
 Technologie-Peripheriegeräte
KI
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Technologie-Peripheriegeräte
KI
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern

01 Ausblick im Überblick
Derzeit ist es schwierig, das richtige Gleichgewicht zwischen Erkennungseffizienz und Erkennungsergebnissen zu finden. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird.
02 Hintergrund & Motivation
Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Die Objekterkennung spielt eine entscheidende Rolle bei der Interpretation von Fernerkundungsbildern und kann zur Segmentierung, Beschreibung und Zielverfolgung von Fernerkundungsbildern verwendet werden. Aufgrund ihres relativ großen Sichtfelds und der Notwendigkeit großer Höhen weisen optische Fernerkundungsbilder aus der Luft jedoch Unterschiede in Bezug auf Maßstab, Blickpunktspezifität, zufällige Ausrichtung und hohe Hintergrundkomplexität auf, während die meisten herkömmlichen Datensätze terrestrische Ansichten enthalten. Daher weisen die zur Konstruktion künstlicher Merkmalserkennung verwendeten Techniken traditionell große Unterschiede in Genauigkeit und Geschwindigkeit auf. Aufgrund der Bedürfnisse der Gesellschaft und der Unterstützung der Entwicklung von Deep Learning ist der Einsatz neuronaler Netze zur Zielerkennung in optischen Fernerkundungsbildern notwendig.
Derzeit können Zielerkennungsalgorithmen, die Deep Learning zur Analyse optischer Fernerkundungsfotos kombinieren, in drei Typen unterteilt werden: überwacht, unbeaufsichtigt und schwach überwacht. Aufgrund der Komplexität und Unsicherheit unbeaufsichtigter und schwach überwachter Algorithmen sind überwachte Algorithmen jedoch die am häufigsten verwendeten Algorithmen. Darüber hinaus können überwachte Objekterkennungsalgorithmen in einstufige oder zweistufige Algorithmen unterteilt werden. Basierend auf der Annahme, dass sich Flugzeuge normalerweise an Flughäfen und Schiffe normalerweise an Häfen und Ozeanen befinden, können durch die Erkennung von Flughäfen und Häfen in heruntergesampelten Sternbildern und die anschließende Zuordnung der entdeckten Objekte auf die ursprünglichen ultrahochaufgelösten Satellitenbilder Objekte von erkannt werden verschiedene Größen gleichzeitig. Einige Forscher haben eine auf RCNN basierende rotierende Zielerkennungsmethode vorgeschlagen, die die Genauigkeit der Zielerkennung in Fernerkundungsbildern verbessert, indem das Randomisierungsproblem der Zielrichtungen gelöst wird.
03 Neue Algorithmusforschung
Die meisten Erkennungsköpfe der aktuellen YOLO-Serie basieren auf den Ausgabeeigenschaften von FPN und PAFPN. Darunter sind FPN-basierte Netzwerke wie YOLOv3 und ihre Varianten in Abbildung dargestellt a unten Sie nutzen direkt die Einweg-Fusionsfunktion für die Ausgabe. YOLOv4 und YOLOv5 basieren auf dem PAFPN-Algorithmus und fügen auf dieser Basis einen Low-Level-zu-High-Level-Kanal hinzu, der Low-Level-Signale direkt nach oben überträgt (b unten).
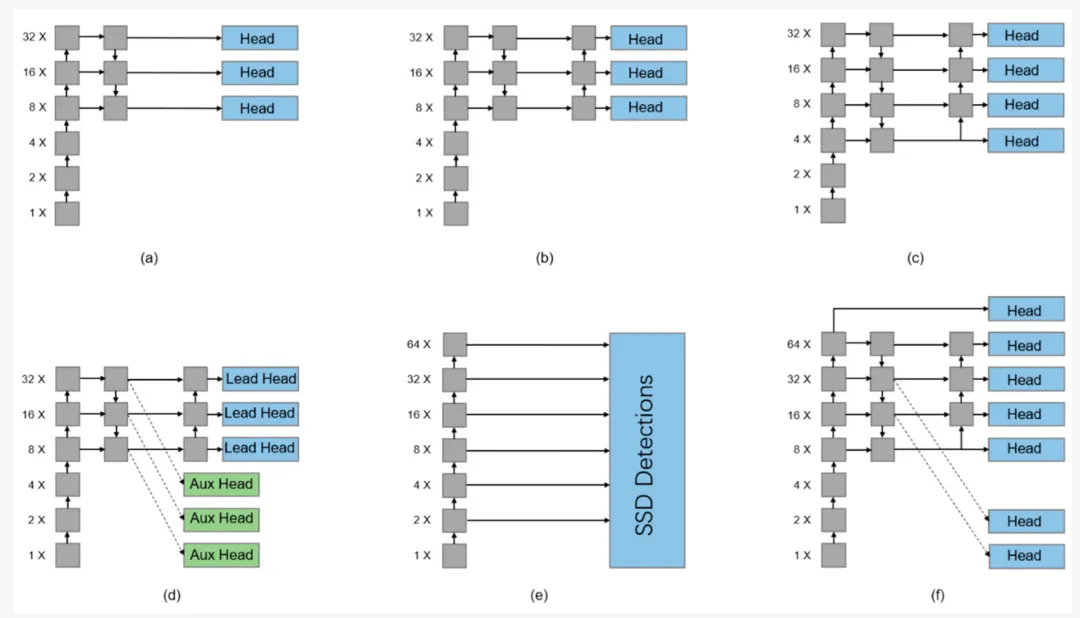
Wie in der Abbildung oben gezeigt, wurde in einigen Studien ein Erkennungskopf für bestimmte Erkennungsaufgaben im TPH-YOLOv5-Modell hinzugefügt. In den Abbildungen b und c oben kann nur die PAFPN-Funktion für die Ausgabe verwendet werden, während die FPN-Funktion nicht vollständig genutzt wird. Daher verbindet YOLOv7 drei Hilfsköpfe mit dem FPN-Ausgang, wie in Abbildung d oben gezeigt, obwohl die Hilfsköpfe nur für die „Grobauswahl“ verwendet werden und eine geringere Gewichtsbewertung haben. Der SSD-Erkennungskopf soll das zu grobe Ankersatzdesign des YOLO-Netzwerks verbessern und ein dichtes Ankerdesign basierend auf mehreren Maßstäben vorschlagen. Wie in Abbildung f gezeigt, kann diese Strategie gleichzeitig die Funktionsinformationen von PANet und FPN nutzen. Darüber hinaus gibt es einen 64-fachen Downsampling-Prozess, der die Ausgabe direkt hinzufügt, wodurch das Netzwerk frühere globale Informationen enthält.
Die Mehrfacherkennungskopfmethode kann die Ausgabefunktionen des Netzwerks effektiv nutzen. Verbessertes YOLO ist ein Objekterkennungsnetzwerk für hochauflösende Fernerkundungsfotos. Wie in der folgenden Abbildung dargestellt:

