1. Gesamtrahmen

Die Hauptaufgaben lassen sich in drei Kategorien einteilen. Die erste besteht darin, kausale Strukturen zu entdecken, also kausale Beziehungen zwischen Variablen aus den Daten zu identifizieren. Die zweite Möglichkeit besteht darin, kausale Effekte abzuschätzen, also aus den Daten den Grad des Einflusses einer Variablen auf eine andere Variable abzuleiten. Es ist zu beachten, dass sich dieser Einfluss nicht auf die relative Natur bezieht, sondern darauf, wie sich der Wert oder die Verteilung einer anderen Variablen ändert, wenn in eine Variable eingegriffen wird. Der letzte Schritt besteht darin, Verzerrungen zu korrigieren, da bei vielen Aufgaben verschiedene Faktoren dazu führen können, dass die Verteilung von Entwicklungsbeispielen und Anwendungsbeispielen unterschiedlich ist. In diesem Fall kann uns die kausale Schlussfolgerung dabei helfen, Verzerrungen zu korrigieren.
Diese Funktionen eignen sich für eine Vielzahl von Szenarien, das typischste davon sind Entscheidungsszenarien. Durch kausale Schlussfolgerungen können wir verstehen, wie verschiedene Benutzer auf unser Entscheidungsverhalten reagieren. Zweitens sind Geschäftsprozesse in Industrieszenarien oft komplex und langwierig, was zu Datenverzerrungen führt. Eine klare Beschreibung der Ursache-Wirkungs-Beziehungen dieser Abweichungen durch kausale Schlussfolgerungen kann uns helfen, sie zu korrigieren. Darüber hinaus stellen viele Szenarien hohe Anforderungen an die Robustheit und Interpretierbarkeit des Modells. Es besteht die Hoffnung, dass das Modell Vorhersagen auf der Grundlage kausaler Beziehungen treffen kann und kausale Schlussfolgerungen dazu beitragen können, leistungsfähigere Erklärungsmodelle zu erstellen. Schließlich ist auch die Bewertung der Auswirkungen von Entscheidungsergebnissen wichtig. Kausaler Rückschluss kann helfen, die tatsächlichen Auswirkungen von Strategien besser zu analysieren.
Als nächstes stellen wir zwei wichtige Themen der kausalen Schlussfolgerung vor: Wie beurteilt man, ob eine Szene für kausale Schlussfolgerungen geeignet ist, und typische Algorithmen für kausale Schlussfolgerungen.
Zunächst ist es wichtig zu bestimmen, ob ein Szenario für die Anwendung kausaler Schlussfolgerungen geeignet ist. Kausaler Rückschluss wird normalerweise verwendet, um das Problem der Kausalität zu lösen, dh um anhand beobachteter Daten auf die Beziehung zwischen Ursache und Wirkung zu schließen. Daher führen wir bei der Beurteilung eines
2. Anwendungsszenariobewertung (Entscheidungsproblem)
zunächst die Beurteilung ein, ob ein Szenario für die Verwendung von Inferenz geeignet ist Dabei geht es vor allem um Entscheidungsprobleme.
