
 Technologie-Peripheriegeräte
KI
1,5-mal jenseits der Beugungsgrenze sind die Abbildungsbedingungen zehnmal niedriger, die Tsinghua-Universität und die Chinesische Akademie der Wissenschaften nutzen KI-Methoden, um die Mikroskopauflösung zu verbessern
Technologie-Peripheriegeräte
KI
1,5-mal jenseits der Beugungsgrenze sind die Abbildungsbedingungen zehnmal niedriger, die Tsinghua-Universität und die Chinesische Akademie der Wissenschaften nutzen KI-Methoden, um die Mikroskopauflösung zu verbessern
1,5-mal jenseits der Beugungsgrenze sind die Abbildungsbedingungen zehnmal niedriger, die Tsinghua-Universität und die Chinesische Akademie der Wissenschaften nutzen KI-Methoden, um die Mikroskopauflösung zu verbessern

Herausgeber |. Computergestützte Superauflösungsmethoden, einschließlich traditioneller Analysealgorithmen und Deep-Learning-Modelle, haben die optische Mikroskopie erheblich verbessert. Unter diesen haben überwachte tiefe neuronale Netze eine hervorragende Leistung gezeigt, aber aufgrund der hohen Dynamik lebender Zellen sind große Mengen hochwertiger Trainingsdaten erforderlich, und die Beschaffung dieser Daten ist sehr mühsam und unpraktisch.
In der neuesten Forschung haben Forscher der Tsinghua-Universität und der Chinesischen Akademie der Wissenschaften Zero-Shot-Dekonvolutionsnetzwerke (ZS-DeconvNet) entwickelt, die die Auflösung von Mikroskopbildern sofort um das 1,5-fache über die oben genannte Beugungsgrenze hinaus erhöhen können, während die Fluoreszenz ist zehnmal niedriger als bei herkömmlichen hochauflösenden Bildgebungsbedingungen und wird unbeaufsichtigt durchgeführt, ohne dass Bodenexperimente oder zusätzliche Datenerfassung erforderlich sind.
Die Forscher demonstrierten außerdem die vielseitige Anwendbarkeit von ZS-DeconvNet auf mehrere Bildgebungsmodalitäten, darunter Totalreflexions-Fluoreszenzmikroskopie, 3D-Weitfeldmikroskopie, konfokale Mikroskopie, Zwei-Photonen-Mikroskopie, Gitterlichtblattmikroskopie und multiple modale strukturierte Beleuchtungsmikroskopie ; die eine mehrfarbige, hochauflösende 2D/3D-Bildgebung mehrzelliger embryonaler Organismen von mitotischen Einzelzellen bis hin zu Mäusen und Caenorhabditis elegans ermöglicht.
Die Forschung trug den Titel „
Zero-Shot-Lernen ermöglicht sofortige Rauschunterdrückung und Superauflösung in der optischen Fluoreszenzmikroskopie“ und wurde am 16. Mai 2024 in „Nature Communications“ veröffentlicht.
 Die optische Fluoreszenzmikroskopie ist für die biologische Forschung von entscheidender Bedeutung. Die Weiterentwicklung der Superauflösungstechnologie hat zu verbesserten Bilddetails geführt, aber mit der Verbesserung der räumlichen Auflösung gehen auch Kompromisse bei anderen Bildgebungsparametern einher. Computergestützte Superauflösungsmethoden sind zu einem Forschungsschwerpunkt geworden, da sie die Bildqualität online verbessern, die Fähigkeiten vorhandener Geräte erweitern und den Anwendungsbereich erweitern können.
Die optische Fluoreszenzmikroskopie ist für die biologische Forschung von entscheidender Bedeutung. Die Weiterentwicklung der Superauflösungstechnologie hat zu verbesserten Bilddetails geführt, aber mit der Verbesserung der räumlichen Auflösung gehen auch Kompromisse bei anderen Bildgebungsparametern einher. Computergestützte Superauflösungsmethoden sind zu einem Forschungsschwerpunkt geworden, da sie die Bildqualität online verbessern, die Fähigkeiten vorhandener Geräte erweitern und den Anwendungsbereich erweitern können.
