
 Technologie-Peripheriegeräte
KI
OpenAI und Google haben an zwei aufeinanderfolgenden Tagen große Schritte unternommen, beide wollen KI-Assistenten „intelligent' machen
Technologie-Peripheriegeräte
KI
OpenAI und Google haben an zwei aufeinanderfolgenden Tagen große Schritte unternommen, beide wollen KI-Assistenten „intelligent' machen
OpenAI und Google haben an zwei aufeinanderfolgenden Tagen große Schritte unternommen, beide wollen KI-Assistenten „intelligent' machen

Nachdem wir gestern die Frühjahrsveröffentlichung von OpenAI gesehen haben, ist es nicht schwer zu erraten, dass es auf der heutigen Google I/O-Konferenz definitiv eine Einführung in KI-Assistenten geben wird.
Schließlich hat Altman, der GPT-4o vor der Google I/O-Konferenz veröffentlicht hat, volle Relevanz bewiesen. Mit Altmans Methoden ist er natürlich zuversichtlich, genau zuzuschlagen und diese „rote und blaue“ „Konfrontation“ bis zum Ende zu beseitigen .
Tatsächlich wurde auf der Konferenz von Google-CEO Pichai der neue KI-Assistent Project Astra von Google vorgestellt, der sein Debüt auf der Google I/O-Konferenz gab.

Was ist Projekt Astra?
Project Astra ist ein multimodaler Echtzeit-Assistent für allgemeine künstliche Intelligenz mit Google Gemini als Basis-Engine, der dem Nachfolger von Google Assistant entspricht.
Genau wie Siri, Alexa und andere KI-Assistenten, die wir in der Vergangenheit verwendet haben, können Sie immer noch mit der Stimme interagieren. Der Unterschied besteht darin, dass sie dank der einzigartigen Eigenschaften der generativen KI jetzt über bessere Verständnisfähigkeiten verfügt mehr Dinge, und was noch wichtiger ist, dieses Mal verfügt es auch über visuelle Erkennungsfunktionen, die es dem KI-Assistenten ermöglichen, die Welt mit offenen Augen zu sehen.
In der Videodemonstration von Google auf der Konferenz lag der Fokus auf der visuellen Intelligenz dieses KI-Assistenten.
In dem Demonstrationsvideo hielt ein Google-Ingenieur ein Mobiltelefon mit eingeschalteter Kamera in der Hand und ermöglichte es Gemini, Objekte zu identifizieren, die Geräusche im Raum erzeugen, den auf dem Monitorbildschirm angezeigten Code zu identifizieren und sogar die aktuelle Adresse des Moderators zu identifizieren durch Straßenansichten im Freien.

Als der Ingenieur die mit diesem KI-Assistenten ausgestattete Datenbrille auf das auf der Tafel entworfene System richtete, wandte Google den KI-Assistenten auch auf Mobiltelefone an Wie das System verbessert werden kann, kann der KI-Assistent sogar Vorschläge zur Verbesserung des Systemdesigns machen.

Dies ist die visuelle Intelligenz, die Google auf dem KI-Assistenten anzeigt. Mit dem Segen von Gemini wurden die interaktiven Fähigkeiten solcher KI-Assistenten erheblich verbessert.
Allerdings liegt ein solcher KI-Assistent hinsichtlich der Natürlichkeit der tatsächlichen Interaktion noch weit hinter den Ergebnissen zurück, die OpenAI GPT-4o gestern gezeigt hat.
OpenAI hat erfolgreich abgeschnitten
Nur einen Tag vor der Google I/O-Konferenz veranstaltete OpenAI eine große Frühjahrskonferenz, bei der der Schlüssel zum Einsatz von KI-Assistenten auf Mobiltelefonen lag Funktion, die auf dieser Konferenz demonstriert wurde.
Nach den auf der OpenAI-Konferenz demonstrierten Fähigkeiten des KI-Assistenten zu urteilen, ist der Demonstrationseffekt hinsichtlich der Benutzerfreundlichkeit des Demonstrationsinhalts, der Natürlichkeit des Interaktionsprozesses und der multimodalen Fähigkeiten dieses KI-Assistenten besser .
Das liegt daran, dass OpenAI beim Laden von GPT-4o auf das Mobiltelefon nicht nur visuelle Intelligenz hinzufügte, sondern es dem KI-Assistenten auch ermöglichte, in Echtzeit zu reagieren (die offizielle durchschnittliche Antwortverzögerung beträgt 320 Millisekunden) und kann Jederzeit getroffen werden kann, kann sogar menschliche Emotionen verstehen.
Während der Demonstration der Fähigkeiten der visuellen Intelligenz schrieb OpenAI eine mathematische Gleichung auf Papier, damit der KI-Assistent das Problem Schritt für Schritt lösen konnte, ähnlich wie ein Grundschullehrer.

