistische Ergebnisse zeigen, dass das Challenge-Set (ARC-C) seltenere gleichzeitig auftretende Paare enthält, was die Hypothese bestätigt, dass eine optimale Anpassungsverpackung das Erlernen von Tail-Wissen effektiv unterstützen kann, und auch erklärt, warum herkömmliche große Sprachmodelle nicht in der Lage sind, Long-Tail zu lernen Wissen liefert eine Erklärung für die aufgetretenen Schwierigkeiten.
Zusammenfassung
Dieser Artikel befasst sich mit dem häufigen Problem der Dokumentkürzung beim Training großer Sprachmodelle. Dieser Kürzungseffekt beeinträchtigt die Fähigkeit des Modells, logische Kohärenz und sachliche Konsistenz zu lernen, und verstärkt das Halluzinationsphänomen während des Generierungsprozesses. Die Autoren schlugen Best-fit Packing vor, das die Integrität jedes Dokuments durch Optimierung des Datensortierungsprozesses maximiert. Diese Methode eignet sich nicht nur für die Verarbeitung großer Datensätze mit Milliarden von Dokumenten, sondern ist auch hinsichtlich der Datenkompaktheit herkömmlichen Methoden ebenbürtig.
Experimentelle Ergebnisse zeigen, dass diese Methode äußerst effektiv bei der Reduzierung unnötiger Kürzungen ist, die Leistung des Modells bei verschiedenen Text- und Codeaufgaben erheblich verbessern kann und die Illusion der Sprachgenerierung in geschlossenen Domänen wirksam reduziert. Obwohl sich die Experimente in diesem Artikel hauptsächlich auf die Phase vor dem Training konzentrieren, kann eine optimale Anpassungsverpackung auch in anderen Phasen, wie z. B. der Feinabstimmung, eingesetzt werden. Diese Arbeit trägt zur Entwicklung effizienterer und zuverlässigerer Sprachmodelle bei und treibt die Entwicklung der Sprachmodell-Trainingstechnologie voran.
Weitere Forschungsdetails finden Sie im Originalpapier. Wenn Sie an einem Job oder Praktikum interessiert sind, können Sie den Autor dieses Artikels per E-Mail an zijwan@amazon.com.
kontaktierenDas obige ist der detaillierte Inhalt vonICML 2024 |. Die neue Grenze des Pre-Trainings für große Sprachmodelle: „Best Adaptation Packaging' gestaltet die Standards für die Dokumentenverarbeitung neu. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!









 Zusammenfassung
Zusammenfassung 















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