Diese Methoden sind in zwei Kategorien unterteilt: Techniken wie Dekonvolution basierend auf analytischen Modellen und Super-Resolution (SR)-Netzwerke basierend auf Deep Learning. Ersteres ist durch Parameterabstimmung und schlechte Anpassungsfähigkeit an komplexe Bildumgebungen eingeschränkt. Letzteres kann komplexe Bildtransformationen durch Big Data erlernen, steht jedoch vor Herausforderungen wie Schwierigkeiten bei der Erfassung und hoher Abhängigkeit von der Qualität der Trainingsdaten. Dies schränkt die Popularität der Deep-Learning-Superauflösungstechnologie in täglichen Anwendungen in der biologischen Forschung ein.
Hier schlug ein Forschungsteam der Tsinghua-Universität und der Chinesischen Akademie der Wissenschaften ein Zero-Shot-Dekonvolution-Framework für tiefe neuronale Netzwerke ZS-DeconvNet vor, das in der Lage ist, DLSR-Netzwerke unüberwacht zu trainieren und dabei nur eine niedrige Auflösung und einen geringen Signalempfang zu verwenden -Rauschverhältnis Ein Stapel planarer Bilder oder volumetrischer Bilder, der eine Zero-Shot-Implementierung ermöglicht.
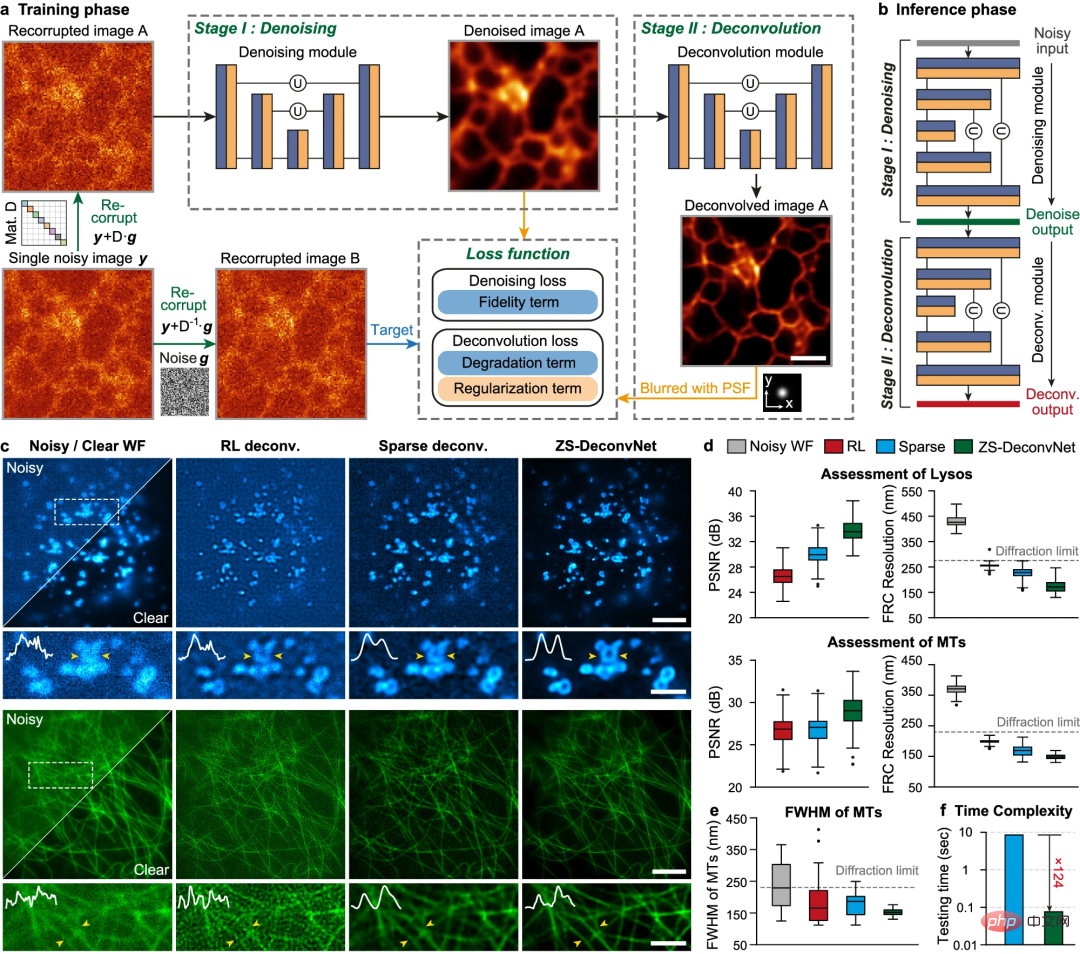 Abbildung: Zero-Shot-Dekonvolutionsnetzwerk. (Quelle: Papier)
Abbildung: Zero-Shot-Dekonvolutionsnetzwerk. (Quelle: Papier)
Die Forscher sagen, dass ZS-DeconvNet selbst beim Training an einem einzelnen Eingabebild mit niedrigem Signal-Rausch-Verhältnis die Auflösung um mehr als das 1,5-fache über die Beugungsgrenze hinaus verbessern kann, mit hoher Wiedergabetreue und Quantifizierung, und ohne dass ein spezifisches Bild erforderlich ist Parameteranpassung.