Die Grundstruktur des Backbone-Netzwerks ist ein CSP-dichtes Netzwerk mit C3- und Faltungsmodulen als Kern. Nach der Datenerweiterung werden Bilder in das Netzwerk eingespeist und nach der Kanalmischung durch das Conv-Modul mit Kernelgröße 6 führen viele Faltungsmodule den Feature-Abruf durch. Nach einem Funktionserweiterungsmodul namens SPPF werden sie mit dem PANet von Neck verbunden. Um die Erkennungsfähigkeit des Netzwerks zu verbessern, wird eine bidirektionale Merkmalsfusion durchgeführt. Conv2d wird verwendet, um die fusionierten Feature-Layer unabhängig zu erweitern, um mehrschichtige Ausgaben zu generieren. Wie in der folgenden Abbildung dargestellt, kombiniert der NMS-Algorithmus die Ausgaben aller Einzelschichtdetektoren, um den endgültigen Erkennungsrahmen zu generieren.

Abbildung b unten beschreibt die strukturelle Zusammensetzung jedes Moduls des verbesserten YOLO-Netzwerks.

Conv umfasst eine 2D-Faltungsschicht, eine BN-Schicht-Batch-Normalisierung und eine Silu-Aktivierungsfunktion, C3 enthält zwei 2D-Faltungsschichten und eine Engpassschicht und Upsample ist eine Upsampling-Schicht. Das SPPF-Modul ist eine beschleunigte Version des SPP-Moduls, das MAB-Modul ist wie oben erwähnt und das ECA ist wie in der unteren linken Ecke dargestellt. Nach dem globalen Durchschnittspooling auf Kanalebene ohne Dimensionsreduzierung werden schnelle 1D-Faltungen der Größe k verwendet, um lokale kanalübergreifende Interaktionsinformationen zu erfassen, wobei die Beziehung jedes Kanals zu seinen k Nachbarn berücksichtigt wird, wodurch ECA effizient durchgeführt wird. Die beiden oben genannten Transformationen sammeln Merkmale entlang zweier Raumrichtungen, um ein Paar richtungsbezogener Merkmalskarten zu erzeugen, die dann mithilfe von Faltungs- und Sigmoidfunktionen verkettet und modifiziert werden, um eine Aufmerksamkeitsausgabe bereitzustellen.
04 Experiment und Visualisierung
Der SIMD-Datensatz ist ein Open-Source-Datensatz zur Erkennung hochauflösender Fernerkundungsobjekte mit mehreren Kategorien, der insgesamt 15 Kategorien enthält, wie in Abbildung 4 dargestellt. Darüber hinaus ist der SIMD-Datensatz stärker auf kleine und mittelgroße Ziele verteilt (w


