
 Technologie-Peripheriegeräte
KI
Yann LeCun: ViT ist langsam und ineffizient. Die Echtzeit-Bildverarbeitung hängt immer noch von der Faltung ab.
Technologie-Peripheriegeräte
KI
Yann LeCun: ViT ist langsam und ineffizient. Die Echtzeit-Bildverarbeitung hängt immer noch von der Faltung ab.
Yann LeCun: ViT ist langsam und ineffizient. Die Echtzeit-Bildverarbeitung hängt immer noch von der Faltung ab.

Ist es im Zeitalter der Transformer-Vereinigung immer noch notwendig, die CNN-Richtung der Computer Vision zu untersuchen?
Anfang dieses Jahres machte das große Videomodell Sora von OpenAI die Vision Transformer (ViT)-Architektur populär. Seitdem gibt es eine anhaltende Debatte darüber, wer leistungsfähiger ist: ViT oder traditionelle Faltungs-Neuronale Netze (CNN).
Kürzlich beteiligte sich auch Turing-Preisträger Yann LeCun, Chefwissenschaftler von Meta, der in den sozialen Medien aktiv war, an der Diskussion über den Streit zwischen ViT und CNN.

Die Ursache für diesen Vorfall war, dass Harald Schäfer, CTO von Comma.ai, seine neuesten Forschungsergebnisse vorstellte. Er (wie viele neuere KI-Wissenschaftler) verweist auf Yann LeCuns Aussage, dass, obwohl der Turing-Award-Tycoon glaubt, dass reines ViT nicht praktikabel ist, wir unseren Kompressor kürzlich auf reines ViT umgestellt haben Die Wirkung ist sehr gut.
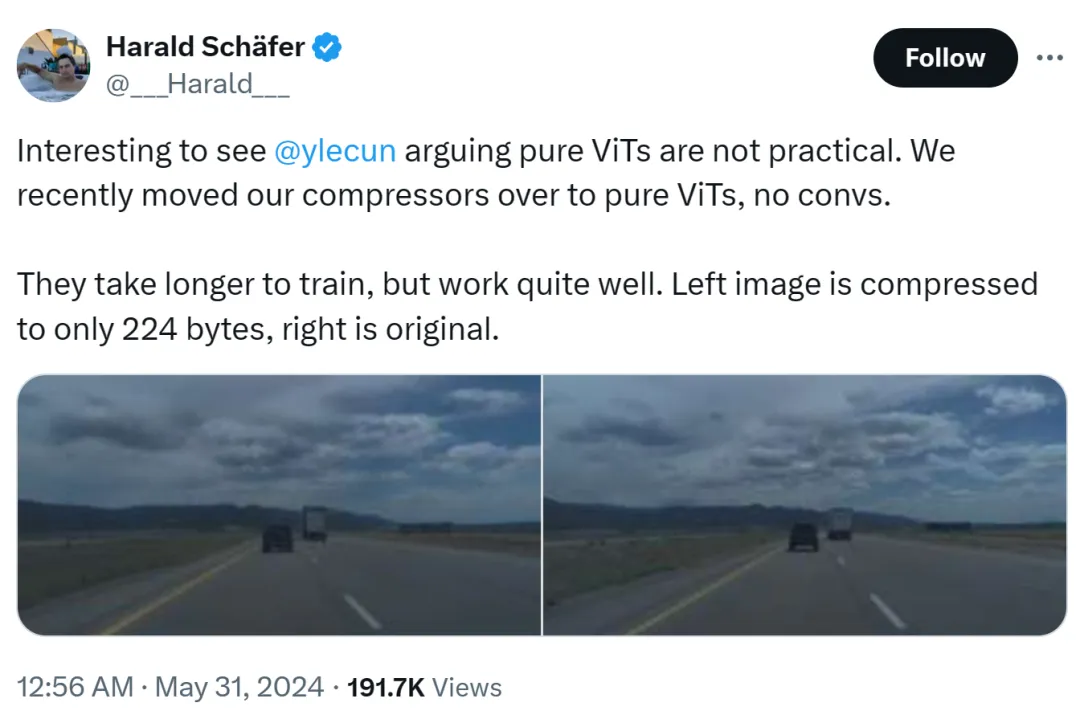
Zum Beispiel ist das Bild links auf nur 224 Bytes komprimiert und rechts ist das Originalbild.