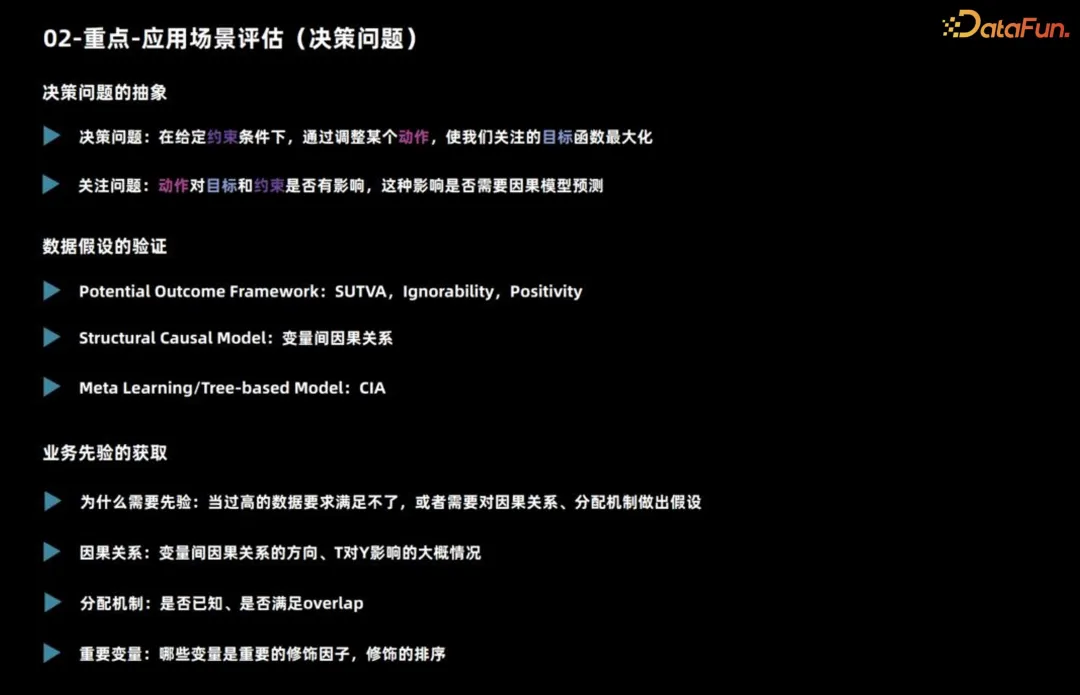
Was ein Entscheidungsproblem betrifft, müssen Sie zunächst klären, um was es sich handelt, d. h. welche Maßnahmen unter welchen Einschränkungen zu ergreifen sind, um welches Ziel zu maximieren. Anschließend müssen Sie überlegen, ob diese Aktion Auswirkungen auf die Ziele und Einschränkungen hat und ob Sie zur Vorhersage ein kausales Inferenzmodell verwenden müssen.
Wenn wir beispielsweise ein Produkt vermarkten, überlegen wir in der Regel, ob wir angesichts des Gesamtbudgets jedem Benutzer Gutscheine oder Rabatte gewähren. Betrachten Sie die Umsatzmaximierung als übergeordnetes Ziel. Wenn keine Budgetbeschränkung besteht, kann sich dies auf die Endverkäufe auswirken. Solange Sie jedoch wissen, dass es sich um eine Vorwärtsstrategie handelt, können Sie allen Benutzern Rabatte gewähren.
In diesem Fall hat die Entscheidungshandlung zwar Auswirkungen auf das Ziel, es besteht jedoch keine Notwendigkeit, zur Vorhersage ein kausales Inferenzmodell zu verwenden.
Das Obige ist die grundlegende Analyse des Entscheidungsproblems. Darüber hinaus muss beobachtet werden, ob die Datenelemente erfüllt sind. Für die Erstellung von Kausalmodellen stellen unterschiedliche Kausalalgorithmen unterschiedliche Anforderungen an Daten und Aufgabenannahmen.
- Das Modell potenzieller Ergebnisklassen basiert auf drei Hauptannahmen. Erstens muss der individuelle kausale Effekt stabil sein, wenn beispielsweise die Auswirkung der Ausgabe von Gutscheinen auf die Kaufwahrscheinlichkeit der Benutzer untersucht wird, muss sichergestellt werden, dass das Verhalten eines Benutzers nicht durch andere Benutzer, z. B. durch Offline-Preisvergleiche, beeinflusst wird durch Gutscheine mit unterschiedlichen Rabatten. Die zweite Annahme besteht darin, dass die tatsächliche Verarbeitung des Benutzers und die möglichen Ergebnisse unabhängig von der charakteristischen Situation sind, was zur Behandlung unbeobachteter Verwirrungen verwendet werden kann. Bei der dritten Hypothese geht es um Überschneidungen, das heißt, jeder Benutzertyp sollte unterschiedliche Entscheidungen treffen, da sonst die Leistung dieses Benutzertyps bei unterschiedlichen Entscheidungen nicht beobachtet werden kann.