ZS-DeconvNet eignet sich für eine Vielzahl von Bildgebungsmodalitäten, von der Rastermikroskopie bis zur Weitfeld-Detektionsmikroskopie, und hat seine Fähigkeiten in einer Vielzahl von Proben und Mikroskopaufbauten unter Beweis gestellt.
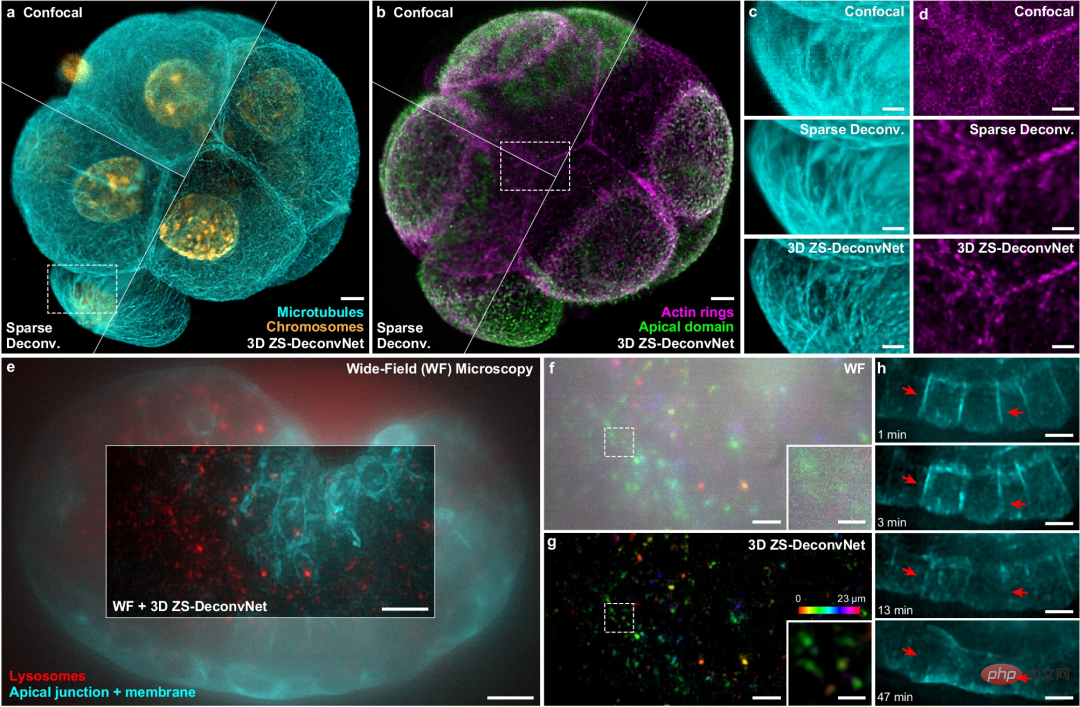 Abbildung: Verallgemeinerung von ZS-DeconvNet auf mehrere Bildgebungsmodalitäten. (Quelle: Papier)
Abbildung: Verallgemeinerung von ZS-DeconvNet auf mehrere Bildgebungsmodalitäten. (Quelle: Papier)
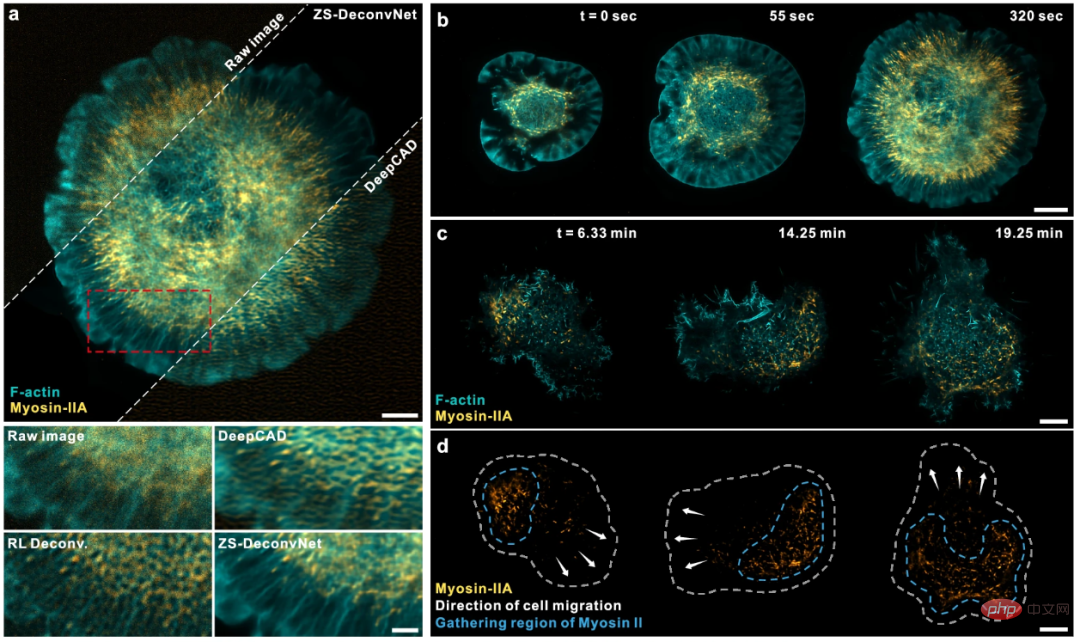
Forscher zeigen, dass richtig trainiertes ZS-DeconvNet hochauflösende Bilder im Millisekundenbereich ableiten kann und so ein lichtempfindliches Zytoskelett während der Interaktion mehrerer Organellen, der Migration sowie der Mitose und Organellendynamik sowie einen langen Hochdurchsatz ermöglicht -Term SR 2D/3D-Bildgebung subzellulärer Strukturen und Dynamik bei der Entwicklung von C. elegans und Mäuseembryonen.
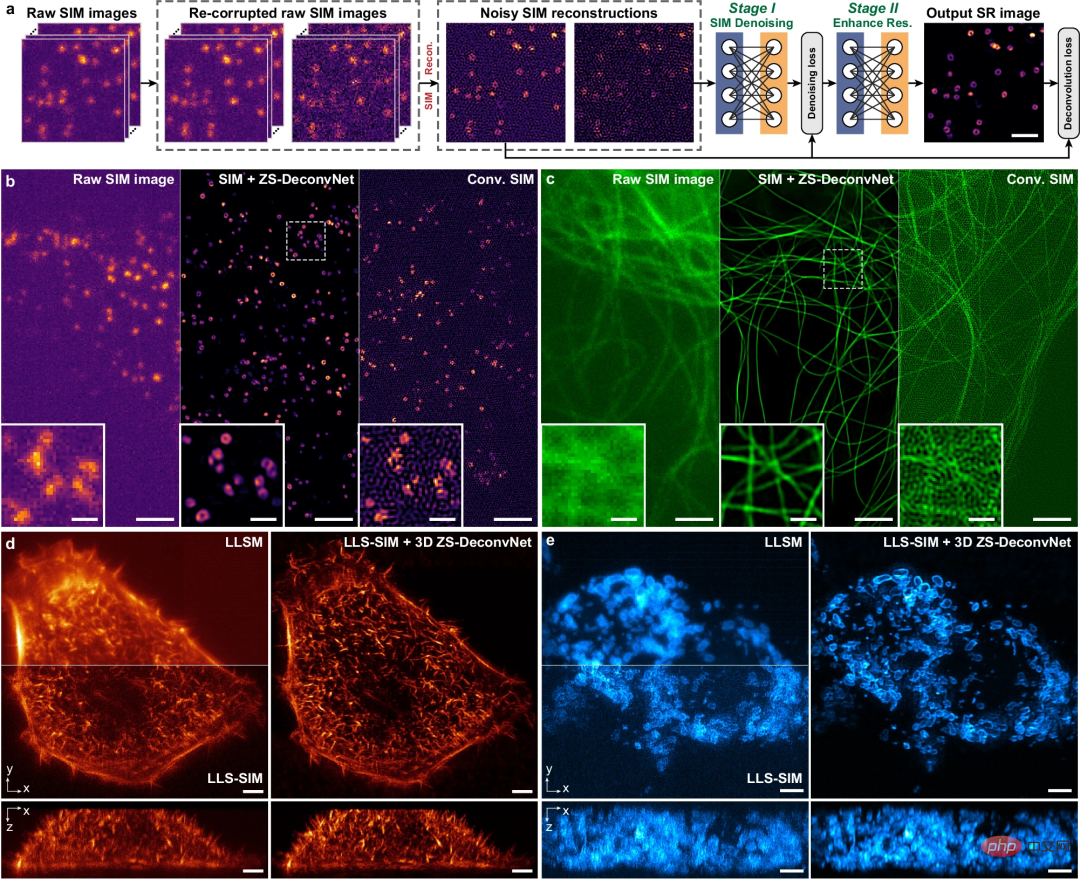 Abbildung: Zero-Sample-Rauschunterdrückung und Auflösungsverbesserung in multimodalen SIM-Daten. (Quelle: Papier)
Abbildung: Zero-Sample-Rauschunterdrückung und Auflösungsverbesserung in multimodalen SIM-Daten. (Quelle: Papier)