ist nur 14×128, was für ein Weltmodell für autonomes Fahren sehr groß ist, was bedeutet, dass eine große Datenmenge für das Training eingegeben werden kann. Die Schulung in einer virtuellen Umgebung ist kostengünstiger als in einer realen Umgebung, in der Agenten gemäß den Richtlinien geschult werden müssen, damit sie ordnungsgemäß arbeiten können. Höhere Auflösungen für virtuelles Training funktionieren besser, allerdings wird der Simulator sehr langsam, sodass derzeit eine Komprimierung erforderlich ist.
Seine Demonstration löste Diskussionen im KI-Kreis aus und Eric Jang, Vizepräsident für künstliche Intelligenz bei 1X, antwortete, dass die Ergebnisse erstaunlich seien.
Harald lobte weiterhin ViT: Das ist eine sehr schöne Architektur.
Jemand begann hier Anstoß zu nehmen: Meister wie LeCun schaffen es manchmal nicht, mit dem Innovationstempo Schritt zu halten.
Yann LeCun reagierte jedoch schnell und argumentierte, dass er nicht sage, dass ViT nicht praktikabel sei und dass es jetzt von allen genutzt werde. Er möchte damit zum Ausdruck bringen, dass ViT zu langsam und ineffizient ist und daher für die Echtzeitverarbeitung hochauflösender Bild- und Videoaufgaben ungeeignet ist.
Yann LeCun und Cue Xie Saining, ein Assistenzprofessor an der New York University, dessen Arbeit ConvNext bewiesen hat, dass CNN genauso gut sein kann wie ViT, wenn die Methode richtig ist.
Er fährt fort, dass man mindestens ein paar Faltungsschichten mit Pooling und Schritten braucht, bevor man sich an eine Selbstaufmerksamkeitsschleife hält.
Wenn Selbstaufmerksamkeit gleichbedeutend mit Permutation ist, macht dies für die Bild- oder Videoverarbeitung auf niedriger Ebene überhaupt keinen Sinn, und auch die Patchifizierung mit einem einzigen Schritt am Frontend ist nicht möglich. Da zudem die Korrelation in Bildern oder Videos stark lokal konzentriert ist, ist die globale Aufmerksamkeit bedeutungslos und nicht skalierbar.
Auf einer höheren Ebene ist es sinnvoll, eine Selbstaufmerksamkeitsschleife zu verwenden, sobald Features Objekte darstellen: Es sind die Beziehungen und Interaktionen zwischen Objekten, die wichtig sind, nicht ihre Standorte. Diese Hybridarchitektur wurde durch das DETR-System entwickelt, das vom Meta-Forscher Nicolas Carion und Co-Autoren vervollständigt wurde.
Seit dem Aufkommen der DETR-Arbeit sagte Yann LeCun, dass seine Lieblingsarchitektur Faltung/Stride/Pooling auf niedriger Ebene und Selbstaufmerksamkeitsschleife auf hoher Ebene sei.