- Die Hauptannahme struktureller Kausalmodelle ist der kausale Zusammenhang zwischen Variablen, und diese Annahmen sind oft schwer zu beweisen. Beim Einsatz von Meta-Learning und baumbasierten Methoden wird in der Regel von bedingter Unabhängigkeit ausgegangen, d. h. gegebene Merkmale, Entscheidungshandlungen und potenzielle Ergebnisse sind unabhängig. Diese Annahme ähnelt der zuvor erwähnten Unabhängigkeitsannahme.
In tatsächlichen Geschäftsszenarien ist das Verständnis von Vorkenntnissen entscheidend. Zunächst muss man den Verteilungsmechanismus tatsächlicher Beobachtungsdaten verstehen, der die Grundlage für frühere Entscheidungen darstellt. Wenn die genauesten Daten nicht verfügbar sind, kann es notwendig sein, sich auf Annahmen zu verlassen, um Schlussfolgerungen zu ziehen. Zweitens kann uns die Geschäftserfahrung dabei helfen, zu bestimmen, welche Variablen einen erheblichen Einfluss auf die Unterscheidung kausaler Effekte haben, was für die Feature-Entwicklung von entscheidender Bedeutung ist. Wenn wir uns also mit tatsächlichen Geschäften befassen, können wir in Kombination mit dem Verteilungsmechanismus von Beobachtungsdaten und Geschäftserfahrung Herausforderungen besser bewältigen und Entscheidungen und Feature-Engineering effektiv durchführen.
3. Typischer Kausalalgorithmus
Das zweite wichtige Thema ist die Auswahl des Kausalinferenzalgorithmus.
Der erste ist der Algorithmus zur Entdeckung der Kausalstruktur. Das Hauptziel dieser Algorithmen besteht darin, kausale Zusammenhänge zwischen Variablen zu ermitteln. Die wichtigsten Forschungsideen lassen sich in drei Kategorien einteilen. Die erste Methode besteht darin, anhand der bedingten Unabhängigkeitsmerkmale des Knotennetzwerks im Kausalgraphen zu beurteilen. Ein anderer Ansatz besteht darin, eine Bewertungsfunktion zu definieren, um die Qualität des Kausaldiagramms zu messen. Beispielsweise wird durch die Definition einer Likelihood-Funktion ein gerichteter azyklischer Graph gesucht, der die Funktion maximiert, und als Kausalgraph verwendet. Der dritte Methodentyp führt mehr Informationen ein. Nehmen Sie beispielsweise an, dass der eigentliche Datengenerierungsprozess für zwei Variablen einem nm-Typ, einem additiven Rauschmodell, folgt, und ermitteln Sie dann die Richtung der Kausalität zwischen den beiden Variablen.
Die Schätzung kausaler Effekte umfasst eine Vielzahl von Algorithmen. Hier sind einige gängige Algorithmen:
- Die erste ist die instrumentelle Variablenmethode, die Did-Methode und die synthetische Kontrollmethode, die in der Ökonometrie häufig erwähnt werden. Die Kernidee der instrumentellen Variablenmethode besteht darin, Variablen zu finden, die mit der Behandlung, aber nicht mit dem Zufallsfehlerterm in Zusammenhang stehen, also instrumentelle Variablen. Zu diesem Zeitpunkt wird die Beziehung zwischen der instrumentellen Variablen und der abhängigen Variablen nicht durch Verwirrung beeinflusst. Die Vorhersage kann in zwei Phasen unterteilt werden: Verwenden Sie zunächst die instrumentelle Variable, um die Behandlungsvariable vorherzusagen, und verwenden Sie dann die vorhergesagte Behandlungsvariable, um sie vorherzusagen Die abhängige Variable ist der durchschnittliche Behandlungseffekt (ATE). Die DID-Methode und das synthetische Kontrollgesetz sind Methoden, die für Paneldaten entwickelt wurden, aber hier nicht im Detail vorgestellt werden.