Und wenn Sie mit GPT-4o einen „Videoanruf“ tätigen, kann es Ihren Gesichtsausdruck erkennen, Ihre Gefühle verstehen und wissen, ob Sie jetzt glücklich oder traurig aussehen, genau wie ein Mensch.

Es ist nicht schwer festzustellen, dass sowohl Google als auch OpenAI mit Unterstützung der heutigen Großmodelltechnologie versuchen, den ursprünglichen groben KI-Assistenten neu zu erfinden, in der Hoffnung, dass der KI-Assistent interagieren kann bei uns natürlich wie echte Menschen.
Den Videodemonstrationsergebnissen der beiden Konferenzen davor und danach nach zu urteilen, hat uns der KI-Assistent, der große Modelle als Basismotor verwendet, tatsächlich deutlich das Gefühl gegeben, dass es einen deutlichen Generationsunterschied zwischen dem aktuellen KI-Assistenten und dem vorherigen Siri gibt und Alexa.
Da die Entwicklung der generativen KI und der Großmodelltechnologie in vollem Gange ist, versucht Apple auch, Siri neu zu erfinden. Zuvor berichtete Bloomberg unter Berufung auf mit der Angelegenheit vertraute Personen, dass Apple über eine Zusammenarbeit mit OpenAI und Google spreche ihre großen Modelle auf das Betriebssystem iOS 18 umstellen.
Ob ein solcher KI-Assistent Siri wieder populär machen und zu einer Killeranwendung für KI-Telefone werden kann, hängt davon ab, ob Apple den KI-Assistenten wieder erfolgreich „verzaubern“ kann.
Das obige ist der detaillierte Inhalt vonOpenAI und Google haben an zwei aufeinanderfolgenden Tagen große Schritte unternommen, beide wollen KI-Assistenten „intelligent' machen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1664
1664
 14
1422
52
1316
25
1268
29
1240
24
14
1422
52
1316
25
1268
29
1240
24

 Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Die große Model-App Tencent Yuanbao ist online! Hunyuan wird zu einem Allround-KI-Assistenten aufgerüstet, der überall hin mitgenommen werden kann
Jun 09, 2024 pm 10:38 PM
Am 30. Mai kündigte Tencent ein umfassendes Upgrade seines Hunyuan-Modells an. Die auf dem Hunyuan-Modell basierende App „Tencent Yuanbao“ wurde offiziell eingeführt und kann in den App-Stores von Apple und Android heruntergeladen werden. Im Vergleich zur Hunyuan-Applet-Version in der vorherigen Testphase bietet Tencent Yuanbao Kernfunktionen wie KI-Suche, KI-Zusammenfassung und KI-Schreiben für Arbeitseffizienzszenarien. Yuanbaos Gameplay ist außerdem umfangreicher und bietet mehrere Funktionen für KI-Anwendungen , und neue Spielmethoden wie das Erstellen persönlicher Agenten werden hinzugefügt. „Tencent strebt nicht danach, der Erste zu sein, der große Modelle herstellt.“ Liu Yuhong, Vizepräsident von Tencent Cloud und Leiter des großen Modells von Tencent Hunyuan, sagte: „Im vergangenen Jahr haben wir die Fähigkeiten des großen Modells von Tencent Hunyuan weiter gefördert.“ . In die reichhaltige und umfangreiche polnische Technologie in Geschäftsszenarien eintauchen und gleichzeitig Einblicke in die tatsächlichen Bedürfnisse der Benutzer gewinnen
 Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Das große Bytedance Beanbao-Modell wurde veröffentlicht. Der Full-Stack-KI-Dienst Volcano Engine unterstützt Unternehmen bei der intelligenten Transformation
Jun 05, 2024 pm 07:59 PM
Tan Dai, Präsident von Volcano Engine, sagte, dass Unternehmen, die große Modelle gut implementieren wollen, vor drei zentralen Herausforderungen stehen: Modelleffekt, Inferenzkosten und Implementierungsschwierigkeiten: Sie müssen über eine gute Basisunterstützung für große Modelle verfügen, um komplexe Probleme zu lösen, und das müssen sie auch Dank der kostengünstigen Inferenzdienste können große Modelle weit verbreitet verwendet werden, und es werden mehr Tools, Plattformen und Anwendungen benötigt, um Unternehmen bei der Implementierung von Szenarien zu unterstützen. ——Tan Dai, Präsident von Huoshan Engine 01. Das große Sitzsackmodell feiert sein Debüt und wird häufig genutzt. Das Polieren des Modelleffekts ist die größte Herausforderung für die Implementierung von KI. Tan Dai wies darauf hin, dass ein gutes Modell nur durch ausgiebigen Gebrauch poliert werden kann. Derzeit verarbeitet das Doubao-Modell täglich 120 Milliarden Text-Tokens und generiert 30 Millionen Bilder. Um Unternehmen bei der Umsetzung groß angelegter Modellszenarien zu unterstützen, wird das von ByteDance unabhängig entwickelte Beanbao-Großmodell durch den Vulkan gestartet
 Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
Fortgeschrittene Praxis des industriellen Wissensgraphen
Jun 13, 2024 am 11:59 AM
1. Einführung in den Hintergrund Lassen Sie uns zunächst die Entwicklungsgeschichte von Yunwen Technology vorstellen. Yunwen Technology Company ... 2023 ist die Zeit, in der große Modelle vorherrschen. Viele Unternehmen glauben, dass die Bedeutung von Diagrammen nach großen Modellen stark abgenommen hat und die zuvor untersuchten voreingestellten Informationssysteme nicht mehr wichtig sind. Mit der Förderung von RAG und der Verbreitung von Data Governance haben wir jedoch festgestellt, dass eine effizientere Datenverwaltung und qualitativ hochwertige Daten wichtige Voraussetzungen für die Verbesserung der Wirksamkeit privatisierter Großmodelle sind. Deshalb beginnen immer mehr Unternehmen, darauf zu achten zu wissenskonstruktionsbezogenen Inhalten. Dies fördert auch den Aufbau und die Verarbeitung von Wissen auf einer höheren Ebene, wo es viele Techniken und Methoden gibt, die erforscht werden können. Es ist ersichtlich, dass das Aufkommen einer neuen Technologie nicht alle alten Technologien besiegt, sondern auch neue und alte Technologien integrieren kann.
 Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Benchmark GPT-4! Das große Jiutian-Modell von China Mobile hat die doppelte Registrierung bestanden
Apr 04, 2024 am 09:31 AM