Sie können den Ausgang des SPPF-Moduls mit dem Ausgangsheader verbinden, um große Ziele im Bild zu identifizieren. Die Ausgabe des SPPF-Moduls verfügt jedoch über mehrere Verbindungen und umfasst Ziele in mehreren Maßstäben. Daher führt die direkte Verwendung für den Erkennungskopf zur Identifizierung großer Objekte zu einer schlechten Modelldarstellung, wie in der Abbildung oben vor und nach dem Hinzufügen dargestellt MAB-Modul Visueller Vergleich von Heatmaps einiger Erkennungsergebnisse. Nach dem Hinzufügen des MAB-Moduls konzentriert sich der Erkennungskopf auf die Erkennung großer Ziele und weist die Vorhersage kleiner Ziele anderen Vorhersageköpfen zu, was den Ausdruckseffekt des Modells verbessert und besser den Anforderungen der Aufteilung des Erkennungskopfs nach Ziel entspricht Größe im YOLO-Algorithmus.

Einige Testergebnisse sind im Bild oben dargestellt. Den einzelnen Erkennungsergebnissen nach zu urteilen, gibt es keinen großen Unterschied zu anderen Algorithmen. Im Vergleich zu anderen Algorithmen verbessert der von uns untersuchte Algorithmus jedoch den Erkennungseffekt des Modells und stellt gleichzeitig sicher, dass der Zeitverbrauch nicht wesentlich ansteigt, und nutzt den Aufmerksamkeitsmechanismus Verbessern Sie den Ausdruckseffekt des Modells.

Das obige ist der detaillierte Inhalt vonVerbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