- Ein weiterer gängiger Ansatz ist die Verwendung von Propensity Scores zur Abschätzung kausaler Effekte. Der Kern dieser Methode besteht darin, den versteckten Allokationsmechanismus vorherzusagen, beispielsweise die Wahrscheinlichkeit, einen Coupon auszugeben, im Vergleich zur Wahrscheinlichkeit, keinen Coupon auszugeben. Wenn zwei Benutzer die gleiche Wahrscheinlichkeit haben, Gutscheine auszugeben, ein Benutzer den Gutschein jedoch tatsächlich erhalten hat und der andere nicht, können wir die beiden Benutzer hinsichtlich des Verteilungsmechanismus als gleichwertig betrachten und daher ihre Auswirkungen vergleichen. Darauf aufbauend kann eine Reihe von Methoden verallgemeinert werden, darunter Matching-Methoden, hierarchische Methoden, Gewichtungsmethoden usw.
- Eine andere Methode besteht darin, das Ergebnis direkt vorherzusagen. Selbst wenn unbeobachtete Störfaktoren vorliegen, können die Ergebnisse direkt durch Annahmen vorhergesagt und durch das Modell automatisch angepasst werden. Dieser Ansatz wirft jedoch möglicherweise die Frage auf: Wenn die direkte Vorhersage des Ergebnisses ausreicht, verschwindet das Problem dann? Eigentlich nicht.
- Die vierte Idee ist die Kombination von Neigungsbewertung und potenziellen Ergebnissen, wobei die Verwendung dualer robuster und dualer maschineller Lernmethoden möglicherweise genauer ist. Duale Robustheit und duales maschinelles Lernen bieten doppelte Sicherheit durch die Kombination zweier Methoden, wobei die Genauigkeit beider Teile die Zuverlässigkeit des Endergebnisses gewährleistet.
- Eine weitere Methode ist das strukturelle Kausalmodell, das ein Modell auf der Grundlage von Ursache-Wirkungs-Beziehungen erstellt, beispielsweise Ursache-Wirkungs-Diagrammen oder strukturierten Gleichungen. Dieser Ansatz ermöglicht die direkte Intervention einer Variablen, um ein Ergebnis zu erhalten, sowie kontrafaktische Schlussfolgerungen. Allerdings geht dieser Ansatz davon aus, dass wir die kausalen Zusammenhänge zwischen Variablen bereits kennen, was oft eine luxuriöse Annahme ist.
- Meta-Lernmethode ist eine wichtige Lernmethode, die viele verschiedene Kategorien abdeckt. Eines davon ist S-Learning, das die Verarbeitungsmethode als Feature behandelt und direkt in das Modell einspeist. Durch Anpassen dieser Funktion können wir Änderungen in den Ergebnissen bei verschiedenen Verarbeitungsmethoden beobachten. Dieser Ansatz wird manchmal als Einzelmodell-Lerner bezeichnet, da wir für jede Versuchs- und Kontrollgruppe ein Modell erstellen und dann die Merkmale ändern, um die Ergebnisse zu beobachten. Eine weitere Methode ist X-Learning, dessen Prozess dem S-Learning ähnelt, jedoch zusätzlich den Schritt der Kreuzvalidierung berücksichtigt, um die Leistung des Modells genauer zu bewerten.
- Die Baummethode ist eine intuitive und einfache Methode, die die Stichprobe durch den Aufbau einer Baumstruktur aufteilt, um den Unterschied in den kausalen Effekten auf den linken und rechten Knoten zu maximieren. Da diese Methode jedoch anfällig für Überanpassung ist, werden in der Praxis häufig Methoden wie Random Forests verwendet, um das Risiko einer Überanpassung zu verringern. Die Verwendung der Boosting-Methode kann die Herausforderung erhöhen, da es einfacher ist, einige Informationen herauszufiltern. Daher müssen komplexere Modelle entworfen werden, um Informationsverluste bei der Verwendung zu verhindern. Meta-Lernmethoden und baumbasierte Algorithmen werden oft auch als Uplift-Modelle bezeichnet.