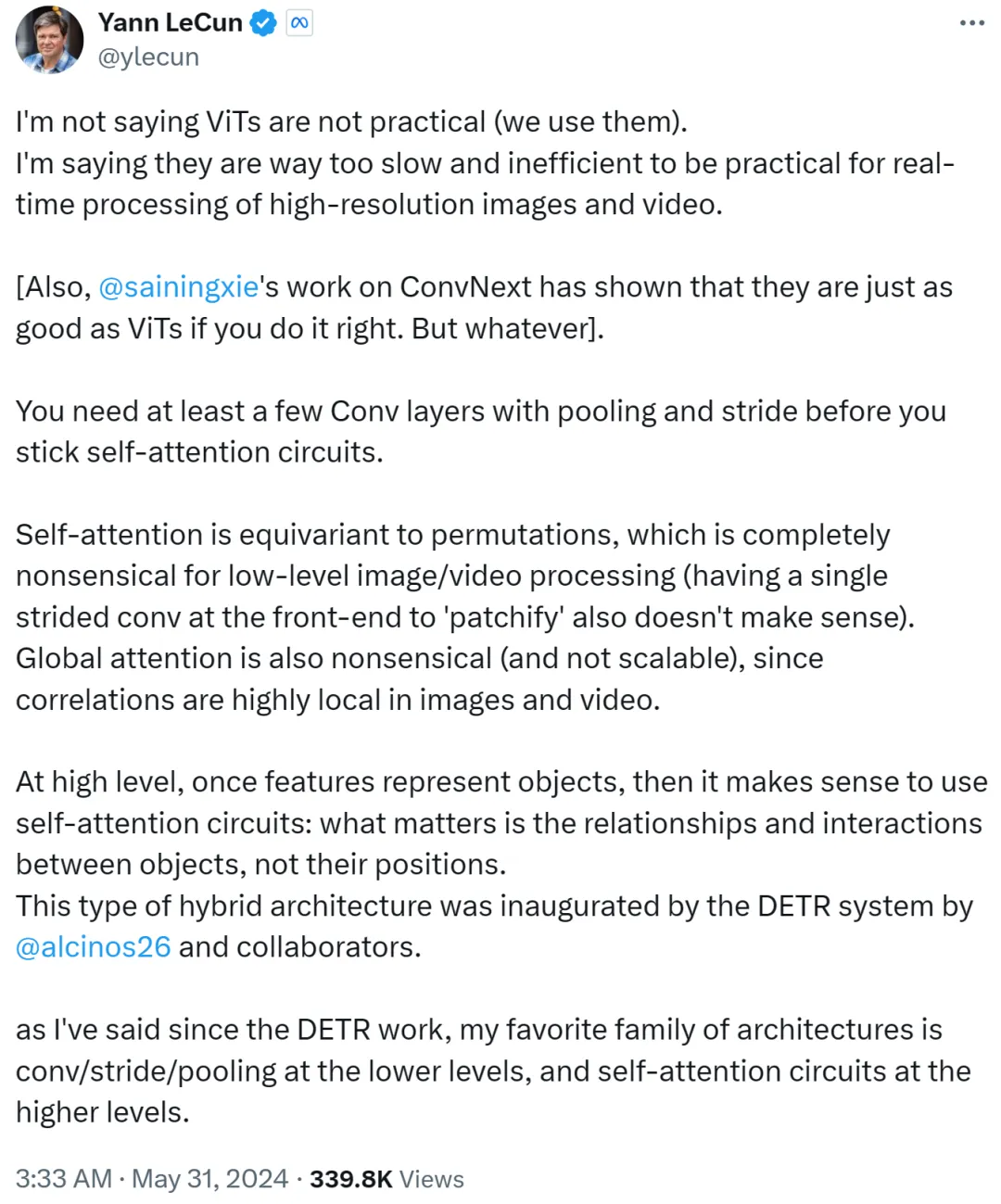
Yann LeCun hat es im zweiten Beitrag zusammengefasst: Verwenden Sie Faltung mit Schrittweite oder Pooling auf niedriger Ebene, verwenden Sie Selbstaufmerksamkeitsschleife auf hoher Ebene und verwenden Sie Merkmalsvektoren, um Objekte darzustellen.
Er geht auch davon aus, dass Tesla Fully Self-Driving (FSD) Faltungen (oder komplexere lokale Operatoren) auf niedrigen Ebenen verwendet, kombiniert mit mehr globalen Schleifen auf höheren Ebenen (möglicherweise unter Verwendung von Selbstaufmerksamkeit). Daher ist die Verwendung von Transformers für Patch-Einbettungen auf niedriger Ebene eine völlige Verschwendung.