Darüber hinaus hat das Team eine Fidschi-Plug-in-Toolbox und eine Tutorial-Homepage der ZS-DeconvNet-Methode erstellt, die einfach verwendet werden kann, um ZS-DeconvNet in der biologischen Forschungsgemeinschaft weit verbreitet zu machen von Benutzern ohne tiefe Lernkenntnisse.
Trotz seiner breiten Anwendbarkeit und Robustheit wird ZS-DeconvNet-Benutzern empfohlen, sich der potenziellen Phantomgenerierung und ihrer Einschränkungen bewusst zu sein, wie z. B. der falschen Identifizierung von Signalen mit geringer Fluoreszenz, Leistungseinbußen bei der Anwendung auf Bilder verschiedener Bildgebungsmodi und Problemen durch falsches PSF Matching und Die Auflösungsverbesserung beim unbeaufsichtigten Lernen ist nicht so offensichtlich wie beim überwachten Lernen.
In Zukunft werden die Funktionen und der Anwendungsbereich von ZS-DeconvNet durch die Kombination fortschrittlicherer Netzwerkarchitekturen, die Erweiterung auf andere optische Superauflösungstechnologien, die Einführung von Domänenanpassungs- oder Generalisierungstechnologien und die Verarbeitung räumlich variierender PSFs weiter erweitert.
Link zum Papier: https://www.nature.com/articles/s41467-024-48575-9
Das obige ist der detaillierte Inhalt von1,5-mal jenseits der Beugungsgrenze sind die Abbildungsbedingungen zehnmal niedriger, die Tsinghua-Universität und die Chinesische Akademie der Wissenschaften nutzen KI-Methoden, um die Mikroskopauflösung zu verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1664