Laut Nachrichten vom 4. April hat die Cyberspace Administration of China kürzlich eine Liste registrierter großer Modelle veröffentlicht, in der das „Jiutian Natural Language Interaction Large Model“ von China Mobile enthalten ist, was darauf hinweist, dass das große Jiutian AI-Modell von China Mobile offiziell generative künstliche Intelligenz bereitstellen kann Geheimdienste nach außen. China Mobile gab an, dass dies das erste groß angelegte Modell sei, das von einem zentralen Unternehmen entwickelt wurde und sowohl die nationale Doppelregistrierung „Generative Artificial Intelligence Service Registration“ als auch die „Domestic Deep Synthetic Service Algorithm Registration“ bestanden habe. Berichten zufolge zeichnet sich Jiutians großes Modell für die Interaktion mit natürlicher Sprache durch verbesserte Branchenfähigkeiten, Sicherheit und Glaubwürdigkeit aus und unterstützt die vollständige Lokalisierung. Es hat mehrere Parameterversionen wie 9 Milliarden, 13,9 Milliarden, 57 Milliarden und 100 Milliarden gebildet. und kann flexibel in der Cloud eingesetzt werden, Edge und End sind unterschiedliche Situationen
 Der GPT Store kann es nicht einmal wagen, diesen Weg einzuschlagen. ?
Apr 19, 2024 pm 09:30 PM
Der GPT Store kann es nicht einmal wagen, diesen Weg einzuschlagen. ?
Apr 19, 2024 pm 09:30 PM
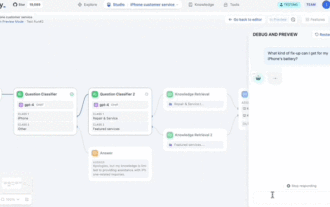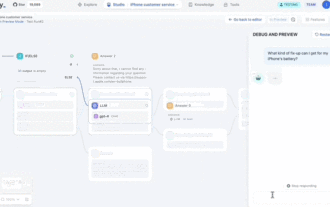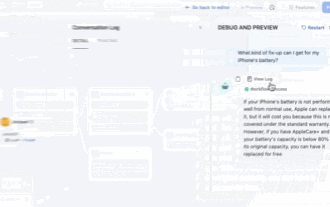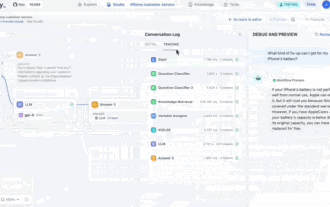
Achtung, dieser Mann hat mehr als 1.000 große Modelle angeschlossen, sodass Sie problemlos anschließen und wechseln können. Kürzlich wurde ein visueller KI-Workflow eingeführt: Er bietet Ihnen eine intuitive Drag-and-Drop-Oberfläche, mit der Sie Ihren eigenen Workflow per Drag-and-Drop auf einer unendlichen Leinwand anordnen können. Wie das Sprichwort sagt: Krieg kostet Geschwindigkeit, und Qubit hörte, dass Benutzer innerhalb von 48 Stunden nach der Online-Schaltung dieses AIWorkflows bereits persönliche Workflows mit mehr als 100 Knoten konfiguriert hatten. Ohne weitere Umschweife möchte ich heute über Dify, ein LLMOps-Unternehmen, und seinen CEO Zhang Luyu sprechen. Zhang Luyu ist auch der Gründer von Dify. Bevor er in das Unternehmen eintrat, verfügte er über 11 Jahre Erfahrung in der Internetbranche. Ich beschäftige mich mit Produktdesign, verstehe Projektmanagement und habe einige einzigartige Einblicke in SaaS. Später er
 Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Neuer Test-Benchmark veröffentlicht, der leistungsstärkste Open-Source-Llama 3 ist peinlich
Apr 23, 2024 pm 12:13 PM
Wenn die Testfragen zu einfach sind, können sowohl Spitzenschüler als auch schlechte Schüler 90 Punkte erreichen, und der Abstand kann nicht vergrößert werden ... Mit der Veröffentlichung stärkerer Modelle wie Claude3, Llama3 und später sogar GPT-5 ist die Branche in Bewegung Dringender Bedarf an einem schwierigeren und differenzierteren Benchmark-Modell. LMSYS, die Organisation hinter der großen Modellarena, brachte den Benchmark der nächsten Generation, Arena-Hard, auf den Markt, der große Aufmerksamkeit erregte. Es gibt auch die neueste Referenz zur Stärke der beiden fein abgestimmten Versionen der Llama3-Anweisungen. Im Vergleich zu MTBench, das zuvor ähnliche Ergebnisse erzielte, stieg die Arena-Hard-Diskriminierung von 22,6 % auf 87,4 %, was auf den ersten Blick stärker und schwächer ist. Arena-Hard basiert auf menschlichen Echtzeitdaten aus der Arena und seine Übereinstimmungsrate mit menschlichen Vorlieben liegt bei bis zu 89,1 %.
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Die lokale Ausführungsleistung des Embedding-Dienstes übertrifft die von OpenAI Text-Embedding-Ada-002, was sehr praktisch ist!
Apr 15, 2024 am 09:01 AM
Ollama ist ein superpraktisches Tool, mit dem Sie Open-Source-Modelle wie Llama2, Mistral und Gemma problemlos lokal ausführen können. In diesem Artikel werde ich vorstellen, wie man Ollama zum Vektorisieren von Text verwendet. Wenn Sie Ollama nicht lokal installiert haben, können Sie diesen Artikel lesen. In diesem Artikel verwenden wir das Modell nomic-embed-text[2]. Es handelt sich um einen Text-Encoder, der OpenAI text-embedding-ada-002 und text-embedding-3-small bei kurzen und langen Kontextaufgaben übertrifft. Starten Sie den nomic-embed-text-Dienst, wenn Sie o erfolgreich installiert haben