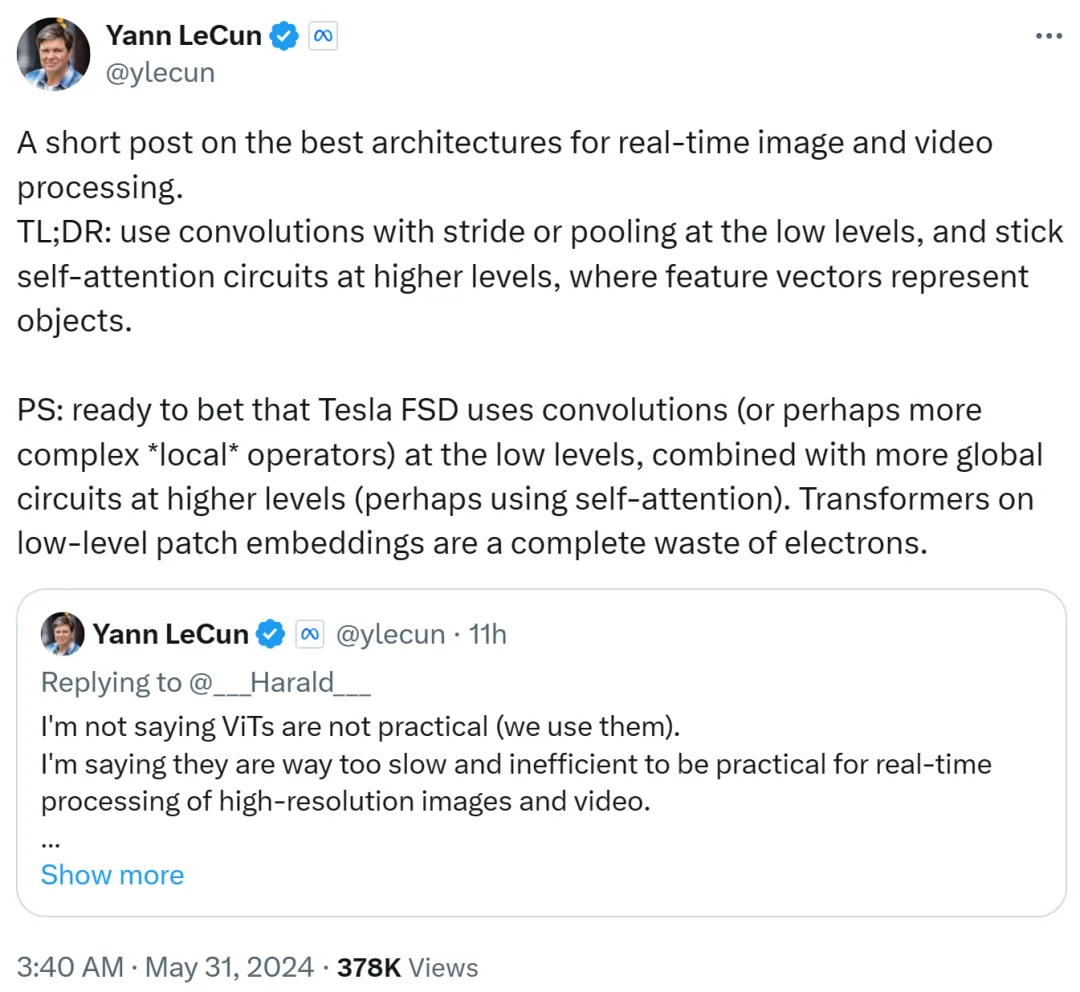
Ich schätze, der Erzfeind Musk nutzt immer noch die Faltungsroute.
Xie Senin äußerte auch seine Meinung. Er glaubt, dass ViT für Bilder mit niedriger Auflösung von 224 x 224 sehr gut geeignet ist, aber was ist, wenn die Bildauflösung 1 Million x 1 Million erreicht? Zu diesem Zeitpunkt wird entweder Faltung verwendet oder ViT wird gepatcht und unter Verwendung gemeinsamer Gewichte verarbeitet, was immer noch Faltungscharakter hat.