- Kausale Darstellung ist eines der Gebiete, das in den letzten Jahren in der Wissenschaft gewisse Ergebnisse erzielt hat. Ziel dieser Methode ist es, verschiedene Module zu entkoppeln und Einflussfaktoren zu trennen, um Störfaktoren genauer zu identifizieren. Durch die Analyse der Faktoren, die die abhängige Variable y und die Behandlungsvariable (Behandlung) beeinflussen, können wir Störfaktoren identifizieren, die sich auf y und die Behandlung auswirken können. Diese Faktoren werden als Störfaktoren bezeichnet. Es wird erwartet, dass diese Methode den End-to-End-Lerneffekt des Modells verbessert. Nehmen Sie zum Beispiel den Propensity Score, der häufig hervorragende Arbeit bei der Bewältigung von Störfaktoren leistet. Allerdings ist eine übermäßige Genauigkeit der Neigungswerte manchmal ungünstig. Unter demselben Neigungswert kann es Situationen geben, in denen die Überlappungsannahme nicht erfüllt werden kann, da der Neigungswert einige Informationen enthalten kann, die sich auf die Störfaktoren beziehen, aber keinen Einfluss auf y haben. Wenn das Modell zu genau lernt, kann es beim gewichteten Matching oder bei der hierarchischen Verarbeitung zu größeren Fehlern kommen. Diese Fehler werden nicht tatsächlich durch Störfaktoren verursacht und müssen daher nicht berücksichtigt werden. Lernmethoden zur Kausaldarstellung bieten eine Möglichkeit, dieses Problem zu lösen und können die Identifizierung und Analyse von Kausalzusammenhängen effektiver bewältigen.
4. Schwierigkeiten bei der tatsächlichen Umsetzung des Kausalschlusses
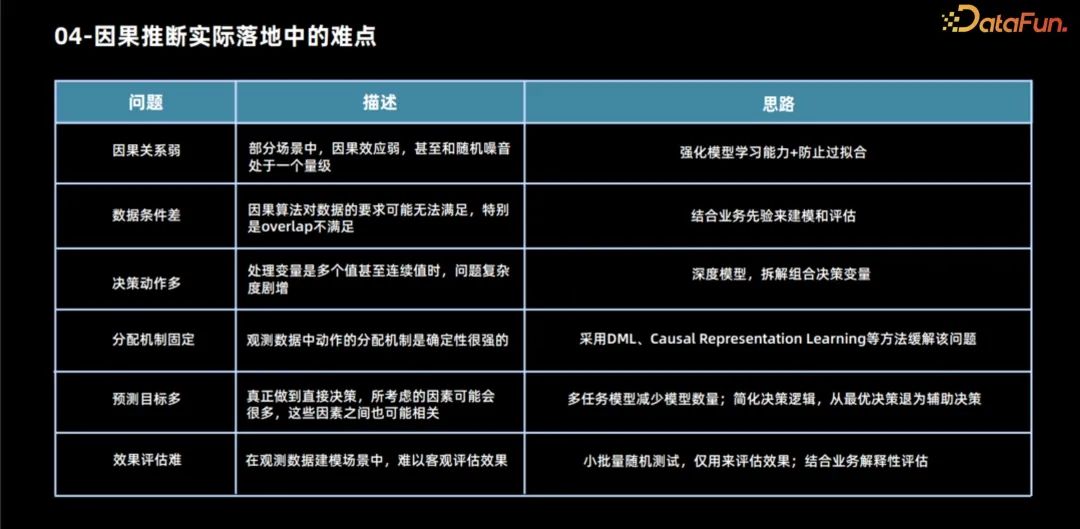
Kausale Schlussfolgerungen stehen in praktischen Anwendungen vor vielen Herausforderungen.