1664
 14
1422
52
1316
25
1268
29
1241
24
14
1422
52
1316
25
1268
29
1241
24

 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
PRO |. Warum verdienen große Modelle, die auf MoE basieren, mehr Aufmerksamkeit?
Aug 07, 2024 pm 07:08 PM
Im Jahr 2023 entwickeln sich fast alle Bereiche der KI in beispielloser Geschwindigkeit weiter. Gleichzeitig verschiebt die KI ständig die technologischen Grenzen wichtiger Bereiche wie der verkörperten Intelligenz und des autonomen Fahrens. Wird der Status von Transformer als Mainstream-Architektur großer KI-Modelle durch den multimodalen Trend erschüttert? Warum ist die Erforschung großer Modelle auf Basis der MoE-Architektur (Mixture of Experts) zu einem neuen Trend in der Branche geworden? Können Large Vision Models (LVM) ein neuer Durchbruch im allgemeinen Sehvermögen sein? ...Aus dem PRO-Mitglieder-Newsletter 2023 dieser Website, der in den letzten sechs Monaten veröffentlicht wurde, haben wir 10 spezielle Interpretationen ausgewählt, die eine detaillierte Analyse der technologischen Trends und industriellen Veränderungen in den oben genannten Bereichen bieten, um Ihnen dabei zu helfen, Ihre Ziele in der Zukunft zu erreichen Jahr vorbereitet sein. Diese Interpretation stammt aus Week50 2023
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