Daher sagte Xie Senin, dass ihm in diesem Moment klar wurde, dass das Faltungsnetzwerk keine Architektur, sondern eine Denkweise ist.
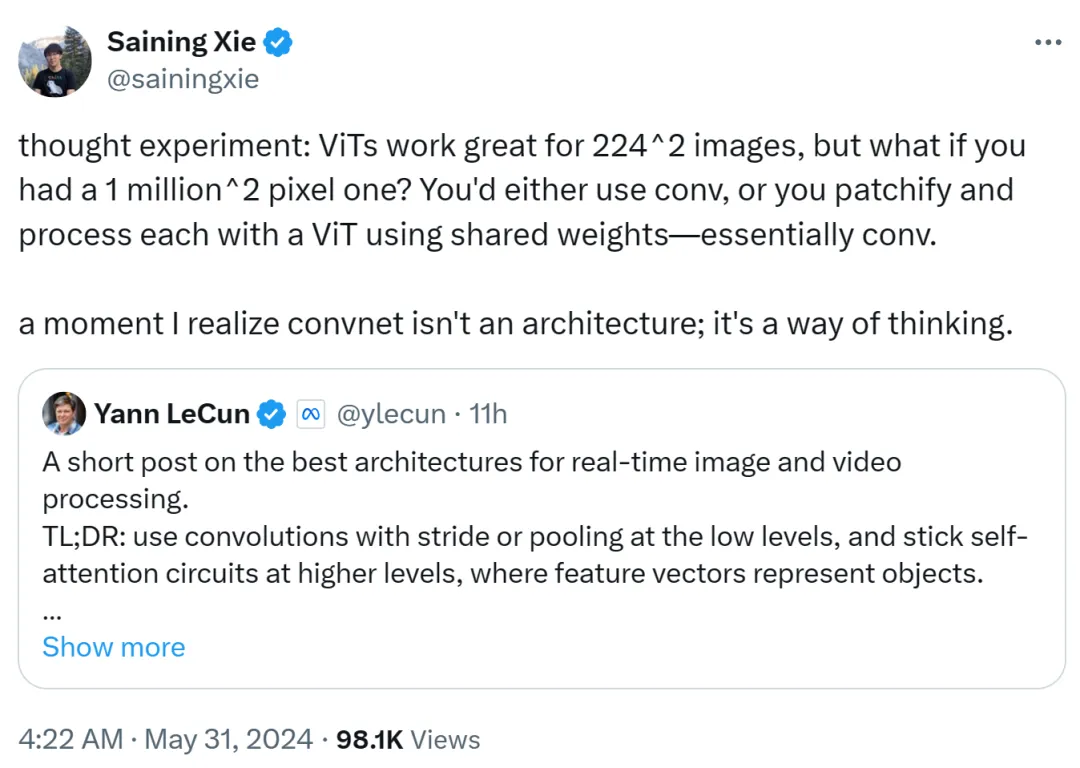
Diese Ansicht wird von Yann LeCun anerkannt.

Google DeepMind-Forscher Lucas Beyer sagte auch, dass er dank der Nullauffüllung herkömmlicher Faltungsnetzwerke sicher ist, dass „Faltungs-ViT“ (anstelle von ViT + Faltung) gut funktionieren wird.
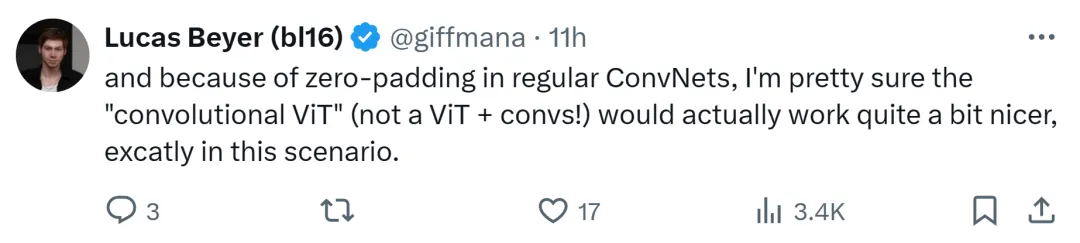
Es ist absehbar, dass diese Debatte zwischen ViT und CNN so lange andauern wird, bis in Zukunft eine weitere leistungsfähigere Architektur auftaucht.