- Schwächung des Kausalzusammenhangs. In vielen Szenarien liegen kausale Zusammenhänge oft in der gleichen Größenordnung wie zufällige Schwankungen im Rauschen, was eine große Herausforderung für die Modellierungsbemühungen darstellt. In diesem Fall ist der Nutzen der Modellierung relativ gering, da der Kausalzusammenhang selbst nicht offensichtlich ist. Doch selbst wenn eine Modellierung notwendig ist, werden Modelle mit stärkeren Lernfähigkeiten benötigt, um diesen geschwächten Kausalzusammenhang genau zu erfassen. Gleichzeitig muss dem Problem der Überanpassung besondere Aufmerksamkeit gewidmet werden, da Modelle mit starken Lernfähigkeiten möglicherweise anfälliger für Rauschen sind, was zu einer Überanpassung des Modells an die Daten führt.
- Das zweite häufige Problem sind unzureichende Datenbedingungen. Der Umfang dieses Problems ist relativ groß, vor allem weil die von uns verwendeten Algorithmusannahmen viele Mängel aufweisen, insbesondere wenn Beobachtungsdaten zur Modellierung verwendet werden und unsere Annahmen möglicherweise nicht vollständig wahr sind. Zu den häufigsten Problemen gehört, dass die Überlappungsannahme möglicherweise nicht erfüllt ist und unser Zuordnungsmechanismus möglicherweise nicht zufällig ist. Ein schwerwiegenderes Problem besteht darin, dass wir nicht einmal über genügend zufällige Testdaten verfügen, was es schwierig macht, die Leistung des Modells objektiv zu bewerten. Wenn wir in diesem Fall immer noch auf der Modellierung bestehen und die Modellleistung besser ist als die jährliche Regel, können wir anhand einiger Geschäftserfahrungen beurteilen, ob die Entscheidung des Modells angemessen ist. Aus geschäftlicher Sicht gibt es keine besonders gute theoretische Lösung für Situationen, in denen einige Annahmen nicht zutreffen, beispielsweise unbeobachtete Störfaktoren. Wenn Sie jedoch ein Modell verwenden müssen, können Sie versuchen, einige kleine Zufallssimulationen auf der Grundlage des Geschäfts durchzuführen Erfahrung oder Tests zur Beurteilung der Richtung und des Ausmaßes des Einflusses von Störfaktoren. Gleichzeitig werden wir unter Berücksichtigung dieser Faktoren im Modell für Situationen, in denen die überlappende Annahme nicht erfüllt ist, dies hier gemeinsam besprechen, obwohl dies das vierte Problem in unserer Aufzählung ist. Wir können einige Algorithmen verwenden, um einige auszuschließen Allokationsmechanismen, d. h. dieses Problem wird durch kausales Repräsentationslernen gemildert.
- Beim Umgang mit dieser Komplexität sind entscheidungsfreudige Handlungen besonders wichtig. Viele bestehende Modelle konzentrieren sich auf die Lösung binärer Probleme. Wenn jedoch mehrere Verarbeitungslösungen beteiligt sind, wird die Zuweisung von Ressourcen zu einem komplexeren Problem. Um dieser Herausforderung zu begegnen, können wir mehrere Verarbeitungslösungen in Teilprobleme in verschiedenen Bereichen zerlegen. Darüber hinaus können wir mithilfe von Deep-Learning-Methoden Verarbeitungsschemata als Merkmale behandeln und davon ausgehen, dass zwischen kontinuierlichen Verarbeitungsschemata und Ergebnissen eine gewisse funktionale Beziehung besteht. Durch die Optimierung der Parameter dieser Funktionen können kontinuierliche Entscheidungsprobleme besser gelöst werden. Dies führt jedoch auch zu einigen zusätzlichen Annahmen, beispielsweise zu Überlappungsproblemen.
- Der Zuteilungsmechanismus ist festgelegt. Siehe Analyse oben.