 Lösung für i7-7700, kein Upgrade auf Windows 11 möglich
Dec 26, 2023 pm 06:52 PM
Lösung für i7-7700, kein Upgrade auf Windows 11 möglich
Dec 26, 2023 pm 06:52 PM
Die Leistung des i77700 reicht völlig aus, um Win11 auszuführen, aber Benutzer stellen fest, dass ihr i77700 nicht auf Win11 aktualisiert werden kann. Dies ist hauptsächlich auf die von Microsoft auferlegten Einschränkungen zurückzuführen, sodass sie es installieren können, solange sie diese Einschränkung überspringen. i77700 kann nicht auf win11 aktualisiert werden: 1. Weil Microsoft die CPU-Version begrenzt. 2. Nur die Intel-Versionen der achten Generation und höher können direkt auf Win11 aktualisiert werden. 3. Als 7. Generation kann der i77700 die Upgrade-Anforderungen von Win11 nicht erfüllen. 4. Der i77700 ist jedoch hinsichtlich der Leistung durchaus in der Lage, Win11 reibungslos zu nutzen. 5. Sie können also das Win11-Direktinstallationssystem dieser Site verwenden. 6. Nachdem der Download abgeschlossen ist, klicken Sie mit der rechten Maustaste auf die Datei und „laden“ sie. 7. Doppelklicken Sie, um den „One-Click“-Vorgang auszuführen
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Entdecken Sie die zugrunde liegenden Prinzipien und die Algorithmusauswahl der C++-Sortierfunktion
Apr 02, 2024 pm 05:36 PM
Die unterste Ebene der C++-Sortierfunktion verwendet die Zusammenführungssortierung, ihre Komplexität beträgt O(nlogn) und bietet verschiedene Auswahlmöglichkeiten für Sortieralgorithmen, einschließlich schneller Sortierung, Heap-Sortierung und stabiler Sortierung.
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Kann künstliche Intelligenz Kriminalität vorhersagen? Entdecken Sie die Möglichkeiten von CrimeGPT
Mar 22, 2024 pm 10:10 PM
Die Konvergenz von künstlicher Intelligenz (KI) und Strafverfolgung eröffnet neue Möglichkeiten zur Kriminalprävention und -aufdeckung. Die Vorhersagefähigkeiten künstlicher Intelligenz werden häufig in Systemen wie CrimeGPT (Crime Prediction Technology) genutzt, um kriminelle Aktivitäten vorherzusagen. Dieser Artikel untersucht das Potenzial künstlicher Intelligenz bei der Kriminalitätsvorhersage, ihre aktuellen Anwendungen, die Herausforderungen, denen sie gegenübersteht, und die möglichen ethischen Auswirkungen der Technologie. Künstliche Intelligenz und Kriminalitätsvorhersage: Die Grundlagen CrimeGPT verwendet Algorithmen des maschinellen Lernens, um große Datensätze zu analysieren und Muster zu identifizieren, die vorhersagen können, wo und wann Straftaten wahrscheinlich passieren. Zu diesen Datensätzen gehören historische Kriminalstatistiken, demografische Informationen, Wirtschaftsindikatoren, Wettermuster und mehr. Durch die Identifizierung von Trends, die menschliche Analysten möglicherweise übersehen, kann künstliche Intelligenz Strafverfolgungsbehörden stärken
 Das neueste Meisterwerk des MIT: Verwendung von GPT-3.5 zur Lösung des Problems der Erkennung von Zeitreihenanomalien
Jun 08, 2024 pm 06:09 PM
Das neueste Meisterwerk des MIT: Verwendung von GPT-3.5 zur Lösung des Problems der Erkennung von Zeitreihenanomalien
Jun 08, 2024 pm 06:09 PM
Heute möchte ich Ihnen einen letzte Woche vom MIT veröffentlichten Artikel vorstellen, in dem GPT-3.5-turbo verwendet wird, um das Problem der Erkennung von Zeitreihenanomalien zu lösen, und zunächst die Wirksamkeit von LLM bei der Erkennung von Zeitreihenanomalien überprüft wird. Im gesamten Prozess gibt es keine Feinabstimmung, und GPT-3.5-Turbo wird direkt zur Anomalieerkennung verwendet. Der Kern dieses Artikels besteht darin, wie man Zeitreihen in Eingaben umwandelt, die von GPT-3.5-Turbo erkannt werden können, und wie man sie entwirft Eingabeaufforderungen oder Pipelines, damit LLM die Anomalieerkennungsaufgabe lösen kann. Lassen Sie mich Ihnen diese Arbeit im Detail vorstellen. Titel des Bildpapiers: Largelingualmodelscanbezero-shotanomalydete
 Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
Verbesserter Erkennungsalgorithmus: zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern
Jun 06, 2024 pm 12:33 PM
01Ausblicksübersicht Derzeit ist es schwierig, ein angemessenes Gleichgewicht zwischen Detektionseffizienz und Detektionsergebnissen zu erreichen. Wir haben einen verbesserten YOLOv5-Algorithmus zur Zielerkennung in hochauflösenden optischen Fernerkundungsbildern entwickelt, der mehrschichtige Merkmalspyramiden, Multierkennungskopfstrategien und hybride Aufmerksamkeitsmodule verwendet, um die Wirkung des Zielerkennungsnetzwerks in optischen Fernerkundungsbildern zu verbessern. Laut SIMD-Datensatz ist der mAP des neuen Algorithmus 2,2 % besser als YOLOv5 und 8,48 % besser als YOLOX, wodurch ein besseres Gleichgewicht zwischen Erkennungsergebnissen und Geschwindigkeit erreicht wird. 02 Hintergrund und Motivation Mit der rasanten Entwicklung der Fernerkundungstechnologie wurden hochauflösende optische Fernerkundungsbilder verwendet, um viele Objekte auf der Erdoberfläche zu beschreiben, darunter Flugzeuge, Autos, Gebäude usw. Objekterkennung bei der Interpretation von Fernerkundungsbildern
 Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
May 09, 2024 am 09:01 AM
1. Hintergrund des Baus der 58-Portrait-Plattform Zunächst möchte ich Ihnen den Hintergrund des Baus der 58-Portrait-Plattform mitteilen. 1. Das traditionelle Denken der traditionellen Profiling-Plattform reicht nicht mehr aus. Der Aufbau einer Benutzer-Profiling-Plattform basiert auf Data-Warehouse-Modellierungsfunktionen, um Daten aus mehreren Geschäftsbereichen zu integrieren, um genaue Benutzerporträts zu erstellen Und schließlich muss es über Datenplattformfunktionen verfügen, um Benutzerprofildaten effizient zu speichern, abzufragen und zu teilen sowie Profildienste bereitzustellen. Der Hauptunterschied zwischen einer selbst erstellten Business-Profiling-Plattform und einer Middle-Office-Profiling-Plattform besteht darin, dass die selbst erstellte Profiling-Plattform einen einzelnen Geschäftsbereich bedient und bei Bedarf angepasst werden kann. Die Mid-Office-Plattform bedient mehrere Geschäftsbereiche und ist komplex Modellierung und bietet allgemeinere Funktionen. 2.58 Benutzerporträts vom Hintergrund der Porträtkonstruktion im Mittelbahnsteig 58