Das obige ist der detaillierte Inhalt vonYann LeCun: ViT ist langsam und ineffizient. Die Echtzeit-Bildverarbeitung hängt immer noch von der Faltung ab.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1673
1673
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 KI und Komponist: Verbesserung der Codequalität und -entwicklung
May 09, 2025 am 12:20 AM
KI und Komponist: Verbesserung der Codequalität und -entwicklung
May 09, 2025 am 12:20 AM
In Composer verbessert AI die Entwicklungseffizienz und die Codesqualität hauptsächlich durch Abhängigkeitsempfehlung, Abhängigkeitskonfliktlösung und Verbesserung der Codequalität. 1. AI kann entsprechende Abhängigkeitspakete entsprechend den Projektanforderungen empfehlen. 2. AI bietet intelligente Lösungen, um mit Abhängigkeitskonflikten umzugehen. 3. AI überprüft den Code und bietet Optimierungsvorschläge zur Verbesserung der Codequalität. Durch diese Funktionen können sich Entwickler mehr auf die Implementierung der Geschäftslogik konzentrieren.
 Strategie zum Geldverdienen mit Zero Foundation: 5 Arten von Altcoins, die im Jahr 2025 bestückt sein müssen, stellen Sie sicher, dass Sie das 50 -mal profitablere machen!
May 08, 2025 pm 08:30 PM
Strategie zum Geldverdienen mit Zero Foundation: 5 Arten von Altcoins, die im Jahr 2025 bestückt sein müssen, stellen Sie sicher, dass Sie das 50 -mal profitablere machen!
May 08, 2025 pm 08:30 PM
In Kryptowährungsmärkten werden Altcoins häufig von Investoren als potenziell hochrangige Vermögenswerte angesehen. Obwohl es viele Altcoins auf dem Markt gibt, können nicht alle Altcoins die erwarteten Vorteile bringen. In diesem Artikel wird Anleger mit einer Null -Foundation einen detaillierten Leitfaden zur Verfügung gestellt, in dem die im Jahr 2025 gehorten 5 Altcoins vorgestellt werden und erklären, wie das Ziel erzielt werden kann, durch diese Anlagen einen stetigen Gewinn von 50 -fachen zu erzielen.
 Top 10 Kryptowährungsbörsen im Währungskreis, die neueste Rangliste der Top 10 Top -Währungs -Handelsplattformen im Jahr 2025
May 08, 2025 pm 10:45 PM
Top 10 Kryptowährungsbörsen im Währungskreis, die neueste Rangliste der Top 10 Top -Währungs -Handelsplattformen im Jahr 2025
May 08, 2025 pm 10:45 PM
Rangliste der Top Ten Kryptowährungsbörsen im Währungskreis: 1. Binance: Führung der Welt, bietet einen effizienten Handel und eine Vielzahl von Finanzprodukten. 2. OKX: Es ist innovativ und vielfältig und unterstützt eine Vielzahl von Transaktionstypen. 3. Huobi: stabil und zuverlässig, mit hochwertigem Service. 4. Coinbase: Seien Sie freundlich für Anfänger und einfache Schnittstelle. 5. Kraken: Die erste Wahl für professionelle Händler mit leistungsstarken Tools. 6. Bitfinex: Effizienter Handel, reichhaltige Handelspaare. 7. Bittrex: Sicherheitsvorschriften, regulatorische Zusammenarbeit. 8. Poloniex und so weiter.