- Ein weiteres häufiges Problem sind viele Zielvorhersagen. In einigen Fällen werden Zielvorhersagen von mehreren Faktoren beeinflusst, die wiederum mit Behandlungsoptionen verbunden sind. Um dieses Problem zu lösen, können wir eine Multitasking-Lernmethode verwenden. Obwohl es schwierig sein kann, komplexe Rollenprobleme direkt zu lösen, können wir das Problem vereinfachen und nur die kritischsten Indikatoren vorhersagen, die vom Behandlungsplan betroffen sind, und zwar schrittweise eine Referenz für die Entscheidungsfindung.
- Schließlich sind die Kosten für Stichprobentests in einigen Szenarien höher und der Wiederherstellungszyklus der Wirkung ist länger. Es ist besonders wichtig, die Leistung des Modells vollständig zu bewerten, bevor es online geht. In diesem Fall können kleinräumige randomisierte Tests zur Bewertung der Wirksamkeit eingesetzt werden. Obwohl der zur Bewertung des Modells erforderliche Stichprobensatz viel kleiner ist als der zur Modellierung erforderliche Stichprobensatz, können wir die Angemessenheit der Modellentscheidungsergebnisse möglicherweise nur anhand der geschäftlichen Interpretierbarkeit beurteilen, wenn selbst kleine Zufallstests nicht möglich sind. 5. Fall: Das Kreditlimit-Entscheidungsmodell von JD Technology als Beispiel, um zu zeigen, wie die kausale Inferenztechnologie zur Formulierung von Kreditprodukten verwendet werden kann, um das optimale Kreditlimit zu bestimmen. Nachdem die Geschäftsziele festgelegt wurden, können diese Ziele in der Regel in Benutzerleistungsindikatoren unterteilt werden, beispielsweise die Produktnutzung und das Kreditaufnahmeverhalten der Benutzer. Durch die Analyse dieser Indikatoren können Geschäftsziele wie Gewinn und Größe berechnet werden. Daher ist der Entscheidungsprozess für Kreditlimits in zwei Schritte unterteilt: Verwenden Sie zunächst die kausale Inferenztechnologie, um die Leistung des Benutzers unter verschiedenen Kreditlimits vorherzusagen, und verwenden Sie dann verschiedene Methoden, um das optimale Kreditlimit für jeden Benutzer basierend auf diesen Leistungen zu bestimmen Betriebsziele.
6. Zukünftige Entwicklung
Wir werden in der zukünftigen Entwicklung mit einer Reihe von Herausforderungen und Chancen konfrontiert sein.
Angesichts der Unzulänglichkeiten aktueller Kausalmodelle sind akademische Kreise zunächst einmal davon überzeugt, dass groß angelegte Modelle erforderlich sind, um komplexere nichtlineare Zusammenhänge zu bewältigen. Kausalmodelle befassen sich in der Regel nur mit zweidimensionalen Daten und die meisten Modellstrukturen sind relativ einfach, sodass künftige Forschungsrichtungen die Behandlung dieses Problems umfassen könnten.
Zweitens schlugen die Forscher das Konzept des kausalen Repräsentationslernens vor und betonten die Bedeutung der Entkopplung und modularer Ideen beim Repräsentationslernen. Durch das Verständnis des Datengenerierungsprozesses aus einer kausalen Perspektive können Modelle, die auf realen Gesetzen basieren, wahrscheinlich bessere Übertragungsmöglichkeiten und eine bessere Verallgemeinerung aufweisen.
Abschließend wiesen die Forscher darauf hin, dass die aktuellen Annahmen zu stark sind und in vielen Fällen den tatsächlichen Bedarf nicht erfüllen können, sodass für unterschiedliche Szenarien unterschiedliche Modelle übernommen werden müssen. Daraus ergibt sich auch eine sehr hohe Hemmschwelle für die Modellimplementierung. Daher ist es von großem Wert, einen vielseitigen Schlangenöl-Algorithmus zu finden.
Das obige ist der detaillierte Inhalt vonKonzentrieren Sie sich darauf! ! Analyse zweier wichtiger Algorithmus-Frameworks für kausale Schlussfolgerungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!





















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