 Web3 AI Crypto Presale bietet Hedge -Fonds -Handelstools für alle Benutzer
May 08, 2025 pm 08:24 PM
Web3 AI Crypto Presale bietet Hedge -Fonds -Handelstools für alle Benutzer
May 08, 2025 pm 08:24 PM
In einem Markt, der oft von inhaltlichen Geschichten angetrieben wird, können reale Merkmale übersehen werden. Picoin gewinnt durch die Unterstützung seiner Gemeinde und erhöht das institutionelle Interesse vor dem Konsens von 2025. In einem Markt, der oft von inhaltlichen Geschichten angetrieben wird, ist es leicht, echte Funktionen zu verpassen. Picoin (Pi) gewann vor dem Konsens 2025 an Dynamik, während Cardano (ADA) mit neuen Konkurrenten konfrontiert war, als es sich schneller bewegte, und ein anderes Projekt bietet etwas anderes an. Während Web3AI-Kryptowährung immer noch in Vorverkaufszustand ist, ist es nicht ein Anliegen, dass sie durch die Verfolgung von Trends erreicht wird, sondern indem sie den Benutzern Zugriff auf dieselbe Art von Tools erhalten, die von Quanten-Hedge-Fonds verwendet werden
 Schockierende Veröffentlichung! Die neuesten maßgeblichen Ranglisten der Top Ten Exchange -Apps im Währungskreis 2025
May 08, 2025 pm 08:03 PM
Schockierende Veröffentlichung! Die neuesten maßgeblichen Ranglisten der Top Ten Exchange -Apps im Währungskreis 2025
May 08, 2025 pm 08:03 PM
Das Folgende ist das maßgebliche umfassende Ranking der Global Digital Currency Exchange-App im Jahr 2025, das auf der Grundlage mehrdimensionaler Daten wie Transaktionsvolumen, Sicherheit, Compliance und Benutzererfahrung zusammengestellt wird, damit Sie Markttrends genau erfassen:
 Top 10 Top -Währungsbörsen in der Währungskreis -App Neueste Rangliste der Top 10 Digitalwährungsbörsen im Währungskreis im Jahr 2025
May 12, 2025 pm 06:00 PM
Top 10 Top -Währungsbörsen in der Währungskreis -App Neueste Rangliste der Top 10 Digitalwährungsbörsen im Währungskreis im Jahr 2025
May 12, 2025 pm 06:00 PM
Top 10 Apps für virtuelle Währungsaustausch im Währungskreis: 1. Binance, 2. OKX, 3. Huobi, 4. Coinbase, 5. Kraken, 6. Bitfinex, 7. Bybit, 8. Kucoin, 9. Gemini, 10. Bitstamp, diese Plattformen sind beliebt für ihre Transaktionsvolumen, Sicherheit und Benutzererfahrung.
 So stellen Sie WordPress -Cookies ein, holen und löschen Sie wie ein Profi)
May 12, 2025 pm 08:57 PM
So stellen Sie WordPress -Cookies ein, holen und löschen Sie wie ein Profi)
May 12, 2025 pm 08:57 PM
Möchten Sie wissen, wie Sie Cookies auf Ihrer WordPress -Website verwenden? Cookies sind nützliche Tools zum Speichern von temporären Informationen in den Browsern der Benutzer. Sie können diese Informationen verwenden, um die Benutzererfahrung durch Personalisierung und Verhaltensziel zu verbessern. In diesem ultimativen Leitfaden zeigen wir Ihnen, wie Sie WordPresscookies wie einen Profi einstellen, erhalten und löschen. Hinweis: Dies ist ein fortgeschrittenes Tutorial. Sie müssen HTML, CSS, WordPress -Websites und PHP beherrschen. Was sind Kekse? Cookies werden erstellt und gespeichert, wenn Benutzer Websites besuchen.
 2025 Huobi apkv10.50.0 Download -Handbuch zum Herunterladen
May 12, 2025 pm 08:48 PM
2025 Huobi apkv10.50.0 Download -Handbuch zum Herunterladen
May 12, 2025 pm 08:48 PM
Huobi apkv10.50.0 Download -Handbuch: 1. Klicken Sie im Artikel direkt auf den direkten Link; 2. Wählen Sie das richtige Download -Paket aus; 3. Ausfüllen der Registrierungsinformationen; 4. Starten Sie den Huobi -Handelsprozess.
